文章目录
数据库三大范式?
转载于:https://zhuanlan.zhihu.com/p/72197799
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。但是有些时候一昧的追求范式减少冗余,反而会降低数据读写的效率,这个时候就要反范式,利用空间来换时间。 目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。所以这里就只记录三范式相关的知识。
1. 第一范式:保证每列的原子性
也可以说每个列都不可以再拆分。举个例子,看下表:
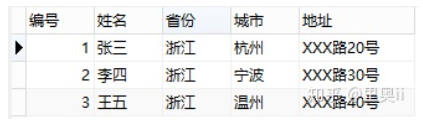
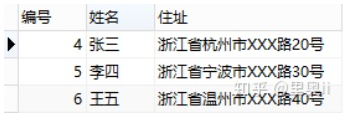 住址这一列可拆为省份、城市和地址,拆完如下:
住址这一列可拆为省份、城市和地址,拆完如下:
2. 在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分
举个例子,看下表:
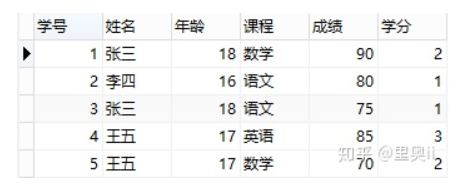
上表满足第一范式,即每个字段不可再分,但是学分依赖于非主键课程,所以不满足第二范式,会造成数据冗余、更新异常、插入异常和删除异常。修改后:

3. 在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键
第三范式又和第二范式相关,用第三范式的定义描述第三范式就是,数据库表中如果不存在非关键字段任一候选关键字段的传递函数依赖则符合第三范式,所谓传递函数依赖指的是如果存在"A–>B–>C"的决定关系,则C传递函数依赖于A。也就是说表中的字段和主键直接对应不依靠其他中间字段,说白了就是,决定某字段值的必须是主键。
举个例子,看下表:
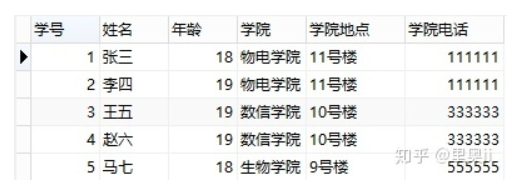
第三范式和第二范式有点像,从这张数据库表结构中可以看出,“姓名”、“年龄”、“学院"和主键"学号"直接关联,但是"学院地点”、“学院电话"却不直接和主键"学号"相关联,和"学院电话"直接相关联的是"学院”,如果表结构这么设计,同样会造成和第二范式一样的数据冗余、更新异常、插入异常、删除异常的问题。更改后:

MySQLmysql有关权限的表都有哪几个?
MySQL服务器通过权限表来控制用户对数据库的访问,权限表存放在mysql数据库里,由mysql_install_db脚本初始化。这些权限表分别user,db,table_priv,columns_priv和host。
下面分别介绍一下这些表的结构和内容:
- user权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。
- db权限表:记录各个帐号在各个数据库上的操作权限。
- table_priv权限表:记录数据表级的操作权限。
- columns_priv权限表:记录数据列级的操作权限。
- host权限表:配合db权限表对给定主机上数据库级操作权限作更细致的控制。这个权限表不受GRANT和REVOKE语句的影响。
mysql有哪些数据类型?
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 整数类型 | tinyInt | 很小的整数(8位二进制) |
| smallint | 小的整数(16位二进制) | |
| mediumint | 中等大小的整数(24位二进制) | |
| int(integer) | 普通大小的整数(32位二进制) | |
| 小数类型 | float | 单精度浮点数 |
| double | 双精度浮点数 | |
| decimal(m,d) | 压缩严格的定点数 | |
| 日期类型 | year | YYYY 1901~2155 |
| time | HH:MM:SS -838:59:59~838:59:59 | |
| date | YYYY-MM-DD 1000-01-01~9999-12-3 | |
| datetime | YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59 | |
| timestamp | YYYY-MM-DD HH:MM:SS 19700101 00:00:01 UTC~2038-01-19 03:14:07UTC | |
| 文本、二进制类型 | CHAR(M) | M为0~255之间的整数 |
| VARCHAR(M) | M为0~65535之间的整数 | |
| TINYBLOB | 允许长度0~255字节 | |
| BLOB | 允许长度0~65535字节 | |
| MEDIUMBLOB | 允许长度0~167772150字节 | |
| LONGBLOB | 允许长度0~4294967295字节 | |
| TINYTEXT | 允许长度0~255字节 | |
| TEXT | 允许长度0~65535字节 | |
| MEDIUMTEXT | 允许长度0~167772150字节 | |
| LONGTEXT | 允许长度0~4294967295字节 | |
| VARBINARY(M) | 允许长度0~M个字节的变长字节字符串 | |
| BINARY(M) | 允许长度0~M个字节的定长字节字符串 |
超键、候选键、主键、外键分别是什么?
超键(super key): 在关系中能唯一标识元组的属性集称为关系模式的超键
候选键(candidate key): 不含有多余属性的超键称为候选键。也就是在候选键中,若再删除属性,就不是超键了!
主键(primary key): 用户选作元组标识的一个候选键程序主键
外键(foreign key):如果关系模式R中属性K是其它模式的主键,那么k在模式R中称为外键。
举个例子:
两张表:
学生信息(学号 身份证号 性别 年龄 身高 体重 宿舍号)
宿舍信息(宿舍号 楼号)
- 超键:只要含有“学号”或者“身份证号”两个属性的集合就叫超键,例如R1(学号 性别)、R2(身份证号 身高)、R3(学号 身份证号)等等都可以称为超键!
- 候选键:不含有多余的属性的超键,比如(学号)、(身份证号)都是候选键,又比如R1中学号这一个属性就可以唯一标识元组了,而有没有性别这一属性对是否唯一标识元组没有任何的影响!
- 主键:就是用户从很多候选键选出来的一个键就是主键,比如你要求学号是主键,那么身份证号就不可以是主键了!
- 宿舍号就是学生信息表的外键
SQL语句主要分为哪几类?
-
数据定义语言DDL(Data Ddefinition Language)
主要为CREATE,DROP,ALTER等操作 即对逻辑结构等有操作的,其中包括表结构,视图和索引。 -
数据查询语言DQL(Data Query Language)SELECT
这个较为好理解 即查询操作,以select关键字。各种简单查询,连接查询等 都属于DQL。 -
数据操纵语言DML(Data Manipulation Language)
主要为INSERT,UPDATE,DELETE等操作 即对数据进行操作的,对应上面所说的查询操作 DQL与DML共同构建了多数初级程序员常用的增删改查操作。而查询是较为特殊的一种 被划分到DQL中。 -
数据控制功能DCL(Data Control Language)
主要为GRANT,REVOKE,COMMIT,ROLLBACK等操作 即对数据库安全性完整性等有操作的,可以简单的理解为权限控制等。
说一说SQL字段有哪几种约束?
- NOT NULL: 用于控制字段的内容一定不能为空(NULL)。
- UNIQUE: 控件字段内容不能重复,一个表允许有多个 Unique 约束。
- PRIMARY KEY: 也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
- FOREIGN KEY: 用于预防破坏表之间连接的动作,也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
- CHECK: 用于控制字段的值范围。
说一说SQL的关联查询?
- 内连接(INNER JOIN)
内连接分为三类: 1. 等值连接:ON A.id=B.id 2. 不等值连接:ON A.id > B.id 3. 自连接:SELECT * FROM A T1 INNER JOIN A T2 ON T1.id=T2.pid - 外连接(LEFT JOIN/RIGHT JOIN)
左外连接:LEFT OUTER JOIN, 以左表为主,先查询出左表,按照ON后的关联条件匹配右表,没有匹配到的用NULL填充,可以简写成LEFT JOIN 右外连接:RIGHT OUTER JOIN, 以右表为主,先查询出右表,按照ON后的关联条件匹配左表,没有匹配到的用NULL填充,可以简写成RIGHT JOIN - 联合查询(UNION与UNION ALL)
SELECT * FROM A UNION SELECT * FROM B UNION ... 1. 就是把多个结果集集中在一起,UNION前的结果为基准,需要注意的是联合查询的列数要相等,相同的记录行会合并 2. 如果使用UNION ALL,不会合并重复的记录行 3. 效率 UNION 高于 UNION ALL - 全连接(FULL JOIN)
MySQL不支持全连接可以使用LEFT JOIN 和UNION和RIGHT JOIN联合使用 SELECT * FROM A LEFT JOIN B ON A.id=B.id UNIONSELECT * FROM A RIGHT JOIN B ON A.id=B.id - 交叉连接(CROSS JOIN)
说一说SQL的子查询?
条件:一条SQL语句的查询结果做为另一条查询语句的条件或查询结果
嵌套:多条SQL语句嵌套使用,内部的SQL查询语句称为子查询。
三种情况:
子查询是单行单列的情况:结果集是一个值,父查询使用:=、 <、 > 等运算符
// 查询工资最高的员工是谁?
select * from employee where salary=(select max(salary) from employee);
子查询是多行单列的情况:结果集类似于一个数组,父查询使用:in 运算符
// 查询工资最高的员工是谁?
select * from employee where salary=(select max(salary) from employee);
子查询是多行多列的情况:结果集类似于一张虚拟表,不能用于where条件,用于select子句中做为子表
// 1) 查询出2011年以后入职的员工信息
// 2) 查询所有的部门信息,与上面的虚拟表中的信息比对,找出所有部门ID相等的员工。
select * from dept d, (select * from employee where join_date > '2011-1-1') e where e.dept_id = d.id;
// 使用表连接:
select d.*, e.* from dept d inner join employee e on d.id = e.dept_id where e.join_date > '2011-1-1'
mysql中 in 和 exists 的区别?
https://cloud.tencent.com/developer/article/1144244
https://www.jianshu.com/p/f212527d76ff
select * from A where id in (select id from B);
select * from A where exists (select 1 from B where A.id=B.id);
-
in() 语句内部原理
IN()只执行一次,它查出B表中的所有id字段并缓存起来。之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加入结果集中,直到遍历完A表的所有记录。
可以看出,当B表数据较大时不适合使用in(),因为它会把B表数据全部遍历一次举例:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差。
-
EXISTS() 语句内部工作原理
exists对外表用loop逐条查询,每次查询都会查看exists的条件语句,当exists里的条件语句能够返回记录行时(无论记录行是的多少,只要能返回),条件就为真,返回当前loop到的这条记录;反之,如果exists里的条件语句不能返回记录行,则当前loop到的这条记录被丢弃,exists的条件就像一个bool条件,当能返回结果集则为true,不能返回结果集则为false
当B表比A表数据大时适合使用exists(),因为它没有那么多遍历操作,只需要再执行一次查询就行。举例: A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等。
varchar与char的区别?如何选择?
char的特点:
1. char表示定长字符串,长度是固定的;
2. 如果插入数据的长度小于char的固定长度时,则用空格填充;
3. 因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
4. 对于char来说,最多能存放的字符个数为255,和编码无关
varchar的特点:
1. varchar表示可变长字符串,长度是可变的;
2. 插入的数据是多长,就按照多长来存储;
3. varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多 余的空间,是时间换空间的做法;
4. 对于varchar来说,最多能存放的字符个数为65532
如何选择?
1. 对于经常变更的数据来说,CHAR比VARCHAR更好,因为CHAR不容易产生碎片。
2. 对于非常短的列,CHAR比VARCHAR在存储空间上更有效率。
3. 使用时要注意只分配需要的空间,更长的列排序时会消耗更多内存。
4. 尽量避免使用TEXT/BLOB类型,查询时会使用临时表,导致严重的性能开销。
mysql中int(10)和char(10)以及varchar(10)的区别?
- int(10)的10表示显示的数据的长度,不是存储数据的大小;
- char(10)表示存储定长的10个字符,不足10个就用空格补齐,占用更多的存储空间;
- varchar(10)表示存储10个变长的字符,存储多少个就是多少个,空格也按一个字符存储,这一点是和char(10)的空格不同的,char(10)的空格表示占位不算一个字符
MySQL中delete,drop,truncate的区别?
三者都表示删除,但是三者有一些差别:
| Delete | Truncate | Drop | |
|---|---|---|---|
| 类型 | 属于DML | 属于DDL | 属于DDL |
| 回滚 | 可回滚 | 不可回滚 | 不可回滚 |
| 删除内容 | 表结构还在,删除表的全部或者一部分数据行 | 表结构还在,删除表中的所有数据 | 从数据库中删除表,所有的数据行,索引和权限也会被删除 |
| 删除速度 | 删除速度慢,需要逐行删除 | 删除速度快 | 删除速度最快 |
因此,当不再需要一张表的时候,用drop;在想删除部分数据行时候,用delete;在保留表而删除所有数据的时候用truncate。
MySQL的binlog有有几种录入格式?分别有什么区别?
有三种格式,statement,row和mixed。
- statement模式下,每一条会修改数据的sql都会记录在binlog中。不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
- row级别下,不记录sql语句上下文相关信息,仅保存哪条记录被修改。记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大。
- mixed,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录。
MySQL有哪几种日志?
https://database.51cto.com/art/201806/576300.htm
二进制日志和重做日志有什么区别?
也许有人会问,既然同样是记录事务日志,和之前介绍的二进制日志有什么区别?首先,二进制日志会记录所有与MySQL数据库有关的日志记录,包括InnoDB、MyISAM、Heap等其他存储引擎的日志。而InnoDB存储引擎的重做日志只记录有关该存储引擎本身的事务日志。
其次,记录的内容不同,无论用户将二进制日志文件记录的格式设为STATEMENT还是ROW,又或者是 MIXED,其记录的都是关于一个事务的具体操作内容,即该日志是逻辑日志。而InnoDB存储引擎的重做日志文件记录的是关于每个页(Page)的更改的物理情况。
此外,写入的时间也不同,二进制日志文件仅在事务提交前进行提交,即只写磁盘一次,不论这时该事务多大。而在事务进行的过程中,却不断有重做日志条目(redoentry)被写入到重做日志文件中。