、概述
我们先来看Flink官方文档的第一句话:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
有道翻译如下:
Apache Flink是一个框架和分布式处理引擎,用于***和有界数据流上的有状态计算。Flink被设计成可以在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。
这里要明确一点,Flink的流式处理可以是有状态的可以是无状态的,比如有些一些任务我只基于某个独立的数据进行计算,最简单的比如说从source端接收数据直接打印到控制台了,然后后面输出到sink,这种不依赖其他数据,这种根本就不涉及到状态,直接就是来一条数据处理一条数据,这个应该比较好理解。
之前我们说过大多数的流应用都是有状态的,Flink执行计算任务的过程中,从source端到sink端中间会有很多的operator,中间会存在多个临时状态,如果任务的某个task挂掉,那它在内存中的状态都会丢失,如果我们中间没有存储中间状态的话,需要从头开始计算,如果我们存储了中间状态,就可以恢复到中间状态,从该状态继续计算,而不是从头开始计算 ;Flink就设计了一种机制来保存任务执行的中间状态,就是状态管理机制。
例如,经典的wordcount程序,task不断的从source端接收数据,处理数据之前,task先去访问state,获取该单词当前的count数,加1后再更新state,并将新的计算结果输出。下面这个图就展示了flink的task如何和state进行交互。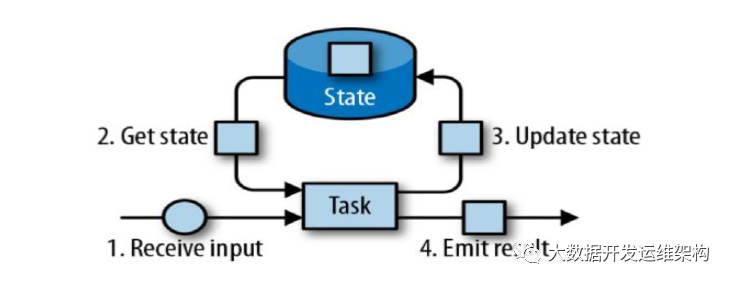
哪些场景需要状态计算呢?下面是我整理了一些典型场景:
a.数据增量统计;
b.聚合操作;
c.机器学习训练模型迭代运算时保存当前模型;
d.Job故障重启,需要从之前的状态恢复;
e.数据记录去重;
f.历史数据的比对。
二、状态分类
在讲解Flink的状态分类之前我们需要先区分几个概念:
1).State 状态
State一般指一个具体的task/operator的状态,Flink为了保证计算过程中出现异常进行数据恢复,就将中间结果存储起来,这个中间结果就是State,默认情况下,State保存在Jobmanager的内存中,也可以保存在TaskManager本地磁盘或HDFS分布式文件系统。
2).State Backend 状态后端
State是如何准确的存储、访问、以及维护是由一个可插拔的组件决定的,这个组件称为状态后端(State backend),一个state backend负责两件事:本地state管理,以及为state做检查点并存储到外部地址。
3).Checkpoint 检查点
Checkpoint是指在某个特定的时刻下,对整个job一个全局的快照,当我们遇到故障或者重启的时候可以从备份中进行恢复。
按照数据的划分和扩张方式,在Flink中有两种类型的state:operator state和keyed state:
1.operator state 算子状态 作用范围限定为算子任务,一个任务一个状态
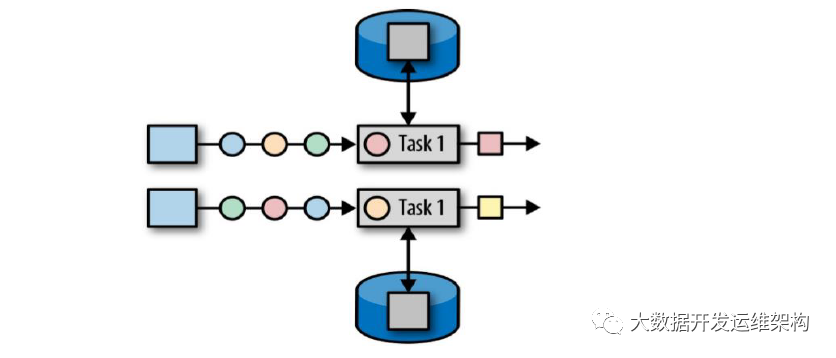
算子状态的作用范围限定为算子任务,由同一并行子任务所处理的所有数据都可以访问到相同的状态;
算子状态对于同一个任务而言是共享的(每一个并行的子任务共享一个状态);
算子状态不能由相同或不同算子的另一个任务访问(相同算子的不同任务之间也不能访问);
operator state提供了三种原型:
List state
以list的方式表示state
Union list state
同样以list的方式表示state。但是它与常规list state的不同点在于:发生故障时恢复的方式、或一个application从检查点开始的方式。
Broadcast state
被用于特殊场景,当一个operator的每个task的state都是相同时。这个属性可以被用于检查点,或是rescaling 一个 operator时。
2.keyed state
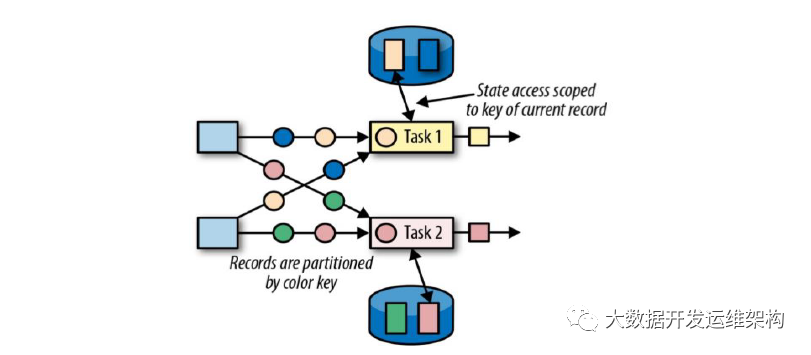
键控状态是基于KeyStream之上的状态,keyBy之后的Operator State。
键控状态是根据输入数据流中定义的键(key)来维度和访问状态的;
Flink为每个key维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态;
当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key;
keyed state提供了三种原型:
Value state
为每个key存一个单值(可以是任意类型)。复杂的数据结构也可以作为value state 存储;
List state
为每个key存一个列表值。这个列表可以是任意类型;
Map state
为每个key存一个key-value 映射。映射中的key和value可以是任意类型。
三、状态存在形式
Keyed State和Operator State,可以以两种形式存在:原始状态和托管状态。
托管方式就是状态管理由flink提供的框架进行管理,通过flink状态管理框架提供的接口,来更新和管理状态的值。这里面包括用于存储状态数据的数据结构,现成的包装类等。
原始方式就是由用户自行管理状态具体的数据结构,框架在做checkpoint的时候(checkpoint是flink进行状态数据持久化存储的机制),使用byte[]来读写状态内容,对其内部数据结构一无所知。
通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态。一般来说,托管状态用的比较多。
这里结合我自己的理解,结合视频和网络上的东西给大家整理了一些概念性的东西,感谢关注!!!