简介
CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强,也是互联网企业中较为常见的架构。
CDH版本:CDH 5.12.2, Parcel
硬件筹备
1,如果是云主机的话,看看配置就行了
2,根据最小原则,准备6台物理主机做基础准备,大致配置如下
PS:具体网关设备什么的这里就不讨论了
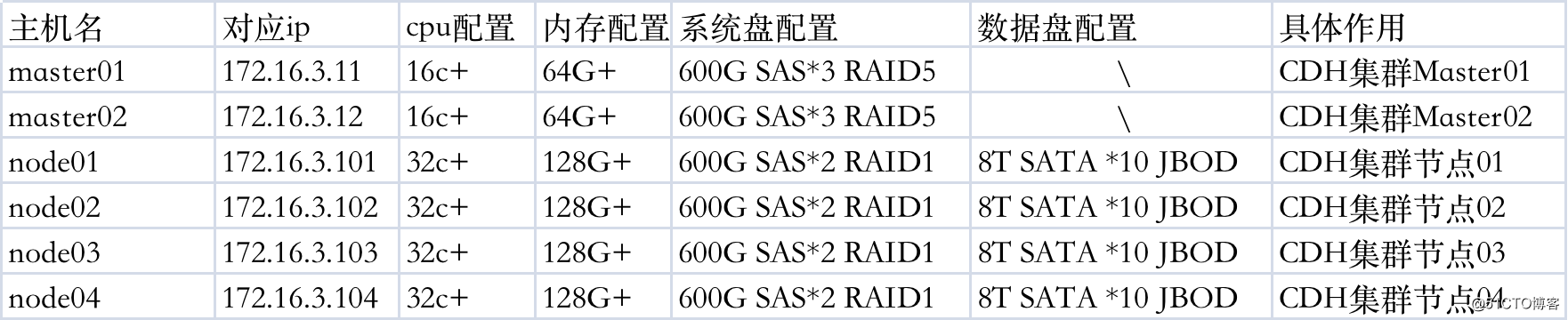
3,系统版本:Centos7.8 64bit 最小化版本
软件筹备
如下操作需要在所有主机运行
1.安装基本网络工具
yum install net-tools ntp
2.安装基本JAVA环境
Jar包名称:jdk-8u151-linux-x64.rpm
安装方式:rpm -ivh jdk-8u151-linux-x64.rpm
PS:版本比我大的基本都行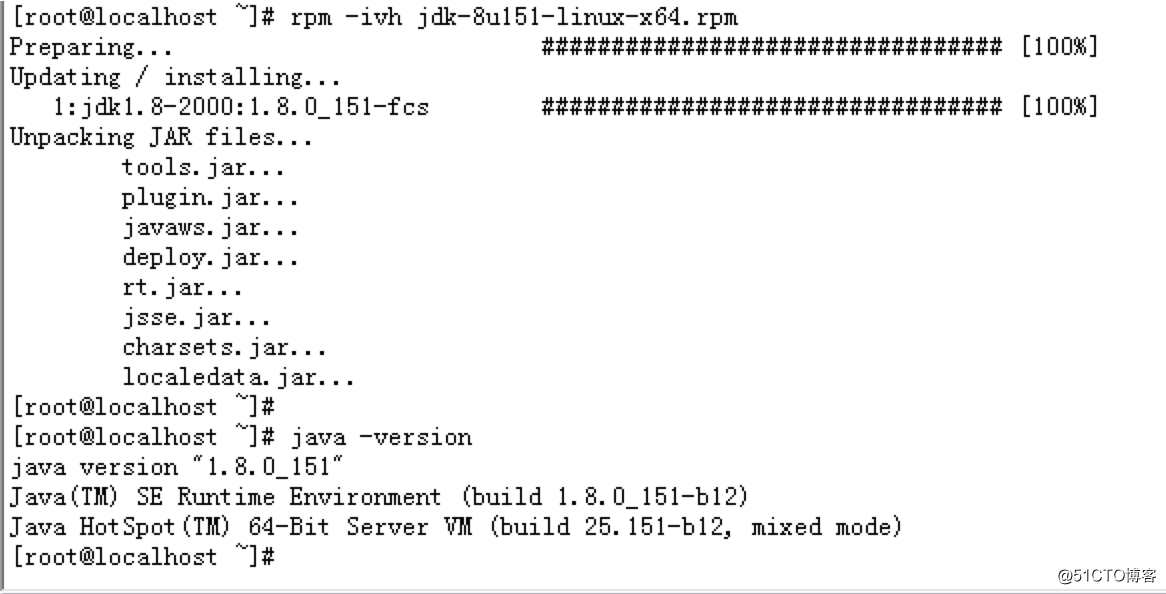
3.修改主机名以及host配置
根据实际情况大致安排先有线上主机任务的分配
1,同步host配置
当前分配如下,写入系统 /etc/hosts文件
172.16.3.11 master01
172.16.3.12 master02
172.16.3.101 node01
172.16.3.102 node02
172.16.3.103 node03
172.16.3.104 node042,更新主机名
修改主机名开机配置文件,确保重启后hostname不变更
[root@localhost ~]# cat /etc/sysconfig/network
# Created by anaconda
NETWORKING=yes
HOSTNAME=master01不重启的情况下直接更改
hostnamectl master014.修改系统参数保证集群正常运行
Cloudera 建议将 /proc/sys/vm/swappiness 设置为最大值 10。当前设置为 60。
echo 10 > /proc/sys/vm/swappiness
已启用透明大页面压缩,可能会导致重大性能问题。请运行
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled以禁用此设置
然后将同一命令添加到 /etc/rc.local 等初始化脚本中,以便在系统重启时予以设置。以下主机将受到影响:
在rc.local中新增以下选项
echo 10 > /proc/sys/vm/swappiness
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled#iptables根据实际情况选择是否禁用
iptables -F
service ntpd restart修改系统limit
在/etc/security/limits.conf 文件中,# End of file之前新增以下配置
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536然后退出重新登陆即可生效
5.关闭各类防火墙
iptables -F
setenforce 0
6.时间同步
CDH对于时区和时间匹配要求比较高
使用ntpd服务来自动同步当前时区对应的时间
yum install ntp
使用tzselect来调整当前时区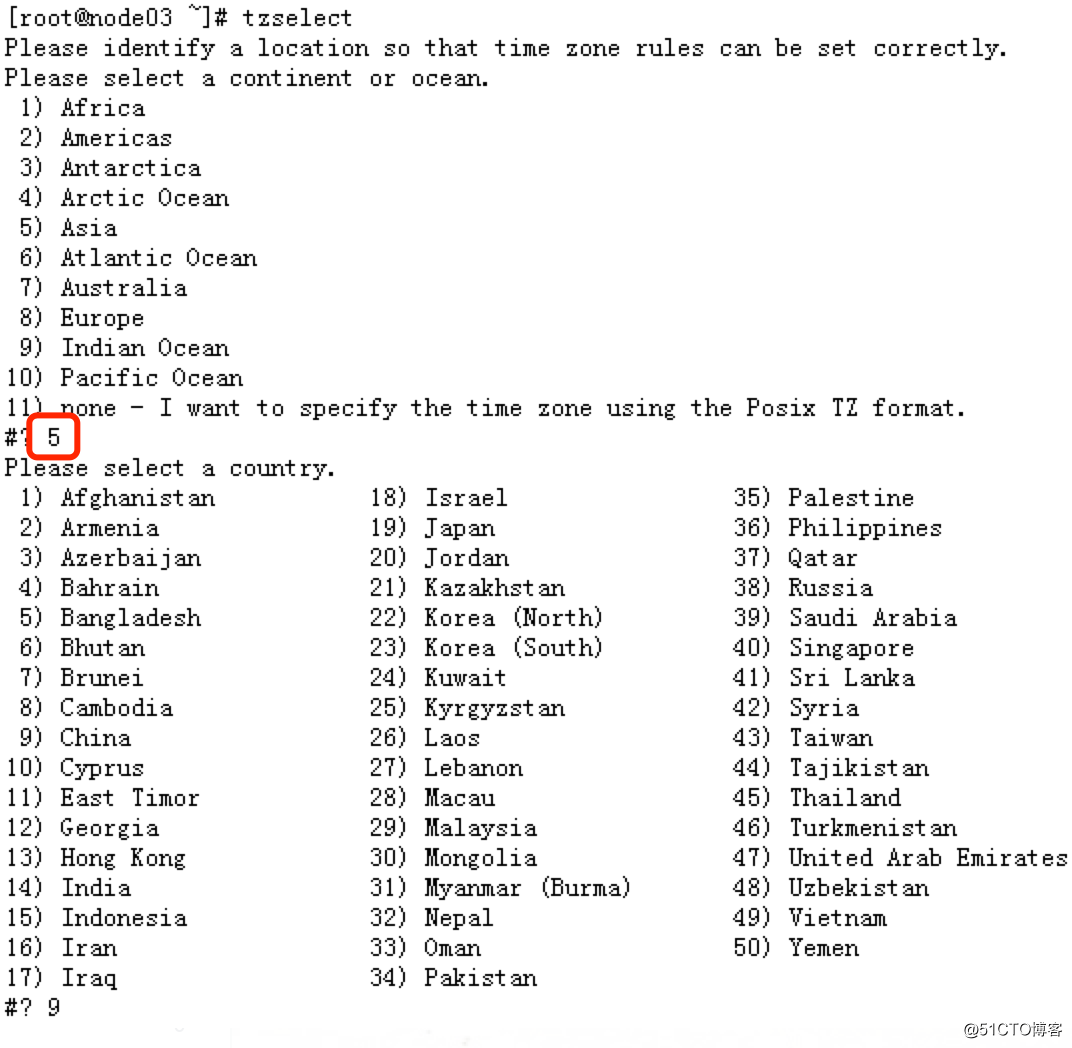
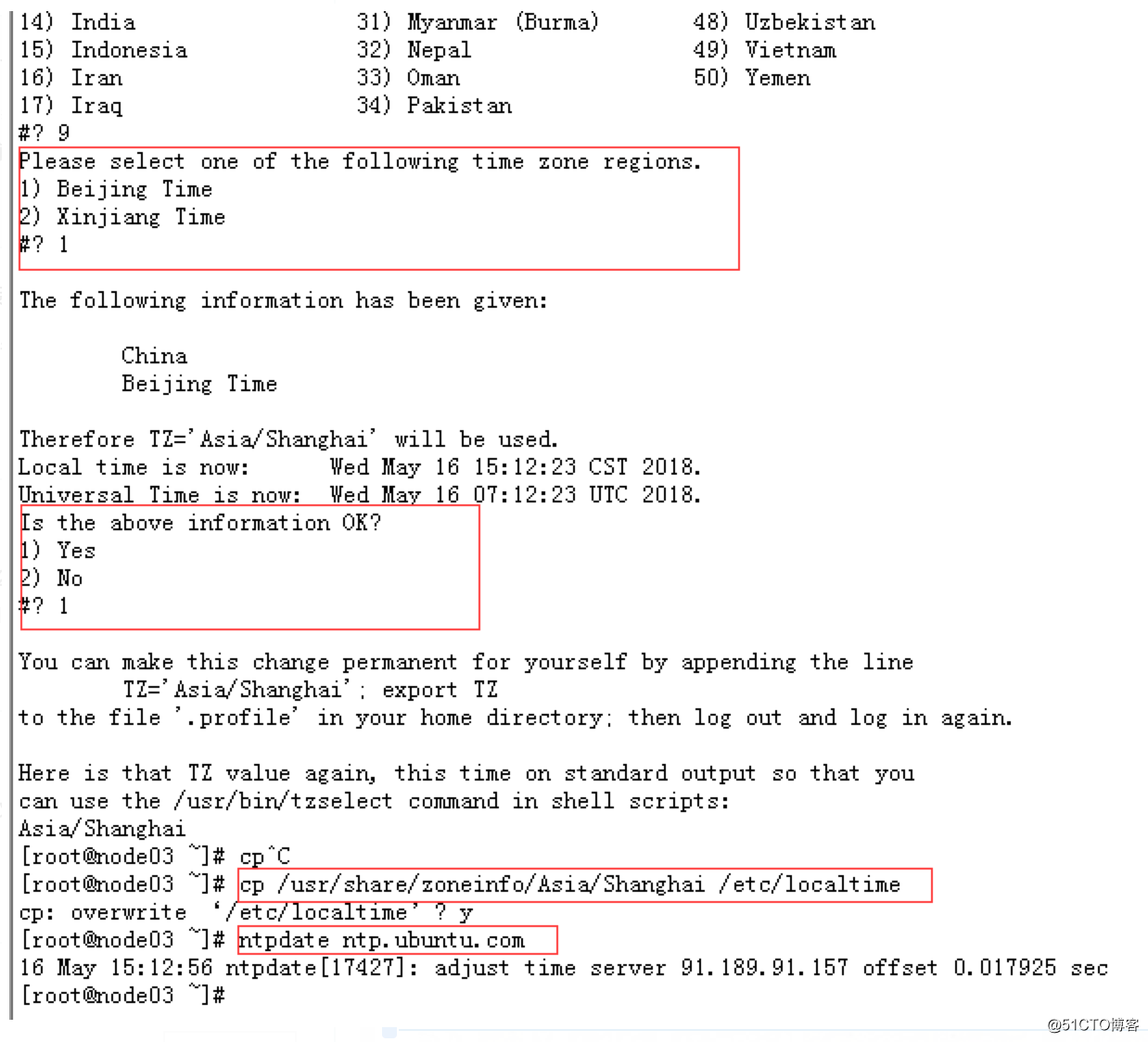
最后启动ntpd服务即可
service ntpd restart
Master节点安装
首先确认安装版本
首先查看版本信息,决定要按照的版本
查看版本信息
https://www.cloudera.com/documentation/enterprise/release-notes/topics/cm_vd.html#cmvd_topic_1
截止至2021-03-19信息如下
Cloudera Manager is available in the following releases:
Cloudera Manager 5.16.2 is the current release of Cloudera Manager 5.16.
Cloudera Manager 5.15.2. 5.14.4, 5.13.3, 5.12.2, 5.11.2, 5.10.2, 5.9.3, 5.8.5, 5.7.6, 5.6.1, 5.5.6, 5.4.10, 5.3.10, 5.2.7, 5.1.6, and 5.0.7 are previous stable releases of Cloudera Manager 5.14, 5.13, 5.12, 5.11, 5.10, 5.9, 5.8, 5.7, 5.6, 5.5, 5.4, 5.3, 5.2, 5.1, and 5.0 respectively.自建yum源
安装当前系统对应的yum源
第一种方式,读取官方源
当前为centos7系统,执行如下源读取
rpm -Uvh http://archive.cloudera.com/cdh5/one-click-install/redhat/7/x86_64/cloudera-cdh-5-0.x86_64.rpm
第二种方式是搭建本地源(推荐该种方式,方便后续node安装)
操作环境:一台新主机:192.168.1.100,Centos7 系统即可
1,首先先拉取在线对应版本的repo文件
rpm -Uvh http://archive.cloudera.com/cdh5/one-click-install/redhat/7/x86_64/cloudera-cdh-5-0.x86_64.rpm
[root@master01 parcel-repo]# cat /etc/yum.repos.d/cloudera-manager.repo
[cloudera-manager]
name = Cloudera Manager, Version 5.12.2
baseurl = https://archive.cloudera.com/cm5/redhat/7/x86_64/cm/5.12.2/
gpgkey = https://archive.cloudera.com/redhat/cdh/RPM-GPG-KEY-cloudera
gpgcheck = 1
2,安装本地源工具
yum install -y yum-utils createrepo httpd
3,启动httpd
service httpd start
4,同步对应原
reposync -r cloudera-manager
5,创建对应repo路径
mkdir -p /var/www/html/mirrors/cdh/
cp -r cloudera-manager/ /var/www/html/mirrors/cdh/
cd /var/www/html/mirrors/cdh/
createrepo .
完成之后对应的本地源就已经搭建成功了
然后修改repo文件
[root@master01 parcel-repo]# cat /etc/yum.repos.d/cloudera-manager.repo
[cloudera-manager]
name = Cloudera Manager, Version 5.12.2
baseurl = http://192.168.1.100/mirrors/cdh/cloudera-manager/
gpgkey = https://archive.cloudera.com/redhat/cdh/RPM-GPG-KEY-cloudera
gpgcheck = 1
安装server端
yum install cloudera-manager-daemons cloudera-manager-server
安装agent端
将/etc/yum.repos.d/cloudera-manager.repo文件同步到各个节点
在各个节点执行 yum install cloudera-manager-agent
这样就可以走内网本地安装,避免install速度慢的尴尬
安装MySQL
CDH集群可以被很多数据库支持,这里我们选择使用Mysql
MYSQL 5.5.6安装
安装MySQL
rpm -Uvh http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
提取成功之后会在/etc/yum.repo.d路径下方生成两个yum文件
然后开始安装:
yum install mysql-server -y
启动:
service mysqld restart
现在设置的账密如下:
mysql -uroot -p111111
ps:密码复杂点哈,别那么简单
执行CDH建表语句
/usr/share/cmf/schema/scm_prepare_database.sh mysql -uroot -p111111 --scm-host localhost scm scm scm_password
导入连接jar包
mkdir -p /usr/share/java/
cp mysql-connector-java.jar /usr/share/java/部署集群前的准备工作
将需要的parcel包放到master01对应路径下
不然需要下载,会比较慢
server端安装完成之后,master01会多出一个7180端口
http://172.16.1.11:7180/
admin admin
然后如下图一步步操作搭建集群
打钩同意
选择免费版
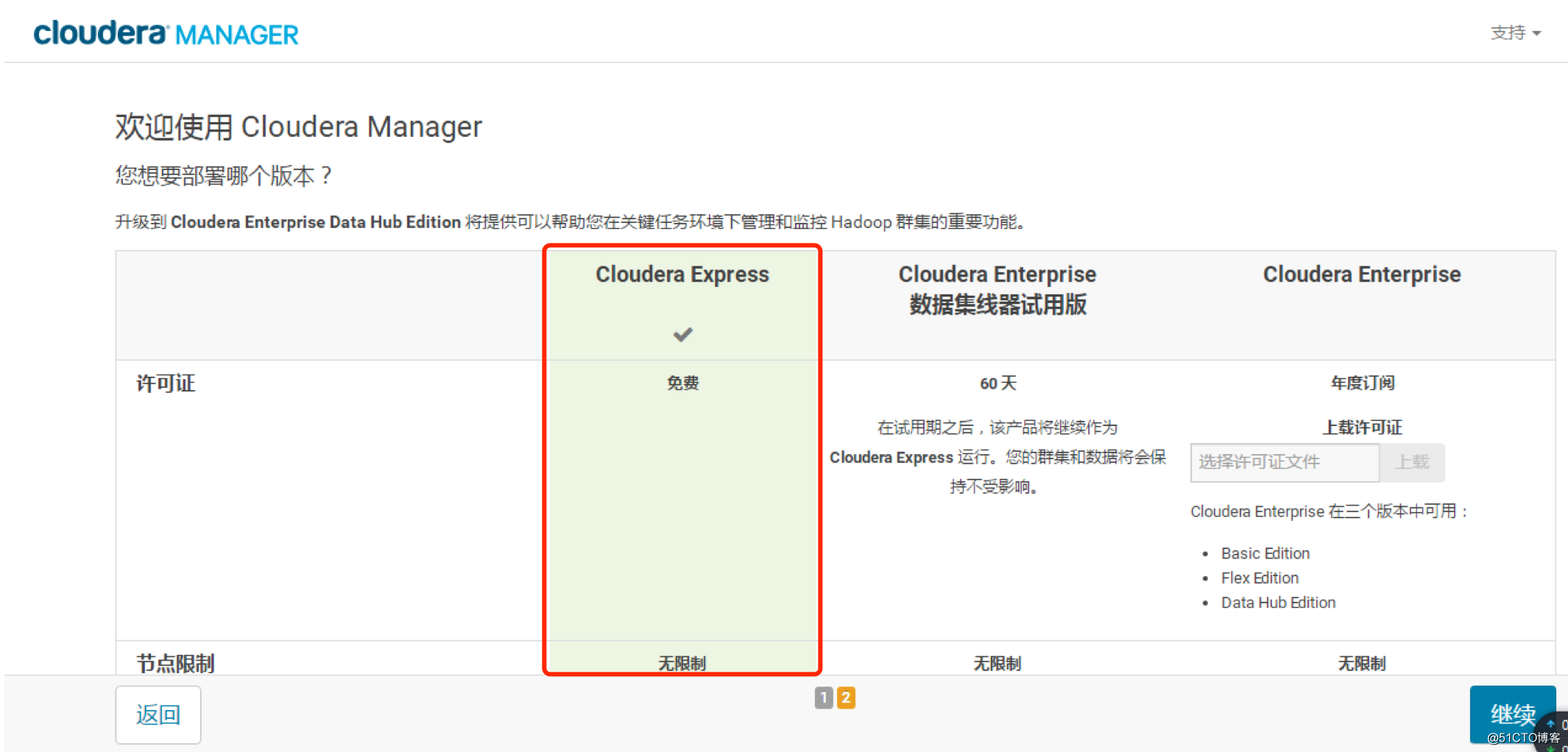
那个。。。免费版肯定不如企业版,,大家视具体情况而定哈
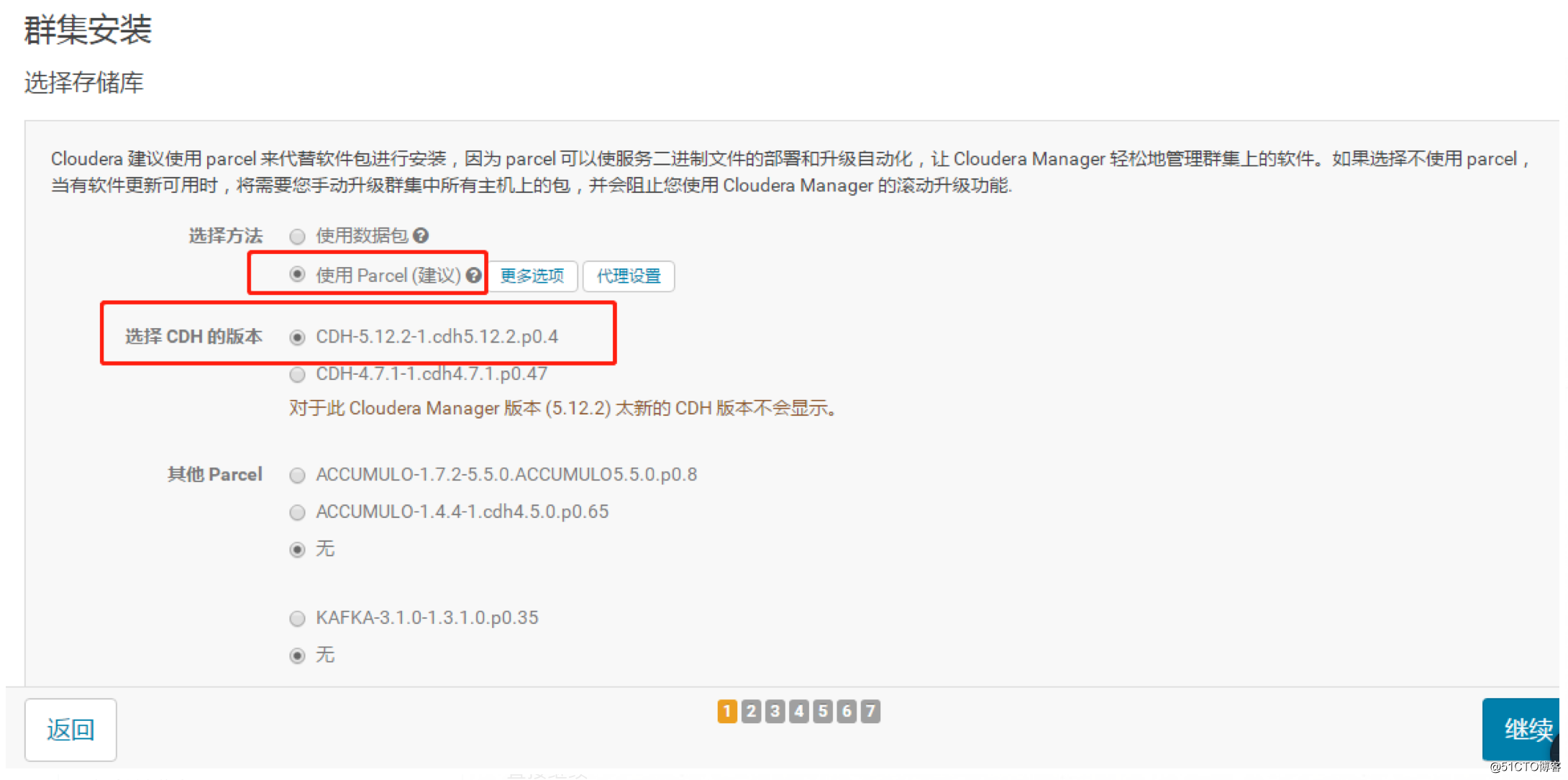
选择parcel安装以及对应版本
直接继续
输入主机对应账号密码
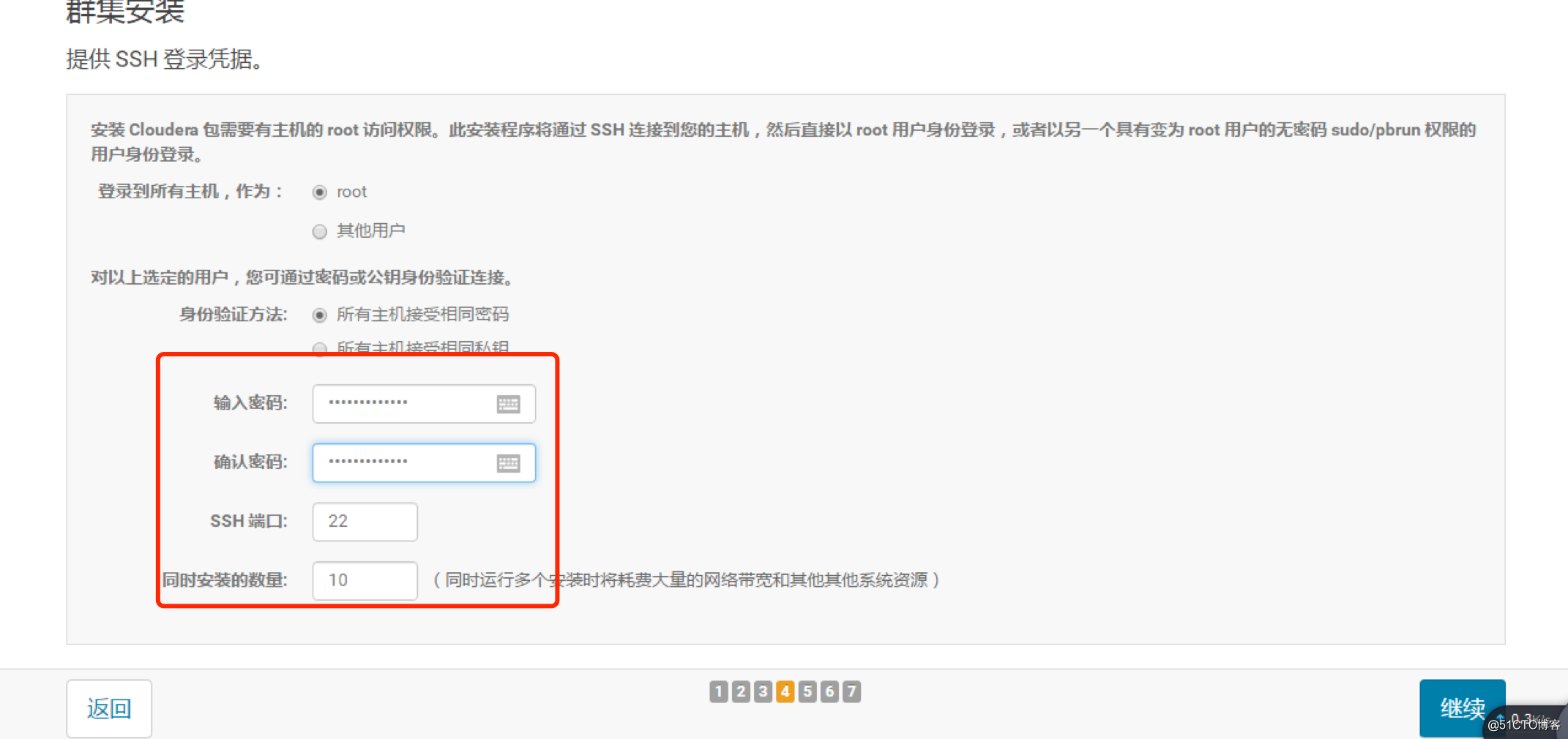
因为事前已经安装过agent,所以接下来的节点部署会比较轻松
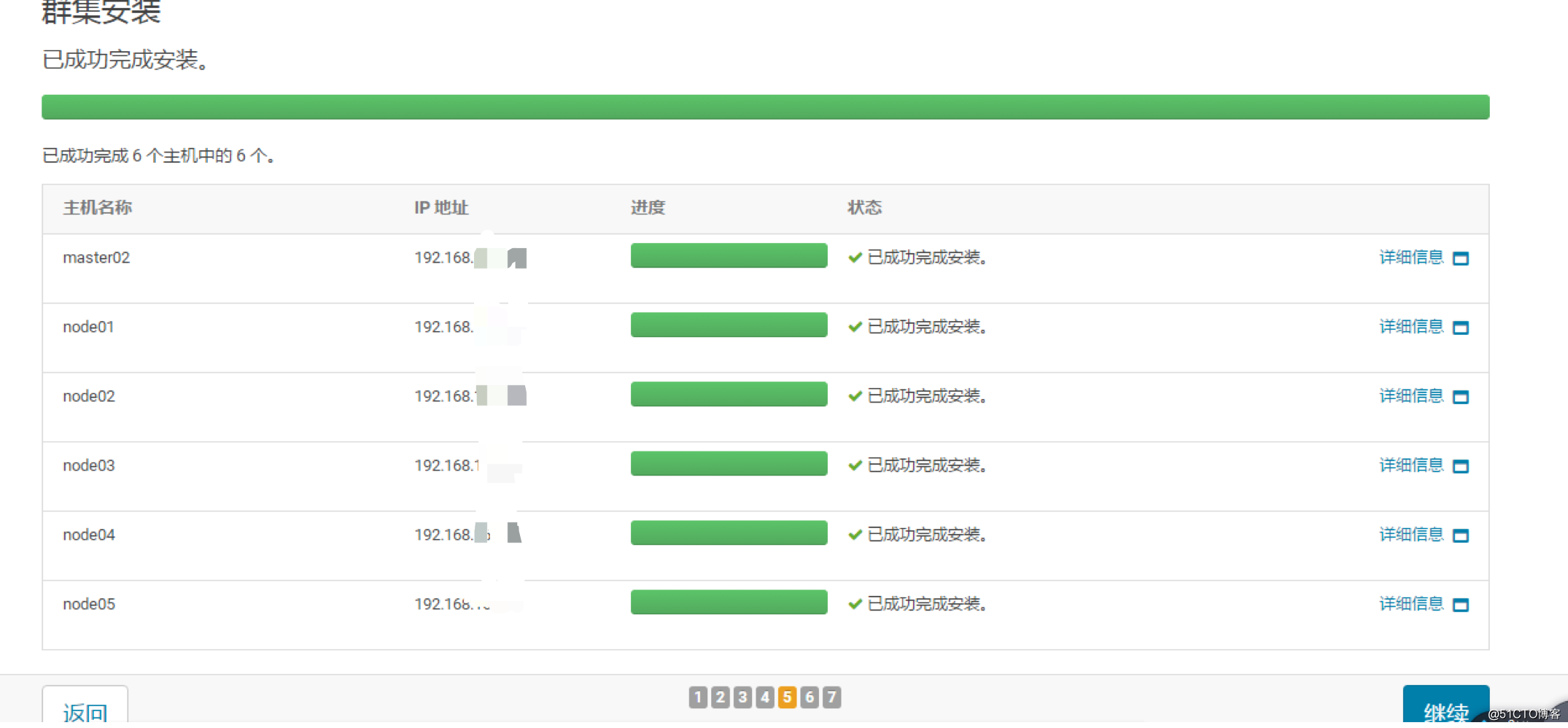
PS:图中IP和文档举例情况不同哈,部署中按照实际ip而定
之前已经部署过parcel包,所以这边会比较快

根据实际业务情况,这边跟我实际需求我选择了spark
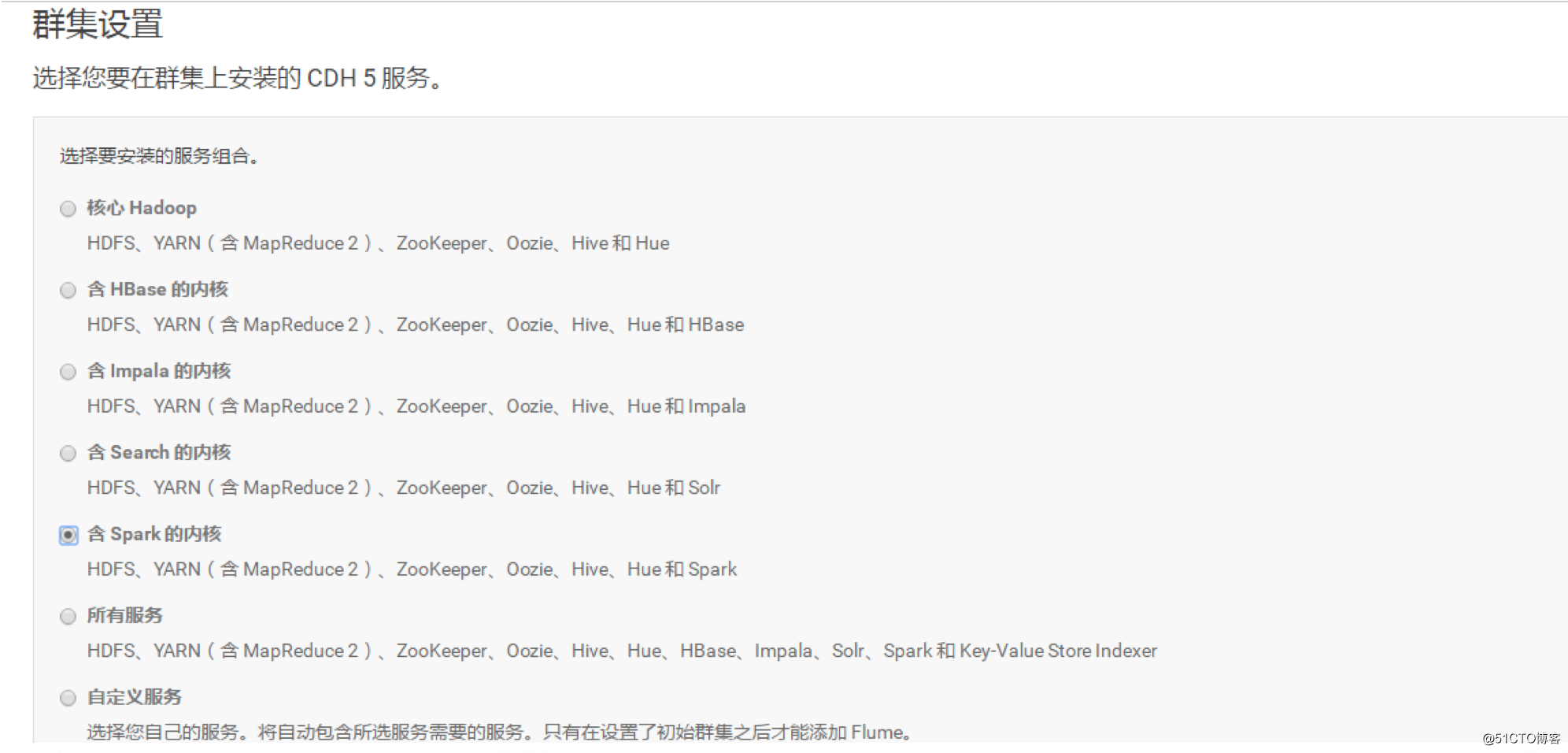
根据实际情况进行节点分布

NameNode:主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
Secondary NameNode:的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点,注意,这不是备份节点,是检查节点,要特别注意!!!
Balancer:平衡节点之间的数据空间使用率
HttpFS:是cloudera公司提供的一个hadoop hdfs的一个http接口,通过WebHDFS REST API 可以对hdfs进行读写等访问
NFSGateway:HDFS的NFS网关允许客户端挂载HDFS并通过NFS与其进行交互,就像它是本地文件系统的一部分一样。网关支持NFSv3。
Datanode:数据存储的节点

Hive Gateway:Hive默认网关,默认每个节点都要有
Hive Metastore Server:Hive元数据的访问入口,使用Thrift协议,提供对hive元数据的跨语言访问。
WebHCatServer:WebHCat提供了Rest接口,使用户能够通过安全的HTTPS协议执行行Hive DDL操作、运行Hive HQL任务、 运行MapReduce任务等。
HiveServer2:Hive库中数据的访问入口,同样适用thrift 协议,提供对Hive中数据的跨语言访问,比如 常见的python, java 等对hive数据的远程访问,beeline 客户端也是通过HiveServer2方式访问数据的
PS:相对而言,如果Hive 中存在一张表。访问这张表的信息 通过 Metastore Server
访问表的具体内容,通过 HiveServer2

Hue Server:Hue Server是建立在Django Python的Web框架上的Web应用程序
Load Balancer:hue的负载均衡

Service Monitor:收集有关服务的运行状况和指标信息
Activity Monitor:收集有关服务运行的活动的信息
Host Monitor:收集有关主机的运行状况和指标信息
Event Server:聚合组件的事件并将其用于警报和搜索
Alert Publisher :为特定类型的事件生成和提供警报
Oozie:是一个与Hadoop技术栈的项目集成,支持多种类型的Hadoop作业(例如Java map-reduce,Streaming map-reduce,Pig,Hive,Sqoop和Distcp,Spark)以及系统特定的工作(例如Java程序和shell脚本),用于管理Apache Hadoop作业的工作流调度程序系统。

History Server:历史任务记录
Gateway:Spark的节点调度网关

Resource Manager:资源分配与调度
Job History:历史任务调度记录
Node Manager:单个节点的资源与任务管理
Server:至少三个节点,合理的话五个节点,主要用于配置管理,分布式同步等
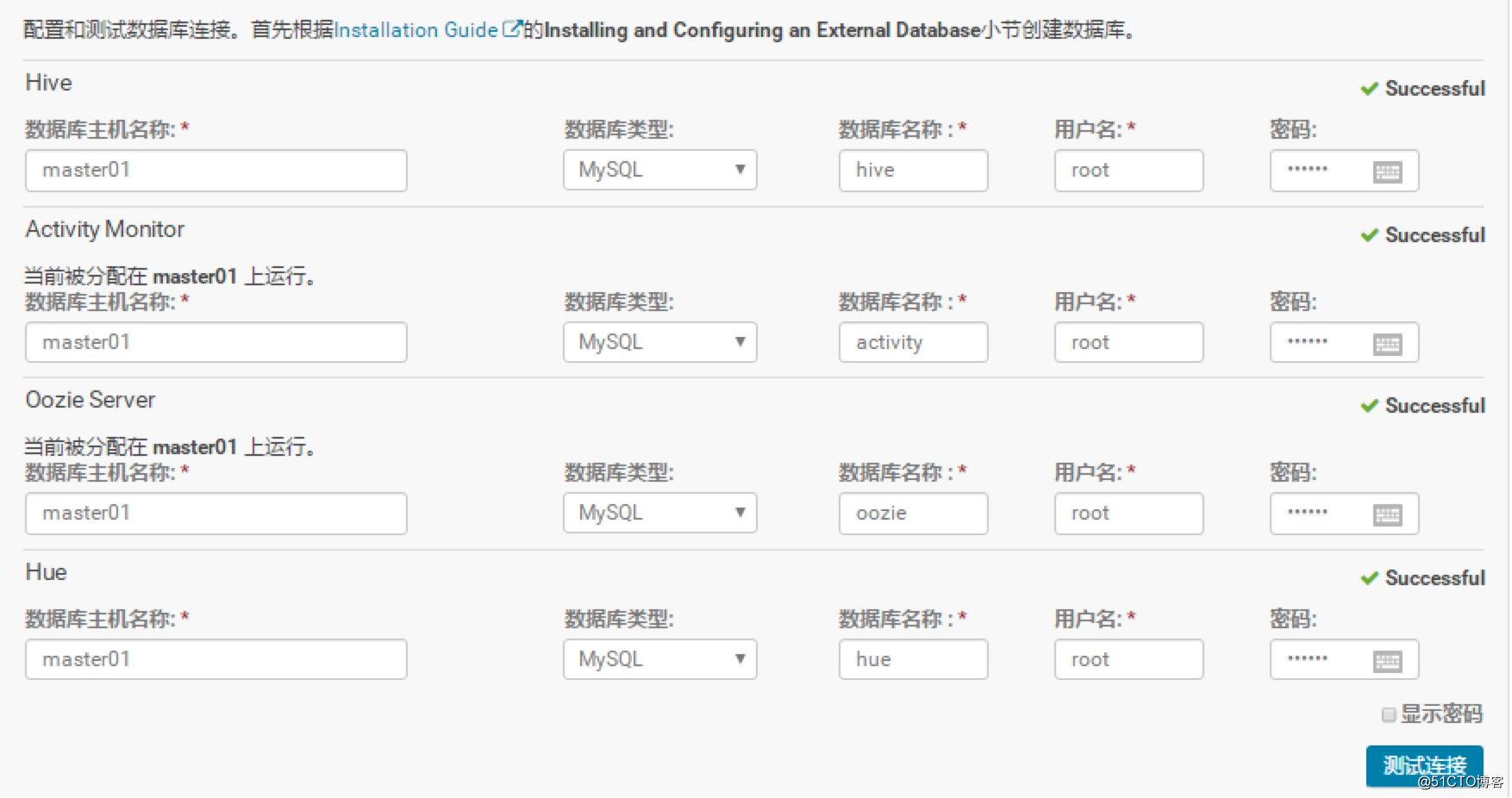
直接下一步可以配置对应的数据库连接,具体如下图
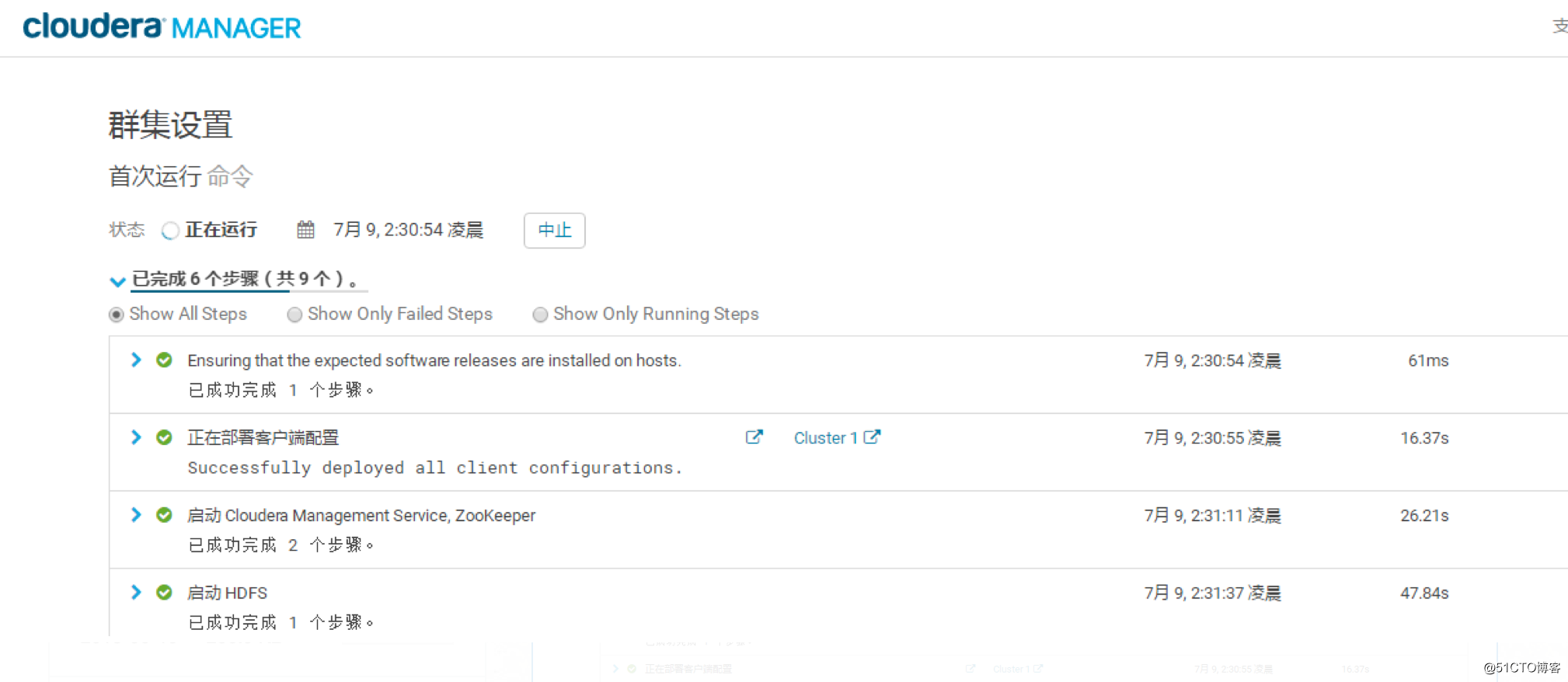
下一步-->就会开始按照之前的部署自动安装
最后,集群搭建完毕,欢呼!!!
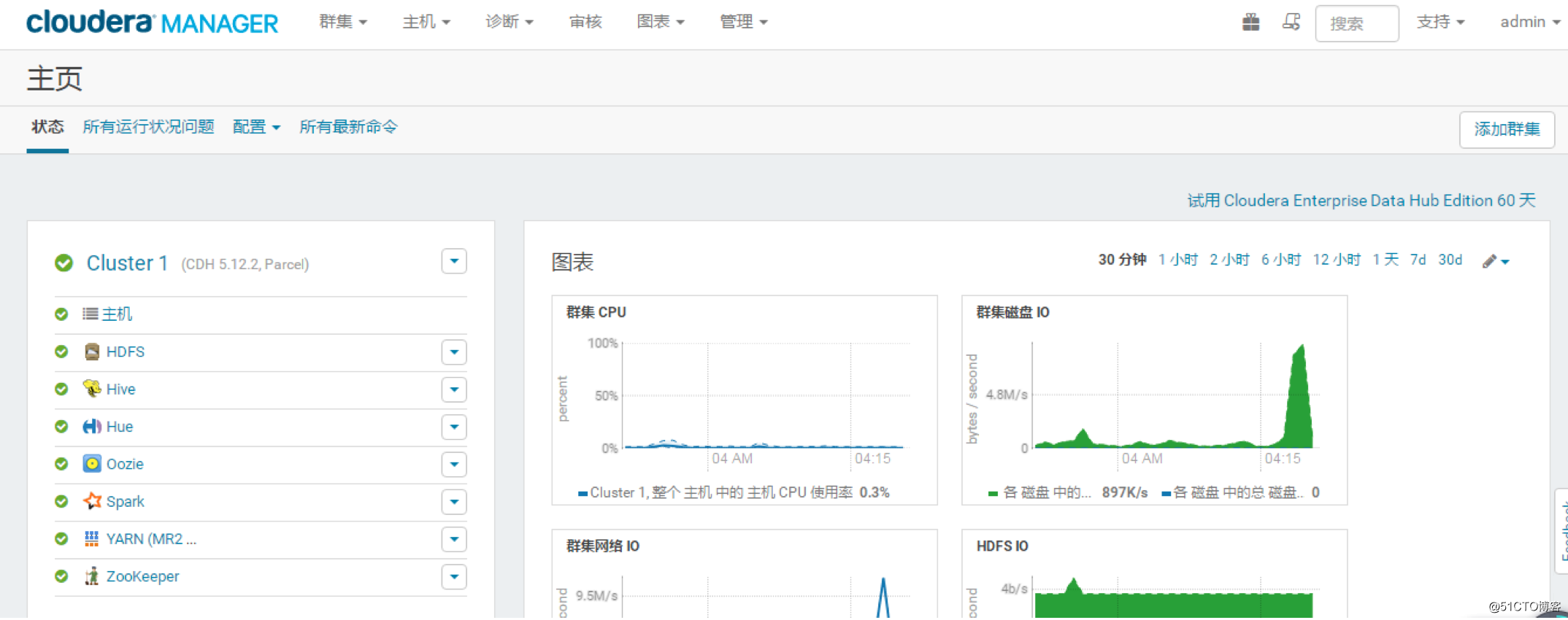
总结
CDH提供了相对完善的组件和管理机制,但不代表着不需要维护和优化了,后续会逐渐说些优化相关的内容