文章目录
-
- 每日精进
-
- **1.hdfs启动流程**
- 2.hdfs ,spark streaming, flink三者中的checkpoint原理
- 1、谈谈你对Hive内部表、外部表、分区表、分桶表的区别,并介绍一下使用场景
- 2、介绍一下Sort By,Order By,Distrbute By,Cluster By的区别
- 3、谈谈你所知道有哪些常用的Hive调优方式?
- 1、清楚描述 MapReduce 的 shuffle 过程
- 2、HBase 的 rowkey 设计需要遵循什么原则,以及如何解决热点问题
- 3、早几年是有很多 elasticsearch /solr 为 mysql 或者 HBase 作二级索引,但是现在 elasticsearch 在不断的加大在大数据领域的支持,是否可以取代 HBase
- 1、谈谈Hadoop里面的压缩格式以及使用场景
- 2、Sqoop在导入数据的时候出现了数据倾斜,你有什么解决方案。另外,使用Sqoop的注意事项,你能列举出来几个?
- 3、小鹏汽车充电有两种类型,快充、慢充,有如下数据:
- 1、介绍一下拉链表的原理,以及适用于哪些场景?
- 2、如果使用spark遇到了 OOM ,你会怎么处理?
- 3、A 文件有 50 亿条 URL,B 文件也有 50 亿条 URL,每条 URL 大小为 64B,在一台只有 4G 内存的机器上,怎么找出 A、B 中相同的 URL?
每日精进
1.hdfs启动流程
个人理解:
hdfs启动流程
hdfs是Hadoop Distribute File System 的简称,即分布式文件系统,用于存储海量数据.
hdfs的启动分为三步:1.启动Namenode;2.启动Datanode;3.启动Secondary Namenode;
详细说说:
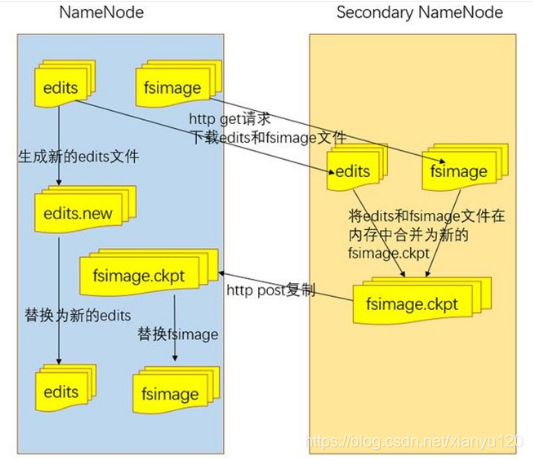
Secondary NameNode的工作流程:(为了方便Secondary NameNode以SN替代,NameNode)首先SN通知NN切换成edits文件;
NN中的edits和fsimage通过http的方式传输到SN,并在SN中合并成新的fsimage.ckpt,之后传输回NN,并将旧的fsimage替换;
NN中的edits生成新的edits文件并替换旧的edits
参考答案:



2.hdfs ,spark streaming, flink三者中的checkpoint原理
spark和flink还没学,就先不回答了
基础题:
1、谈谈你对Hive内部表、外部表、分区表、分桶表的区别,并介绍一下使用场景
Hive内部表和外部表的区别在于:一个被删除时,元数据和数据全部被删除,一个数据保留,元数据被删除;内部表适用不需要保留数据的场景,外部表仅删除数据,适用保证数据安全的场景.
分区表是在原有数据表的结构上添加分区,这样在扫描时只扫描指定的分区,未指定的分区不扫描,减少了扫描的数量从而加快查询的效率,分桶表是在表和分区的基础上新添加的结构,用于提高join效率及取样,
他们的区别在于:分区表的字段绝对不能出现在数据表结构中,多层分区,其结构是嵌套结构。分桶需要指定分桶字段,且字段必须是数据表中已有的一个字段,分桶表的数据只能通过insert overwrite加载数据。
2、介绍一下Sort By,Order By,Distrbute By,Cluster By的区别
order by 全局排序,只有一个reduce,数据量大时效率较慢 sort by 一个reduce内部排序,不是全局排序。
DISTRIBUTE BY的字段与SORT BY的字段相同时,可以使用CLUSTER BY进行替换,但CLUSTER BY不能指定排序规则(只能是降序),DISTRIBUTE BY+SORT BY可以指定排序规则(可升可降)
思考题:
3、谈谈你所知道有哪些常用的Hive调优方式?
hive的优化很多,我们做项目时70%时间都花在hive的调优上.常见的Hive调优比如并行编译,小文件合并,矢量化查询,读取零拷贝优化,数据倾斜优化等等
关于hive的调优,我曾写过两篇博客专门总结了当时项目中存在的hive调优的点,各位大佬如果感兴趣可以点开链接看看:
链接
链接
基础题:
1、清楚描述 MapReduce 的 shuffle 过程
shuffle过程:分为四步
分区,排序,局部合并,分组
从内存角度看shuffle的过程:
Map将数据传入环形缓冲区(默认100MB),数据达到一定阈值(默认0.8)时,进行溢写生成n个临时文件,临时文件达到10个(可调整)后merge合并成一个大文件,
然后Reduce数据读取,reduce会主动发起拷贝线程到maptask获取属于自己的数据,数据进入到ReduceTask中的环形缓冲区,当达到一定阈值后进行溢写,生成临时文件,临时文件再合并成一个大文件,最后输出到Reduce

2、HBase 的 rowkey 设计需要遵循什么原则,以及如何解决热点问题

思考题:
3、早几年是有很多 elasticsearch /solr 为 mysql 或者 HBase 作二级索引,但是现在 elasticsearch 在不断的加大在大数据领域的支持,是否可以取代 HBase


基础题:
1、谈谈Hadoop里面的压缩格式以及使用场景
常用的压缩格式有LZO,LZ4,Gzip,Bzip2,Snappy,在实际项目开发中一般选用Snappy

思考题:
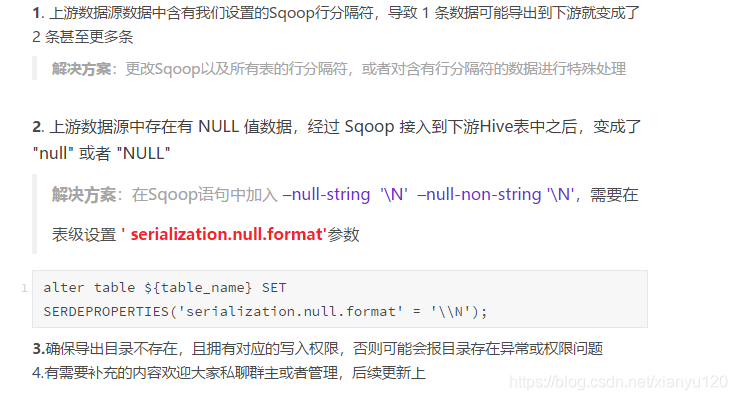
2、Sqoop在导入数据的时候出现了数据倾斜,你有什么解决方案。另外,使用Sqoop的注意事项,你能列举出来几个?
增加split by 解决
具体:
–split by 字段
-m 数量 使用几个Task进行数据采集
使用Sqoop遇到的bug:hdfs文件的权限问题,文件格式问题,没有设置主键,Output directory already exists…
智力题:
3、小鹏汽车充电有两种类型,快充、慢充,有如下数据:
车辆 ID 充电时间 充电类型
a 20200701 20:00:09 1
a 20200701 21:00:09 0
a 20200702 20:00:09 1
a 20200703 11:00:09 1
a 20200704 12:00:09 1
b 20200706 12:00:09 0
a 20200706 12:00:09 0
其中1为快充,0为慢充,求每辆车最长 连续快充次数 ,以上例子结果为
a 3
b 0
请写出对应的SQL
基础题
1、介绍一下拉链表的原理,以及适用于哪些场景?
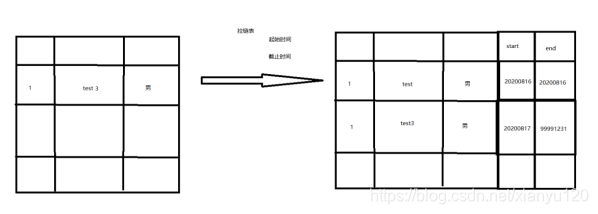
拉链表的原理:说白了就是在原有表基础上增加两个字段,一个start_time,一个end_time
数据如果不变就不动,如果有新数据进来,就将原数据的end_time天数-1(改成前天),start_time不变,新数据的start_time写成今天,end_time设置成9999-12-31
这其中的操作都在新建的两张临时表(update表和tmp表)中进行,它适合最大程度节省存储空间,又能满足数据历史状态的场景
拉链表就是之前我们讲过的SCD2,它的优点是即满足了反应数据的历史状态,又能在最大程度上节省存储。
拉链表的实现需要在原始字段基础上增加两个新字段:
start_time(表示该条记录的生命周期开始时间——周期快照时的状态)
end_time(该条记录的生命周期结束时间)
4.3.1.8.1.2 采集实现步骤
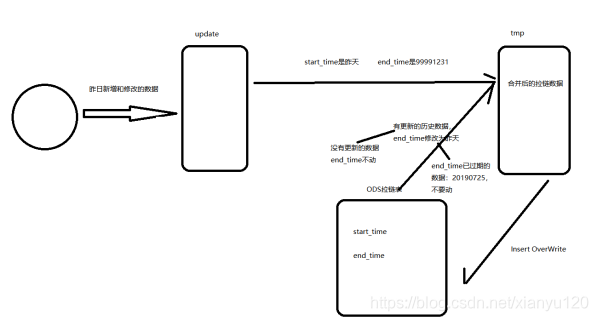
1.建立增量数据临时表update;
2.抽取昨日增量数据(新增和更新)到update表;
3.建立合并数据临时表tmp;
4.合并昨日增量数据(update表)与历史数据(拉链表)
(1)新数据end_time设为’9999-12-31’,也就是当前有效;
(2)如果增量数据有重复id的旧数据,将旧数据end_time更新为前天(昨日-1),也就是从昨天开始不再生效;
(3)合并后的数据写入tmp表;
5.将临时表的数据,覆盖到拉链表中;
6.下次抽取需要重建update表和tmp表。
查询拉链表数据时,可以通过start_time和end_time查询出快照数据。
思考题
2、如果使用spark遇到了 OOM ,你会怎么处理?
智力题