目录
1.前言
笔者原以为数据库的知识点面试前背一背就好,但其实这样根本不行。一是容易忘记,二是根本不会变通,面试官换一个问法就懵逼。本文大部分篇幅在讲索引的底层实现,面试题放在了最后,如果能把前面底层实现部分通读吸收一下,面试题根本不是问题,当然想直接看面试题的小伙伴可以直接移步目录第七点:索引有关面试题解析,最后附自己整理的索引脑图。
2.索引数据结构分类
索引的底层数据结构经笔者查阅资料后发现分为很多类,光树状结构就有五种,分别是二叉查找树(Binary Search Tree)、自平衡二叉查找树(Self-balancing Binary Search Tree)、B 树(B-Tree)、字典树(Trie-Tree)、空间数据分割树(Spatial Data Partitioning Tree)。具体如下图所示:
| 类别 | 树名称 |
|---|---|
| 二叉查找树(Binary Search Tree) | 二叉查找树,笛卡尔树,T 树 |
| 自平衡二叉查找树(Self-balancing Binary Search Tree) | AA 树,AVL 树, 红黑树(Red-Black Tree), 伸展树(Splay Tree) |
| B 树(B-Tree) | 2-3 树,2-3-4 树, B 树,B+ 树,B* 树 |
| 字典树(Trie-Tree) | 后缀树,基数树,三叉查找树,快速前缀树 |
| 空间数据分割树(Spatial Data Partitioning Tree) | R 树,R+ 树,R* 树, 线段树,优先 R 树 |
此文我们主要分析MySQL索引方面的知识,包括最早版本使用的二叉树、B-Tree、面试总问到的红黑树、以及现版本使用的B+Tree。
3.二叉查找树
二叉查找树:是n个有限元素的集合,该集合或者为空、或者由一个称为根(root)的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成,是一种二分查找树,有很好的查找性能,相当于二分查找。关于MySQL不使用二叉树的原因我们来看下一张图,有1~7七个数据,如果插入顺序为4、3、5、2、6、1、7,结果是一棵高度为4的排序树。附数据结构可视化网站地址,想要自己尝试的小伙伴可以点进来试试。

但如果数据插入顺序变成了1、2、3、4、5、6、7,结果就退化成了一个拥有7个结点的链表

二叉树存在的问题:二叉树树的深度依赖元素插入顺序,而且插入数据比较大时,会导致树的深度比较高。数据查询的时间主要依赖于磁盘IO的次数,二叉树深度越大,查找的次数越多,性能越差,最坏的情况为退化成了链表。
4.红黑树(自平衡二叉查找树)
红黑树:红黑树是一种特化的AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。 它虽然是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n是树中元素的数目。特点:左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。红黑树插入1、2、3、4、5、6、7,七个元素GIF图:

查找元素7过程:

红黑树存在的问题:尽量不让一棵树的单边变得太长而退化成链表,能有效地减少高度,高度变小降低了查找I/O的次数,性能比二叉树要好。但红黑树一个节点只能有两个子节点,虽然平衡了链表退化问题,但高度总体来看还是太高。
5.B-Tree
B-Tree:B树简单地说就是多叉树,每个叶子会存储数据,和指向下一个节点的指针。B-Tree插入1、2、3、4、5、6、7,七个元素GIF图:

查找元素7过程:

B-Tree特点
1)叶子结点具有相同深度
2)所有索引元素不重复
3)节点中的数据索引从左到右依次递增
从查询流程我们能看出,B-Tree的查询效率好像也并不比平衡二叉树高,但查询所经过的结点数量要比二叉树少了1个,在数据量大的时候意味着要少很多次的磁盘IO,这对性能的提升是很大的。前面对B-Tree操作的图我们能看出来,元素就是类似1、2、3这样的数值,但是数据库的数据都是一条条的数据,如果某个数据库以B-Tree的数据结构存储数据,那数据怎么存放的呢?

具体存放如下图:
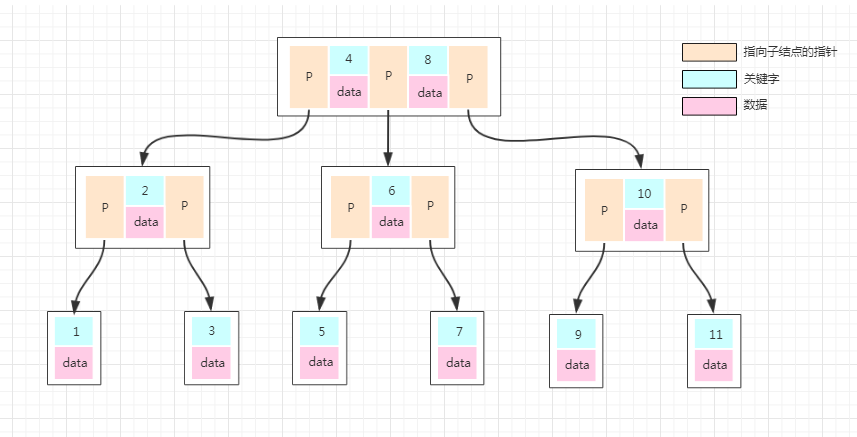
在进行数据库存储中,我们把元素部分拆分成了key-data的形式,key就是数据的主键,data就是具体的数据。
B-Tree存在的问题:B-Tree在每一个节点存储了索引和数据,导致进行搜索的时候需要把索引和数据都加载到内存中,这样就不是很划算,内存资源这么宝贵,多存些索引岂不是更好。
6.B+Tree
6.1 B+Tree概述及特点
B+Tree:在B-Tree基础上的一种优化,使其更适合实现外存储索引结构
B+Tree特点:
1)非叶子节点不存储数据,只存索引(冗余),这样可以保证存放更多的索引
2)叶子节点存储所有索引字段
3)叶子节点用指针连接,提高区间访问性能
6.2 B+Tree存放数据示例
B+Tree存放数据示例图:

6.3 MyISAM存储引擎索引实现
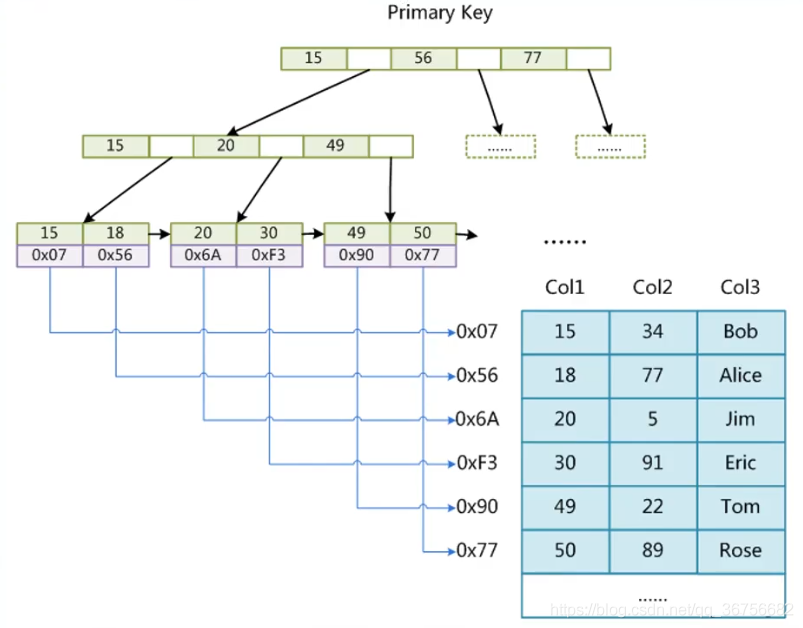
select * from tablename where id = 20 MyISAM查询流程:先去MYI文件查询索引数据,定位到 id = 20的叶子节点处,拿到20所对应的数据文件地址"0x6A",然后从MYD文件中查找,根据此文件地址定位到具体id = 20的那一行记录。
6.4 InnoDB底层存储引擎索引实现
注:InnoDB的主键索引为聚集索引(索引和数据存放在一起),而一个二级索引索引位置存放的数据为主键ID的值。


select * from tablename where id = 20 InnoDB主键索引查询流程:直接从IDB文件中查询id = 20的索引即可直接获取当前行数据。
select * from tablename where name = 'Alice' InnoDB非主键索引查询流程:直接从IDB文件中查询name = Alice 的索引,得到主键id = 18,再从当前文件中查找id为18的数据。
7.索引有关面试题解析
7.1 什么是索引
在数据之外,数据库还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用指向数据,这样就可以在这些数据结构上实现高效查找,这些数据结构就是索引。
7.2 索引的分类
单值索引:一个索引只包含单个列,一个表中可以有多个单值索引
唯一索引:索引列的值必须唯一,可为空
复合索引:一个索引包括多个列
7.3 索引的优势
1)提高数据检索效率,降低磁盘IO成本
2)通过对数据的排序,降低排序成本
7.4 索引的劣势
1)索引虽提高了查询效率,但同时降低了更新、修改、删除的效率,因为MySQL不仅要保存数据,还要维护数据和索引的关系。
2)需要成本去维护索引。一个性能良好的索引需要不断的去尝试,以找到最优解。
7.5 什么情况下适合建立索引
1)主键自动建立唯一索引
2)频繁作为查询条件的字段(where后面的字段)
3)查询中与其他表关联的字段(各种join on后面的字段)
4)单值/复合索引选择?(高并发下倾向选择复合索引)
5)查询中排序的字段
6)查询中统计或分组的字段
7.6 什么情况下不适合建立索引
1)表数据太少
2)频繁更新的字段
3)where后面用不到的字段
7.7 什么时候会出现索引失效
1)like以通配符开头('%abc')会导致索引失效,违反最左前缀法则
2)在索引列上做任何操作(计算、函数、类型转换),会导致索引失效而转向全表扫描
3)存储引擎不能使用索引中范围条件右边的列,举例:select id,name from student where id > 50 and name = '张三',会导致name索引失效
4)尽量使用覆盖索引,不要select *
5)MySQL在使用不等于(!=或<>)的时候无法使用索引会导致全表扫描,理由也很简单,B+Tree叶子节点用指针相连且是排好序的,这种数据结构只能解决有序的定值查询,像不等于这种无法利用索引查询。
6)IS NULL、IS NOT NULL无法使用索引,理由同上
7)字符串不加单引号索引失效
8)用or连接时会导致索引失效
7.8 为什么建议InnoDB必须建主键
对于InnoDB来说,如果不手动建主键索引,MySQL底层依然会帮我们创建一个聚集索引来维护整张表的所有数据,因为B+Tree必须依靠索引才能建立。为什么建议InnoDB必须建主键呢?因为本身数据库的资源就非常宝贵,我们尽量能手动做的就不要麻烦MySQL去帮我们维护,说白了就是降低数据库开销。
7.9 为什么推荐使用整型主键
我们就拿UUID举个例子,一大串十分长但无具体意义的字符串,回顾上面InnoDB的索引图,是比较两个int型数据快捷呢还是比较两个字符串快捷呢?想都不用想肯定是比较两个int型更具有优势,字符串需要逐位的去比较,如果碰巧两个字符串只有最后一位不一致那不是亏得要死。
7.10 为什么推荐使用自增主键
上文B+Tree第三条特性:叶子节点用指针连接,提高区间访问性能。这样带来了一个好处那就是范围查找,比如一行SQL:select * from tablename where id between 1 and 20,MySQL只需要查到索引等于1的位置,然后通过链表往后依次找到20的位置,首尾位置之间就是我们需要查找的结果集。但这样也带来了一个问题,加入我们主键已经插入了1、2、3、4、6、7,这时候我们插入了5,MySQL在维护索引的时候就会打破原有链表顺序,导致链表节点分裂重排,从而消耗性能。
7.11 为什么InnoDB非主键索引存储的是主键值
保持一致性,当数据库表进行DML操作时,同一行记录的页地址会发生改变,因非主键索引保存的是主键的值,无需进行更改。同时还可以节省存储空间,因为Innodb数据本身就已经汇聚到主键索引所在的B+树上了, 如果普通索引还继续再保存一份数据,就会导致有多少索引就要存多少份数据。
7.12 为什么不使用B-Tree而使用B+Tree
B+Tree将数据的存储都放在了叶子节点,非叶子节点全部用来存放冗余索引,这样可以保证非叶子节点可以存储更多的索引,因为决定B+Tree高度的就是非叶子节点,如果非叶子节点可以存储更多的值就会使树的整体高度变少,从而降低磁盘IO次数,降低系统消耗。
8.索引脑图

本文整理自: https://www.bilibili.com/video/BV1xh411Z79d?p=3
https://www.jianshu.com/p/ac12d2c83708
https://www.cnblogs.com/guokaifeng/p/11272896.html
https://www.cnblogs.com/boothsun/p/8970952.html#autoid-6-0-0