很多介绍TF开发的书籍中都喜欢用逻辑回归拟合线性二维数据来开始介绍TF的开发过程,按照数据准备,模型搭建,反向损失函数定义和训练模型,使用模型的的顺序来介绍,并给出代码。但TF框架本身隐藏了其中的大部分流程,只暴露了一小部分参数供给用户程序调节,导致学习者知其然但不知道其所以然,可能一行剪短的tf函数调用,隐藏了大部分的实现细节。根据网上学习的资料,结合自己摸索,这里给出一种不依赖tensorflow用单神经元实现一次函数拟合的例子,也是用python实现。这样做一方面是因为自己也是个新手,写出来的过程本身就是学习的过程,可以加深印象,另一方面,如果当中有不对的地方,也好让别人指点,纠正。
单个神经元工作模型:
对于符合形如
![]()
此类线性函数分布的数据,理论上单个神经元即可实现对其进行拟合. 单神经元的工作模型如下:
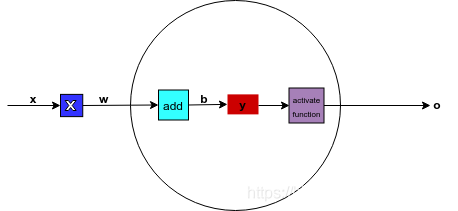
网络完成的功能简要介绍如下,x作为样本输入端,w是权重,中间方形框表示x,w之间的操作是乘法操作,然后结果在加上后续的b,得到的结果y在进行一个叫做activate function函数的变换,得到最终输出o. l上述计算过程用方程表达如下:
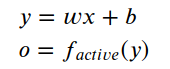
在神经网络领域,专业的叫法称呼b为偏置,w为权重,f为激活函数(activate function),也叫非线性单元
拟合的过程不过就是通过不断的输入样本,根据输出值和预期值的误差变化趋势,不断调整权重w和偏置b,得到适合样本数据的最佳权重和置换值,这个过程就是训练的过程。
另外插一句题外话,我学的是自动化,自动化专业接触最多的一个词就是”负反馈",上面介绍的神经网络工作过程,实际上也是用了反馈的原理,将预期值和实际值之间的误差作为控制信号源,通过网络”反馈“给前面的神经元节点,产生控制w和b变化的控制信号,从而使输出和预期值拟合的过程。常用的BP神经网络,BP(back propagate,负向传播)也和负反馈的原理神合,负反馈对应的控制变量变成了负梯度。
下面根据以上网络模型,给出带噪声的符合y=6x规律的数据拟合实现。
数据准备:
下面的代码产生一组介于区间[-1,1]之间的100个样点,并将每个样点值乘以6之后加上随机噪声进行输出。
import numpy as np
import matplotlib.pyplot as plt
traing_x=np.linspace(-1, 1, 100)
traing_y=6*traing_x + np.random.randn(*traing_x.shape) * 0.3
plt.plot(traing_x,traing_y,'ro', label='Original data')
plt.legend()
plt.show()数据图像为:
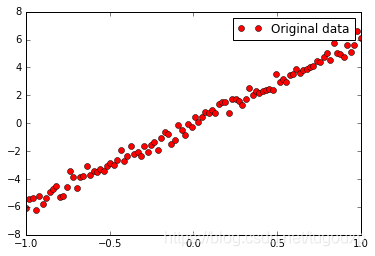
根据数据图像分布来看,总体上符合
![]()
的分布规律,噪声影响导致数据点在距离直线不远的范围浮动变化。
选择激活函数:
选择比较常用的sigmoid函数作为激活函数,其图像为:

选择将其作为激活函数的另一个原因是, 从数据分布图上可见,在区间 x的取值区间[-1,1],y 的取值范围为[-6,6], sigmoid函数在[-6,6]区间上具备比较良好的区分度。
将函数复核后,上述神经网络的传递方程式:
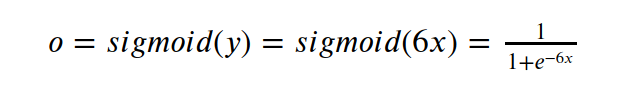
图像变成如下所示:

网络traing是根据负梯度进行的,负梯度的计算过程是损失函数对权重和偏置的偏导数,根据链式求导法则,对sigmoid函数求导是链式法则的中间一环,下面是计算sigmoid导数的过程
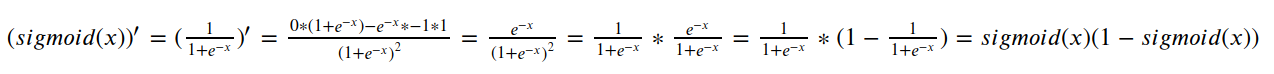
所以,sigmoid函数的导数为:
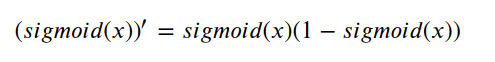
选择损失函数:
这里选择均值平方差(Mean Squared Error, MSE),也叫做”均方误差" 作为训练结果的评价指标,也就是loss函数,它主要表达的是预测值和真实值之间的差异,在数理统计中,均方误差是指参数估计值与参数真实值之差平方的期望值,它的定义如下:
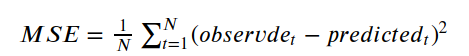
其中预测值和真实值是经过sigmoid函数进行映射之后的输出。
以单次训练为例,本例中,每一期训练的每单笔数据均为一个样本:

训练优化的目的就是不断减少损失函数的值,我们知道,改变网络的权重和偏置可以影响预测值,但我们应该怎么做才能使结果朝着损失函数减少的方向优化呢?这里需要高等数学中的一些概念。
observde是样本真值,是属于模型外部输入的常数,不用对其求导,所以,对w, b分别求偏导为:

模型搭建:
定义激活函数, 损失函数,sigmoid求导函数等子程序:
# Sigmoid activation function: f(x) = 1 / (1 + e^(-x))
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# Derivative of sigmoid: f'(x) = f(x) * (1 - f(x))
def derivative_sigmoid(x):
f = sigmoid(x)
return f * (1 - f)
def mse_loss(expect, actual):
return ((expect - actual) ** 2).mean()然后定义神经元,其中导数按照上面给出的公式计算,但是,根据偏导数更新新的w,b值呢? 这里用上了负梯度的概念。
根据上面的公式,损失函数的梯度为:
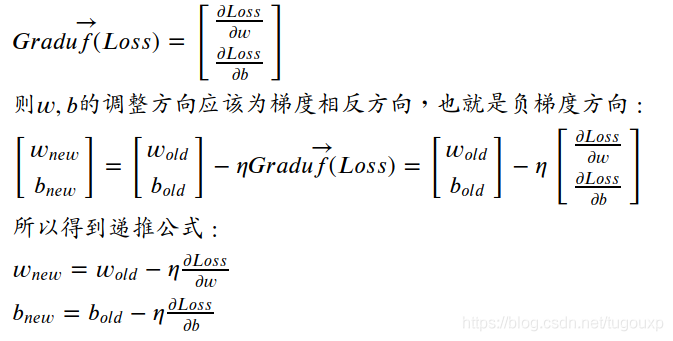
至于为什么选择负梯度,你可以这样想:

其中为梯度下降算法的下降变化率,用来控制梯度算法的收敛速度的,在机器学习中有一个专门的名字,叫做学习率,可以取0~1之间的数字,当得到在局部最优的偏置和权重后,梯度向量变为0,递推公式得到稳定输出,此时
算法达到最优解.
class one_neural_network:
def __init__(self):
# Weights
self.w = np.random.normal()
# Biases
self.b = np.random.normal()
def feedforward(self, x):
# x is a numpy array with 2 elements.
o= sigmoid(self.w * x + self.b)
return o
def train(self, input, expect):
learn_rate = 0.1
epochs = 600 # number of times to loop through the entire dataset
datasets = traing_x.shape[0];
result = np.zeros(epochs)
for epoch in range(epochs):
for counter in range(datasets):
x=traing_x[counter]
y=traing_y[counter]
o1 = self.w * x + self.b
o2 = sigmoid(o1)
exp = sigmoid(y)
d_L_d_input = -2 * (exp - o2)
d_input_d_w = x * derivative_sigmoid(o1)
d_input_d_b = derivative_sigmoid(o1)
self.w -= learn_rate * d_L_d_input * d_input_d_w
self.b -= learn_rate * d_L_d_input * d_input_d_b
y_predict = np.apply_along_axis(self.feedforward, 0, traing_x)
loss = mse_loss(sigmoid(traing_y), y_predict)
print("Epoch %d loss: %.3f" % (epoch, loss))
result[epoch] = loss;
print(self.w)
print(self.b)
plt.plot(result)
plt.grid(True)
plt.axis('tight')
#plt.ylim(0,0.1)
plt.show()编写应用代码:
应用代码其实非常简单,都是对上面已经封装好的函数的直接调用,把模型数据喂给这些函数就好了.
# train our neural network!
network = one_neural_network()
network.train(traing_x, traing_y)执行训练:
程序中设置学习率为0.1,训练600轮,经过600轮的训练后,得到的结果如下:
Epoch 595 loss: 0.001
Epoch 596 loss: 0.001
Epoch 597 loss: 0.001
Epoch 598 loss: 0.001
Epoch 599 loss: 0.001
6.02222669476
0.0489193518788
损失曲线:
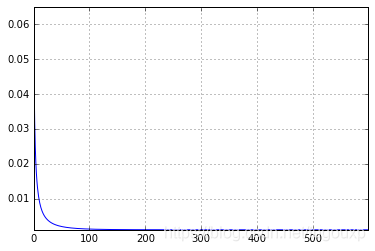
由数据可见,经过600轮训练后,loss平均值稳定再0.001,从损失曲线也可以明显看出,随着训练进行,MSE损失越来越小。
最终,训练出来的w=6.02222669476,b=0.0489193518788非常接近真实值6和0.
进一步,修改模型函数,调整初始数据的w和b值,看上述代码能否追踪新的变化,让b=4, w=2,调整训练1500轮。
traing_y=2*traing_x + np.random.randn(*traing_x.shape) * 0.3+4损失函数变化图:
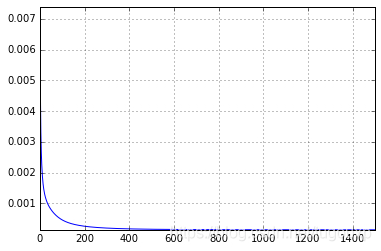
Epoch 1496 loss: 0.000
Epoch 1497 loss: 0.000
Epoch 1498 loss: 0.000
Epoch 1499 loss: 0.000
1.93756984637
3.91283159652
值得注意的是学习率的值对训练效果影响很大,不合适的学习率甚至有可能导致损失函数不收敛,在合适的学习率下,损失函数每一步迭代都会有所减小,表现在图像中就是损失函数随着迭代次数增加,呈现单调递减的形态。
数学家已经证明,只要学习率设置的足够小,损失函数一定会收敛,只是收敛的速度有快有慢,所以如果遇到不收敛的情况,最大可能是学习率设置的太大了。
可以看到w收敛到1.93756984637,b收敛到3.91283159652,非常接近2和4,loss值已经接近0,误差基本检测不到了
以上就是TF框架中关于回归训练的原理展开,虽然不一定相同,但思想应该是一致的。
附图
执行完学习,就该进行推理了,输入一个新的x值,它会给你一个最符合实际的输出。