扩展:
1. source exec 区别 http://alsww.blog.51cto.com/2001924/1113112
2. Linux特殊符号大全http://ask.apelearn.com/question/7720
3. sort并未按ASCII排序 http://blog.csdn.net/zenghui08/article/details/7938975
shell特殊符号cut命令
- cut 分割,-d 分隔符 -f 指定段号 -c 指定第几个字符
- sort 排序, -n 以数字排序 -r 反序 -t 分隔符 -kn1/-kn1,n2
- wc -l 统计行数 -m 统计字符数 -w 统计词
- uniq 去重, -c统计行数
- tee 和>类似,重定向的同时还在屏幕显示
- tr 替换字符,tr 'a' 'b',大小写替换tr '[a-z]' '[A-Z]'
- split 切割,-b大小(默认单位字节),-l行数
cut命令
- cut命令用来截取某个字符串
- 格式:cut –d “分割符” 文件名
- -d:后面跟分割字符,分割字符用双引号括起来;
- -f:后面跟接第几段字符串
- -c:后面接第几个字符
- 截取passwd第1到第3段
[root@yong-02 test]# head -3 passwd |cut -d ":" -f 1-3
root:x:0
bin:x:1
daemon:x:2- 截取passwd第1段和第3段
[root@yong-02 test]# head -3 passwd |cut -d ":" -f 1,3
root:0
bin:1
daemon:2- 截取第3个字符
[root@yong-02 test]# head -3 passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@yong-02 test]# head -3 passwd |cut -c 3
o
n
e- 截取第2个字符到第6个字符
[root@yong-02 test]# head -3 passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@yong-02 test]# head -3 passwd |cut -c 2-6
oot:x
in:x:
aemon
sort命令
- sort命令用做排序,格式sort [-t 分割符] [-kn1,n2] [-nur],n1,n2指的是数字
- -t 分割符
- -k 按第几列排序;区间范围用逗号-k3,5
- -n 按数字排序
- -r 反序排序,按从打到小排序
- -u 去重复
- -un 字母开头的会识别成重复内容,如skj1 a weotj 都会认为是重复内容,只显示数字内容
- sort 不加任何选项,从首行字符向后,依次按ASCII码值进行比较,按升序排序
[root@yong-02 test]# vim passwd
adf
123
111
!!!
!jk
lfas
<::
>,
%^
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
polkitd:x:999:997:User for polkitd:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin- 以数字排序
[root@yong-02 test]# sort -n passwd
<::
>,
!!!
%^
adf
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
halt:x:7:0:halt:/sbin:/sbin/halt
!jk
lfas
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
polkitd:x:999:997:User for polkitd:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
111
123- 注意:如果有字母或者特殊符号,在数字排序中,都默认看成0.
- 反向排序
[root@yong-02 test]# sort -nr passwd
123
111
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
root:x:0:0:root:/root:/bin/bash
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
polkitd:x:999:997:User for polkitd:/:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
lfas
!jk
halt:x:7:0:halt:/sbin:/sbin/halt
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
adf
%^
!!!
>,
<::- 去重复,这里把字母都看成了0,然后去重复。
[root@yong-02 test]# sort -nu passwd
adf
111
123
wc命令
- wc命令用于统计文档的行数,字符数,单词数。
- -l 统计行数
- -m统计字符数
- -w统计单词数
- 查看文件1.txt 行数
[root@yong-02 test]# cat 1.txt
abcd
1abcd
123
111
121
[root@yong-02 test]# wc -l 1.txt
5 1.txt- 查看文件1.txt字符有多少个,$为行尾字符
[root@yong-02 test]# cat -A 1.txt
abcd$
1abcd$
123$
111$
121$
[root@yong-02 test]# wc -m 1.txt
23 1.txt- -w统计单词,它是以空格或者空白字符来分割。
[root@yong-02 test]# cat 1.txt
abcd
1abcd
123
111
121
[root@yong-02 test]# wc -w 1.txt
5 1.txt- 如果wc后面不加任何选项,直接跟文档,则会把行数,单词数,字符数依次输出。
[root@yong-02 test]# cat 1.txt
abcd
1abcd
123
111
121
[root@yong-02 test]# wc 1.txt
5 5 23 1.txtuniq命令
- uniq命令用来删除重复的行,通常和sort连在一起使用
- -c选项比较常用,它表示统计重复的行数,并把行数写在前面
[root@yong-02 test]# cat 2.txt
111
222
123
111
222
adf
123
111
!!!
!jk
lfas
<::
>,
%^
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
- 先排序然后删除重复行
[root@yong-02 test]# sort 2.txt |uniq -c
1 <::
1 >,
1 !!!
1 %^
3 111
2 123
2 222
1 adf
1 bin:x:1:1:bin:/bin:/sbin/nologin
1 daemon:x:2:2:daemon:/sbin:/sbin/nologin
1 !jk
1 lfas
1 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
1 root:x:0:0:root:/root:/bin/bash
3 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdowntee命令
- tee命令后面文件名,其作用类似于重定向>;但是它比重定向多一个显示在屏幕上的功能;
[root@yong-02 test]# cat 1.txt > a.txt
[root@yong-02 test]# cat 1.txt |tee a.txt
abcd
1abcd
123
111
121- tee –a 相当于追加重定向>>;它多了一个显示在屏幕上的功能
[root@yong-02 test]# cat 1.txt |tee -a a.txt
abcd
1abcd
123
111
121
[root@yong-02 test]# cat a.txt
abcd
1abcd
123
111
121
abcd
1abcd
123
111
121
命令tr
- tr命令用于替换字符
[root@yong-02 test]# cat 1.txt |tr 'a' 'A'
Abcd
1Abcd
123
111
121
[root@yong-02 test]# cat 1.txt |tr 'a-z' 'A-Z' ##最好'[a-z]' '[A-Z]'
ABCD
1ABCD
123
111
121
split命令
- split 用于分割文档
- split -l 按行来分割
- split -b 按大小来分割
- split -b 按大小来分割
[root@yong-02 test]# find /etc/ -type f -name "*.conf" -exec cat {} >test.txt \;
[root@yong-02 test]# du -sh test.txt
240K test.txt
[root@yong-02 test]# split -b 100k test.txt
[root@yong-02 test]# ls
test.txt xab xaa xac
- split –l 按行来分割
[root@yong-02 test]# wc -l test.txt
6082 test.txt
[root@yong-02 test]# split -l 1000 test.txt
[root@yong-02 test]# ls
test.txt xab xad xaf
xaa xac xae xag
- split 后面如果不指定文件名,则会以xaa,xab ……这样的文件名来存取切割后的文件
- 指定目标分割文件名 为abc.
[root@yong-02 test]# split -l 1000 test.txt abc.
[root@yong-02 test]# ls
abc.ab abc.ad abc.af test.txt
abc.aa abc.ac abc.ae abc.ag
特殊符号
- $ 变量前缀,!$组合,正则里面表示行尾
- ;多条命令写到一行,用分号分割
- ~ 用户家目录,后面正则表达式表示匹配符
- & 放到命令后面,会把命令丢到后台
- 重定向 > 追加重定向>> 错误重定向2> 错误追加重定向2>> 正确和错误重定向&>
- [ ] 指定字符中的一个,[0-9],[a-zA-Z],[abc]
- || 和 && ,用于命令之间
- $:可以作为变量前面的标示符,可以和!结合起来使用,在正则里面表示行尾
[root@yong-02 test]# ls /tmp/gzip/
1.txt 2.txt.zip 4.txt test yyl.tar yyl.tar.gz yyl.zip
2.txt 3.txt 5.txt yyl yyl.tar.bz2 yyl.tar.xz
[root@yong-02 test]# ls !$
ls /tmp/gzip/
1.txt 2.txt.zip 4.txt test yyl.tar yyl.tar.gz yyl.zip
2.txt 3.txt 5.txt yyl yyl.tar.bz2 yyl.tar.xz- ; 多条命令写在一行,用;分割
[root@yong-02 test]# cat 1.txt ;cat a.txt
abcd
1abcd
123
111
121
abcd-
~ 家目录,后面正则表示匹配符
-
重定向(正确) > ,会覆盖以前的内容
[root@yong-02 test]# echo "abcdefg" >a.txt
[root@yong-02 test]# cat a.txt
abcdefg- 追加重定向(正确)>>
[root@yong-02 test]# echo "1234" >>a.txt
[root@yong-02 test]# cat a.txt
abcdefg
1234- 错误重定向 2>
[root@yong-02 test]# cat c.txt 2>a.txt
[root@yong-02 test]# cat a.txt
cat: c.txt: 没有那个文件或目录- 错误追加重定向 2>>
[root@yong-02 test]# cat c.txt 2>>a.txt
[root@yong-02 test]# cat a.txt
cat: c.txt: 没有那个文件或目录
cat: c.txt: 没有那个文件或目录- &> 错误和正确都重定向到某个文件里面。
[root@yong-02 test]# cat 1.txt c.txt &>a.txt
[root@yong-02 test]# cat a.txt
abcd
1abcd
123
111
121
cat: c.txt: 没有那个文件或目录- shell中的链接符号 && || ;
- && 前面命令执行成功后,才会执行后面的命令;如果前面执行不成功,后面命令不执行
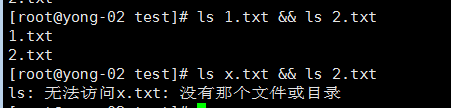
- || 前面的命令执行不成功,才会执行后面的命令;如果前面命令执行成功,后面命令不执行

- ; 左边的命令成功与否,后边的命令都会执行
