1. 前向特征选择方法
从所有特征中选择特征的重要性最大的特征入模型。
1.1 直接利用feature importance变量来判断特征重要性
我们在构建树类模型(XGBoost、LightGBM等)时,如果想要知道哪些变量比较重要的话,可以通过模型的feature_importances_方法来获取特征重要性。例如LightGBM的feature_importances_可以通过特征的分裂次数或利用该特征分裂后的增益来衡量。一般情况下,不同的衡量准则得到的特征重要性会有差异。一般通过多种评价标准来交叉选择特征 – 若一个特征在不同的评价标准下都是比较重要的,那么该特征对label有较好的预测能力。
1.2 卡方检验
卡方检验是一种假设检验方法。属于非参数检验。根本思想在于比较理论频数和实际频数的吻合程度。
下面举个例子:
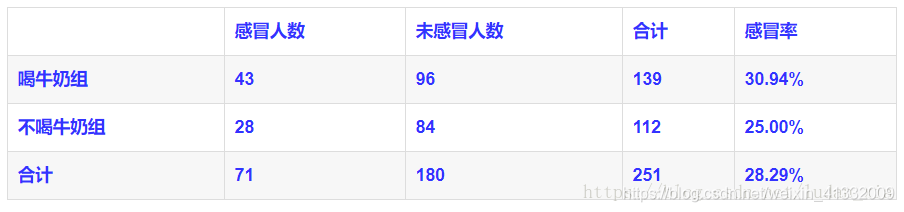
喝牛奶组和不喝牛奶组的感冒率为30.94%和25.00%,两者的差别可能是抽样误差导致,也可能是牛奶对感冒率真的有影响。那么假设喝牛奶对感冒发病率没有影响,即喝牛奶与感冒无关。之后就要检验这个假设是否成立,或者推翻这个假设。
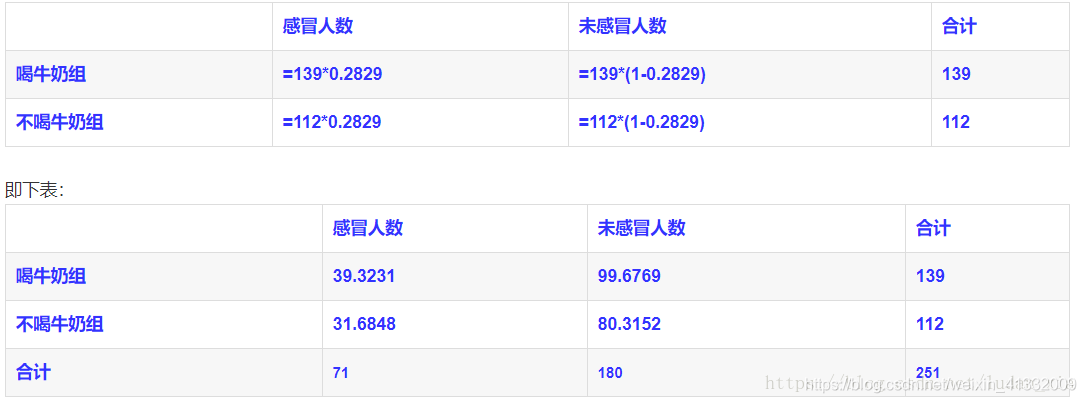
在理论上,如果喝牛奶和不喝牛奶对感冒并没有任何影响的话,分布应该是均匀的,如下表:
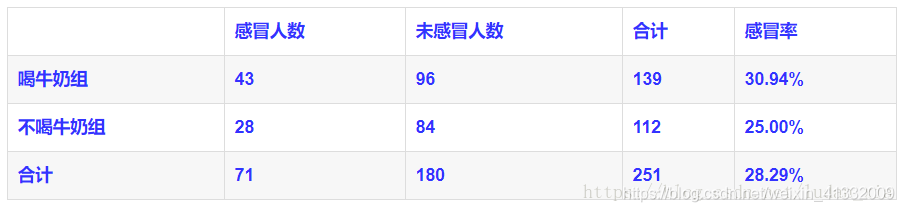
但实际的结果却由第一个图所示:
卡方检验的计算公式:
χ 2 = ∑ ( A − T ) 2 T \chi^2 = \sum \frac{(A-T)^2}{T} χ2=∑T(A−T)2
其中,A是每一项的理论值,T是每一项的实际值。 χ 2 \chi^2 χ2值的意义:衡量理论与实际的差异程度。在本例中,
χ 2 = 1.077 \chi^2=1.077 χ2=1.077
下面就需要检验这个值是否在拒绝域中。我们需要查询卡方分布的临界值,将计算的值与临界值比较。查询临界值就需要知道自由度: 自 由 度 V = ( 行 数 − 1 ) ∗ ( 列 数 − 1 ) 自由度V=(行数-1)*(列数-1) 自由度V=(行数−1)∗(列数−1);对于该问题V=1,查询可得临界值为3.84.
如果 χ 2 \chi^2 χ2<临界值 则假设成立。
可以用卡方检验来提取特征,起到特征降维的目的。
2.3 信息增益
使用决策树中的信息增益计算方法,即计算按此特征分类之后熵的减少程度,以此来衡量特征的重要程度。
所以,树模型天然就可以衡量特征的重要性,例如可以用GBDT来构造特征: https://blog.csdn.net/weixin_41332009/article/details/113337618
2.4 互信息
和信息增益类似。
https://blog.csdn.net/weixin_41332009/article/details/113836524
2. 后向特征选择
首先使用所有特征进行训练,然后从中选择特征的重要性最小的特征移除然后重新训练。
2.1 permutation importance
常规思路:首先让全部特征参与训练然后预测得出score1(mse,rmse等),然后依次去掉一个特征去训练模型(有多少个特征就会训练多少个模型),分别预测会得到对应的缺失特征的得分score2,score2-score1就代表一个特征的预测能力。然而,有100个特征岂不是要训练100个模型?这样做太麻烦了,所以Permutation importance 的算法是这样的:
- 用全部特征,训练一个模型。
- 验证集预测得到得分。
- 验证集的一个特征列的值进行随机打乱,预测得到得分。
- 将上述得分做差即可得到特征x1对预测的影响。
- 依次将每一列特征按上述方法做,得到每个特征对预测的影响。
import eli5
from eli5.sklearn import PermutationImportance
# first_model是已经训练好的模型
perm = PermutationImportance(first_model, random_state=1).fit(val_X, val_y)
# 显示结果
eli5.show_weights(perm, feature_names = val_X.columns.tolist())
打印结果:
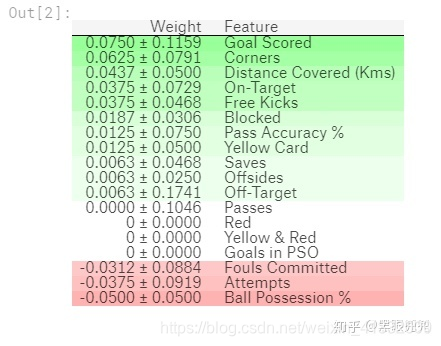
绿色代表该变量很重要,红色代表没有用、甚至会有反作用。