一、引子
文章结合尚硅谷Go语言教程以及博学谷、http://c.biancheng.net/view/3990.html等其他资料整理,侵删
原PDF阅读:
http://xwjpics.gumptlu.work/%E5%B0%9A%E7%A1%85%E8%B0%B7_%E9%9F%A9%E9%A1%BA%E5%B9%B3_Go%E8%AF%AD%E8%A8%80%E6%A0%B8%E5%BF%83%E7%BC%96%E7%A8%8B.pdf
背景介绍
Go语言(或 Golang)起源于 2007 年,并在 2009 年正式对外发布。Go 是非常年轻的一门语言,它的主要目标是“兼具 Python 等动态语言的开发速度和 C/C++ 等编译型语言的性能与安全性”。
Go语言是编程语言设计的又一次尝试,是对类C语言的重大改进,它不但能让你访问底层操作系统,还提供了强大的网络编程和并发编程支持。Go语言的用途众多,可以进行网络编程、系统编程、并发编程、分布式编程。
Go语言的推出,旨在不损失应用程序性能的情况下降低代码的复杂性,具有“部署简单、并发性好、语言设计良好、执行性能好”等优势,目前国内诸多 IT 公司均已采用Go语言开发项目。
Go语言有时候被描述为“C 类似语言”,或者是“21 世纪的C语言”。Go 从C语言继承了相似的表达式语法、控制流结构、基础数据类型、调用参数传值、指针等很多思想,还有C语言一直所看中的编译后机器码的运行效率以及和现有操作系统的无缝适配。
因为Go语言没有类和继承的概念(但是可以实现),所以它和 Java 或 C++ 看起来并不相同。但是它通过接口(interface)的概念来实现多态性。Go语言有一个清晰易懂的轻量级类型系统,在类型之间也没有层级之说。因此可以说Go语言是一门混合型的语言。
此外,很多重要的开源项目都是使用Go语言开发的,其中包括 Docker、Go-Ethereum、Thrraform 和 Kubernetes。
Go语言创始人
对语言进行评估时,明白设计者的动机以及语言要解决的问题很重要。Go语言出自 Ken Thompson 和 Rob Pike、Robert Griesemer 之手,他们都是计算机科学领域的重量级人物。
1) Ken Thompson
贝尔实验室 Unix 团队成员,C语言、Unix 和 Plan 9 的创始人之一,在 20 世纪 70 年代,设计并实现了最初的 UNIX 操作系统,仅从这一点说,他对计算机科学的贡献怎么强调都不过分。他还与 Rob Pike 合作设计了 UTF-8 编码方案。

2) Rob Pike
Go语言项目总负责人,贝尔实验室 Unix 团队成员,除帮助设计 UTF-8 外,还帮助开发了分布式多用户操作系统 Plan 9、Inferno 操作系统和 Limbo 编程语言,并与人合著了《The Unix Programming Environment》,对 UNIX 的设计理念做了正统的阐述。
3) Robert Griesemer
就职于 Google,参与开发 Java HotSpot 虚拟机,对语言设计有深入的认识,并负责 Chrome 浏览器和 Node.js 使用的 Google V8 JavaScript 引擎的代码生成部分。
这些计算机科学领城的重量级人物设计Go语言的初衷是满足 Google 的需求。设计此语言花费了两年的时间,融入了整个团队多年的经验及对编程语言设计的深入认识。设计团队借鉴了 Pascal、Oberon 和C语言的设计智慧,同时让Go语言具备动态语言的便利性。因此,Go语言体现了经验丰富的计算机科学家的语言设计理念,是为全球最大的互联网公司之一设计的。
Go语言的所有设计者都说,设计Go语言是因为 C++ 给他们带来了挫败感。在 Google I/O 2012 的 Go 设计小组见面会上,Rob Pike 是这样说的:
我们做了大量的 C++ 开发,厌烦了等待编译完成,尽管这是玩笑,但在很大程度上来说也是事实。
Go 是编译型语言
Go 使用编译器来编译代码。编译器将源代码编译成二进制(或字节码)格式;在编译代码时,编译器检查错误、优化性能并输出可在不同平台上运行的二进制文件。要创建并运行 Go 程序,程序员必须执行如下步骤。
- 使用文本编辑器创建 Go 程序;
- 保存文件;
- 编译程序;
- 运行编译得到的可执行文件。
这不同于 Python、Ruby 和 JavaScript 等语言,它们不包含编译步骤。Go 自带了编译器,因此无须单独安装编译器。
为什么要学习Go语言
如果你要创建系统程序,或者基于网络的程序,Go语言是很不错的选择。作为一种相对较新的语言,它是由经验丰富且受人尊敬的计算机科学家设计的,旨在应对创建大型并发网络程序面临的挑战。
在Go语言出现之前,开发者们总是面临非常艰难的抉择,究竟是使用执行速度快但是编译速度并不理想的语言(如:C++),还是使用编译速度较快但执行效率不佳的语言(如:.NET、Java),或者说开发难度较低但执行速度一般的动态语言呢?显然,Go语言在这 3 个条件之间做到了最佳的平衡:快速编译,高效执行,易于开发。
Go语言支持交叉编译,比如说你可以在运行 Linux 系统的计算机上开发可以在 Windows 上运行的应用程序。这是第一门完全支持 UTF-8 的编程语言,这不仅体现在它可以处理使用 UTF-8 编码的字符串,就连它的源码文件格式都是使用的 UTF-8 编码。Go语言做到了真正的国际化!
Go语言吉祥物
Go语言有一个吉祥物,在会议、文档页面和博文中,大多会包含下图所示的 Go Gopher,这是才华横溢的插画家 Renee French 设计的,她也是 Go 设计者之一 Rob Pike 的妻子。

Go语言特性
go语言也称为 Golang,是由 Google 公司开发的一种静态强类型、编译型、并发型、并具有垃圾回收功能的编程语言。
接下来从几个方面来具体介绍一下Go语言的特性。
语法简单
抛开语法样式不谈,单就类型和规则而言,Go 与 C99、C11 相似之处颇多,这也是Go语言被冠以“NextC”名号的重要原因。
Go语言的语法处于简单和复杂的两极。C语言简单到你每写下一行代码,都能在脑中想象出编译后的模样,指令如何执行,内存如何分配,等等。而 C 的复杂在于,它有太多隐晦而不着边际的规则,着实让人头疼。相比较而言,Go 从零开始,没有历史包袱,在汲取众多经验教训后,可从头规划一个规则严谨、条理简单的世界。
Go语言的语法规则严谨,没有歧义,更没什么黑魔法变异用法。任何人写出的代码都基本一致,这使得Go语言简单易学。放弃部分“灵活”和“自由”,换来更好的维护性,我觉得是值得的。
将“++”、“–”从运算符降级为语句,保留指针,但默认阻止指针运算,带来的好处是显而易见的。还有,将切片和字典作为内置类型,从运行时的层面进行优化,这也算是一种“简单”。
并发模型
时至今日,并发编程已成为程序员的基本技能,在各个技术社区都能看到诸多与之相关的讨论主题。在这种情况下Go语言却一反常态做了件极大胆的事,从根本上将一切都并发化,运行时用 Goroutine 运行所有的一切,包括 main.main 入口函数。
可以说,Goroutine 是 Go 最显著的特征。它用类协程的方式来处理并发单元,却又在运行时层面做了更深度的优化处理。这使得语法上的并发编程变得极为容易,无须处理回调,无须关注线程切换,仅一个关键字,简单而自然。
搭配 channel,实现 CSP 模型。将并发单元间的数据耦合拆解开来,各司其职,这对所有纠结于内存共享、锁粒度的开发人员都是一个可期盼的解脱。若说有所不足,那就是应该有个更大的计划,将通信从进程内拓展到进程外,实现真正意义上的分布式。
内存分配
将一切并发化固然是好,但带来的问题同样很多。如何实现高并发下的内存分配和管理就是个难题。好在 Go 选择了 tcmalloc,它本就是为并发而设计的高性能内存分配组件。
可以说,内存分配器是运行时三大组件里变化最少的部分。刨去因配合垃圾回收器而修改的内容,内存分配器完整保留了 tcmalloc 的原始架构。使用 cache 为当前执行线程提供无锁分配,多个 central 在不同线程间平衡内存单元复用。在更高层次里,heap 则管理着大块内存,用以切分成不同等级的复用内存块。快速分配和二级内存平衡机制,让内存分配器能优秀地完成高压力下的内存管理任务。
在最近几个版本中,编译器优化卓有成效。它会竭力将对象分配在栈上,以降低垃圾回收压力,减少管理消耗,提升执行性能。可以说,除偶尔因性能问题而被迫采用对象池和自主内存管理外,我们基本无须参与内存管理操作。
垃圾回收
垃圾回收一直是个难题。早年间,Java 就因垃圾回收低效被嘲笑了许久,后来 Sun 连续收纳了好多人和技术才发展到今天。可即便如此,在 Hadoop 等大内存应用场景下,垃圾回收依旧捉襟见肘、步履维艰。
相比 Java,Go 面临的困难要更多。因指针的存在,所以回收内存不能做收缩处理。幸好,指针运算被阻止,否则要做到精确回收都难。
每次升级,垃圾回收器必然是核心组件里修改最多的部分。**从并发清理,到降低 STW 时间,直到 Go 的 1.5 版本实现并发标记,逐步引入三色标记和写屏障等等,都是为了能让垃圾回收在不影响用户逻辑的情况下更好地工作。**尽管有了努力,当前版本的垃圾回收算法也只能说堪用,离好用尚有不少距离。
静态链接
Go 刚发布时,静态链接被当作优点宣传。只须编译后的一个可执行文件,无须附加任何东西就能部署。这似乎很不错,只是后来风气变了。连着几个版本,编译器都在完善动态库 buildmode 功能,场面一时变得有些尴尬。
暂不说未完工的 buildmode 模式,静态编译的好处显而易见。将运行时、依赖库直接打包到可执行文件内部,简化了部署和发布操作,无须事先安装运行环境和下载诸多第三方库。这种简单方式对于编写系统软件有着极大好处,因为库依赖一直都是个麻烦。
标准库
功能完善、质量可靠的标准库为编程语言提供了充足动力。在不借助第三方扩展的情况下,就可完成大部分基础功能开发,这大大降低了学习和使用成本。最关键的是,标准库有升级和修复保障,还能从运行时获得深层次优化的便利,这是第三方库所不具备的。
Go 标准库虽称不得完全覆盖,但也算极为丰富。其中值得称道的是 net/http,仅须简单几条语句就能实现一个高性能 Web Server,这从来都是宣传的亮点。更何况大批基于此的优秀第三方 Framework 更是将 Go 推到 Web/Microservice 开发标准之一的位置。
当然,优秀第三方资源也是语言生态圈的重要组成部分。近年来崛起的几门语言中,Go 算是独树一帜,大批优秀作品频繁涌现,这也给我们学习 Go 提供了很好的参照。
工具链
完整的工具链对于日常开发极为重要。Go 在此做得相当不错,无论是编译、格式化、错误检查、帮助文档,还是第三方包下载、更新都有对应的工具。其功能未必完善,但起码算得上简单易用。
内置完整测试框架,其中包括单元测试、性能测试、代码覆盖率、数据竞争,以及用来调优的 pprof,这些都是保障代码能正确而稳定运行的必备利器。
除此之外,还可通过环境变量输出运行时监控信息,尤其是垃圾回收和并发调度跟踪,可进一步帮助我们改进算法,获得更佳的运行期表现。
二、go基础重点总结
1. 环境变量配置

2. Golang 执行流程分析
- 如果是对源码编译后,再执行,Go 的执行流程如下图

- 如果我们是对源码直接执行go run 源码,Go 的执行流程如下图

- 两种执行流程的方式区别:
- 如果我们先编译生成了可执行文件,那么我们可以将该可执行文件拷贝到没有go 开发环境的机器上,仍然可以运行
- 如果我们是直接go run go 源代码,那么如果要在另外一个机器上这么运行,也需要go 开发环境,否则无法执行。
- 在编译时,编译器会将程序运行依赖的库文件包含在可执行文件中,所以,可执行文件变大了很多。
3. 数据类型
基本数据类型与派生数据类型

特点总结:
-
字符串一旦赋值了,字符串就不能修改了,Go中字符串是不可变的
-
Golang 和java / c 不同,Go 在不同类型的变量之间赋值时需要显式转换。也就是说Golang 中数据类型不能自动转换。
表达式T(v) 将值v 转换为类型T
T: 就是数据类型,比如int32,int64,float32 等等
v: 就是需要转换的变量 -
被转换的是变量存储的数据(即值),变量本身的数据类型并没有变化!

-
如果变量名、函数名、常量名首字母大写并且写在函数外部,则可以被其他的包访问如果首字母小写,则只能在本包中使用.
值类型与引用类型
- 值类型:基本数据类型int 系列, float 系列, bool, string 、数组和结构体struct
- 引用类型:指针、slice 切片、map、管道chain、interface 等都是引用类型
区别: 值类型函数传递复制原值新建存储空间不影响原值,引用类型函数拷贝指针(地址),指向同一个存储空间修改会影响原值
判断值类型还是引用类型的方法,在调用函数和被调用函数之前使用unsafe.Sizeof():
该函数的作用是输出变量的字节大小, 在64位操作系统下, 指针的大小一致均为8字节
4. 运算符
-
Golang 的**++ 和-- 只能写在变量的后面,不能写在变量的前面**即:只有a++ a-- 没有++a
-
Golang 的自增自减只能当做一个独立语言使用,没有返回值,类似i++ > 10 都是错误的
-
短路效应依然存在:&&也叫短路与:如果第一个条件为false,则第二个条件不会判断,最终结果为false
-
||也叫短路或:如果第一个条件为true,则第二个条件不会判断,最终结果为true
-
go不支持三元运算符
优先级表

5. 循环
-
循环遍历中文乱码
如果我们的字符串含有中文,那么传统的遍历字符串方式,就是错误,会出现乱码。
原因是传统的对字符串的遍历是按照字节来遍历,而一个汉字在utf8 编码是对应3 个字节。如何解决需要要将str 转成[]rune 切片

或者使用for-range的方式:
var world = "nihao 北京" for _, val := range world{ fmt.Printf("%c", val) } -
Go 语言没有while 和do…while 语法,用for代替
-
break 语句出现在多层嵌套的语句块中时,可以通过标签指明要终止的是哪一层语句块

-
continue 语句出现在多层嵌套的循环语句体中时,可以通过标签指明要跳过的是哪一层循环,
-
Go 语言的goto 语句可以无条件地转移到程序中指定的行。在Go 程序设计中一般不主张使用goto 语句。
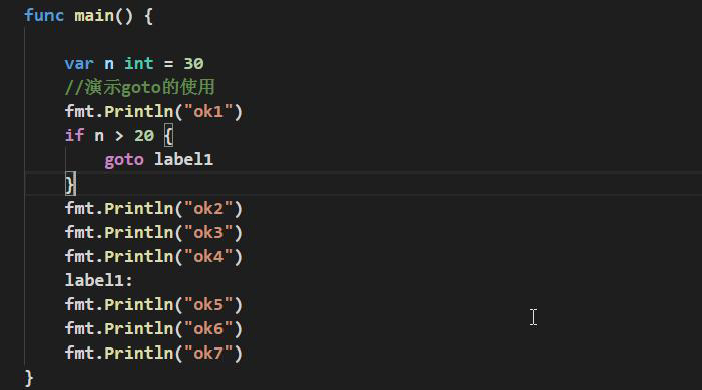
6. 函数和go语言包
6.1 包
-
包的本质实际上就是创建不同的文件夹,来存放程序文件。
-
go 的每一个文件都是属于一个包的,也就是说go 是以包的形式来管理文件和项目目录结构的
-
包的三个作用:
-
区分相同名字的函数、变量等标识符
-
当程序文件很多时,可以很好的管理项目
-
控制函数、变量等访问范围,即作用域
-
-
文件的包名通常和文件所在的文件夹名一致,一般为小写字母。
-
在import 包时,路径从$GOPATH 的src 下开始,不用带src , 编译器会自动从src 下开始引入
-
为了让其它包的文件,可以访问到本包的函数,则该函数名的首字母需要大写
-
在访问其它包函数,变量时,其语法是包名.函数名
-
如果包名较长,Go 支持给包取别名, 注意细节:取别名后,原来的包名就不能使用了

-
同一包下,不能有相同的函数名(也不能有相同的全局变量名),否则报重复定义
-
如果你要编译成一个可执行程序文件,就需要将这个包声明为main , 即package main .这个就是一个语法规范,如果你是写一个库,包名可以自定义

6.2函数
-
基本数据类型和数组默认都是值传递的,即进行值拷贝。在函数内修改,不会影响到原来的值。

-
如果希望函数内的变量能修改函数外的变量(指的是默认以值传递的方式的数据类型),可以传入变量的地址&,函数内以指针的方式操作变量。

-
Go 函数不支持函数重载
-
在Go 中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以对函数调用
func add(a, b int) int { return a + b } func main() { funcAdd := add fmt.Printf("函数的类型是:%T\n", funcAdd) fmt.Printf("%d", funcAdd(2, 7)) //9 } //函数的类型是:func(int, int) int -
函数既然是一种数据类型,因此在Go 中,函数可以作为形参,并且调用
-
支持对函数返回值命名
-
Go 支持可变参数
func addAll(n int, args... int) (sum int) { sum = n for _,val := range args{ sum += val } return } func main() { fmt.Printf("%d", addAll(1,2,3,4,5,6)) } //21
6.3 Init函数
- 每一个源文件都可以包含一个init 函数,该函数会在main 函数执行前,被Go 运行框架调用,也就是说init 会在main 函数前被调用。
- 执行先后顺序:全局变量定义->init函数->main 函数
6.4 匿名函数
如果我们某个函数只是希望使用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用。
//全局匿名函数
var FunMul = func(a, b int) int {
return a * b
}
func main() {
//调用方式1 直接调用 只能调用一次
res := func(a, b int) int {
return a + b
}(2, 4)
fmt.Printf("%d\n", res)
//调用方式2 赋值给变量 可以多次调用
funAdd := func(a,b int) int {
return a + b
}
a := funAdd(1, 4)
b := funAdd(5, 7)
fmt.Println(a, b)
}
6.5 闭包
基本介绍:
闭包就是一个函数和与其相关的引用环境组合的一个整体(实体)
例子:
func AddUpper() func(int) int{
//对n做了初始化,以后每次都不会初始化了,类似于类中的字段
n := 10
str := "Hello"
return func(i int) int {
n += i
str += string(36)
fmt.Printf(str)
return n
}
}
func main() {
upper := AddUpper()
fmt.Printf("%d\n", upper(1))
fmt.Printf("%d\n", upper(2))
fmt.Printf("%d\n", upper(3))
}
/*
Hello$11
Hello$$13
Hello$$$16
*/
函数的理解:
闭包是类, 函数是操作,n 是字段。函数和它使用到n 构成闭包。
我们要搞清楚闭包的关键,就是要分析出返回的函数它使用(引用)到哪些变量,因为函数和它引用到的变量共同构成闭包。
闭包案例:
请编写一个程序,具体要求如下
- 编写一个函数makeSuffix(suffix string) 可以接收一个文件后缀名(比如.jpg),并返回一个闭包
- 调用闭包,可以传入一个文件名,如果该文件名没有指定的后缀(比如.jpg) ,则返回 文件名.jpg , 如果已经有.jpg 后缀,则返回原文件名。
func makeSuffix(suffix string) func(string) string {
return func(s string) string {
if !strings.HasSuffix(s, suffix) {
return s + suffix
}
return s
}
}
func main() {
suffix := makeSuffix(".jpg")
fmt.Println(suffix("xwj.jpg"))
fmt.Println(suffix("xwj"))
fmt.Println(suffix("xwj.java"))
}
/*
xwj.jpg
xwj.jpg
xwj.java.jpg
*/
闭包的好处,如果使用传统的方法,也可以轻松实现这个功能,但是传统方法需要每次都传入后缀名,比如.jpg ,而闭包因为可以保留上次引用的某个值,所以我们传入一次就可以反复使用。大家可以仔细的体会一把!
当函数每次调用参数都需要传递一个常值的时候可以使用闭包封装,其实闭包就是让其中的“环境变量”一次初始化后续不会再初始化而是反复使用
6.6 Defer
在函数中,程序员经常需要创建资源(比如:数据库连接、文件句柄、锁等) ,为了在函数执行完毕后,及时的释放资源,Go 的设计者提供defer (延时机制)。
func test(i, j int) {
defer fmt.Printf("i = %d, j = %d\n", i+10, j+10)
defer fmt.Printf("i = %d, j = %d\n", i+5, j+5)
fmt.Printf("i = %d, j = %d\n", i, j)
}
func main() {
test(10, 10)
}
//10 10
//15 15
//20 20
注意的细节:
-
当go 执行到一个defer 时,不会立即执行defer 后的语句,而是将defer 后的语句压入到一个栈中,然后继续执行函数下一个语句。
-
当函数执行完毕后,在从defer 栈中,依次从栈顶取出语句执行(先入后出)
-
在defer 将语句放入到栈时,也会先将相关的值拷贝同时入栈。请看一段代码:
func test2(i, j int) int { defer fmt.Printf("i = %d, j = %d\n", i+10, j+10) defer fmt.Printf("i = %d, j = %d\n", i+5, j+5) i++ j++ fmt.Printf("i = %d, j = %d\n", i, j) return i+j } func main() { res := test2(10, 20) fmt.Printf("res = %d\n", res) } //i = 11, j = 21 //i = 15, j = 25 //i = 20, j = 30 //res = 32 -
defer 最主要的价值是在,当函数执行完毕后,可以及时的释放函数创建的资源

- 在golang 编程中的通常做法是,创建资源后,比如(打开了文件,获取了数据库的链接,或者是锁资源), 可以执行defer file.Close() defer connect.Close()
- 在defer 后,可以继续使用创建资源.
6.7 函数传参
值类型参数默认就是值传递,而引用类型参数默认就是引用传递。不管是值传递还是引用传递,传递给函数的都是**变量的副本**,不同的是,值传递的是值的拷贝,引用传递的是地址的拷贝,一般来说,地址拷贝效率高,因为数据量小,而值拷贝决定拷贝的数据大小,数据越大,效率越低。
如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&

6.8 变量作用域
函数外部声明/定义的变量叫全局变量,作用域在**整个包都有效,如果其首字母为大写**,则作用域在整个项目程序有效
6.9 字符串常用处理函数
-
len(str) 获取字符串长度
-
r:=[]rune(str) 字符串遍历同时处理有中文的问题
-
字符串转整数: n, err := strconv.Atoi(“12”)
func main() { n, err := strconv.Atoi("12") if err != nil{ fmt.Println(err) }else { fmt.Println(n) } } -
整数转字符串str = strconv.Itoa(12345)
-
字符串转[]byte: var bytes = []byte(“hello go”)
-
[]byte 转字符串: str = string([]byte{97, 98, 99})
-
10 进制转2, 8, 16 进制: str = strconv.FormatInt(123, 2) //第二个参数表示进制
-
查找子串是否在指定的字符串中: strings.Contains(“seafood”, “foo”)
-
统计一个字符串有几个指定的子串: strings.Count(“ceheese”, “e”)
-
不区分大小写的字符串比较(== 是区分字母大小写的): fmt.Println(strings.EqualFold(“abc”,“Abc”)) // true
-
返回子串在字符串第一次出现的index 值,如果没有返回-1 : strings.Index(“NLT_abc”, “abc”)
-
返回子串在字符串最后一次出现的index,如没有返回-1 : strings.LastIndex(“go golang”, “go”)
-
将指定的子串替换成另外一个子串: strings.Replace(“go go hello”, “go”, “go 语言”, n) n 可以指定你希望替换几个,如果n=-1 表示全部替换
-
按照指定的某个字符, 为分割标识, 将一个字符串拆分成字符串数组:strings.Split(“hello,wrold,ok”, “,”)
-
将字符串的字母进行大小写的转换: strings.ToLower(“Go”) // go strings.ToUpper(“Go”) // GO
-
将字符串左右两边的空格去掉: strings.TrimSpace(" tn a lone gopher ntrn ")
-
将字符串左右两边指定的字符去掉: strings.Trim("! hello! “, " !”) // [“hello”] //将左右两边!和" "去掉
-
将字符串左边指定的字符去掉: strings.TrimLeft("! hello! “, " !”) // [“hello”] //将左边! 和""去掉
-
将字符串右边指定的字符去掉:strings.TrimRight("! hello! “, " !”) // [“hello”] //将右边! 和""去掉
-
判断字符串是否以指定的字符串开头: strings.HasPrefix(“ftp://192.168.10.1”, “ftp”) // true
-
判断字符串是否以指定的字符串结束: strings.HasSuffix(“NLT_abc.jpg”, “abc”) //false
6.10 内置函数
-
new:用来分配内存,主要用来分配值类型,比如int、float32,struct…返回的是**指针**
func main() { num1 := 100 num2 := new(int) *num2 = 100 fmt.Printf("num1=%d, num1的地址=%v, num2的值是=%v,*num2=%v, &num2(num2的地址)=%v", num1, &num1, num2, *num2, &num2) } -
make:用来分配内存,主要用来分配引用类型,比如channel、map、slice。
6.11 错误处理
go语言不支持传统的try catch,Go 中引入的处理方式为:defer, panic, recover
Go 中可以抛出一个panic 的异常,然后在defer 中通过Recover 捕获这个异常,然后正常处理
案例:使用defer+recover处理错误:
func main() {
//异常处理函数
defer func() {
err := recover() //recover内置函数可以捕获异常
if err != nil {
fmt.Println("异常出现!")
}
}()
num1 := 10
num2 := 0
res := num1 / num2
fmt.Println(res)
}
进行错误处理后,程序不会轻易挂掉,如果加入预警代码,就可以让程序更加的健壮
自定义错误:
- errors.New(“错误说明”) , 会返回一个error 类型的值,表示一个错误,程序会继续执行
- panic 内置函数,接收一个interface{}类型的值(也就是任何值了)作为参数。可以接收error 类型的变量,输出错误信息,并退出程序.
7.数组
go语言中数组是值类型
数组的定义
var 数组名[数组大小]数据类型 var a [10]int
四种初始化方式
//第一种
var nums1 [4]int = [4]int{
1, 2, 3, 4}
fmt.Println("nums1=", nums1)
//第二种,上一种的省略格式
var nums2 = [4]int{
1, 2, 3, 4}
fmt.Println("nums2=", nums2)
//第三种 [...]规定的写法
var nums3 = [...]int{
8, 9, 10}
fmt.Println("nums3=", nums3)
//第四种
var nums4 = []int{
1: 200, 2: 6000, 3: 800}
fmt.Println("nums4=", nums4)
//第五种
var nums5 = []string{
1: "哈哈", 2: "你好", 3: "啦啦"}
fmt.Println("nums5=", nums5)
数组注意细节
-
数组的长度是固定的。不能变化
-
数组中的元素可以是任何数据类型,包括值类型和引用类型,但是不能混用。
-
Go语言中的数组属于值类型,在默认情况下是值传递, 因此会进行值拷贝
-
如想在其它函数中,去修改原来的数组,可以使用引用传递(指针方式)
func test01(nums [4]int){ for index, val := range nums{ nums[index] = val + 10 } fmt.Println("test01中的数组:",nums) } func test02(nums *[4]int){ for index, val := range nums{ nums[index] = val + 10 } fmt.Println("test02中的数组:", nums) } //值传递与引用传递 //值传递 test01(nums) // 值传递。不改变原数组 fmt.Println("main中的数组:", nums) //引用传递 test02(&nums) fmt.Println("main中的数组:", nums) //test01中的数组: [13 14 15 16] //main中的数组: [3 4 5 6] //test02中的数组: &[13 14 15 16] //main中的数组: [13 14 15 16] -
长度是数组类型的一部分,在传递函数参数时需要考虑数组的长度
8.切片
切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵守引用传递的机制。
切片的使用和数组类似,遍历切片、访问切片的元素和求切片长度len(slice)都一样。
切片的长度是可以变化的,因此切片是一个可以动态变化数组。
基本语法: var 切片名[]类型

- slice 的确是一个引用类型
- slice 从底层来说,其实就是一个数据结构(struct 结构体)
type slice struct {
ptr *[2]int
len int
cap int
}
切片使用的三种方式
-
第一种:对已有数组的引用
-
第二种:make命令 基本语法:var 切片名[]type = make([]type, len, [cap])
参数说明: type: 就是数据类型,len : 大小,cap :指定切片容量,可选, 如果你分配了cap,则要求cap>=len.如果不分配cap那么默认的容量==len
通过make 方式创建的切片对应的数组是由make 底层维护,对外不可见,即只能通过slice 去访问各个元素.
-
第三种:定义一个切片,直接就指定具体数组, 使用原理类似make 的方式
nums := [...]int{
1, 3, 5, 7, 9}
//第一种创建切片的方式
slice := nums[1:3] //[0, 3)
fmt.Println("nums = ", nums)
fmt.Println(cap(nums))
fmt.Println("slice = ", slice)
fmt.Println(len(slice))
fmt.Println(cap(slice))
//第二种创建切片的方式
slice2 := make([]float64, 20)
slice2[1] = 0.23
fmt.Println(slice2)
fmt.Println("slice2 = ", slice2)
fmt.Println(len(slice2))
fmt.Println(cap(slice2))
//第三种方式
slice3 := []string{
"哈哈", "lala", "背景"} //要和数组的创建区分开
fmt.Println("slice3 = ", slice3)
fmt.Println(len(slice3))
fmt.Println(cap(slice3))
方式之间的区别:

方式二只能通过切片访问数组
注意点:
-
切片初始化时,仍然不能越界。范围在[0-len(arr)] 之间,但是可以动态增长.
-
切片定义完后,还不能使用,因为本身是一个空的,需要让其引用到一个数组,或者make 一个空间供切片来使用
-
切片可以继续切片
-
make只能创建slice、map、channel并且返回一个有初始值(非零)的对象
-
用append 内置函数,可以对切片进行动态追加(尾部)
slice := []int{ 1, 2, 3, 4} fmt.Println(slice)//[1 2 3 4] //直接添加元素 slice = append(slice, 5, 7, 9, 10) fmt.Println(slice) //[1 2 3 4 5 7 9 10] //切片添加切片 slice2 := []int{ 55,66,77,88} fmt.Println(slice2)//[55 66 77 88] slice = append(slice, slice2...) fmt.Println(slice2)//[55 66 77 88]-
切片append 操作的本质就是对数组扩容
-
向切片添加元素时,切片的容量会自动增长。1024以下时以两倍的方式增长。
-
go 底层会创建一下新的数组newArr(安装扩容后大小)
-
将slice 原来包含的元素拷贝到新的数组newArr
-
slice 重新引用到newArr
-
注意newArr 是在底层来维护的,程序员不可见.

-
-
切片的拷贝操作
切片使用copy 内置函数完成拷贝,注意拷贝的两者间空间独立
slice := []int{ 2, 3, 4, 4, 6, 8} slice2 := make([]int, 20) copy(slice2, slice) fmt.Println("slice = ", slice) fmt.Println("slice2 = ", slice2)//slice2 = [2 3 4 4 6 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0] slice[0] = 9999 fmt.Println(slice2[0])//2 -
切片是引用类型,底层是一个指向数组的结构体,所以在传递时,遵守引用传递机制,拷贝的原来的地址值,这样对指向一个地址可以操作,所以能够实现对原值的修改

-
切片在函数中的调用,当需要对slice做插入和删除时,由于需要更改长度字段,值拷贝就不行了,需要传slice本身在内存中的地址。
例如:
func main() { //res := []int{} res := make([]int, 0) appendItem(res) fmt.Printf("res %v\n", res) //res [] } func appendItem(res []int) { res = append(res, 1) res = append(res, 2) res = append(res, 3) }append在函数中并没有效果,需要传递slice本身在内存中的地址:
func main() { //res := []int{} res := make([]int, 0) appendItem(&res) fmt.Printf("res %v\n", res) //res [1 2 3] } func appendItem(res *[]int) { *res = append(*res, 1) *res = append(*res, 2) *res = append(*res, 3) }
string 和 slice
-
string 底层是一个byte 数组,因此string 也可以进行切片处理
字符串的底层数据结构:
type StringHeader struct { Data uintptr //指向底层的字节数组 Len int //字符串字节长度 }字符串其实是一个结构体,因此字符串的赋值操作也就是reflect.StringHeader结构体的复制过程,并不会涉及底层字节数组的复制
-
string 是不可变的(只读),也就说不能通过str[0] = ‘z’ 方式来修改字符串

string1 := "xxxxww"
s2 := string1
tmp := []byte(s2)
tmp[0] = 'A'
s2 = string(tmp) //底层重新生成了字符数组
fmt.Println(string1) //xxxxww 字符串不能修改
fmt.Println(s2) //Axxxww 新的字符串数组
fmt.Println(&string1, &s2) //两者地址不同 但是指向同一个字节数组
slice := []int{
1, 3}
slice2 := slice
slice2[0] = 4
fmt.Println(slice)//[4 3] 切片复制是同一个空间的引用复制,能修改值
- 如果需要修改字符串,可以先将string -> []byte / 或者 []rune -> 修改-> 重写转成string
9. Map
基本语法:
var map 变量名 map[key type] value type
key可以为很多类型(能用==判断的类型均可,所以slice、map、function不可以),但是一般为int、string
简单的申明:
func main() {
//声明
//声明是不会分配内存的
var a map[int]string
//赋值会报错
a[1] = "啊哈哈"
fmt.Println(a[1])
}
声明是不会分配内存的,初始化需要make ,分配内存后才能赋值和使用。
//make申请内存
a = make(map[int]string, 10) //第二个参数是len
//创建map映射的简洁方式
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
//创建map的第三种方式 声明+创建内存+赋值
a2 := map[int]string{
0 : "1",
1 : "哈哈",
}
fmt.Println(a2)
增删改查/遍历
-
增加/修改: map[“key”] = value //如果key 还没有,就是增加,如果key 存在就是修改。
-
删除: delete(map,“key”) ,delete 是一个内置函数,如果key 存在,就删除该key-value,如果key 不存在,不操作,但是也不会报错
如果要删除全部的key,没有便捷的方法一次性删除,可以先遍历所有key一个一个删除,或者直接新建一个map,让原来的自动被gc回收
-
查找 val, ok := map[“key”]
people := map[int]string{ 0 : "蜘蛛侠", 1 : "美国队长", } val, ok := people[3] //返回ok是bool值 if ok{ fmt.Println(val) }else { fmt.Println("没有1",ok) } -
map的遍历:for-range
for k, v := range intmap { .... } //也可以省略v, 只遍历key for k := range intmap { .... } -
判断key是否存在
func main() { stringMap := make(map[int]string) stringMap[1] = "sdhau" stringMap[2432] = "dad" //判断key是否存在 if k, has := stringMap[1]; has{ fmt.Println(k) } }
map的切片数组
切片的元素数据类型如果是map,那么称为map切片或map的切片数组
func main() {
var mapSlice []map[string]string
//切片本身需要make 创建一个切片数组长度为2,其中的元素是map[string]string类型(未分配空间)
mapSlice = make([]map[string]string, 2)
if mapSlice[0] == nil{
//重点:因为Map不是简单数据类型,所以在使用的时候也需要先make
mapSlice[0] = make(map[string]string, 2)
mapSlice[0]["啊哈哈"] = "噜啦啦"
mapSlice[0]["玩玩"] = "怎么说"
}
if mapSlice[1] == nil {
mapSlice[1] = make(map[string]string, 2)
mapSlice[1]["啦啦"] = "dnjak"
mapSlice[1]["xi"] = "das"
//虽然申请了两个空间但是map会动态增加,所以还是可以添加
mapSlice[1]["dsadsa"] = "2312"
mapSlice[1]["das"] = "2312"
mapSlice[1]["vcx"] = "2312"
}
//这里写法会导致数组越界
//if mapSlice[2] == nil {
// mapSlice[2] = make(map[string]string, 2)
// mapSlice[2]["啦啦"] = "dnjak"
// mapSlice[2]["xi"] = "das"
// //虽然申请了两个空间但是会动态增加,所以还是可以添加
// mapSlice[2]["dsadsa"] = "2312"
//}
//我们需要使用到切片的append函数,动态的增加切片空间
newMap := map[string]string{
"火云邪神" : "哈哈哈",
"加油" : "哈哈哈",
}
//添加到map切片中
mapSlice = append(mapSlice, newMap)
//[map[啊哈哈:噜啦啦 玩玩:怎么说] map[das:2312 dsadsa:2312 vcx:2312 xi:das 啦啦:dnjak] map[加油:哈哈哈 火云邪神:哈哈哈]]
fmt.Println(mapSlice)
}
map排序
map的key是无序的,所以每次遍历得到的结果可能都不一样
golang 中没有一个专门的方法针对map 的key 进行排序
golang 中map 的排序,是先将key 进行排序,然后根据key 值遍历输出即可
func main() {
newMap := map[string]string{
"牛魔王" : "25",
"孙悟空" : "52",
}
//对map排序
keys := make([]string, 1)
for k := range newMap{
keys = append(keys, k)
}
//排序
sort.Strings(keys)
fmt.Println("排序后的keys: ", keys)
//排序后的keys: [ 孙悟空 牛魔王]
//输出
for _, k := range keys{
fmt.Println(newMap[k]) //52 25
}
}
map中判断Key是否存在:
if k, has := stringMap[1]; has{
fmt.Println(k)
}
注意事项
-
go中的map的key也不能重复,重复赋值取最后一个赋值
-
go中的map无序存储
-
映射map分配空间大小取决于make中的size参数,但是产生的映射长度为0(初始),size可以省略,系统会默认分配一个小的起始大小0
-
map中没有cap容量的定义

-
map 是引用类型,遵守引用类型传递的机制(复制指针/地址的值),在一个函数接收map,修改后,会直接修改原来的map
func main() { newMap := map[int]string{ 1:"洗洗", 2:"哈哈", } changeMap(newMap) //引用类型改变原数据 fmt.Println(newMap[1]) //啦啦 var newMapSlice []map[int]int newMapSlice = make([]map[int]int, 1) newMapSlice[0] = make(map[int]int, 2) newMapSlice[0][1] = 100 newMapSlice[0][2] = 200 changeMapSlice(newMapSlice) fmt.Println(newMapSlice[0][1]) //300 同样被修改 changeMapSlice2(newMapSlice[:]) //切片的切片 fmt.Println(newMapSlice[0][2]) //900 同样修改 } func changeMap(m map[int]string) { //修改map m[1] = "啦啦" } func changeMapSlice(ms []map[int]int) { //修改map切片 ms[0][1] = 300 } func changeMapSlice2(ms []map[int]int) { //修改map切片 ms[0][2] = 900 } -
map能够自动扩容动态的增长键值对(不用写append),并不会发生panic,而map的slice数组动态增长则需要使用append函数; 普通数组大小固定,但是数组切片可以使用append函数动态增长
10. 面向对象编程
-
Golang 也支持面向对象编程(OOP),但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言,所以我们说Golang 支持面向对象编程特性是比较准确的。
-
Golang 是基于struct 来实现OOP 特性的。
-
Golang 面向对象编程非常简洁,去掉了传统OOP 语言的继承、方法重载、构造函数和析构函数、隐藏的this 指针、泛型等等
-
Golang 仍然有面向对象编程的继承,封装和多态的特性,只是实现的方式和其它OOP 语言不一样,比如继承:Golang 没有extends 关键字,继承是通过匿名字段来实现。
-
Golang 面向对象(OOP)很优雅,OOP 本身就是语言类型系统(type system)的一部分,通过接口(interface)关联,耦合性低,也非常灵活。在Golang 中面向接口编程是非常重要的特性。
结构体变量(实例)在内存的布局:

10.1 结构体基本语法
注意: 结构体是类型定义, 即定义中不能赋值也不能用var等关键字, 可以把它看作是类似于Bool、int、string等类型
type 结构体名称 struct {
field1 type
field2 type
}
//举例:
type Student struct {
Name string //字段
Age int //字段
Score float32
}
// 或者使用new函数创建结构体指针
var stu *Stuent
stu = new(Stuent)
字段/属性
一般是基本数据类型、数组,也可是引用类型
字段如果没有分配值则为默认值,特别的,指针,slice,和map 的零值都是nil ,即还没有分配空间。
想要外部调用结构体字段,结构体字段首字母要大写!!!一般都是大写
结构体是值类型,默认是值拷贝,互不影响。
创建结构体变量的方式:
type Cat struct {
Name string
Age int
Color string
Hobby string
}
func main() {
//第一种方式
var cat1 Cat
cat1.Name = "波斯猫"
cat1.Age = 3
cat1.Color = "yellow"
cat1.Hobby = "睡觉"
//第二种方式
cat2 := Cat{
Name: "",
Age: 0,
Color: "",
Hobby: "",
}
fmt.Println(cat2)
//或者
//var cat2 Cat = Cat{
// Name: "",
// Age: 0,
// Color: "",
// Hobby: "",
//}
//第三种方式 new
//注意返回值必须是结构体指针
var cat3 *Cat = new(Cat)
(*cat3).Name = "橘猫"
//等价于
cat3.Name = "橘猫" //go的设计上对指针进行的优化,底层会对cat3.Name 进行处理,给其加上取地址即(*cat3).Name
fmt.Println(cat3.Name)
//第四种方式 &{}
//var cat4 = &Cat{} //可以直接赋值 也可以后面赋值
var cat4 = &Cat{
Name: "haha",
Age: 0,
Color: "",
Hobby: "",
}
fmt.Println(cat4)
}
注:
- 第三第四种返回的是结构体指针
- *结构体指针的标准方式是(*p).Name 但是Go语言的设计者在底层进行了处理,所以p.Name 等同于(p).Name
- (*p).Name 不能写成 *p.Name 因为 . 的优先级高于 *
方法
Golang 中的方法是作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是struct。比如int , float32 等都可以有方法
语法:
type A struct {
Num int
}
func (a A) test() {
fmt.Println(a.Num)
}
test方法与结构体A是绑定的
test 方法只能通过Person 类型的变量来调用,而不能直接调用,也不能使用其它类型变量来调用
func (p Person) test() {}… p 表示哪个Person 变量调用,这个p 就是它的副本, 这点和函数传参非常相似。
注意点:
-
如果一个类型实现了String()这个方法,那么fmt.Println 默认会调用这个变量的String()进行输出
type School struct { Name string Size int64 } func (s School) String() string { str := fmt.Sprintf("学校名:%s, 大小:%d", s.Name, s.Size) return str } func main() { s1 := School{ Name: "cqupt", Size: 10000, } //学校名:cqupt, 大小:10000 fmt.Println(s1) }
方法与普通函数的区别:
-
对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然

-
对于方法,接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以
type Room struct { Name string Size int64 } func (r Room) method01() { fmt.Println("哈哈哈") } func (r *Room) method02() { fmt.Println("哈哈哈") } func main() { r1 := Room{ Name: "海景房", Size: 10000000, } r1.method01() (&r1).method02() //这样是标准的写法 r1.method02() //不用取地址也是可以的 }
不管调用形式如何,真正决定是值拷贝还是地址拷贝,看这个方法是和哪个类型绑定.
如果是和值类型,比如(p Person) , 则是值拷贝, 如果和指针类型,比如是(p *Person) 则是地址拷贝。
10.2 细节与注意点
- 结构体指针的直接赋值不会创建新的内存,和原来的内存共享
type Dog struct {
Name string
Age int
Color string
Hobby string
}
func main() {
dog01 := Dog{
Name: "旺财",
Age: 10,
Color: "",
Hobby: "",
}
var dog02 *Dog = &dog01
dog02.Age = 20
fmt.Println(dog01.Age) //20 指向同一处
}
-
结构体的所有字段在内存中是连续的
-
结构体是用户单独定义的类型,和其它类型进行转换时需要有完全相同的字段(名字、个数和类型、定义的顺序也要相同)
-
结构体进行type 重新定义(相当于取别名),Golang 认为是新的数据类型,但是相互间可以强转
type People struct { Name string Age int Color string Hobby string } //使用 type对结构体重命名 type P People func main() { var p1 People var p2 P //这样是错误的, 即使是重命名也需要强制类型转换 //p2 = p1 p2 = P(p1) //正确的写法 p2.Name = "姐姐" fmt.Println(p2) }
-
struct 的每个字段上,可以写上一个tag, 该tag 可以通过反射机制获取,常见的使用场景就是序列化和反序列化。
因为结构体的额字段一般都是首字母大写,序列化后返回给客户端的json字符串的字段也是大写,这可能会导致客户端的不适应,所以可以使用tag来命名一个小写的名字,通过反射机制获取
type mao struct { Name string `json:"name"` Age int `json:"age"` Color string `json:"color"` Hobby string `json:"hobby"` } func main() { //创建一个对象 p1 := mao{ Name: "小阳", Age: 80, Color: "", Hobby: "", } //序列化 //如果把字段写成小写的,那么json.Marshal则为空串,因为变为私有 //改进的方法就是设置tag jsonP, err := json.Marshal(p1) if err != nil { fmt.Println(err) }else { fmt.Printf("%s", jsonP) //设置tag前: {"Name":"小阳","Age":80,"Color":"","Hobby":""} //设置后: {"name":"小阳","age":80,"color":"","hobby":""} } }
-
什么地方可以省略(*P)(底层自动编译)什么地方必须用指针类型
1.不考虑
-
使用结构体的字段的时候,不管是结构体指针还是结构体都可以直接使用 “.” 语法取字段
-
调用结构体绑定的方法的时候,不管指定的是指针还是结构体都可以直接使用
2.要标准
- 函数传参数的时候,参数为值类型就值类型,参数要求指针类型就需要传地址
-
10.3 工厂模式
Golang 的结构体没有构造函数,通常可以使用工厂模式来解决这个问题。
解决的问题:
-
使用工厂模式实现跨包创建结构体实例(变量)的案例:
当结构体名小写时,其他包就不能调用该结构体,这时除了改为大写之外还可以使用工厂模式
model包中的people.go
package model type People struct { //注意全部为小写,外部无法引用 name string age int phone int8 sex string } //工厂模式解决 func NewPeople(name string, age int) *People { //数据创建在此处,向外返回他的指针 return &People{ name: name, age: age, phone: 0, sex: "", } } //小写字段,外部访问不到 需要使用此方式get set func (p *People) GetName() string { return p.name } func (p *People) SetName(name string) { p.name = name }main包中的引用main.go
package main import ( "fmt" "heima_GO/day04/model" ) func main() { p1 := model.NewPeople("xwj", 15) //此处的p1是指针 fmt.Println(p1) fmt.Println(*p1) //注意:如果引用的包的字段是小写的,即使获取到了实例对象,其字段也无法使用 //fmt.Println(p1.name) //解决:在model包中添加专门的调用方法 fmt.Println(p1.GetName()) p1.SetName("xy") fmt.Println(p1.GetName()) }
注意工厂模式返回的数据结构,每调用一次都会生成一个新的存储空间并返回指针供使用,所以多个之间是不会有影响的
10.4 封装
封装(encapsulation)就是把抽象出的字段和对字段的操作封装在一起,数据被保护在内部,程序的其它包只有通过被授权的操作(方法),才能对字段进行操作
10.5 继承
出现代码冗余,不利于维护也不利于拓展,需要提高代码的复用性
在Golang 中,如果**一个struct 嵌套了另一个匿名结构体**,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承特性。

基本语法:
type Goods struct {
Name string
Price int
}
type Book struct {
Goods //这里就是嵌套匿名结构体Goods
Writer string
}
type student struct {
person //上一个结构体
classroom string
}
继承细节说明:
-
结构体可以使用嵌套匿名结构体所有的字段和方法(不管大小写),即:首字母大写或者小写的字段、方法,都可以使用。
-
当结构体和匿名结构体有相同的字段或者方法时,编译器采用就近访问原则访问,如希望访问匿名结构体的字段和方法,可以通过匿名结构体名来区分
type student struct { person Name string classroom string } func (s *student) GetName() string { return s.Name //返回student的Name(就近原则) } func (s *student) GetName2() string { return s.person.Name //返回person的Name } -
结构体嵌入两个(或多个)匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时,就必须明确指定匿名结构体名字,否则编译报错
-
如果一个struct 嵌套了一个有命名的结构体,这种模式就是**组合而不是继承**,如果是组合关系,那么在访问组合的结构体的字段或方法时,必须带上结构体的名字
func main() { student := model.NewStudent("无名", "有名", "学生自己的名字", "cqupt") fmt.Println(student.Name) //学生自己的名字 fmt.Println(student.Person.Name) //无名 fmt.Println(student.P1.Name) //有名 }student.go
type Person struct { Name string age int // 隐私字段小写 sal float64 // } type student struct { Person P1 Person //有名的结构体 Name string classroom string } func NewStudent(name1, name2, name3 string, cr string) *student { return &student{ Person: Person{ Name: name1}, P1: Person{ Name: name2}, Name: name3, classroom: cr, } } -
嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值
-
在Go中基本数据类型字段也是可以匿名的,但是需要注意的是匿名字段不能重复不然无法区分
type GoodStudent struct { student int //基本类型匿名字段 ID int //添加了名字,所以还是可以区分的 //int //再添加一个就会报错 }func main() { goodStudent := new(model.GoodStudent) goodStudent.ID = 15 goodStudent.SetInt(52) fmt.Println("int : ", goodStudent.GetInt()) //52 fmt.Println("ID :", goodStudent.ID) //15 }
多重继承
一个struct 嵌套了多个匿名结构体,那么该结构体可以直接访问嵌套的匿名结构体的字段和方法,从而实现了多重继承。
如嵌入的匿名结构体有相同的字段名或者方法名,则在访问时,需要通过匿名结构体类型名来区分。
10.6 接口
interface 类型可以定义一组方法,但是这些不需要实现。并且**interface 不能包含任何变量。**
type Usb interface {
Start()
Stop()
}
type Iphone struct {
}
func (i *Iphone) Start() {
fmt.Println("开机")
}
func (i * Iphone) Stop() {
fmt.Println("关机")
}
-
接口里的所有方法都没有方法体,即接口的方法都是没有实现的方法。接口体现了程序设计的多态和高内聚低偶合的思想。
-
Golang 中的接口,不需要显式的实现。**只要一个变量,含有接口类型中的所有方法,那么这个变量就实现这个接口。**因此,Golang 中没有implement 这样的关键字
细节:
-
接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量
-
在Golang 中,一个自定义类型需要将某个接口的所有方法都实现,我们说这个自定义类型实现了该接口。
-
一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接口类型
-
只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型。

-
一个自定义类型可以实现多个接口
type Usb interface { Start() Stop() } type Usb2 interface { Restart() } type Iphone struct { name string } func (i *Iphone) Start() { fmt.Println("开机") } func (i * Iphone) Stop() { fmt.Println("关机") } func (u *Iphone) Restart() { fmt.Println("重启") } func main() { phone := Iphone{ } phone.Start() phone.Stop() phone.Restart() } -
Golang 接口中不能有任何变量
-
一个接口(比如A 接口)可以继承多个别的接口(比如B,C 接口),这时如果要实现A 接口,也必须将B,C 接口的方法也全部实现。
-
interface 类型默认是一个指针(引用类型),如果没有对interface 初始化就使用,那么会输出nil
-
空接口interface{} 没有任何方法,所以所有类型都实现了空接口, 即我们可以把任何一个变量赋给空接口。
-
体会两种实现接口方式的区别:
//这里是iphone结构体本身实现了接口方法 func (i Iphone) Start() { fmt.Println("开机") } func (i Iphone) Stop() { fmt.Println("关机") } func (i Iphone) Restart() { fmt.Println("重启") } //这里是iphone结构体的指针实现了接口方法 //func (i *Iphone) Start() { // fmt.Println("开机") //} //func (i * Iphone) Stop() { // fmt.Println("关机") //} // //func (i *Iphone) Restart() { // fmt.Println("重启") //} func main() { phone := Iphone{ } var a Usb = phone //本身实现方法 // var b Usb = &phone //结构体指针实现了方法 a.Start() a.Stop() }
接口与继承
当A 结构体需要扩展功能,同时不希望去破坏继承关系,则可以去实现某个接口即可,因此我们可以认为:实现接口是对继承机制的补充.

-
继承的价值主要在于:解决代码的复用性和可维护性。
-
接口的价值主要在于:设计,设计好各种规范(方法),让其它自定义类型去实现这些方法。
接口比继承更加灵活,继承是满足is - a 的关系,而接口只需满足like - a 的关系
接口在一定程度上实现代码解耦
10.7 多态
在Go 语言,多态特征是通过接口实现的
type USB interface {
Start()
End()
}
type telphone struct {
}
func (t telphone) Start() {
fmt.Println("手机启动")
}
func (t telphone) End() {
fmt.Println("手机关闭")
}
type camera struct {
}
func (c camera) Start() {
fmt.Println("相机启动")
}
func (c camera) End() {
fmt.Println("相机关闭")
}
func Work(usb USB) {
//多态的使用
usb.Start()
usb.End()
}
func main() {
t := telphone{
}
c := camera{
}
Work(t)
Work(c)
}
10.8 类型断言
接口 => 具体实现类

func main() {
var x interface{
}
var b2 float64 = 1.23
x = b2 //空接口可以接受任何类型
y := x.(float64) //断言
fmt.Printf("y的类型是%T, 值是%v\n", y, y) //y的类型是float64, 值是1.23
}
在进行类型断言时,如果类型不匹配,就会报panic, 因此进行类型断言时,要确保原来的空接口指向的就是断言的类型.
=> 在进行断言时,带上检测机制,如果成功就ok,否则也不要报panic
func main() {
var x interface{
}
var b2 float64 = 1.23
x = b2 //空接口可以接受任何类型
y := x.(float64)
fmt.Printf("y的类型是%T, 值是%v\n", y, y) //y的类型是float64, 值是1.23
//类型断言带检测
if z, ok := x.(float64); ok{
//注意这里特殊的语法
fmt.Printf("z的类型是%T, 值是%v\n", z, z)
}else {
fmt.Println("error")
}
fmt.Println("继续执行")
}
11. 文件操作

os.File 封装所有文件相关操作,File 是一个结构体
打开关闭文件
-
打开关闭文件
func main() { file, err := os.Open("../111.txt") if err != nil { fmt.Println("打开文件出错", err) } fmt.Printf("file=%v",file) //关闭文件 err = file.Close() if err != nil { fmt.Println("关闭文件失败!", err) } }
Open读取文件
-
读取文件的内容并显示在终端(带缓冲区的方式),适合大文件慢慢读
func main() { file, err := os.Open("../111.txt") if err != nil { fmt.Println(err) } //使用defer 最后关闭资源 defer file.Close() reader := bufio.NewReader(file) for{ //按行读取 str, err := reader.ReadString('\n') if err == io.EOF { break } fmt.Println(str) } } -
读取文件的内容并显示在终端(使用ioutil 一次将整个文件读入到内存中),这种方式适用于文件不大的情况
func main() { file := "../111.txt" //ioutil.ReadFile是隐性的读取文件,不需要close //返回值是[]byte bytes, err := ioutil.ReadFile(file) if err != nil { fmt.Println(err) } fmt.Printf("%s", string(bytes)) }
OpenFile读取文件
func [OpenFile]
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/O。如果出错,错误底层类型是*PathError。

func main() {
//os.O_WRONLY | os.O_CREATE 只可以写,如果没有该文件就创建
file, err := os.OpenFile("../111.txt", os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Println(err)
return
}
//延迟关闭
defer file.Close()
str := "hello Garden\n"
//创建带缓冲的writer
writer := bufio.NewWriter(file)
//写入
writer.Write([]byte(str))
//因为Writer是带有缓存机制的
//所以内容其实是先写进缓存中,然后需要手动调用flush函数
//才写入到文件中
writer.Flush()
}
打开一个存在的文件,在原来的内容追加内容:
func main() {
//打开一个存在的文件,在原来的内容追加内容 os.O_APPEND
file, err := os.OpenFile("../111.txt", os.O_WRONLY | os.O_APPEND, 0666)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
writer := bufio.NewWriter(file)
defer writer.Flush()
i , err := writer.Write([]byte("你是猪吗"))
if err != nil {
fmt.Println(err)
}
fmt.Println("写入的字符数:", i) //一个中文算三个字符
}
打开一个存在的文件,将原来的内容读出显示在终端,并且追加5 句"hello,北京!"
func main() {
file, err := os.OpenFile("../111.txt", os.O_RDWR|os.O_APPEND, 0666)
if err != nil {
fmt.Println(err)
}
defer file.Close()
//读取文件
reader := bufio.NewReader(file)
for true {
str, err := reader.ReadString('\n') //一行一行读取
if err == io.EOF {
//如果读到文件的末尾
break
}
fmt.Printf("%s", str)
}
writer := bufio.NewWriter(file)
defer writer.Flush()
writer.Write([]byte("\r\n北京你好!"))
}
文件的复制:
使用bufio(带缓冲区的方法读)
//文件的复制
func main() {
file1, file2 := "../111.txt", "../222.txt"
//打开第一个文件
from, err := os.OpenFile(file1, os.O_RDONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Println("打开读出文件失败", err)
}
//打开第二个文件
to, err := os.OpenFile(file2, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Println("打开写入文件失败", err)
}
defer to.Close() //先关上写 在关读
defer from.Close()
//读取第一个文件内容
reader := bufio.NewReader(from)
writer := bufio.NewWriter(to)
defer writer.Flush()
for true {
//按行读取
str, err := reader.ReadString('\n')
//写入
_, werr := writer.Write([]byte(str))
if werr != nil{
fmt.Println(werr)
}
if err == io.EOF {
//读完了
break
}
}
fmt.Println("复制结束")
}
判断文件是否存在

func PathExists(path string) (bool, error) {
_, err := os.Stat(path)
if err == nil{
//文件存在
return true, nil
}else if os.IsNotExist(err) {
//文件不存在
return false, nil
}
return false, err
}
文件拷贝
io 包: func Copy(dst Writer, src Reader) (written int64, err error)
//文件copy的简便方法
func main() {
written, err := CopyFile("../meixi.png", "../hah.png")
if err != nil {
fmt.Println(err)
}
fmt.Println(written)
}
func CopyFile(file1 string, file2 string) (written int64, err error) {
from, err := os.OpenFile(file1, os.O_RDONLY|os.O_CREATE, 0666)
defer from.Close()
if err != nil {
fmt.Println("打开文件失败:", err)
}
reader := bufio.NewReader(from)
to, err := os.OpenFile(file2 , os.O_WRONLY|os.O_CREATE, 0666)
defer to.Close()
writer := bufio.NewWriter(to)
return io.Copy(writer, reader)
}
命令行参数
os.Args 是一个string 的切片,用来存储所有的命令行参数
func main() {
//0 : C:\Users\Administrator\AppData\Local\Temp\go-build253394010\b001\exe\cmd.exe
//1 : 1
//2 : 2
//3 : 3
//4 : 4
//5 : 5
//6 : 6
for i:=0; i<len(os.Args); i++ {
fmt.Println(i, " : ", os.Args[i])
}
}
- 解析带有指定参数形式的命令行。
比如:cmd>main.exe -f c:/aaa.txt -p 200 -u root这样的形式命令行,go 设计者给我们提供了flag包,可以方便的解析命令行参数,而且参数顺序可以随意
func main() {
//cmd>main.exe -f c:/aaa.txt -p 200 -u root
var file string
var port int
var username string
//func StringVar(p *string, name string, value string, usage string)
//"f" : name, 指定-f接收的参数
//" " : value, 默认值
//"用户名": usage, 说明
flag.StringVar(&file, "f", "", "用户名")
flag.IntVar(&port, "p", 8080, "端口")
flag.StringVar(&username, "u", "", "用户名")
//!!!最为重要的方法: 转换 必须调用
flag.Parse()
fmt.Println(file, port, username)
}
json


序列化
go中使用json序列化
type pig struct {
Name string `json:"pigName"` //希望序列化重新制定那么使用tag标签(反射机制),注意中间不要有空格
Age int
Fit bool
nickName string //注意小写的不会被序列化
}
func main() {
newPig := new(pig)
newPig.Name = "xx"
newPig.Age = 18
newPig.Fit = true
newPig.nickName = "xy"
//序列化
bytes, err := json.Marshal(newPig)
if err != nil {
fmt.Println(err)
}
fmt.Printf("%s", string(bytes))
}
注意:
- Name string
json:"pigName"//希望序列化重新制定那么使用tag标签(反射机制),注意中间不要有空格 - nickName string //注意结构体中小写的不会被序列化
反序列化
type pig struct {
Name string `json:"pigName"` //希望序列化重新制定那么使用tag标签(反射机制),注意中间不要有空格
Age int
Fit bool
nickName string //注意小写的不会被序列化
}
func main() {
str := "{\"pigName\":\"xx\",\"Age\":18,\"Fit\":true}"
var newpig pig //这里创建的了对应的对象,是有存储空间的
//反序列化
err := json.Unmarshal([]byte(str), &newpig)
if err != nil {
fmt.Println(err)
}
fmt.Println(newpig) //&{xx 18 true }
}
-
在反序列化一个json 字符串时,要确保反序列化后的数据类型和原来序列化前的数据类型一致
-
如果json 字符串是通过程序获取到的,则不需要再对“ 转义处理。
-
反序列化的参数不能是纯指针没有具体的指向,创建时如果要创建纯指针也需要new结构体,或者直接创建结构体本身再取指针
//正确的写法 var resMonster *Monster resMonster = new(Monster) err = json.Unmarshal([]byte(readString), resMonster)
12. 单元测试
testing 测试框架
Go 语言中自带有一个轻量级的测试框架testing 和自带的go test 命令来实现单元测试和性能测试,testing 框架和其他语言中的测试框架类似,可以基于这个框架写针对相应函数的测试用例,也可以基于该框架写相应的压力测试用例。通过单元测试,可以解决如下问题:
- 确保每个函数是可运行,并且运行结果是正确的
- 确保写出来的代码性能是好的,
- 单元测试能及时的发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决,而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
package testing
import "testing"
testing 提供对 Go 包的自动化测试的支持。通过 go test 命令,能够自动执行如下形式的任何函数:
func TestXxx(*testing.T)
其中 Xxx 可以是任何字母数字字符串(但第一个字母不能是小写 [a-z]),用于识别测试例程。
在这些函数中,使用 Error, Fail 或相关方法来发出失败信号。
注意:函数开头的Test是固定的写法,后面的Xxx第一个字母要大写**
使用例子:
import "testing"
func TestAddUpper(t *testing.T) {
res := AddUpper(10)
if res != 11{
t.Fatalf("代码计算错误%v\n", res)
}
//如果正确就输出日志
t.Logf("代码正确%v\n",res)
}
没有主函数也可以执行

test框架大致的原理

- **测试用例文件名必须以_test.go 结尾。**比如cal_test.go , cal 不是固定的。
- 测试用例函数必须以Test 开头,一般来说就是Test+被测试的函数名,比如TestAddUpper
- TestAddUpper(t tesing.T) 的形参类型必须是testing.T
- 一个测试用例文件中,可以有多个测试用例函数,比如TestAddUpper、TestSub
- 运行测试用例指令:
(1) cmd>go test [如果运行正确,无日志,错误时,会输出日志]
(2) cmd>go test -v [运行正确或是错误,都输出日志]
-
当出现错误时,可以使用t.Fatalf 来格式化输出错误信息,并退出程序
-
t.Logf 方法可以输出相应的日志
-
测试用例函数,并没有放在main 函数中,也执行了,这就是测试用例的方便之处[原理图].
-
PASS 表示测试用例运行成功,FAIL 表示测试用例运行失败
-
测试单个文件,一定要带上被测试的原文件
go test -v cal_test.go cal.go -
**测试单个方法
go test -v -test.run TestAddUpper**
Tips
1.cap与len的区别
cap容量指底层数组大小,len长度指可以使用的大小
在与当你用 appen d扩展长度时,如果新的长度小于容量,不会更换底层数组,否则,go 会新申请一个底层数组,拷贝这边的值过去,把原来的数组丢掉。也就是说,容量的用途是:在数据拷贝和内存申请的消耗与内存占用之间提供一个权衡。
而长度,则是为了帮助你限制切片可用成员的数量,提供边界查询的。所以用 make 申请好空间后,需要注意不要越界【越 len 】
2.什么地方可以省略(*P)(底层自动编译)什么地方必须用指针类型
2.1 不考虑
- 使用结构体的字段的时候,不管是结构体指针还是结构体都可以直接使用 “.” 语法取字段
- 调用结构体绑定的方法的时候,不管指定的是指针还是结构体都可以直接使用
2.2 要标准
- 函数传参数的时候,参数为值类型就值类型,参数要求指针类型就需要传地址
3. 类型直接赋值
- 字符串直接赋值的结果为创建新的空间,不影响原来的字符串
- 结构体不创建空间直接赋值会直接指向头一个内存,共享空间,会改变原来的值
4.项目中一个封装对象的函数注意点
如果该对象在整个项目流程中始终是一个保持不变,那么函数前面的指定对象必须使用指针,如果不使用指针那么就是值复制,会产生多个对象复制,导致对象数据的改变不影响原来的对象数据(因为重新拷贝了一个对象)
例:
//同一对象指针
func (c *CustomerService) GetNowCustomerNum() uint {
c.customerNum ++
return c.customerNum
}
//值拷贝 不修改原对象值
func (c CustomerService) GetNowCustomerNum() uint {
c.customerNum ++
return c.customerNum
}
5. go: cannot find main module; see ‘go help modules’
问题原因:开启了go mod 但是找不到项目根目录下的go mod文件
不想使用go mod可以关闭,要使用的话就创建go mod文件
go env -w GO111MODULE=off //关闭
go env -w GO111MODULE=on //打开
6. unexpected directory layout:
运行go test时提示:unexpected directory layout:
网上的解决方案:https://blog.csdn.net/turbock/article/details/102505260
原因:引包不当
项目结构:

import (
"../model" //这里错误
"testing"
)
解决:引包一定要从GOPATH的src目录下开始引包,而不能直接使用相对路径
正确的修改:
import (
"heima_GO/day08/model"
"testing"
)