正则表达式–简单爬虫实例–4K美女篇
文章目录
section1:声明
自己的学习笔记,爬取内容不会用于商业
section2:下载链接分析
首先,我们要找到我们想要爬取的详情页 4K美女

这里的图片就是我们想要的目标。
接下来,我们需要看一下这个页面的源代码进行进一步的分析。(可以选择右击检查或者使用快捷键Ctrl+Shift+I)
以第一张图片为例(代码如下):

出现了源文件标签src,我们就想去拿它后面的内容然后和‘http://pic.netbian.com’部分整和成一个链接,但是如果你提前是网页上去试的话,会出现这个结果。
(为啥是和http://pic.netbian.com这个部分整和呢,因为这是网站首页链接,哈哈哈)

是一张缩略图,不是我们想要的高清大图。
我们再仔细看一下,源文件标签上面还有一个超链接标签,点一下,来到了这个页面:

那我们就再对这个页面进行检查一次好了。

又发现了一个源文件,那我们再和‘http://pic.netbian.com’组合一下试试!

ohhhhhh,是我们想要的高清大图!
那么接下来就是理清思路,开始爬虫吧!
section3:代码编写
1、导入板块
import requests
import re
import os
2、构造请求
headers = {
'user - agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.116Safari / 537.36'
}
url='http://pic.netbian.com/4kmeinv/'
response_1=requests.get(url=url,headers=headers)
html_1=response_1.text
对于Requests库的学习,我之前整理过一点点(当时还不会写,有点点乱)
3、正则表达式的构造
因为我们从详情页到高清图,中间要先去另一个页面,所以我们构造的第一个正则表达式,是去另一个页面的。

我们需要的是超链接标签href后面的内容,于是正则表达式可以这样写:
<a.*?href.+?(/tupian.+?html)
正则表达式的常见符号,可以参考 正则表达式——常用的匹配规则
4、数据处理
构造完毕,我们就需要把这些数据取出来
image_urls=re.findall('<a.*?href.+?(/tupian.+?html)',html_1,re.S)
我们可以打印一下,看一看结果
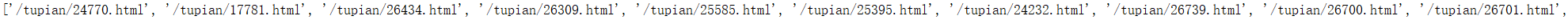
我们可以看到是一个列表,re.findall拿到的结果是一个结果,这里需要注意一下。所以,我们要对这个结果进行遍历,以便我们使用。
for image_url in image_urls:
picture_urls = 'http://pic.netbian.com' + image_url
因为提取到的结果不是一个完整的链接,所以我在遍历的时候,顺便给补全了。然后我们打印一下,看结果。
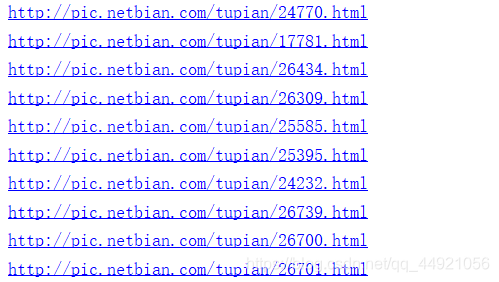
出现了,是一系列的链接,点击第一个,刚刚好是我们刚刚查看的那个,说明我们成功了。
接着,重复上面步骤对这个页面进行分析、提取数据
for image_url in image_urls:
picture_urls = 'http://pic.netbian.com' + image_url
# print(picture_urls)
response_2 = requests.get(url=picture_urls, headers=headers)
html_2 = response_2.text
pictures = re.findall('<div.*?photo-pic.*?<img src="(/uploads.+?jpg).*?alt.+?"(.*?)"', html_2, re.S)
这里的正则表达式,我再构建的时候,提取的内容为源文件及alt后面的内容

for picture in pictures:
picture_url = picture[0]
picture_src = 'http://pic.netbian.com' + picture_url#高清图的源文件链接
picture_name = picture[1] + '.jpg'#构建准备保存的图片的名称
picture_name = picture_name.encode('iso-8859-1').decode('gbk')#这里是防止图片名称出现乱码的情况
5、保存数据
首先,我们要创建一个文件夹
if not os.path.exists('D:/4K美女'):
os.mkdir('D:/4K美女')
其次,对于我们拿到的数据做最后的处理
picture_data = requests.get(url=picture_src, headers=headers).content#写入文件的内容——也就是想要的高清大图啦
picture_path = 'D:/4K美女/' + picture_name#构建图片存储路径
最后,写入文件,进行保存收尾
with open(picture_path, 'wb') as f:
f.write(picture_data)
print(picture_path, '下载完成')
6、完整代码
import requests
import re
import os
#创建文件夹
if not os.path.exists('D:/4K美女'):
os.mkdir('D:/4K美女')
headers = {
'user - agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.116Safari / 537.36'
}
url='http://pic.netbian.com/4kmeinv/'
response_1=requests.get(url=url,headers=headers)
html_1=response_1.text
image_urls=re.findall('<a.*?href.+?(/tupian.+?html)',html_1,re.S)
# print(image_urls)
for image_url in image_urls:
picture_urls = 'http://pic.netbian.com' + image_url
# print(picture_urls)
response_2 = requests.get(url=picture_urls, headers=headers)
html_2 = response_2.text
pictures = re.findall('<div.*?photo-pic.*?<img src="(/uploads.+?jpg).*?alt.+?"(.*?)"', html_2, re.S)
for picture in pictures:
picture_url = picture[0]
picture_src = 'http://pic.netbian.com' + picture_url#高清图的源文件链接
picture_name = picture[1] + '.jpg'#构建准备保存的图片的名称
picture_name = picture_name.encode('iso-8859-1').decode('gbk')#这里是防止图片名称出现乱码的情况
picture_data = requests.get(url=picture_src, headers=headers).content#写入文件的内容——也就是想要的高清大图啦
picture_path = 'D:/4K美女/' + picture_name#构建图片存储路径
# 保存图片
with open(picture_path, 'wb') as f:
f.write(picture_data)
print(picture_path, '下载完成')
section4:补充(多页爬取)
如果想进行多页爬取,只需要给第一个url做一下for循环处理,即:
for i in range(2,5):
url='http://pic.netbian.com/4kmeinv/index_{}.html'.format(i)
response_1=requests.get(url=url,headers=headers)
html_1=response_1.text
那么开冲吧!!!!!
这是我第一次完成一个爬虫实例,感觉我写的不错的小伙伴,可否给个赞支持一下呢,嘿嘿。
我知道,我可能有一些地方用语不是很规范,也希望能有大佬对我进行一些建议。