6.Flink Table&SQL
1. Table API & SQL 介绍
1.1 为什么需要Table API & SQL
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/
Table API & SQL的特点
Flink之所以选择将 Table API & SQL 作为未来的核心 API,是因为其具有一些非常重要的特点:

- 声明式:属于设定式语言,用户只要表达清楚需求即可,不需要了解底层执行;
- 高性能:可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划;
- 简单易学:易于理解,不同行业和领域的人都懂,学习成本较低;
- 标准稳定:语义遵循SQL标准,非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少;
- 流批统一:可以做到API层面上流与批的统一,相同的SQL逻辑,既可流模式运行,也可批模式运行,Flink底层Runtime本身就是一个流与批统一的引擎
Flink的Table模块包括 Table API 和 SQL:
Table API 是一种类SQL的API,通过Table API,用户可以像操作表一样操作数据,非常直观和方便
SQL作为一种声明式语言,有着标准的语法和规范,用户可以不用关心底层实现即可进行数据的处理,非常易于上手
Flink Table API 和 SQL 的实现上有80%左右的代码是公用的。作为一个流批统一的计算引擎,Flink 的 Runtime 层是统一的。
1.2 Table API& SQL发展历程
架构升级
自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。随着版本的不断更新,API 也出现了很多不兼容的地方。
在 Flink 1.9 中,Table 模块迎来了核心架构的升级,引入了阿里巴巴Blink团队贡献的诸多功能
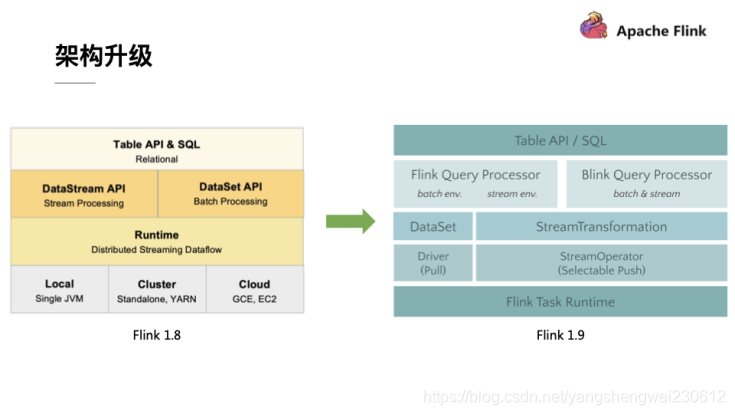
在Flink 1.9 之前,Flink API 层 一直分为DataStream API 和 DataSet API,Table API & SQL 位于 DataStream API 和 DataSet API 之上。可以看处流处理和批处理有各自独立的api (流处理DataStream,批处理DataSet)。而且有不同的执行计划解析过程,codegen过程也完全不一样,完全没有流批一体的概念,面向用户不太友好。
在Flink1.9之后新的架构中,有两个查询处理器:Flink Query Processor,也称作Old Planner和Blink Query Processor,也称作Blink Planner。为了兼容老版本Table及SQL模块,插件化实现了Planner,Flink原有的Flink Planner不变,后期版本会被移除。新增加了Blink Planner,新的代码及特性会在Blink planner模块上实现。批或者流都是通过解析为Stream Transformation来实现的,不像Flink Planner,批是基于Dataset,流是基于DataStream。
查询处理器的选择
查询处理器是 Planner 的具体实现,通过parser、optimizer、codegen(代码生成技术)等流程将 Table API & SQL作业转换成 Flink Runtime 可识别的 Transformation DAG,最终由 Flink Runtime 进行作业的调度和执行。
Flink Query Processor查询处理器针对流计算和批处理作业有不同的分支处理,流计算作业底层的 API 是 DataStream API, 批处理作业底层的 API 是 DataSet API
Blink Query Processor查询处理器则实现流批作业接口的统一,底层的 API 都是Transformation,这就意味着我们和Dataset完全没有关系了
Flink1.11之后Blink Query Processor查询处理器已经是默认的了
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/
了解-Blink planner和Flink Planner具体区别如下:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/common.html

1.3 注意:
https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/common.html
API稳定性

性能对比
注意:目前FlinkSQL性能不如SparkSQL,未来FlinkSQL可能会越来越好
下图是Hive、Spark、Flink的SQL执行速度对比:

2. 案例准备
2.1 依赖
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- flink执行计划,这是1.9版本之前的-->
<!-- <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!-- blink执行计划,1.11+默认的-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
flink-table-common:这个包中主要是包含 Flink Planner 和 Blink Planner一些共用的代码。
● flink-table-api-java:这部分是用户编程使用的 API,包含了大部分的 API。
● flink-table-api-scala:这里只是非常薄的一层,仅和 Table API 的 Expression 和 DSL 相关。
● 两个 Planner:flink-table-planner 和 flink-table-planner-blink。
● 两个 Bridge:flink-table-api-scala-bridge 和 flink-table-api-java-bridge,
Flink Planner 和 Blink Planner 都会依赖于具体的 JavaAPI,也会依赖于具体的 Bridge,通过 Bridge 可以将 API 操作相应的转化为Scala 的 DataStream、DataSet,或者转化为 JAVA 的 DataStream 或者Data Set
2.2 程序结构
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/common.html#structure-of-table-api-and-sql-programs

// create a TableEnvironment for specific planner batch or streaming
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// create a Table
tableEnv.connect(...).createTemporaryTable("table1");
// register an output Table
tableEnv.connect(...).createTemporaryTable("outputTable");
// create a Table object from a Table API query
Table tapiResult = tableEnv.from("table1").select(...);
// create a Table object from a SQL query
Table sqlResult = tableEnv.sqlQuery("SELECT ... FROM table1 ... ");
// emit a Table API result Table to a TableSink, same for SQL result
TableResult tableResult = tapiResult.executeInsert("outputTable");
tableResult...
2.3 SQL API
2.3.1 获取环境
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/common.html#create-a-tableenvironment
// **********************
// FLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
// or TableEnvironment fsTableEnv = TableEnvironment.create(fsSettings);
// ******************
// FLINK BATCH QUERY
// ******************
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.BatchTableEnvironment;
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
// **********************
// BLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
// or TableEnvironment bsTableEnv = TableEnvironment.create(bsSettings);
// ******************
// BLINK BATCH QUERY
// ******************
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment bbTableEnv = TableEnvironment.create(bbSettings);
2.3.2 创建表
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// table is the result of a simple projection query
Table projTable = tableEnv.from("X").select(...);
// register the Table projTable as table "projectedTable"
tableEnv.createTemporaryView("projectedTable", projTable);
tableEnvironment
.connect(...)
.withFormat(...)
.withSchema(...)
.inAppendMode()
.createTemporaryTable("MyTable")
2.3.3 查询表
Table API
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register Orders table
// scan registered Orders table
Table orders = tableEnv.from("Orders");// compute revenue for all customers from France
Table revenue = orders
.filter($("cCountry")
.isEqual("FRANCE"))
.groupBy($("cID"), $("cName")
.select($("cID"), $("cName"), $("revenue")
.sum()
.as("revSum"));
// emit or convert Table
// execute query
SQL
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register Orders table
// compute revenue for all customers from France
Table revenue = tableEnv.sqlQuery(
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);
// emit or convert Table
// execute query
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register "Orders" table
// register "RevenueFrance" output table
// compute revenue for all customers from France and emit to "RevenueFrance"
tableEnv.executeSql(
"INSERT INTO RevenueFrance " +
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);
2.3.4 写出表
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// create an output Table
final Schema schema = new Schema()
.field("a", DataTypes.INT())
.field("b", DataTypes.STRING())
.field("c", DataTypes.BIGINT());
tableEnv.connect(new FileSystem().path("/path/to/file"))
.withFormat(new Csv().fieldDelimiter('|').deriveSchema())
.withSchema(schema)
.createTemporaryTable("CsvSinkTable");
// compute a result Table using Table API operators and/or SQL queries
Table result = ...
// emit the result Table to the registered TableSink
result.executeInsert("CsvSinkTable");
2.3.5 与DataSet/DataStream集成
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/common.html#integration-with-datastream-and-dataset-api
Create a View from a DataStream or DataSet

// get StreamTableEnvironment
// registration of a DataSet in a BatchTableEnvironment is equivalent
StreamTableEnvironment tableEnv = ...;
// see "Create a TableEnvironment" section
DataStream<Tuple2<Long, String>> stream = ...
// register the DataStream as View "myTable" with fields "f0", "f1"
tableEnv.createTemporaryView("myTable", stream);
// register the DataStream as View "myTable2" with fields "myLong", "myString"
tableEnv.createTemporaryView("myTable2", stream, $("myLong"), $("myString"));
Convert a DataStream or DataSet into a Table
// get StreamTableEnvironment// registration of a DataSet in a BatchTableEnvironment is equivalent
StreamTableEnvironment tableEnv = ...;
// see "Create a TableEnvironment" section
DataStream<Tuple2<Long, String>> stream = ...
// Convert the DataStream into a Table with default fields "f0", "f1"
Table table1 = tableEnv.fromDataStream(stream);
// Convert the DataStream into a Table with fields "myLong", "myString"
Table table2 = tableEnv.fromDataStream(stream, $("myLong"), $("myString"));
Convert a Table into a DataStream or DataSet
Convert a Table into a DataStream
Append Mode: This mode can only be used if the dynamic Table is only modified by INSERT changes, i.e, it is append-only and previously emitted results are never updated.
追加模式:只有当动态表仅通过插入更改进行修改时,才能使用此模式,即,它是仅追加模式,并且以前发出的结果从不更新。
Retract Mode: This mode can always be used. It encodes INSERT and DELETE changes with a boolean flag.
撤回模式:此模式始终可用。它使用布尔标志对插入和删除更改进行编码。
// get StreamTableEnvironment.
StreamTableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// Table with two fields (String name, Integer age)
Table table = ...
// convert the Table into an append DataStream of Row by specifying the class
DataStream<Row> dsRow = tableEnv.toAppendStream(table, Row.class);
// convert the Table into an append DataStream of Tuple2<String, Integer>
// via a TypeInformation
TupleTypeInfo<Tuple2<String, Integer>> tupleType = new TupleTypeInfo<>(
Types.STRING(),
Types.INT());
DataStream<Tuple2<String, Integer>> dsTuple =
tableEnv.toAppendStream(table, tupleType);
// convert the Table into a retract DataStream of Row.
// A retract stream of type X is a DataStream<Tuple2<Boolean, X>>.
// The boolean field indicates the type of the change.
// True is INSERT, false is DELETE.
DataStream<Tuple2<Boolean, Row>> retractStream =
tableEnv.toRetractStream(table, Row.class);
Convert a Table into a DataSet
// get BatchTableEnvironment
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
// Table with two fields (String name, Integer age)
Table table = ...
// convert the Table into a DataSet of Row by specifying a class
DataSet<Row> dsRow = tableEnv.toDataSet(table, Row.class);
// convert the Table into a DataSet of Tuple2<String, Integer> via a TypeInformationTupleTypeInfo<Tuple2<String, Integer>> tupleType = new TupleTypeInfo<>(
Types.STRING(),
Types.INT());
DataSet<Tuple2<String, Integer>> dsTuple =
tableEnv.toDataSet(table, tupleType);
2.3.6 TableAPI
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/tableApi.html
2.3.7 SQLAPI
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/sql/
2.4 相关概念
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/streaming/dynamic_tables.html
2.4.1 Dynamic Tables & Continuous Queries
在Flink中,它把针对无界流的表称之为Dynamic Table(动态表)。它是Flink Table API和SQL的核心概念。顾名思义,它表示了Table是不断变化的。
我们可以这样来理解,当我们用Flink的API,建立一个表,其实把它理解为建立一个逻辑结构,这个逻辑结构需要映射到数据上去。Flink source源源不断的流入数据,就好比每次都往表上新增一条数据。表中有了数据,我们就可以使用SQL去查询了。要注意一下,流处理中的数据是只有新增的,所以看起来数据会源源不断地添加到表中。
动态表也是一种表,既然是表,就应该能够被查询。我们来回想一下原先我们查询表的场景。
打开编译工具,编写一条SQL语句
将SQL语句放入到mysql的终端执行
查看结果
再编写一条SQL语句
再放入到终端执行
再查看结果
……如此反复
而针对动态表,Flink的source端肯定是源源不断地会有数据流入,然后我们基于这个数据流建立了一张表,再编写SQL语句查询数据,进行处理。这个SQL语句一定是不断地执行的。而不是只执行一次。注意:针对流处理的SQL绝对不会像批式处理一样,执行一次拿到结果就完了。而是会不停地执行,不断地查询获取结果处理。所以,官方给这种查询方式取了一个名字,叫Continuous Query,中文翻译过来叫连续查询。而且每一次查询出来的数据也是不断变化的。
动态表/无界表

连续查询/需要借助State

这是一个非常简单的示意图。该示意图描述了:我们通过建立动态表和连续查询来实现在无界流中的SQL操作。大家也可以看到,在Continuous上面有一个State,表示查询出来的结果会存储在State中,再下来Flink最终还是使用流来进行处理。
所以,我们可以理解为Flink的Table API和SQL,是一个逻辑模型,通过该逻辑模型可以让我们的数据处理变得更加简单。
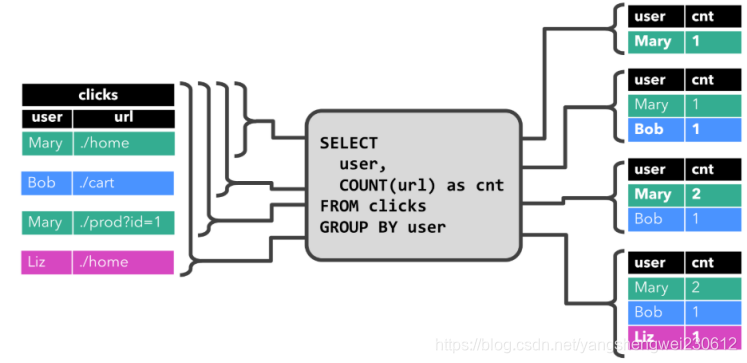
3. 案例1
3.1 需求
将DataStream注册为Table和View并进行SQL统计
代码实现
将DataStream数据转Table和View然后使用sql进行统计查询
注意:表中内容不能直接打印出来,需要转为datastream打印输出
package cn.itcast.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Arrays;
import static org.apache.flink.table.api.Expressions.$;
/**
* Author itcast
* Desc 演示Flink Table&SQL 案例- 将DataStream数据转Table和View然后使用sql进行统计查询
*/
public class Demo01 {
public static void main(String[] args) throws Exception {
//TODO 0.env (创建表环境)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
//TODO 1.source
DataStream<Order> orderA = env.fromCollection(Arrays.asList(
new Order(1L, "beer", 3),
new Order(1L, "diaper", 4),
new Order(3L, "rubber", 2)));
DataStream<Order> orderB = env.fromCollection(Arrays.asList(
new Order(2L, "pen", 3),
new Order(2L, "rubber", 3),
new Order(4L, "beer", 1)));
//TODO 2.transformation
// 将DataStream数据转Table,然后查询
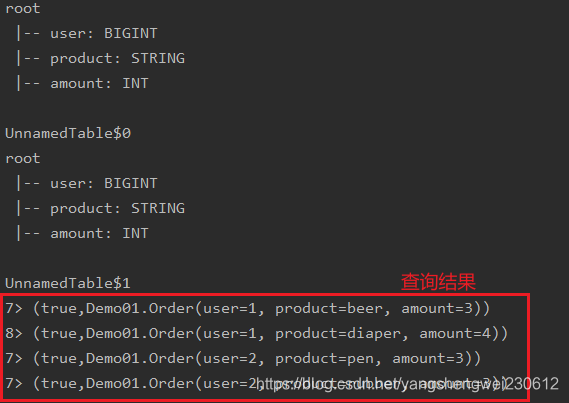
Table tableA = tenv.fromDataStream(orderA, $("user"), $("product"), $("amount"));
tableA.printSchema();
System.out.println(tableA);
//将DataStream数据转View,然后查询,表名为tableB
tenv.createTemporaryView("tableB", orderB, $("user"), $("product"), $("amount"));
//查询:tableA中amount>2的和tableB中amount>1的数据最后合并
/*
select * from tableA where amount > 2
union
select * from tableB where amount > 1
*/
String sql = "select * from "+tableA+" where amount > 2 \n" +
"union \n" +
" select * from tableB where amount > 1";
Table resultTable = tenv.sqlQuery(sql);
resultTable.printSchema();
System.out.println(resultTable);//UnnamedTable$1
//将Table转为DataStream
//DataStream<Order> resultDS = tenv.toAppendStream(resultTable, Order.class);//union all使用toAppendStream
DataStream<Tuple2<Boolean, Order>> resultDS = tenv.toRetractStream(resultTable, Order.class);//union使用toRetractStream
//toAppendStream → 将计算后的数据append到结果DataStream中去
//toRetractStream → 将计算后的新的数据在DataStream原数据的基础上更新true或是删除false
//类似StructuredStreaming中的append/update/complete
//TODO 3.sink
resultDS.print();
//TODO 4.execute
env.execute();
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Order {
public Long user;
public String product;
public int amount;
}
}
4. 案例2
4.1 需求
使用SQL和Table两种方式对DataStream中的单词进行统计
4.2 代码实现-SQL
package cn.itcast.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
/**
* Author itcast
* Desc 演示Flink Table&SQL 案例- 使用SQL和Table两种方式做WordCount
*/
public class Demo02 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
//TODO 1.source
DataStream<WC> wordsDS = env.fromElements(
new WC("Hello", 1),
new WC("World", 1),
new WC("Hello", 1)
);
//TODO 2.transformation
//将DataStream转为View或Table,表名为t_words
tenv.createTemporaryView("t_words", wordsDS,$("word"), $("frequency"));
/*
select word,sum(frequency) as frequency
from t_words
group by word
*/
String sql = "select word,sum(frequency) as frequency\n " +
"from t_words\n " +
"group by word";
//执行sql
Table resultTable = tenv.sqlQuery(sql);
//Table转为DataStream
DataStream<Tuple2<Boolean, WC>> resultDS = tenv.toRetractStream(resultTable, WC.class);
//toAppendStream → 将计算后的数据append到结果DataStream中去
//toRetractStream → 将计算后的新的数据在DataStream原数据的基础上更新true或是删除false
//类似StructuredStreaming中的append/update/complete
//TODO 3.sink
resultDS.print();
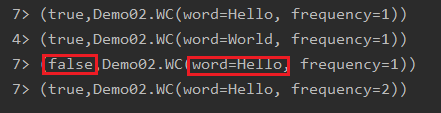
//new WC("Hello", 1),
//new WC("World", 1),
//new WC("Hello", 1)
//输出结果
//(true,Demo02.WC(word=Hello, frequency=1))
//(true,Demo02.WC(word=World, frequency=1))
//(false,Demo02.WC(word=Hello, frequency=1))
//(true,Demo02.WC(word=Hello, frequency=2))
//TODO 4.execute
env.execute();
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class WC {
public String word;
public long frequency;
}
}
4.3 代码实现-table风格(了解)
package cn.itcast.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
/**
* Author itcast
* Desc 演示Flink Table&SQL 案例- 使用SQL和Table两种方式做WordCount
*/
public class Demo02_2 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
//TODO 1.source
DataStream<WC> wordsDS = env.fromElements(
new WC("Hello", 1),
new WC("World", 1),
new WC("Hello", 1)
);
//TODO 2.transformation
//将DataStream转为View或Table
Table table = tenv.fromDataStream(wordsDS);
//使用table风格查询/DSL
Table resultTable = table
.groupBy($("word"))
.select($("word"), $("frequency").sum().as("frequency"))
.filter($("frequency").isEqual(2));
//转换为DataStream
DataStream<Tuple2<Boolean, WC>> resultDS = tenv.toRetractStream(resultTable, WC.class);
//TODO 3.sink
resultDS.print();
//TODO 4.execute
env.execute();
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class WC {
public String word;
public long frequency;
}
}

5. 案例3
5.1 需求
使用Flink SQL来统计5秒内 每个用户的 订单总数、订单的最大金额、订单的最小金额
也就是每隔5秒统计最近5秒的每个用户的订单总数、订单的最大金额、订单的最小金额
上面的需求使用流处理的Window的基于时间的滚动窗口就可以搞定!
那么接下来使用FlinkTable&SQL-API来实现
5.2 编码步骤
1.创建环境
2.使用自定义函数模拟实时流数据
3.设置事件时间和Watermaker
4.注册表
5.执行sql-可以使用sql风格或table风格(了解)
6.输出结果
7.触发执行
5.3 代码实现-方式1 sql风格
查询sql
/*
select userId, count(orderId) as orderCount, max(money) as maxMoney,min(money) as minMoney
from t_order
group by userId,
//窗口语法,每隔5秒统计最近5秒
tumble(createTime, INTERVAL '5' SECOND)
*/
package cn.itcast.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.time.Duration;
import java.util.Random;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import static org.apache.flink.table.api.Expressions.$;
/**
* Author itcast
* Desc 演示Flink Table&SQL 案例- 使用事件时间+Watermaker+window完成订单统计
*/
public class Demo03 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
//TODO 1.source
DataStreamSource<Order> orderDS = env.addSource(new RichSourceFunction<Order>() {
private Boolean isRunning = true;
@Override
public void run(SourceContext<Order> ctx) throws Exception {
Random random = new Random();
while (isRunning) {
Order order = new Order(UUID.randomUUID().toString(), random.nextInt(3), random.nextInt(101), System.currentTimeMillis());
TimeUnit.SECONDS.sleep(1);
ctx.collect(order);
}
}
@Override
public void cancel() {
isRunning = false;
}
});
//TODO 2.transformation
//需求:事件时间+Watermarker+FlinkSQL和Table的window完成订单统计
DataStream<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((order, recordTimestamp) -> order.getCreateTime())
);
//将DataStream-->View/Table,注意:指定列的时候需要指定哪一列是时间
tenv.createTemporaryView("t_order",orderDSWithWatermark,$("orderId"), $("userId"), $("money"), $("createTime").rowtime());
/*
select userId, count(orderId) as orderCount, max(money) as maxMoney,min(money) as minMoney
from t_order
group by userId,
//窗口语法,每隔5秒统计最近5秒
tumble(createTime, INTERVAL '5' SECOND)
*/
String sql = "select userId, count(orderId) as orderCount, max(money) as maxMoney,min(money) as minMoney\n " +
"from t_order\n " +
"group by userId,\n " +
"tumble(createTime, INTERVAL '5' SECOND)";
//执行sql
Table resultTable = tenv.sqlQuery(sql);
//table转DataStream
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultTable, Row.class);
//TODO 3.sink
resultDS.print();
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Order {
private String orderId;
private Integer userId;
private Integer money;
private Long createTime;//事件时间
}
}
toAppendStream → 将计算后的数据append到结果DataStream中去
toRetractStream → 将计算后的新的数据在DataStream原数据的基础上更新true或是删除false
5.4 代码实现-方式2 table风格(了解)
package cn.itcast.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.time.Duration;
import java.util.Random;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
/**
* Author itcast
* Desc 演示Flink Table&SQL 案例- 使用事件时间+Watermaker+window完成订单统计-Table风格
*/
public class Demo03_2 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
//TODO 1.source
DataStreamSource<Order> orderDS = env.addSource(new RichSourceFunction<Order>() {
private Boolean isRunning = true;
@Override
public void run(SourceContext<Order> ctx) throws Exception {
Random random = new Random();
while (isRunning) {
Order order = new Order(UUID.randomUUID().toString(), random.nextInt(3), random.nextInt(101), System.currentTimeMillis());
TimeUnit.SECONDS.sleep(1);
ctx.collect(order);
}
}
@Override
public void cancel() {
isRunning = false;
}
});
//TODO 2.transformation
//需求:事件时间+Watermarker+FlinkSQL和Table的window完成订单统计
DataStream<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((order, recordTimestamp) -> order.getCreateTime())
);
//将DataStream-->View/Table,注意:指定列的时候需要指定哪一列是时间
tenv.createTemporaryView("t_order",orderDSWithWatermark,$("orderId"), $("userId"), $("money"), $("createTime").rowtime());
//Table table = tenv.fromDataStream(orderDSWithWatermark, $("orderId"), $("userId"), $("money"), $("createTime").rowtime());
//table.groupBy().select();
//table查询风格
Table resultTable = tenv.from("t_order")
.window(Tumble.over(lit(5).second())
.on($("createTime"))
.as("tumbleWindow"))
.groupBy($("tumbleWindow"), $("userId"))
.select(
$("userId"),
$("orderId").count().as("orderCount"),
$("money").max().as("maxMoney"),
$("money").min().as("minMoney")
);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultTable, Row.class);
//TODO 3.sink
resultDS.print();
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Order {
private String orderId;
private Integer userId;
private Integer money;
private Long createTime;//事件时间
}
}

6. 案例4
6.1 需求
从Kafka中消费数据并过滤出状态为success的数据再写入到Kafka
{
"user_id": "1", "page_id":"1", "status": "success"}
{
"user_id": "1", "page_id":"1", "status": "success"}
{
"user_id": "1", "page_id":"1", "status": "success"}
{
"user_id": "1", "page_id":"1", "status": "success"}
{
"user_id": "1", "page_id":"1", "status": "fail"}
/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 2 --partitions 3 --topic input_kafka
/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 2 --partitions 3 --topic output_kafka
/export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic input_kafka
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic output_kafka --from-beginning
链接kafka获取的到的数据直接会转为表

<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
6.2 代码实现
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/kafka.html
package cn.itcast.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* Author itcast
* Desc 演示Flink Table&SQL 案例- 从Kafka:input_kafka主题消费数据并生成Table,然后过滤出状态为success的数据再写回到Kafka:output_kafka主题
*/
public class Demo04 {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
//TODO 1.source
TableResult inputTable = tenv.executeSql(
"CREATE TABLE input_kafka (\n" +
" `user_id` BIGINT,\n" +
" `page_id` BIGINT,\n" +
" `status` STRING\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'input_kafka',\n" +
" 'properties.bootstrap.servers' = 'node1:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json'\n" +
")"
);
//TODO 2.transformation
//编写sql过滤出状态为success的数据
String sql = "select * from input_kafka where status='success'";
Table etlResult = tenv.sqlQuery(sql);
//TODO 3.sink
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(etlResult, Row.class);
resultDS.print();
TableResult outputTable = tenv.executeSql(
"CREATE TABLE output_kafka (\n" +
" `user_id` BIGINT,\n" +
" `page_id` BIGINT,\n" +
" `status` STRING\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'output_kafka',\n" +
" 'properties.bootstrap.servers' = 'node1:9092',\n" +
" 'format' = 'json',\n" +
" 'sink.partitioner' = 'round-robin'\n" +
")"
);
tenv.executeSql("insert into output_kafka select * from "+ etlResult);
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Order {
private String orderId;
private Integer userId;
private Integer money;
private Long createTime;//事件时间
}
}
//准备kafka主题
///export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 2 --partitions 3 --topic input_kafka
///export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 2 --partitions 3 --topic output_kafka
///export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic input_kafka
//{"user_id": "1", "page_id":"1", "status": "success"}
//{"user_id": "1", "page_id":"1", "status": "success"}
//{"user_id": "1", "page_id":"1", "status": "success"}
//{"user_id": "1", "page_id":"1", "status": "success"}
//{"user_id": "1", "page_id":"1", "status": "fail"}
///export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic output_kafka --from-beginning
7. 总结-Flink-SQL常用算子
7.1 SELECT
SELECT 用于从 DataSet/DataStream 中选择数据,用于筛选出某些列。
示例:
SELECT * FROM Table;// 取出表中的所有列
SELECT name,age FROM Table;// 取出表中 name 和 age 两列
与此同时 SELECT 语句中可以使用函数和别名,例如我们上面提到的 WordCount 中:
SELECT word, COUNT(word) FROM table GROUP BY word;
7.2 WHERE
WHERE 用于从数据集/流中过滤数据,与 SELECT 一起使用,用于根据某些条件对关系做水平分割,即选择符合条件的记录。
示例:
SELECT name,age FROM Table where name LIKE ‘% 小明 %’;
SELECT * FROM Table WHERE age = 20;
WHERE 是从原数据中进行过滤,那么在 WHERE 条件中,Flink SQL 同样支持 =、<、>、<>、>=、<=,以及 AND、OR 等表达式的组合,最终满足过滤条件的数据会被选择出来。并且 WHERE 可以结合 IN、NOT IN 联合使用。举个例子:
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
7.3 DISTINCT
DISTINCT 用于从数据集/流中去重根据 SELECT 的结果进行去重。
示例:
SELECT DISTINCT name FROM Table;
对于流式查询,计算查询结果所需的 State 可能会无限增长,用户需要自己控制查询的状态范围,以防止状态过大。
7.4 GROUP BY
GROUP BY 是对数据进行分组操作。例如我们需要计算成绩明细表中,每个学生的总分。
示例:
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
7.5 UNION 和 UNION ALL
UNION 用于将两个结果集合并起来,要求两个结果集字段完全一致,包括字段类型、字段顺序。
不同于 UNION ALL 的是,UNION 会对结果数据去重。
示例:
SELECT * FROM T1 UNION (ALL) SELECT * FROM T2;
7.6 JOIN
JOIN 用于把来自两个表的数据联合起来形成结果表,Flink 支持的 JOIN 类型包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
这里的 JOIN 的语义和我们在关系型数据库中使用的 JOIN 语义一致。
示例:
JOIN(将订单表数据和商品表进行关联)
SELECT * FROM Orders INNER JOIN Product ON Orders.productId = Product.id
LEFT JOIN 与 JOIN 的区别是当右表没有与左边相 JOIN 的数据时候,右边对应的字段补 NULL 输出,RIGHT JOIN 相当于 LEFT JOIN 左右两个表交互一下位置。FULL JOIN 相当于 RIGHT JOIN 和 LEFT JOIN 之后进行 UNION ALL 操作。
示例:
SELECT * FROM Orders LEFT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders RIGHT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders FULL OUTER JOIN Product ON Orders.productId = Product.id
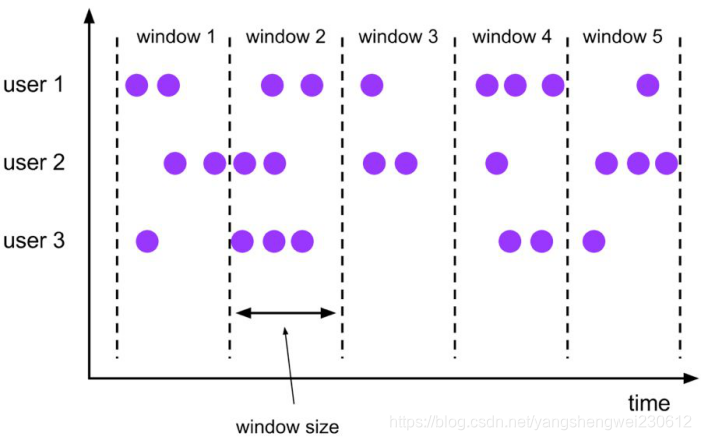
7.7 Group Window
根据窗口数据划分的不同,目前 Apache Flink 有如下 3 种 Bounded Window:
Tumble,滚动窗口,窗口数据有固定的大小,窗口数据无叠加;
Hop,滑动窗口,窗口数据有固定大小,并且有固定的窗口重建频率,窗口数据有叠加;
Session,会话窗口,窗口数据没有固定的大小,根据窗口数据活跃程度划分窗口,窗口数据无叠加。
Tumble 滚动窗口对应的语法如下:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
…
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
其中:
[gk] 决定了是否需要按照字段进行聚合;
TUMBLE_START 代表窗口开始时间;
TUMBLE_END 代表窗口结束时间;
timeCol 是流表中表示时间字段;
size 表示窗口的大小,如 秒、分钟、小时、天。
举个例子,假如我们要计算每个人每天的订单量,按照 user 进行聚合分组:
SELECT user, TUMBLE_START(rowtime, INTERVAL ‘1’ DAY) as wStart, SUM(amount)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ DAY), user;
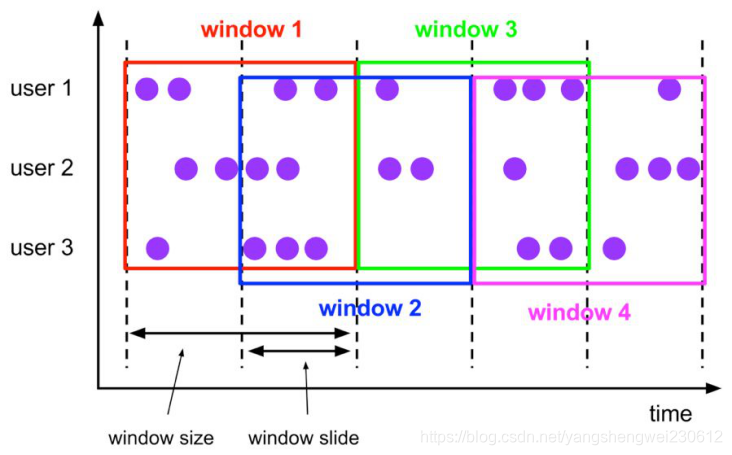
7.7.2 Hop Window
Hop 滑动窗口和滚动窗口类似,窗口有固定的 size,与滚动窗口不同的是滑动窗口可以通过 slide 参数控制滑动窗口的新建频率。因此当 slide 值小于窗口 size 的值的时候多个滑动窗口会重叠,具体语义如下:
Hop 滑动窗口对应语法如下:
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
…
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
每次字段的意思和 Tumble 窗口类似:
[gk] 决定了是否需要按照字段进行聚合;
HOP_START 表示窗口开始时间;
HOP_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
slide 表示每次窗口滑动的大小;
size 表示整个窗口的大小,如 秒、分钟、小时、天。
举例说明,我们要每过一小时计算一次过去 24 小时内每个商品的销量:
SELECT product, SUM(amount)
FROM Orders
GROUP BY product,HOP(rowtime, INTERVAL ‘1’ HOUR, INTERVAL ‘1’ DAY)
7.7.3 Session Window
会话时间窗口没有固定的持续时间,但它们的界限由 interval 不活动时间定义,即如果在定义的间隙期间没有出现事件,则会话窗口关闭。
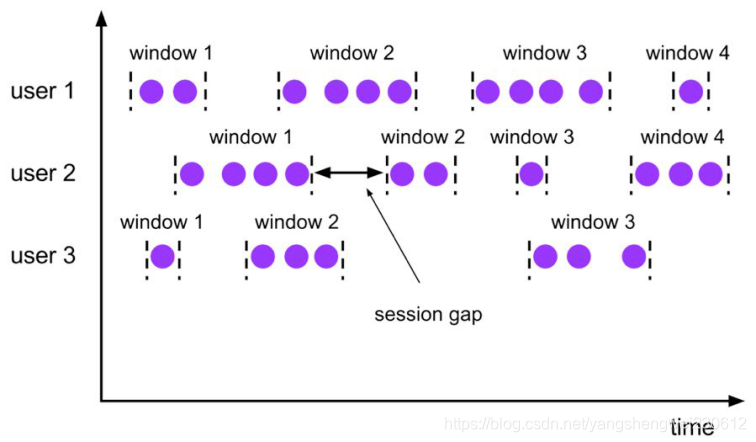
Seeeion 会话窗口对应语法如下:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
…
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
[gk] 决定了是否需要按照字段进行聚合;
SESSION_START 表示窗口开始时间;
SESSION_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
gap 表示窗口数据非活跃周期的时长。
例如,我们需要计算每个用户访问时间 12 小时内的订单量:
SELECT user, SESSION_START(rowtime, INTERVAL ‘12’ HOUR) AS sStart, SESSION_ROWTIME(rowtime, INTERVAL ‘12’ HOUR) AS sEnd, SUM(amount)
FROM Orders
GROUP BY SESSION(rowtime, INTERVAL ‘12’ HOUR), user
7.Flink-Action综合练习
课程目标
掌握使用Flink实现模拟双十一实时大屏统计
掌握使用Flink实现订单自动好评
1. Flink模拟双十一实时大屏统计
1.1 需求

在大数据的实时处理中,实时的大屏展示已经成了一个很重要的展示项,比如最有名的双十一大屏实时销售总价展示。除了这个,还有一些其他场景的应用,比如我们在我们的后台系统实时的展示我们网站当前的pv、uv等等,其实做法都是类似的。
今天我们就做一个最简单的模拟电商统计大屏的小例子,
需求如下:
1.实时计算出当天零点截止到当前时间的销售总额
2.计算出各个分类的销售top3
3.每秒钟更新一次统计结果
1.2 数据
首先我们通过自定义source 模拟订单的生成,生成了一个Tuple2,第一个元素是分类,第二个元素表示这个分类下产生的订单金额,金额我们通过随机生成.
/**
* 自定义数据源实时产生订单数据Tuple2<分类, 金额>
*/
public static class MySource implements SourceFunction<Tuple2<String, Double>>{
private boolean flag = true;
private String[] categorys = {
"女装", "男装","图书", "家电","洗护", "美妆","运动", "游戏","户外", "家具","乐器", "办公"};
private Random random = new Random();
@Override
public void run(SourceContext<Tuple2<String, Double>> ctx) throws Exception {
while (flag){
//随机生成分类和金额
int index = random.nextInt(categorys.length);//[0~length) ==> [0~length-1]
String category = categorys[index];//获取的随机分类
double price = random.nextDouble() * 100;//注意nextDouble生成的是[0~1)之间的随机数,*100之后表示[0~100)
ctx.collect(Tuple2.of(category,price));
Thread.sleep(20);
}
}
@Override
public void cancel() {
flag = false;
}
}
1.3 编码步骤:
1.env
2.source
3.transformation
3.1定义大小为一天的窗口,第二个参数表示中国使用的UTC+08:00时区比UTC时间早
.keyBy(0)
window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))
3.2定义一个1s的触发器
.trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(1)))
3.3聚合结果.aggregate(new PriceAggregate(), new WindowResult());
3.4看一下聚合的结果
CategoryPojo(category=男装, totalPrice=17225.26, dateTime=2020-10-20 08:04:12)
4.使用上面聚合的结果,实现业务需求:
result.keyBy(“dateTime”)
//每秒钟更新一次统计结果
.window(TumblingProcessingTimeWindows.of(Time.seconds(1)))
//在ProcessWindowFunction中实现该复杂业务逻辑
.process(new WindowResultProcess());
4.1.实时计算出当天零点截止到当前时间的销售总额
4.2.计算出各个分类的销售top3
4.3.每秒钟更新一次统计结果
5.execute
1.4 代码实现
package cn.itcast.action;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.ContinuousProcessingTimeTrigger;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.util.List;
import java.util.PriorityQueue;
import java.util.Queue;
import java.util.Random;
import java.util.stream.Collectors;
/**
* Author itcast
* Desc
* 1.实时计算出当天零点截止到当前时间的销售总额 11月11日 00:00:00 ~ 23:59:59
* 2.计算出各个分类的销售top3
* 3.每秒钟更新一次统计结果
*/
public class DoubleElevenBigScreem {
public static void main(String[] args) throws Exception {
//TODO 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);//方便观察
//TODO 2.source
DataStream<Tuple2<String, Double>> orderDS = env.addSource(new MySource());
//TODO 3.transformation--初步聚合:每隔1s聚合一下截止到当前时间的各个分类的销售总金额
DataStream<CategoryPojo> tempAggResult = orderDS
//分组
.keyBy(t -> t.f0)
//如果直接使用之前学习的窗口按照下面的写法表示:
//表示每隔1天计算一次---不对!
//.window(TumblingProcessingTimeWindows.of(Time.days(1)));
//表示每隔1s计算最近一天的数据,但是11月11日 00:01:00运行计算的是: 11月10日 00:01:00~11月11日 00:01:00 ---不对!
//.window(SlidingProcessingTimeWindows.of(Time.days(1),Time.seconds(1)));
//*例如中国使用UTC+08:00,您需要一天大小的时间窗口,
//*窗口从当地时间的00:00:00开始,您可以使用{@code of(时间.天(1),时间.hours(-8))}.
//下面的代码表示从当天的00:00:00开始计算当天的数据,缺一个触发时机/触发间隔
//3.1定义大小为一天的窗口,第二个参数表示中国使用的UTC+08:00时区比UTC时间早
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))
//3.2自定义触发时机/触发间隔
.trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(1)))
//.sum()//简单聚合
//3.3自定义聚合和结果收集
//aggregate(AggregateFunction<T, ACC, V> aggFunction,WindowFunction<V, R, K, W> windowFunction)
.aggregate(new PriceAggregate(), new WindowResult());//aggregate支持复杂的自定义聚合
//3.4看一下聚合的结果
tempAggResult.print("初步聚合的各个分类的销售总额");
//初步聚合的各个分类的销售总额> DoubleElevenBigScreem.CategoryPojo(category=游戏, totalPrice=563.8662504982619, dateTime=2021-01-19 10:31:40)
//初步聚合的各个分类的销售总额> DoubleElevenBigScreem.CategoryPojo(category=办公, totalPrice=876.5216500403918, dateTime=2021-01-19 10:31:40)
//TODO 4.sink-使用上面初步聚合的结果(每隔1s聚合一下截止到当前时间的各个分类的销售总金额),实现业务需求:
tempAggResult.keyBy(CategoryPojo::getDateTime)
.window(TumblingProcessingTimeWindows.of(Time.seconds(1)))//每隔1s进行最终的聚合并输出结果
//.sum//简单聚合
//.apply()
.process(new FinalResultWindowProcess());//在ProcessWindowFunction中实现该复杂业务逻辑
//TODO 5.execute
env.execute();
}
/**
* 自定义数据源实时产生订单数据Tuple2<分类, 金额>
*/
public static class MySource implements SourceFunction<Tuple2<String, Double>> {
private boolean flag = true;
private String[] categorys = {
"女装", "男装", "图书", "家电", "洗护", "美妆", "运动", "游戏", "户外", "家具", "乐器", "办公"};
private Random random = new Random();
@Override
public void run(SourceContext<Tuple2<String, Double>> ctx) throws Exception {
while (flag) {
//随机生成分类和金额
int index = random.nextInt(categorys.length);//[0~length) ==> [0~length-1]
String category = categorys[index];//获取的随机分类
double price = random.nextDouble() * 100;//注意nextDouble生成的是[0~1)之间的随机小数,*100之后表示[0~100)的随机小数
ctx.collect(Tuple2.of(category, price));
Thread.sleep(20);
}
}
@Override
public void cancel() {
flag = false;
}
}
/**
* 自定义聚合函数,指定聚合规则
* AggregateFunction<IN, ACC, OUT>
*/
private static class PriceAggregate implements AggregateFunction<Tuple2<String, Double>, Double, Double> {
//初始化累加器
@Override
public Double createAccumulator() {
return 0D;//D表示double,L表示Long
}
//把数据累加到累加器上
@Override
public Double add(Tuple2<String, Double> value, Double accumulator) {
return value.f1 + accumulator;
}
//获取累加结果
@Override
public Double getResult(Double accumulator) {
return accumulator;
}
//合并各个subtask的结果
@Override
public Double merge(Double a, Double b) {
return a + b;
}
}
/**
* 自定义窗口函数,指定窗口数据收集规则(负责返回聚合的结果如何返回)
* WindowFunction<IN, OUT, KEY, W extends Window>
*/
private static class WindowResult implements WindowFunction<Double, CategoryPojo, String, TimeWindow> {
private FastDateFormat df = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@Override
//void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out)
public void apply(String category, TimeWindow window, Iterable<Double> input, Collector<CategoryPojo> out) throws Exception {
long currentTimeMillis = System.currentTimeMillis();
String dateTime = df.format(currentTimeMillis);
Double totalPrice = input.iterator().next();
out.collect(new CategoryPojo(category,totalPrice,dateTime));
}
}
/**
* 用于存储聚合返回结果
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class CategoryPojo {
private String category;//分类名称
private double totalPrice;//该分类总销售额
private String dateTime;// 截止到当前时间的时间,本来应该是EventTime,但是我们这里简化了直接用当前系统时间即可
}
/**
* 自定义窗口完成销售总额统计和分类销售额top3统计并输出
* abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window>
*/
private static class FinalResultWindowProcess extends ProcessWindowFunction<CategoryPojo, Object, String, TimeWindow> {
//注意:
//下面的key/dateTime表示当前这1s的时间
//elements:表示截止到当前这1s的各个分类的销售数据
@Override
public void process(String dateTime, Context context, Iterable<CategoryPojo> elements, Collector<Object> out) throws Exception {
//1.实时计算出当天零点截止到当前时间的销售总额 11月11日 00:00:00 ~ 23:59:59
double total = 0D;//用来记录销售总额
//2.计算出各个分类的销售top3:如: "女装": 10000 "男装": 9000 "图书":8000
//注意:这里只需要求top3,也就是只需要排前3名就行了,其他的不用管!当然你也可以每次对进来的所有数据进行排序,但是浪费!
//所以这里直接使用小顶堆完成top3排序:
//70
//80
//90
//如果进来一个比堆顶元素还有小的,直接不要
//如果进来一个比堆顶元素大,如85,直接把堆顶元素删掉,把85加进去并继续按照小顶堆规则排序,小的在上面,大的在下面
//80
//85
//90
//创建一个小顶堆
//https://blog.csdn.net/hefenglian/article/details/81807527
Queue<CategoryPojo> queue = new PriorityQueue<>(3,//初识容量
//正常的排序,就是小的在前,大的在后,也就是c1>c2的时候返回1,也就是升序,也就是小顶堆
(c1, c2) -> c1.getTotalPrice() >= c2.getTotalPrice() ? 1 : -1);
for (CategoryPojo element : elements) {
double price = element.getTotalPrice();
total += price;
if(queue.size()< 3){
queue.add(element);//或offer入队
}else{
if(price >= queue.peek().getTotalPrice()){
//peek表示取出堆顶元素但不删除
//queue.remove(queue.peek());
queue.poll();//移除堆顶元素
queue.add(element);//或offer入队
}
}
}
//代码走到这里那么queue存放的就是分类的销售额top3,但是是升序.需要改为逆序然后输出
List<String> top3List = queue.stream()
.sorted((c1, c2) -> c1.getTotalPrice() >= c2.getTotalPrice() ? -1 : 1)
.map(c -> "分类:" + c.getCategory() + " 金额:" + c.getTotalPrice())
.collect(Collectors.toList());
//3.每秒钟更新一次统计结果-也就是直接输出
double roundResult = new BigDecimal(total).setScale(2, RoundingMode.HALF_UP).doubleValue();//四舍五入保留2位小数
System.out.println("时间: "+dateTime +" 总金额 :" + roundResult);
System.out.println("top3: \n" + StringUtils.join(top3List,"\n"));
}
}
}

2. Flink实现订单自动好评
2.1 需求

在电商领域会有这么一个场景,如果用户买了商品,在订单完成之后,一定时间之内没有做出评价,系统自动给与五星好评,我们今天主要使用Flink的定时器来简单实现这一功能。
2.2 数据
自定义source模拟生成一些订单数据.
在这里,我们生了一个最简单的二元组Tuple3,包含用户id,订单id和订单完成时间三个字段.
/**
* 自定义source实时产生订单数据Tuple3<用户id,订单id, 订单生成时间>
*/
public static class MySource implements SourceFunction<Tuple3<String, String, Long>> {
private boolean flag = true;
@Override
public void run(SourceContext<Tuple3<String, String, Long>> ctx) throws Exception {
Random random = new Random();
while (flag) {
String userId = random.nextInt(5) + "";
String orderId = UUID.randomUUID().toString();
long currentTimeMillis = System.currentTimeMillis();
ctx.collect(Tuple3.of(userId, orderId, currentTimeMillis));
Thread.sleep(500);
}
}
@Override
public void cancel() {
flag = false;
}
}
2.3 编码步骤
1.env
2.source
3.transformation
设置经过interval毫秒用户未对订单做出评价,自动给与好评.为了演示方便,设置5s的时间
long interval = 5000L;
分组后使用自定义KeyedProcessFunction完成定时判断超时订单并自动好评
dataStream.keyBy(0).process(new TimerProcessFuntion(interval));
3.1定义MapState类型的状态,key是订单号,value是订单完成时间
3.2创建MapState
MapStateDescriptor<String, Long> mapStateDesc =
new MapStateDescriptor<>(“mapStateDesc”, String.class, Long.class);
mapState = getRuntimeContext().getMapState(mapStateDesc);
3.3注册定时器
mapState.put(value.f0, value.f1);
ctx.timerService().registerProcessingTimeTimer(value.f1 + interval);
3.4定时器被触发时执行并输出结果
4.sink
5.execute
2.4 代码实现
package cn.itcast.action;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
import java.util.Iterator;
import java.util.Map;
import java.util.Random;
import java.util.UUID;
/**
* Author itcast
* Desc
* 在电商领域会有这么一个场景,如果用户买了商品,在订单完成之后,一定时间之内没有做出评价,系统自动给与五星好评,
* 我们今天主要使用Flink的定时器来简单实现这一功能。
*/
public class OrderAutomaticFavorableComments {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.source
DataStreamSource<Tuple3<String, String, Long>> sourceDS = env.addSource(new MySource());
//这里可以使用订单生成时间作为事件时间,代码和之前的一样
//这里不作为重点,所以简化处理!
//3.transformation
//设置经过interval用户未对订单做出评价,自动给与好评.为了演示方便,设置5000ms的时间
long interval = 5000L;
//分组后使用自定义KeyedProcessFunction完成定时判断超时订单并自动好评
sourceDS.keyBy(0) //实际中可以对用户id进行分组
//KeyedProcessFunction:进到窗口的数据是分好组的
//ProcessFunction:进到窗口的数据是不区分分组的
.process(new TimerProcessFuntion(interval));
//4.execute
env.execute();
}
/**
* 自定义source实时产生订单数据Tuple2<订单id, 订单生成时间>
*/
public static class MySource implements SourceFunction<Tuple3<String, String, Long>> {
private boolean flag = true;
@Override
public void run(SourceContext<Tuple3<String, String, Long>> ctx) throws Exception {
Random random = new Random();
while (flag) {
String userId = random.nextInt(5) + "";
String orderId = UUID.randomUUID().toString();
long currentTimeMillis = System.currentTimeMillis();
ctx.collect(Tuple3.of(userId, orderId, currentTimeMillis));
Thread.sleep(500);
}
}
@Override
public void cancel() {
flag = false;
}
}
/**
* 自定义处理函数用来给超时订单做自动好评!
* 如一个订单进来:<订单id, 2020-10-10 12:00:00>
* 那么该订单应该在12:00:00 + 5s 的时候超时!
* 所以我们可以在订单进来的时候设置一个定时器,在订单时间 + interval的时候触发!
* KeyedProcessFunction<K, I, O>
* KeyedProcessFunction<Tuple就是String, Tuple3<用户id, 订单id, 订单生成时间>, Object>
*/
public static class TimerProcessFuntion extends KeyedProcessFunction<Tuple, Tuple3<String, String, Long>, Object> {
private long interval;
public TimerProcessFuntion(long interval) {
this.interval = interval;//传过来的是5000ms/5s
}
//3.1定义MapState类型的状态,key是订单号,value是订单完成时间
//定义一个状态用来记录订单信息
//MapState<订单id, 订单完成时间>
private MapState<String, Long> mapState;
//3.2初始化MapState
@Override
public void open(Configuration parameters) throws Exception {
//创建状态描述器
MapStateDescriptor<String, Long> mapStateDesc = new MapStateDescriptor<>("mapState", String.class, Long.class);
//根据状态描述器初始化状态
mapState = getRuntimeContext().getMapState(mapStateDesc);
}
//3.3注册定时器
//处理每一个订单并设置定时器
@Override
public void processElement(Tuple3<String, String, Long> value, Context ctx, Collector<Object> out) throws Exception {
mapState.put(value.f1, value.f2);
//如一个订单进来:<订单id, 2020-10-10 12:00:00>
//那么该订单应该在12:00:00 + 5s 的时候超时!
//在订单进来的时候设置一个定时器,在订单时间 + interval的时候触发!!!
ctx.timerService().registerProcessingTimeTimer(value.f2 + interval);
}
//3.4定时器被触发时执行并输出结果并sink
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Object> out) throws Exception {
//能够执行到这里说明订单超时了!超时了得去看看订单是否评价了(实际中应该要调用外部接口/方法查订单系统!,我们这里没有,所以模拟一下)
//没有评价才给默认好评!并直接输出提示!
//已经评价了,直接输出提示!
Iterator<Map.Entry<String, Long>> iterator = mapState.iterator();
while (iterator.hasNext()) {
Map.Entry<String, Long> entry = iterator.next();
String orderId = entry.getKey();
//调用订单系统查询是否已经评价
boolean result = isEvaluation(orderId);
if (result) {
//已评价
System.out.println("订单(orderid: " + orderId + ")在" + interval + "毫秒时间内已经评价,不做处理");
} else {
//未评价
System.out.println("订单(orderid: " + orderId + ")在" + interval + "毫秒时间内未评价,系统自动给了默认好评!");
//实际中还需要调用订单系统将该订单orderId设置为5星好评!
}
//从状态中移除已经处理过的订单,避免重复处理
iterator.remove();
}
}
//在生产环境下,可以去查询相关的订单系统.
private boolean isEvaluation(String key) {
return key.hashCode() % 2 == 0;//随机返回订单是否已评价
}
}
}
2.5 效果

8.Flink高级特性和新特性
课程目标
掌握使用Flink-BroadcastState实现配置动态更新
了解端对端一次性语义
了解异步IO
了解Streaming file sink的使用
掌握FileSink的使用
掌握FlinkSQL整合Hive
https://developer.aliyun.com/article/780123?spm=a2c6h.12873581.0.0.1e3e46ccbYFFrC
1. BroadcastState(状态广播)
1.1 BroadcastState介绍
在开发过程中,如果遇到需要下发/广播配置、规则等低吞吐事件流到下游所有 task 时,就可以使用 Broadcast State。Broadcast State 是 Flink 1.5 引入的新特性。
下游的 task 接收这些配置、规则并保存为 BroadcastState, 将这些配置应用到另一个数据流的计算中 。
场景举例
1)动态更新计算规则: 如事件流需要根据最新的规则进行计算,则可将规则作为广播状态广播到下游Task中。
** ** 如事件流需要实时增加用户的基础信息,则可将用户的基础信息作为广播状态广播到下游Task中。
API介绍
首先创建一个Keyed 或Non-Keyed 的DataStream,
然后再创建一个BroadcastedStream,
最后通过DataStream来连接(调用connect 方法)到Broadcasted Stream 上,
这样实现将BroadcastState广播到Data Stream 下游的每个Task中。
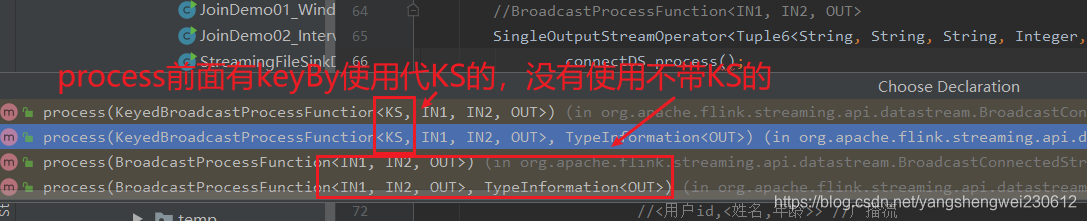
1.如果DataStream是Keyed Stream ,则连接到Broadcasted Stream 后, 添加处理ProcessFunction 时需要使用KeyedBroadcastProcessFunction 来实现, 下面是KeyedBroadcastProcessFunction 的API,代码如下所示:
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}
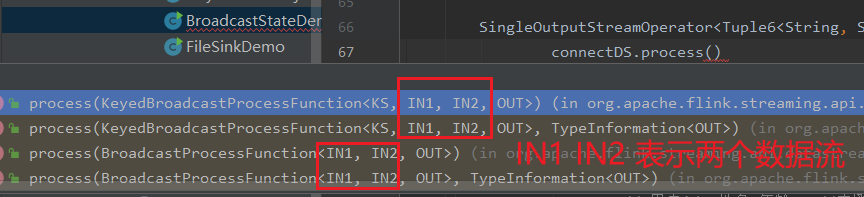
上面泛型中的各个参数的含义,说明如下:
KS:表示Flink 程序从最上游的Source Operator 开始构建Stream,当调用keyBy 时所依赖的Key 的类型;
IN1:表示非Broadcast 的Data Stream 中的数据记录的类型;
IN2:表示Broadcast Stream 中的数据记录的类型;
OUT:表示经过KeyedBroadcastProcessFunction 的processElement()和processBroadcastElement()方法处理后输出结果数据记录的类型。
2.如果Data Stream 是Non-Keyed Stream,则连接到Broadcasted Stream 后,添加处理ProcessFunction 时需要使用BroadcastProcessFunction 来实现, 下面是BroadcastProcessFunction 的API,代码如下所示:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}
上面泛型中的各个参数的含义,与前面KeyedBroadcastProcessFunction 的泛型类型中的后3 个含义相同,只是没有调用keyBy 操作对原始Stream 进行分区操作,就不需要KS 泛型参数。
具体如何使用上面的BroadcastProcessFunction,接下来我们会在通过实际编程,来以使用KeyedBroadcastProcessFunction 为例进行详细说明。
注意事项
- Broadcast State 是Map 类型,即K-V 类型。
- Broadcast State 只有在广播的一侧, 即在BroadcastProcessFunction 或KeyedBroadcastProcessFunction 的processBroadcastElement 方法中可以修改。在非广播的一侧, 即在BroadcastProcessFunction 或KeyedBroadcastProcessFunction 的processElement 方法中只读。
- Broadcast State 中元素的顺序,在各Task 中可能不同。基于顺序的处理,需要注意。
- Broadcast State 在Checkpoint 时,每个Task 都会Checkpoint 广播状态。
- Broadcast State 在运行时保存在内存中,目前还不能保存在RocksDB State Backend 中。
1.2 需求-实现配置动态更新
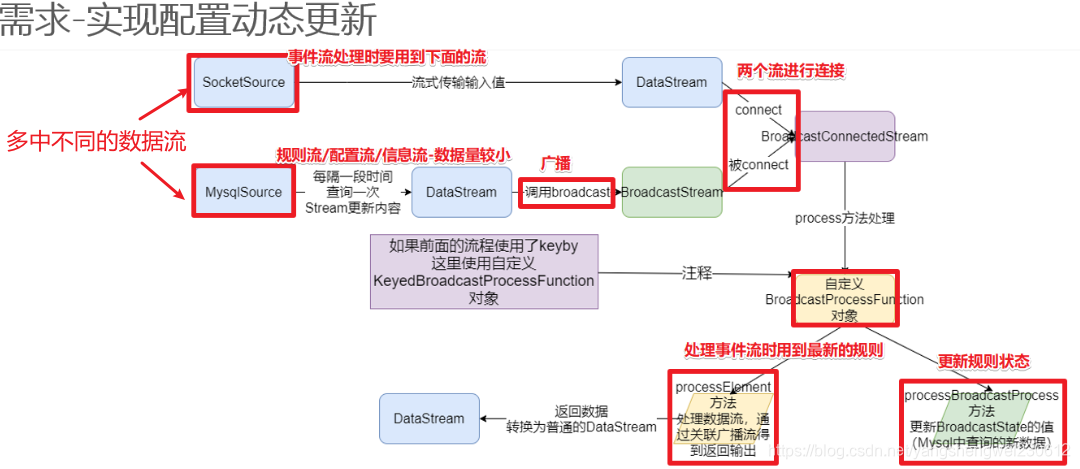
实时过滤出配置中的用户,并在事件流中补全这批用户的基础信息。
事件流:表示用户在某个时刻浏览或点击了某个商品,格式如下。
{
"userID": "user_3", "eventTime": "2019-08-17 12:19:47", "eventType": "browse", "productID": 1}
{
"userID": "user_2", "eventTime": "2019-08-17 12:19:48", "eventType": "click", "productID": 1}
配置数据: 表示用户的详细信息,在Mysql中,如下:
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`userID` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`userName` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`userAge` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`userID`) USING BTREE
) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES ('user_1', '张三', 10);
INSERT INTO `user_info` VALUES ('user_2', '李四', 20);
INSERT INTO `user_info` VALUES ('user_3', '王五', 30);
INSERT INTO `user_info` VALUES ('user_4', '赵六', 40);
SET FOREIGN_KEY_CHECKS = 1;
输出结果:
(user_3,2019-08-17 12:19:47,browse,1,王五,33)
(user_2,2019-08-17 12:19:48,click,1,李四,20)
1.3 编码步骤
1.env
2.source
-1.构建实时数据事件流-自定义随机
<userID, eventTime, eventType, productID>
-2.构建配置流-从MySQL
<用户id,<姓名,年龄>>
3.transformation
-1.定义状态描述器
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>(“config”,Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
-2.广播配置流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = configDS.broadcast(descriptor);
-3.将事件流和广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS =eventDS.connect(broadcastDS);
-4.处理连接后的流-根据配置流补全事件流中的用户的信息
4.sink
5.execute


package cn.itcast.feature;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.tuple.Tuple6;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* Author itcast
* Desc
*/
public class BroadcastStateDemo {
public static void main(String[] args) throws Exception {
//TODO 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//TODO 2.source
//-1.构建实时数据事件流--数据量较大
//<userID, eventTime, eventType, productID>
DataStreamSource<Tuple4<String, String, String, Integer>> eventDS = env.addSource(new MySource());
//-2.配置流/规则流/用户信息流--数据量较小-从MySQL
//<用户id,<姓名,年龄>>
DataStreamSource<Map<String, Tuple2<String, Integer>>> userDS = env.addSource(new MySQLSource());
//TODO 3.transformation
//-1.定义状态描述器
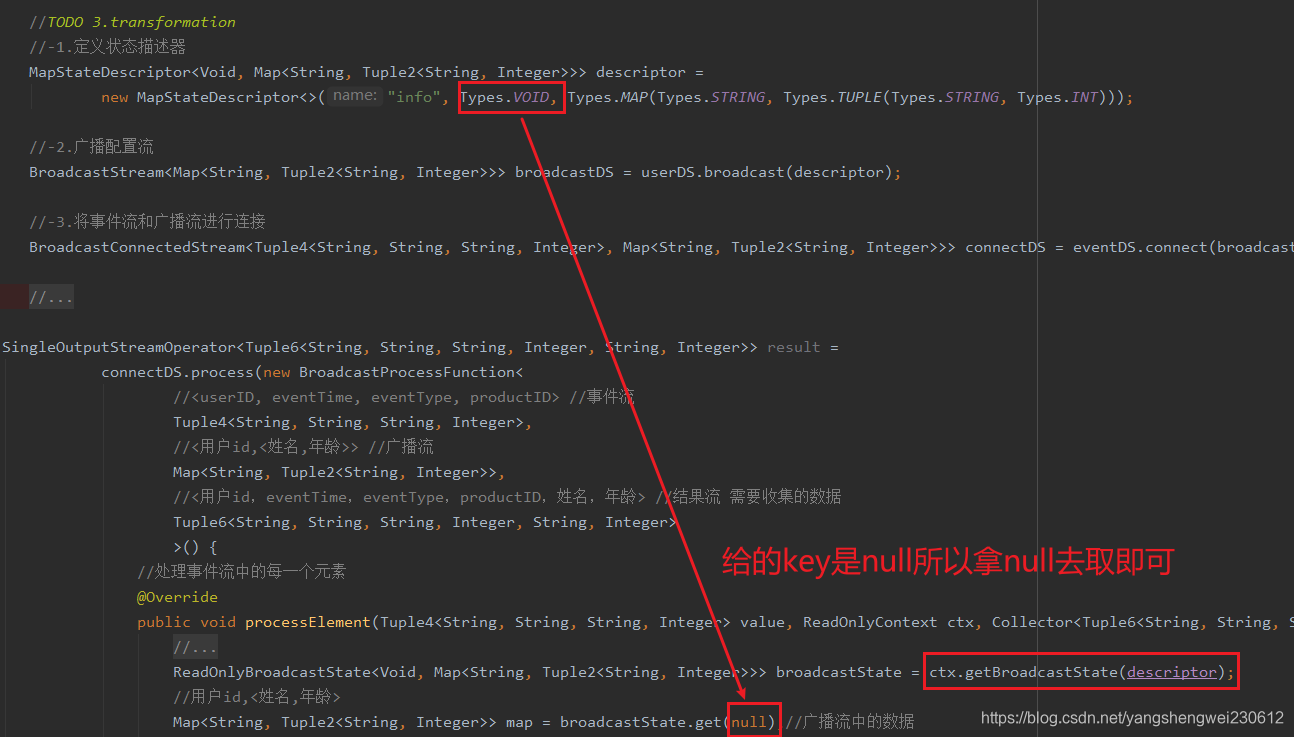
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>("info", Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
//-2.广播配置流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = userDS.broadcast(descriptor);
//-3.将事件流和广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS = eventDS.connect(broadcastDS);
//-4.处理连接后的流-根据配置流补全事件流中的用户的信息
//BroadcastProcessFunction<IN1, IN2, OUT>
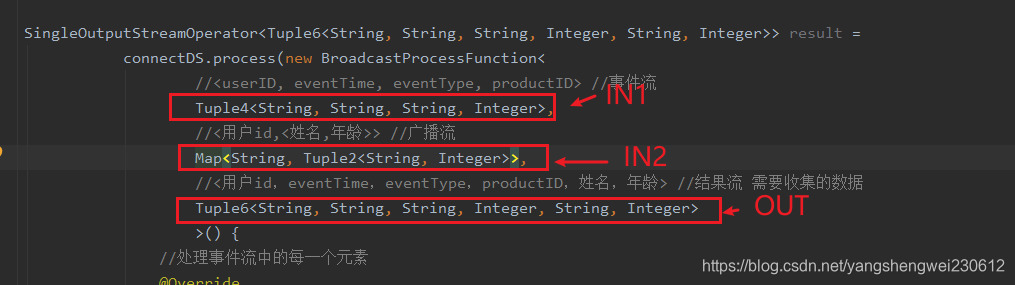
SingleOutputStreamOperator<Tuple6<String, String, String, Integer, String, Integer>> result =
connectDS.process(new BroadcastProcessFunction<
//<userID, eventTime, eventType, productID> //事件流
Tuple4<String, String, String, Integer>,
//<用户id,<姓名,年龄>> //广播流
Map<String, Tuple2<String, Integer>>,
//<用户id,eventTime,eventType,productID,姓名,年龄> //结果流 需要收集的数据
Tuple6<String, String, String, Integer, String, Integer>
>() {
//处理事件流中的每一个元素
@Override
public void processElement(Tuple4<String, String, String, Integer> value, ReadOnlyContext ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception {
//value就是事件流中的数据
//<userID, eventTime, eventType, productID> //事件流--已经有了
//Tuple4<String, String, String, Integer>,
//目标是将value和广播流中的数据进行关联,返回结果流
//<用户id,<姓名,年龄>> //广播流--需要获取
//Map<String, Tuple2<String, Integer>>
//<用户id,eventTime,eventType,productID,姓名,年龄> //结果流 需要收集的数据
// Tuple6<String, String, String, Integer, String, Integer>
//获取广播流
ReadOnlyBroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor);
//用户id,<姓名,年龄>
Map<String, Tuple2<String, Integer>> map = broadcastState.get(null);//广播流中的数据
if (map != null) {
//根据value中的用户id去map中获取用户信息
String userId = value.f0;
Tuple2<String, Integer> tuple2 = map.get(userId);
String username = tuple2.f0;
Integer age = tuple2.f1;
//收集数据
out.collect(Tuple6.of(userId, value.f1, value.f2, value.f3, username, age));
}
}
//更新处理广播流中的数据
@Override
public void processBroadcastElement(Map<String, Tuple2<String, Integer>> value, Context ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception {
//value就是从MySQL中每隔5是查询出来并广播到状态中的最新数据!
//要把最新的数据放到state中
BroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor);
broadcastState.clear();//清空旧数据
broadcastState.put(null, value);//放入新数据
}
});
//TODO 4.sink
// result.print();
//TODO 5.execute
env.execute();
}
/**
* 随机事件流--数据量较大
* 用户id,时间,类型,产品id
* <userID, eventTime, eventType, productID>
*/
public static class MySource implements SourceFunction<Tuple4<String, String, String, Integer>> {
private boolean isRunning = true;
@Override
public void run(SourceContext<Tuple4<String, String, String, Integer>> ctx) throws Exception {
Random random = new Random();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
while (isRunning) {
int id = random.nextInt(4) + 1;
String user_id = "user_" + id;
String eventTime = df.format(new Date());
String eventType = "type_" + random.nextInt(3);
int productId = random.nextInt(4);
ctx.collect(Tuple4.of(user_id, eventTime, eventType, productId));
Thread.sleep(500);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
/**
* 配置流/规则流/用户信息流--数据量较小
* <用户id,<姓名,年龄>>
*/
/*
CREATE TABLE `user_info` (
`userID` varchar(20) NOT NULL,
`userName` varchar(10) DEFAULT NULL,
`userAge` int(11) DEFAULT NULL,
PRIMARY KEY (`userID`) USING BTREE
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
INSERT INTO `user_info` VALUES ('user_1', '张三', 10);
INSERT INTO `user_info` VALUES ('user_2', '李四', 20);
INSERT INTO `user_info` VALUES ('user_3', '王五', 30);
INSERT INTO `user_info` VALUES ('user_4', '赵六', 40);
*/
public static class MySQLSource extends RichSourceFunction<Map<String, Tuple2<String, Integer>>> {
private boolean flag = true;
private Connection conn = null;
private PreparedStatement ps = null;
private ResultSet rs = null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "root");
String sql = "select `userID`, `userName`, `userAge` from `user_info`";
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<Map<String, Tuple2<String, Integer>>> ctx) throws Exception {
while (flag) {
Map<String, Tuple2<String, Integer>> map = new HashMap<>();
ResultSet rs = ps.executeQuery();
while (rs.next()) {
String userID = rs.getString("userID");
String userName = rs.getString("userName");
int userAge = rs.getInt("userAge");
//Map<String, Tuple2<String, Integer>>
map.put(userID, Tuple2.of(userName, userAge));
}
ctx.collect(map);
Thread.sleep(5000);//每隔5s更新一下用户的配置信息!
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
if (conn != null) conn.close();
if (ps != null) ps.close();
if (rs != null) rs.close();
}
}
}
2. 双流Join
2.1 介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/joining.html
https://zhuanlan.zhihu.com/p/340560908
https://blog.csdn.net/andyonlines/article/details/108173259

双流Join是Flink面试的高频问题。一般情况下说明以下几点就可以hold了:
Join大体分类只有两种:Window Join和Interval Join。
Window Join又可以根据Window的类型细分出3种:
Tumbling Window Join、Sliding Window Join、Session Widnow Join。
Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作;
interval join也是利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;
目前Stream join的结果是数据的笛卡尔积;
2.2 Window Join
Tumbling Window Join (滚动窗口(没有重复数据)的的join)
执行翻滚窗口联接时,具有公共键和公共翻滚窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。因为它的行为类似于内部连接,所以一个流中的元素在其滚动窗口中没有来自另一个流的元素,因此不会被发射!
如图所示,我们定义了一个大小为2毫秒的翻滚窗口,结果窗口的形式为[0,1]、[2,3]、。。。。该图显示了每个窗口中所有元素的成对组合,这些元素将传递给JoinFunction。注意,在翻滚窗口[6,7]中没有发射任何东西,因为绿色流中不存在与橙色元素⑥和⑦结合的元素。

import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
Sliding Window Join (滑动窗口(有重复数据)的的join)
在执行滑动窗口联接时,具有公共键和公共滑动窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。在当前滑动窗口中,一个流的元素没有来自另一个流的元素,则不会发射!请注意,某些元素可能会连接到一个滑动窗口中,但不会连接到另一个滑动窗口中!
在本例中,我们使用大小为2毫秒的滑动窗口,并将其滑动1毫秒,从而产生滑动窗口[-1,0],[0,1],[1,2],[2,3]…。x轴下方的连接元素是传递给每个滑动窗口的JoinFunction的元素。在这里,您还可以看到,例如,在窗口[2,3]中,橙色②与绿色③连接,但在窗口[1,2]中没有与任何对象连接。
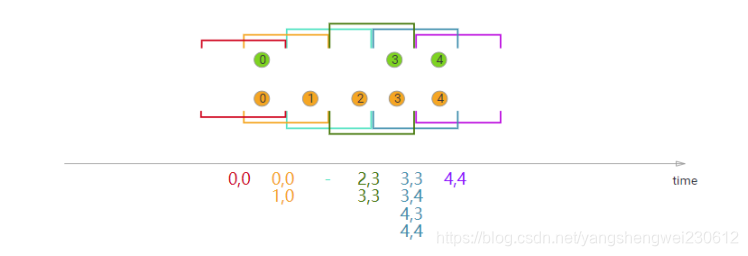
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
ession Window Join
在执行会话窗口联接时,具有相同键(当“组合”时满足会话条件)的所有元素以成对组合方式联接,并传递给JoinFunction或FlatJoinFunction。同样,这执行一个内部连接,所以如果有一个会话窗口只包含来自一个流的元素,则不会发出任何输出!
在这里,我们定义了一个会话窗口连接,其中每个会话被至少1ms的间隔分割。有三个会话,在前两个会话中,来自两个流的连接元素被传递给JoinFunction。在第三个会话中,绿色流中没有元素,所以⑧和⑨没有连接!
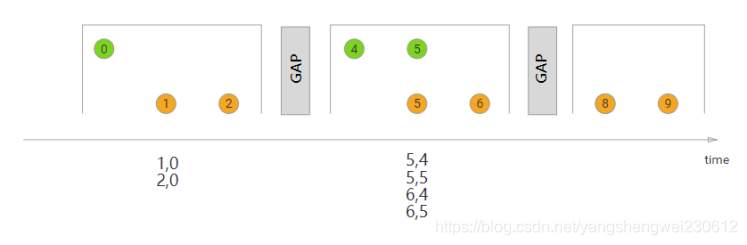
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});