前言
在本系列博客中,你将学习到三种构建 Flink 应用程序的强大案例:
-
动态更新应用程序的逻辑
-
动态的数据分区(shuffle),在作业运行时进行控制
-
基于自定义窗口逻辑的低延迟告警(不使用 Window API)
这几个案例扩展了使用静态定义的数据流可以实现的功能,并提供了满足复杂业务需求的基础。
动态更新应用程序的逻辑 允许作业在运行时进行更改,不需要将作业停止后修改代码再发布。
动态的数据分区 为运行中的 Flink 作业作业提供了动态地将数据分组(group by)的功能。对于想要构建一个可以动态配置应用逻辑的 Flink 程序,类似功能很常见。
自定义窗口管理 演示了如何在原生的 Window API 不能完全满足你的需求下,去通过最底层的 Process Function API 来完成你的需求。你将学会如何自定义 Window 逻辑来实现低延迟告警以及如何利用定时器(Timer)来限制状态的无限增长。
这几个案例都是建立在 Flink 核心功能的基础上,但是通过官方文档你可能无法立即明白,因为如果没有具体的用例,解释和呈现它们背后的原理其实并不是那么简单。这就是为什么我们将通过一些实际的案例来展示,本案例为 Apache Flink 的一个真实使用场景 —— 欺诈检测引擎。我希望你能从本系列文章中收获到这些强大的功能和方法,然后能应用在你们实际的应用场景中去。
在该系列的第一篇博客中,我们将先来看看这个应用程序的架构、组件和交互。然后我们将深入研究第一个案例的的实现细节 —— 动态数据分区。
你将能够在本地运行完整的欺诈检测演示应用程序,并且可以通过 Github 仓库查看其完整实现代码。
欺诈检测系统演示
本次掩饰的欺诈检测引擎的代码是开源的,可以在线获取,要是想在本地运行它,请按照 https://github.com/afedulov/fraud-detection-demo 中的 README 描述的步骤自行进行操作。
你将看到该案例的代码和组件都很全,仅需要通过 docker 和 docker-compose 构建源码。仓库里面包含了下面组件:
-
含有 Zookeeper 的 Apache Kafka
-
Apache Flink(应用程序)
-
欺诈检测引擎的 Web 应用
欺诈检测引擎的目标是消费金融交易的实时数据流,然后根据一组检测规则对其进行评估。这些规则会经常更改和调整,在实际的生产系统中,重要的是要能在作业运行的时候去添加和删除规则,而不会因停止和重新启动作业从而造成高昂的代价。
当你在本地运行成功后,你在浏览器中输入 URL 可以看到如下效果:
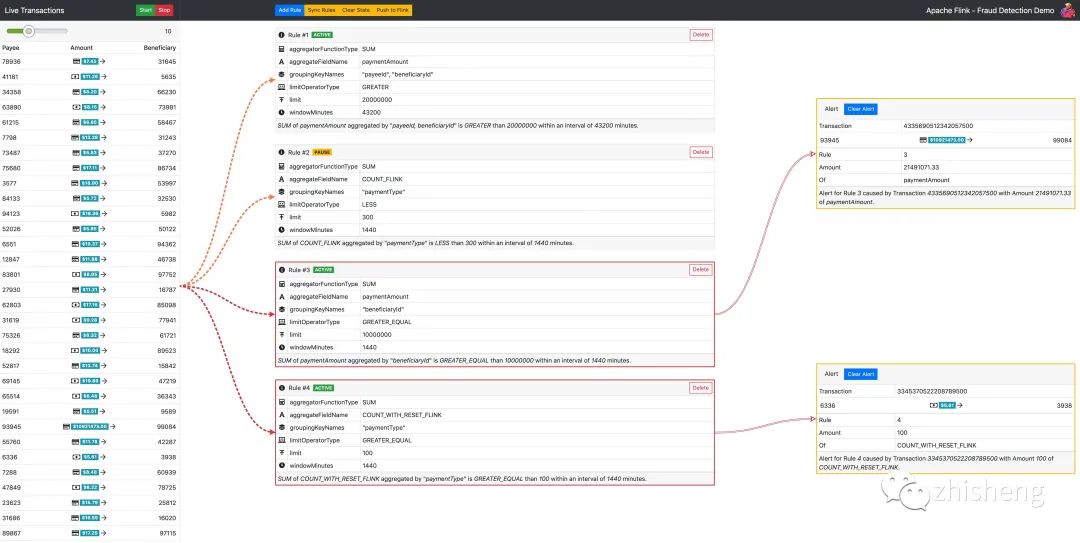
欺诈检测引擎演示UI
点击 “Start” 按钮后,你可以在左侧看到系统中流动的金融交易大盘,你可以通过顶部的滑块去控制每秒生成的数据,中间部分用于管理 Flink 用于计算的规则,你可以在这里创建新规则以及发出控制命令,例如清除 Flink 的状态。
现成的演示带有一组预定义的示例规则,你可以点击 Start 按钮,一段时间之后,将观察到 UI 右侧部分中显示的告警,这些告警消息是 Flink 根据预定义的规则评估生成的交易流的结果。
我们的样本欺诈检测系统包含三个主要的组件:
-
前端(React)
-
后端(SpringBoot)
-
欺诈检测 Flink 应用程序
三者之间的组成关系如下图所示:
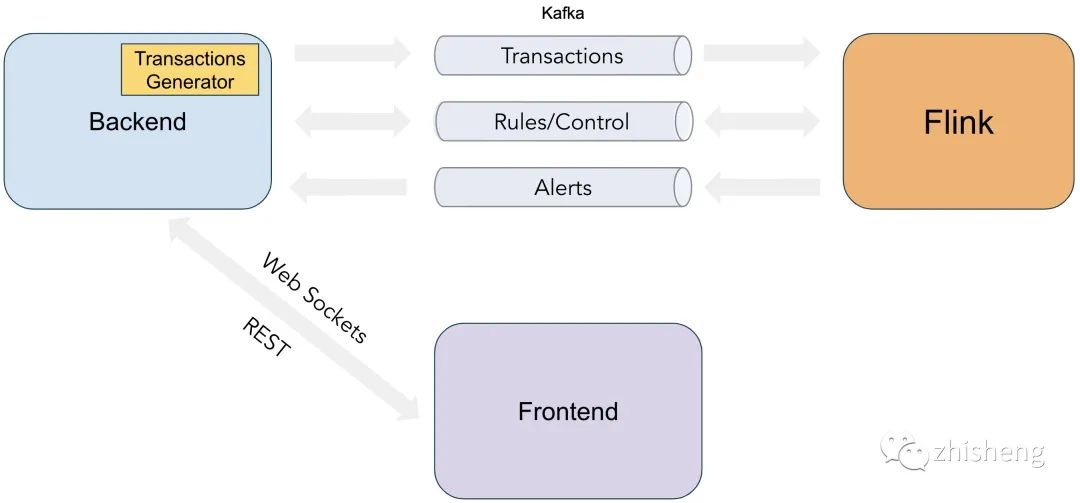
后端将 REST API 暴露给前端,用于创建/删除规则以及发出用于管理演示执行的控制命令,然后,它会将这些前端操作行为数据发送到 Kafka Topic Control 中。后端还包含了一个交易数据生成器组件,该组件用来模拟交易数据的,然后会将这些交易数据发送到 Kafka Topic Transactions 中,这些数据最后都会被 Flink 应用程序去消费,Flink 程序经过规则计算这些交易数据后生成的告警数据会发送到 Kafka Topic Alerts 中,并通过 Web Sockets 将数据传到前端 UI。
现在你已经熟悉了该欺诈检测引擎的总体结构和布局了,接下来我们详细介绍这个系统里面包含的内容。
数据动态分区
如果过去你曾经使用过 Flink DataStream API,那么你肯定很熟悉 keyBy 方法。对数据流中的所有数据按键进行 shuffle,这样具有相同 key 的元素就会被分配到相同的分区。
一般在程序中,数据分区的 keyBy 字段是固定的,由数据内的某些静态字段确定,例如,当构建一个简单的基于窗口的交易流聚合时,我们可能总是按照交易账户 ID 进行分组。
DataStream<Transaction> input = // [...]
DataStream<...> windowed = input
.keyBy(Transaction::getAccountId)
.window(/*window specification*/);
这种方法是在广泛的用例中实现水平可伸缩性的主要模块,但是在应用程序试图在运行时提供业务逻辑灵活性的情况下,这还是不够的。为了理解为什么会发生这种情况,让我们首先以功能需求的形式为欺诈检测系统阐明一个现实的样本规则定义:
在一个星期 之内,当 用户 A 累计 向 B 用户支付的金额超过 1000000 美元,则触发一条告警
PS:A 和 B 用字段描述的话分别是 付款人(payer)和受益人(beneficiary)
在上面的规则中,我们可以发现许多参数,我们希望能够在新提交的规则中指定这些参数,甚至可能在运行时进行动态的修改或调整:
-
聚合的字段(付款金额)
-
分组字段(付款人和受益人)
-
聚合函数(求和)
-
窗口大小(1 星期)
-
阈值(1000000)
-
计算符号(大于)
因此,我们将使用以下简单的 JSON 格式来定义上述参数:
{
"ruleId": 1,
"ruleState": "ACTIVE",
"groupingKeyNames": ["payerId", "beneficiaryId"],
"aggregateFieldName": "paymentAmount",
"aggregatorFunctionType": "SUM",
"limitOperatorType": "GREATER",
"limit": 1000000,
"windowMinutes": 10080
}
在这一点上,重要的是了解 groupingKeyNames 决定了数据的实际物理分区,所有指定参数(payerId + beneficiaryId)相同的交易数据都会汇总到同一个物理计算 operator 里面去。很明显,如果要实现这样的功能,在 Flink 里面是使用 keyBy 函数来完成。
Flink 官方文档中 keyBy() 函数的大多数示例都是使用硬编码的 KeySelector,它提取特定数据的字段。但是,为了支持所需的灵活性,我们必须根据规则中的规范以更加动态的方式提取它们,为此,我们将不得不使用一个额外的运算符,该运算符会将每条数据分配到正确的聚合实例中。
总体而言,我们的主要处理流程如下所示:
DataStream<Alert> alerts =
transactions
.process(new DynamicKeyFunction())
.keyBy(/* some key selector */);
.process(/* actual calculations and alerting */)
先前我们已经建立了每个规则定义一个**groupingKeyNames**参数,该参数指定将哪些字段组合用于传入事件的分组。每个规则可以使用这些字段的任意组合。同时,每个传入事件都可能需要根据多个规则进行评估。这意味着事件可能需要同时出现在计算 operator 的多个并行实例中,这些实例对应于不同的规则,因此需要进行分叉。确保此类事件的调度能达到 DynamicKeyFunction() 的目的。
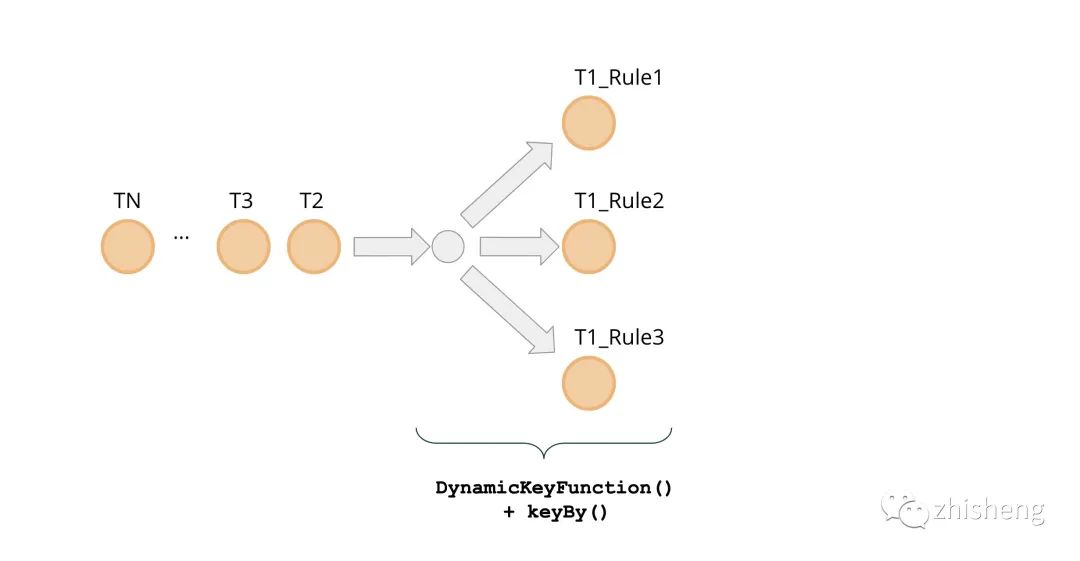
DynamicKeyFunction迭代一组已定义的规则,并通过 keyBy()函数提取所有数据所需的分组 key :
public class DynamicKeyFunction
extends ProcessFunction<Transaction, Keyed<Transaction, String, Integer>> {
...
/* Simplified */
List<Rule> rules = /* Rules that are initialized somehow.
Details will be discussed in a future blog post. */;
@Override
public void processElement(
Transaction event,
Context ctx,
Collector<Keyed<Transaction, String, Integer>> out) {
for (Rule rule :rules) {
out.collect(
new Keyed<>(
event,
KeysExtractor.getKey(rule.getGroupingKeyNames(), event),
rule.getRuleId()));
}
}
...
}
KeysExtractor.getKey()使用反射从数据中提取groupingKeyNames里面所有所需字段的值,并将它们拼接为字符串,例如"{payerId=25;beneficiaryId=12}"。Flink 将计算该字符串的哈希值,并将此特定组合的数据处理分配给集群中的特定服务器。这样就会跟踪付款人25和受益人12之间的所有交易,并在所需的时间范围内评估定义的规则。
注意,Keyed引入了具有以下签名的包装器类作为输出类型DynamicKeyFunction:
public class Keyed<IN, KEY, ID> {
private IN wrapped;
private KEY key;
private ID id;
...
public KEY getKey(){
return key;
}
}
此 POJO 的字段携带了以下信息:wrapped是原始数据,key是使用 KeysExtractor提取出来的结果,id是导致事件的调度规则的 ID(根据规则特定的分组逻辑)。
这种类型的事件将作为keyBy()函数的输入,并允许使用简单的 lambda 表达式作为KeySelector实现动态数据 shuffle 的最后一步。
DataStream<Alert> alerts =
transactions
.process(new DynamicKeyFunction())
.keyBy((keyed) -> keyed.getKey());
.process(new DynamicAlertFunction())
通过应用,DynamicKeyFunction我们隐式复制了事件,以便在 Flink 集群中并行的执行每个规则评估。通过这样做,我们获得了一个重要的功能——规则处理的水平可伸缩性。通过向集群添加更多服务器,即增加并行度,我们的系统将能够处理更多规则。实现此功能的代价是数据重复,这可能会成为一个问题,具体取决于一组特定的参数,例如传入数据速率,可用网络带宽,事件有效负载大小等。在实际情况下,可以进行其他优化应用,例如组合计算具有相同groupingKeyNames 的规则,或使用过滤层,将事件中不需要处理特定规则的所有字段删除。
总结
在此博客文章中,我们通过查看示例用例(欺诈检测引擎)讨论了如何对 Flink 应用程序进行动态,运行时更改。我们已经描述了总体项目结构及其组件之间的交互,并提供了使用 docker 进行构建和运行演示欺诈检测应用程序。然后,我们展示了将 数据动态分区 ,这是第一个实现灵活的动态配置的代码案例。
为了专注于描述本案例的核心机制,我们将 DSL 和基本规则引擎的复杂性降至最低。在未来,不难想象会添加一些扩展,例如允许使用更复杂的规则定义,包括某些事件的过滤,逻辑规则链接以及其他更高级的功能。
在本系列的第二篇博客中,我们将描述规则如何进入正在运行的欺诈检测引擎。此外,我们将详细介绍引擎的主要处理功能 DynamicAlertFunction() 的实现细节。
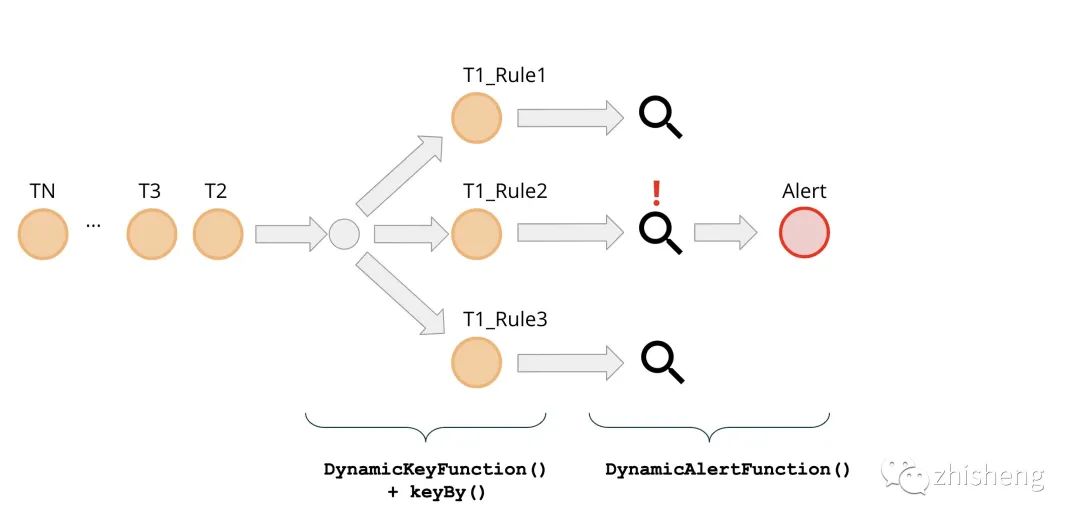
在下一篇文章中,我们会教大家如何利用 Apache Flink 的广播流在我们的欺诈检测系统中动态的处理规则。