操作系统设计的精妙之处就在于,在底层硬件之上创造了新的抽象, 对于系统初始化来说, 它呈现了执行流到线程转化这一概念,该概念远远比它的实现细节更加重要,处理器以“取指-执行”为周期开始串行执行指令,而初始化代码将自身转化为一个并发处理系统, 这里的关键之处在于,初始化代码并没有创建一个独立的并发系统,然后跳转到新的系统。抽象建立的前后不存在真正的跨越,原来串行执行的初始化程序也并没有被抛弃,相反,初始代码可以声明自己是一个线程,填充进程需要的系统数据结构,允许它以线程的身份继续存在,并允许其它线程执行,与此同时,系统第一次唤醒了自己的三头六臂却混然不知,处理器仍然继续着“取指-执行”周期,就好像任何事情都没有发生,而抽象已经在不知不觉中出现了。
同样是初始化, 为什么有的初始化后仍然是前后台裸机, 而OS却产生了并发执行环境, 这种质变的分界在哪里?
分界可能并不存在!
道生一,一生二,二生三,三生万物, 何其奇妙!
对于通用操作系统的定义,可以想象一个场景,我们有一个主程序A,它让机器通过一条一条的执行内存中的指令来完成要求的任务,然后我们可以在这些内存中存入另一个程序B,在我让机器运行程序A的时候,它首先要做的事情是访问这些内存,而这些内存代表的是程序B的指令,机器随之执行,执行的结果代表程序B的功能.
其实如果我们将主程序A固化在系统里面,使其成为烙印在ROM中的"固件",这台机器就成为不仅可以运行B程序,也可以运行C,D,E,F .....各色程序,这样就可以一劳永逸的的解决问题,A就是操作系统.
通用操作系统架构:

上下文切换就是并发执行幻觉的核心,理解调度器的关键在于调度器仅仅是一个函数,也就是说,操作系统的调度器不是从一个进程里拿出CPU并将其转移到另一个进程的主动代理,而是由某个执行中的进程来调用调度器函数。
1.一般情况下,RTOS的Idle任务只能被抢占,不会主动出让处理器,因为idle的实现一般是个死循环,执行流中没有主动出让处理器的调用,这是为什么呢?从zephyr的idle设计可以看出,这样做是为了避免在idle中频繁执行调度器调用,因为调度器为了保证原子性,会被各种系统锁重重保护,如果idle的调用路径中频繁获取各种锁,显然有伤系统性能。
Idle任务的实现为一个死循环,执行流中不包括会引起出让处理器的操作,所以只能依赖于异步上下文,比如timer中断,外设中断等中断设施来保证调度期有执行的机会出让处理器.
Linux则不同,Linux的idle在出生时就是关闭抢占的(preempt_count为1), 所以中断之类的异步事件是无法抢占ilde任务的,反而依赖于schedule_idle中主动调用schedule函数出让处理器,如下图,这也侧面说明了Linux的非实时系统的原因.

再preempt_sched_irq的实现中,调度前打开中断是安全的,而melis中这样做会导致idle任务栈爆掉,也是由于melis允许抢占idle,而linux不允许,系统大部分时间是运行再idle状态的,这样会导致终端寄存器现场不停的再idle栈中积累,导致爆栈.

idle如此特殊,无论在linux还是rtos上面,都必须始终保持在ready就绪状态,因为其它线程都有可能被挂起,为保证系统总能找到一个可执行的上下文(想象一下idle被挂起了,其他线程也一样,CPU无所适从多尴尬). idle必须始终活跃。所以任何可以打断idle执行流的上下文,比如中断,都不能调度,因为中断可能抢占的是idle的执行环境。
idle class的dequeue最能说明问题了,发现这种情况直接kernel error.
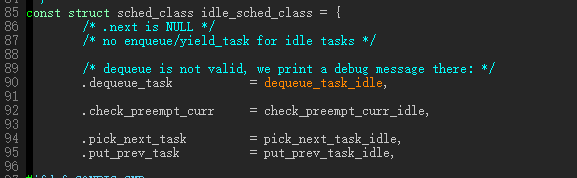
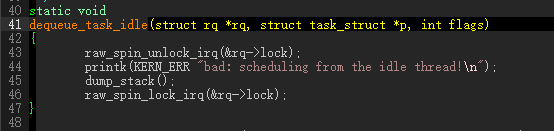
关于强占,强占性系统和非强占性系统的区别非常明显,在强占性调度系统中,线程可以在执行中的任何时刻因被其它线程抢占而挂起,甚至当前线程是刚刚执行完抢占准备投入运行时也是如此,但是在非抢占系统中,当线程意图让一个线程block而让其它线程运行时,此线程并不一定马上被block,它需要等到线程运行到进行一次系统调用才可以。
非抢占的系统有一个好处是变成模型简单,每一个不包含对系统调用的代码都会自动成为一个critical section,这样天然就避免了竞争条件,另一方方面,因为非抢占调度是独占运行的,所以他们不能利用多处理器,需要小心处理长期运行的不含有系统调用的代码区,需要在其中主动插入yield之类的调用,避免CPU锁死在一个协程上运行。
操作系统的基本分类:

一般系统,包括linux在内,抢占点大致分成如下几类:

在一个并发编程系统中,进程不应该在等待其它进程时仍然占用处理器。
调度器设计,机制和策略分离的方式。

2.Nuttx里面, 单核模式下,如果即将就绪的任务位于高优先级,但当前运行的线程恰好又关闭了调度器,这个时候将就绪任务放到g_pendingtask队列而不是g_readytorun里面,其它任何情况都是放入readyqueue。
就绪任务/抢占情况 高优先级 低优先级
当前任务关闭抢占 放入g_pendingtask 放入g_readytorun
当前任务打开抢占 放入g_readytorun 放入g_readytorun
当前任务关闭抢占,高优先级的情况:语义上避免抢占,高优先级任务放入pending queue,可以从根本上保证这一点,抢占恢复 时,在将pending list里面的任务放到ready queue.
当前任务关闭抢占,低优先级的情况: 由于任务优先级比正在运行的任务优先级低,所以即便放进readyqueue,也不会发生误抢占,优先级第一的原则还是要遵守的。
当前任务打开抢占,高优先级:应该放到readyqueue,让抢占发生,因为限制抢占的因素都不存在。
当前任务打开抢占,低优先级:同理,放进去也不synchronize_rcu_tasks() makes sure that no task is stuck in preempted会抢占,而且允许抢占,没必要担心误抢占的case.
抢占的必要条件是,调度器首先要独立,调度器本身也是一个函数,调度器独立的意思是,系统必须让调度器有机会运行,而不过度依赖当前运行环境。典型而有效的做法是,将调度检查放置在中断的退出执行路径中,由于中断的独立性和高优先级,能够保证
调度器一定有机会执行。
不知道是不是个规律,悬挂队列(比如信号量,互斥锁队列)等的任务是没有优先级的,只有任务被唤醒放到readyqueue的时候,优先级才会起作用,当然你可以认为睡眠队列是FIFO队列的优先级也起作用。
3. UCOSIII里面,OSSched执行任务切换的操作,限制条件是 OSSched调用之前,不允许处于临界区,
具体点说就是中断不嵌套,并且调度器不上锁,rt-thread的做法是,中断可嵌套锁, 但调度锁不可以上, zephyr又不一样,不但中断嵌套关闭的时候可以调度,调取器嵌套上锁的时候也可以调度。
387 void OSSched (void)
388 {
389 CPU_SR_ALLOC();
390
391
392
393 if (OSIntNestingCtr > (OS_NESTING_CTR)0) { /* ISRs still nested? */
394 ¦ return; /* Yes ... only schedule when no nested ISRs */
395 }
396
397 if (OSSchedLockNestingCtr > (OS_NESTING_CTR)0) { /* Scheduler locked? */
398 ¦ return; /* Yes */
399 }
400
嵌套中断锁 嵌套调度锁
rt-thread 可以调度 不可以调度
zephyr 可以调度 可以调度
ucos 不可以调度 不可以调度
freertos 可以调度 不可以调度(参考uxSchedulerSuspended)
nuttx 可以调度 可以调度
4.执行PC概念,多任务情况下每个线程都有一个虚拟PC指针,表示当前线程的执行点,单核和多核都是如此。
关键节保护的核心在于,任何情况下(单核,双核,任务之间,任务和中断之间),系统中都应该只有一个虚拟PC代表的上下文位于关键节.
线程是被操作系统调度的实体,具体方式由操作系统选择,锁让程序员获得一些控制权,通过给临界区加锁,可以保证临界区内部只有一个线程活跃,锁将本来由操作系统调度的混乱状态变得更为可控
怎样评价一个锁的实现的好坏呢? 第一是看实现是否有效,能够有效保证临界区的互斥安全. 第二是公平,不能有竞争锁的线程出现饿死,第三就是性能,利用队列睡眠和自旋实现对处理器的浪费是不一样的
5:关于zephyr sdk的实现,官方文档是这么说的:
This differs significantly from how devicetree is used on Linux. The Linux kernel would instead read the entire devicetree data structure in its binary form, parsing it at runtime in order to load and initialize device drivers. Zephyr does not work this way because the size of the devicetree binary and associated handling code would be too large to fit comfortably on the relatively constrained devices Zephyr supports.
6. Zephyr。
The kernel also has the concept of “locking the scheduler”. This is a concept similar to locking the interrupts, but lighter-weight since interrupts can still occur. If a thread has locked the scheduler, is it temporarily non-preemptible.
7.Zephyr关于RTOS 使用周期性时钟的局限性, 基本上这也是所有RTOS实现的局限性。
The amount of added time that occurs during a kernel object operation depends on the following factors.
-
The added time introduced by rounding up the specified time interval when converting from milliseconds to ticks. For example, if a tick duration of 10 ms is being used, a specified delay of 25 ms will be rounded up to 30 ms.
-
The added time introduced by having to wait for the next tick interrupt before a delay can be properly tracked. For example, if a tick duration of 10 ms is being used, a specified delay of 20 ms requires the kernel to wait for 3 ticks to occur (rather than only 2), since the first tick can occur at any time from the next fraction of a millisecond to just slightly less than 10 ms; only after the first tick has occurred does the kernel know the next 2 ticks will take 20 ms.
8: 在SMP 模式下,任务切换时需要保证被切换出去任务的下列行为是原子的
1.任务被放置回readyqueue
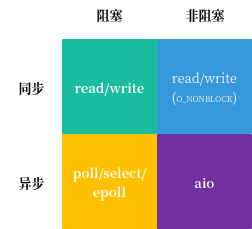
2.任务上下文保存操作
上述1, 2, 需要保证是原子操作,中间不能被打断,才是安全的切换方式。
如果把次序反一下
9. rt-thread是如何保证第八条的呢?
在中断处理的入口,vector_irq执行一开始,首先构造并保存被中断执行任务的现场,而不是像单核模式只是构造一个临时上下文去调用C程序, 在切换点,释放锁之前,务必保证寄存器现场已经保完毕。
10. zephyr是如何保证第八条的呢?
zephyr目前SMP 只支持xtensa, arc, x86_64架构, 从qemu_x86_64的运行来看,有大bug(qemu很容易验证出来),原因是没有follow第八条
11. rtthread smp模式下,进入中断处理后的初始栈帧即是按照任务切换上下文的现场进行布局的,这是与单核模式下构造的临时栈帧布局是不同的
如果中断处理过程中不进入别的CPU状态,则SVC模式下的寄存器不需要进行保存,这也是RTT单核模式下初始保存栈真不按照任务切换的栈帧布局进行保存的原因。

12:还是关于RTT SMP跨任务解锁的一些思考

13:问题的关键点在于,主动切换的现场保存点发生在持大锁之后,而抢占切换由于是异步的,其现场保存点位于拿锁之前
看下图

14:Linux抢占模式下的一些标准特性,首先打开内核的抢占模式
之后,会启用CONFIG_PREEMPT和CONFIG_PREEMPT_COUNT宏

516 spinlock_t test_lock;
517 static int task_thread(void *data)
518 {
519 spin_lock_init(&test_lock);
520 while(1)
521 {
522 printk("%s line %d preempt count %d.\n", __func__, __LINE__, preempt_count());
523 spin_lock(&test_lock);
524 printk("%s line %d preempt count %d.\n", __func__, __LINE__, preempt_count());
525 msleep(1000);
526 printk("%s line %d preempt count %d.\n", __func__, __LINE__, preempt_count());
527 spin_unlock(&test_lock);
528 }
529
530 return 0;
531 }
532 static void linux_thread_create(void)
533 {
534 kernel_thread(task_thread, NULL, CLONE_FS);
535 }
536
如上的测试用例,在打开抢占开关后,调度过程中调度其会报警告,但调度仍然会执行成功
Hardware name: ARM-Versatile Express
[<8011008c>] (unwind_backtrace) from [<8010c188>] (show_stack+0x10/0x14)
[<8010c188>] (show_stack) from [<80669d8c>] (dump_stack+0x78/0x8c)
[<80669d8c>] (dump_stack) from [<80145298>] (__schedule_bug+0x84/0xd4)
[<80145298>] (__schedule_bug) from [<8067ff44>] (__schedule+0x46c/0x720)
[<8067ff44>] (__schedule) from [<80680240>] (schedule+0x48/0xb0)
[<80680240>] (schedule) from [<80683738>] (schedule_timeout+0x88/0x2e0)
[<80683738>] (schedule_timeout) from [<8017fab4>] (msleep+0x2c/0x38)
[<8017fab4>] (msleep) from [<80101ab0>] (task_thread+0x68/0x88)
[<80101ab0>] (task_thread) from [<80107cc8>] (ret_from_fork+0x14/0x2c)
task_thread line 526 preempt count 0.
task_thread line 522 preempt count 0.
task_thread line 524 preempt count 1.
schedule_debug line 3194, preemptcount 2.PREEMPT_DISABLED 1
BUG: scheduling while atomic: swapper/0/759/0x00000002
Modules linked in:
Preemption disabled at:
[< (null)>] (null)
CPU: 0 PID: 759 Comm: swapper/0 Tainted: G W 4.15.10+ #114
Hardware name: ARM-Versatile Express
[<8011008c>] (unwind_backtrace) from [<8010c188>] (show_stack+0x10/0x14)
[<8010c188>] (show_stack) from [<80669d8c>] (dump_stack+0x78/0x8c)
[<80669d8c>] (dump_stack) from [<80145298>] (__schedule_bug+0x84/0xd4)
[<80145298>] (__schedule_bug) from [<8067ff44>] (__schedule+0x46c/0x720)
[<8067ff44>] (__schedule) from [<80680240>] (schedule+0x48/0xb0)
[<80680240>] (schedule) from [<80683738>] (schedule_timeout+0x88/0x2e0)
[<80683738>] (schedule_timeout) from [<8017fab4>] (msleep+0x2c/0x38)
[<8017fab4>] (msleep) from [<80101ab0>] (task_thread+0x68/0x88)
[<80101ab0>] (task_thread) from [<80107cc8>] (ret_from_fork+0x14/0x2c)
task_thread line 526 preempt count 0.
task_thread line 522 preempt count 0.
task_thread line 524 preempt count 1.
schedule_debug line 3194, preemptcount 2.PREEMPT_DISABLED 1
BUG: scheduling while atomic: swapper/0/759/0x00000002
可以看出,sleep前后,preempt的数值不一值,发生不对称的现象。
这是因为 schedule首先会再次递增premmpt_count变量,使变量变为2.
3428 asmlinkage __visible void __sched schedule(void)
3429 {
3430 struct task_struct *tsk = current;
3431
3432 sched_submit_work(tsk);
3433 do {
3434 preempt_disable();
3435 __schedule(false);
3436 sched_preempt_enable_no_resched();
3437 } while (need_resched());
3438 }
但是在 __schedule的执行过程中:
3288 static void __sched notrace __schedule(bool preempt)
3289 {
。。。。。。。。。。
3300 schedule_debug(prev);
。。。。。。。。。。
}
schedule_debugh函数里调用in_atomic_preempt_off进行检查, 一旦发现preempt_countpreempt_count不为PREEMPT_DISABLE_OFFSET,立即报错,并且将counter强行纠正为1.造成不对称。
什么意思呢?这里的意识是,在主动调度(非中断抢占)调度的情况下,要求执行__schedule过程中,最外层只进行一次的preempt_disable调用,不能嵌套调用。更深层次的原因,需要细细品味。
#define in_atomic_preempt_off() (preempt_count() != PREEMPT_DISABLE_OFFSET)
3183 /*
3184 * Various schedule()-time debugging checks and statistics:
3185 */
3186 static inline void schedule_debug(struct task_struct *prev)
3187 {
3188 #ifdef CONFIG_SCHED_STACK_END_CHECK
3189 if (task_stack_end_corrupted(prev))
3190 panic("corrupted stack end detected inside scheduler\n");
3191 #endif
3192
3193 if (unlikely(in_atomic_preempt_off())) {
3194 printk("%s line %d, preemptcount %d.PREEMPT_DISABLED %d\n", __func__, __LINE__, preempt_count(), PREEMPT_DISABLED);
3195 __schedule_bug(prev);
3196 preempt_count_set(PREEMPT_DISABLED);
3197 }
schedule_debug检查的preempt_disable层数为1,客观上决定了idle里面不能睡眠,否则会报错误,原因是 任何睡眠调度接口都会实现再一次调用preempt_disable使 preempt_count再次递增,由于idle环境preempt_count已经为1了,到了schedule_debug毕竟报错。

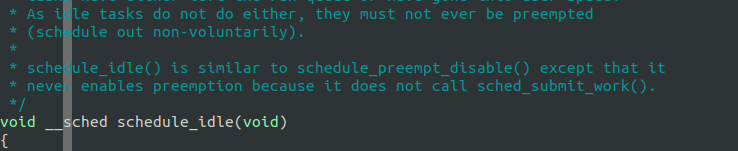
15: Linux IDLE(PID 0)的任务preempt_count为什么设置为 1?默认不抢占?
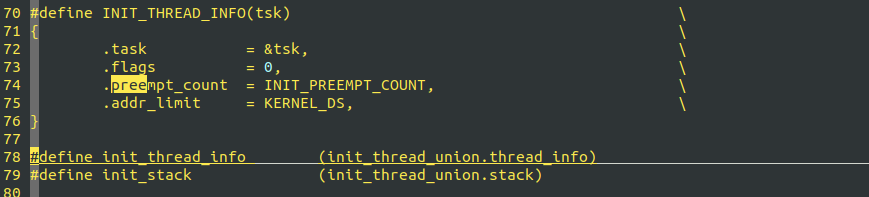
![]()

源码中的注释解释:

16: Linux中的 current指针是通过SP堆栈获取thread_info结构体获得的,所以其和任务切换同时刻发生,具有天然性,
而RTOS中,task_struct在对中,任务切换和current指针赋值并不是同时发生,需要保证原子性。
17: Nuttx CURRENT_REGS中断现场即使 任务调度切换现场
18:关于Linux调度器设计的一些思考
 19:RT-Thread实现中,新创建的任务既可以由rt_hw_context_switch启动,也可以由rt_hw_context_switch_to启动,
19:RT-Thread实现中,新创建的任务既可以由rt_hw_context_switch启动,也可以由rt_hw_context_switch_to启动,
rt_hw_context_switch_to仅供每个核启动第一个任务时调用一次。之后每个新创建的线程都由rt_hw_context_switch启动。
上下文保存有三个地方,首先,任务创建的时候,手工填充任务栈的初始状态,其次,中断发生抢占时,中断处理程序负责保存被抢占的任务现场。最后,任务主动调度时,调用rt_hw_context_switch保存主动退出的任务现场。
20: rt-thread里面,每一次rt_current_thread的重新赋值,意味着SP指针的一次切换,也就是tcb stuct的一次切换。
21:关于大端和小端

22: ARM register convential

23:Linux 任务切换 __switch_to并不保存cpsr状态, 这说明每个任务在切换前后的中断状态是没有记忆性的.
24:rt-thread和linux线程启动的不同点在于,
rt-thread里面,初次任务调度构造的初始寄存器上下文是按照任务的调度现场布局的,这样可以在任务启动的时候调用接口rt_hw_context_switch或者rt_hw_context_switch_to恢复现场.
而Linux下,初次任务调度构造的初始寄存器上下文不是按照任务的调度现场布局的,所以任务首次调度的现场是通过ret_from_fork恢复,运行过程中调度是通过__switch_to恢复现场,这样就可以把异常上下文和任务上下文区分开.

schedule_tail是专门给ret_from_fork封装的接口,整个系统里面只有这里在使用,由于进程首次执行的出口是这里,而不是schedule函数,但是切换要从schedule开始,所以为了保证平衡,这里也必须要执行finish_task_switch函数,同时,由于没有schedule的上下文环境,中断(中断是在finish_task_switch里面重启的)和preempt_disable都要手动打开,如下图。

25:Linux SMP模式下,每个核的idle 都是在preempt_count为1的情况下执行 do_idle loop的.
非启动核

启动核start_kernel

26: Linux调度时机


27: local_irq_save和local_irq_restore调用链里面,如果不通过local_irq_enable强制开中断的话,内层调用是无法使能中断的.
void local_irq_save(unsigned long flags);
void local_irq_disable(void);
对 local_irq_save的调用将把当前中断状态保存到flags中,然后禁用当前处理器上的中断发送。注意, flags 被直接传递, 而不是通过指针来传递。 local_irq_disable不保存状态而关闭本地处理器上的中断发送; 只有我们知道中断并未在其他地方被禁用的情况下,才能使用这个版本。
可通过如下函数打开中断:
void local_irq_restore(unsigned long flags);
void local_irq_enable(void);
第一个版本将local_irq_save保存的flags状态值恢复, 而local_irq_enable无条件打开中断. 与 disable_irq不同, local_irq_disable不会维护对多次的调用的跟踪。 如果调用链中有多个函数需要禁止中断, 应该使用local_irq_save.
在2.6内核, 没有方法全局禁用整个系统的所有中断。 内核开发者认为关闭所有中断的代价太高,因此没有必要提供这个能力。
28:关中断和关调度,锁保护的区别.
关中断,系统降维,由多任务降为单任务,系统中不存在异步执行流
关调度, 系统降维,在不主动调度的情况下,系统只有当前任务和中断执行两个执行流,弱于关中断,但强于锁保护
锁保护, 系统不降维,异步执行流不受影响,等待队列的加入,使受影响的任务有了安身之所,不受影响的任务照常执行,同步粒度
更细密
29:如果一个任务占有共享资源,则其优先级不低于其它等待同一共享资源的任务中优先级最大者,否则,可能会出现不占用资源的中间级优先级任务B打断占有资源的低优先级任务,造成高优先级任务不能执行的优先级反转现象
文章中的说法:如果当前任务不占有任何共享资源,那么该任务的原始优先级必须高于或者等于所有处于等待状态的其他任务的原始优先级,换句话说,如果当前任务没有理由去让其它任务等待(该任务不占有共享资源), 那么它必须比其它等待资源的任务更加急迫
30. Linux 中,如果用户态程序进入内核态运行的过程中将preempt_count修改为1并返回用户态,并不会进行可抢占性检查,而可能会直接切换任务进行调度,见"do_work_pending"函数,可能内核认为用户态的程序不应该进行这样的操作,所以即便这样做了,也不应该影响到内核在返回用户态之前执行调度选择的逻辑,如果哪天因为preempt_count出错,也只会杀死内核线程,不会影响到内核全局稳定性罢了.
所以内核不认为用户太设置preempt_count是多么大的问题.
例如:

打开抢占编译内核和模块,qemu仿真,控制台仿真,创建设备节点:
mknod /dev/my_drv c 100 0


可以看到,a.out segment fault,遇到段错误退出了,进一步印证了猜测, 在open中调用preempt_disable后,会导致a.out退出,但是内核继续正常运行.
原因如下图:

![]()

31:还是上面的例子,增加 set_tsk_need_resched调用,进程推出内核态进入用户态之前添加一条调度任务,

重新编译模块,则异常出现在新的地方,内核正常,,用户态进程调度的时候会出错,因为preempt_count计数不对.
 \\
\\
32: ARM处理器,在SVC模式下调用SWI指令需要注意的问题:

33:不论ARM架构还是mips架构,Linux在发生系统调用和中断陷入的情况下,调用最终的系统调用或者中断处理函数的时候,使用的都是当前任务的内核态堆栈,并非独立的中断堆栈.
至于,为什么同样的系统堆栈,为什么系统调用的时候允许调度,而在中断处理中不允许发生调度,猜测可能是:
1.一直在强调的系统调用的时候,内核是on behaf of用户态运行,所以本质是同一个任务,用户太和内核态是一荣具荣,一损具损的关系,顺序依赖,所以同步进行.
2.而中断不一样,中断本质上是和任务属于不同的上下文,虽然中断仍然可以使用当前任务堆栈去工作,但大多数情况下,中断有属于自己的堆栈,而且所有中断共享同一个堆栈的,比如ARM.这个时候,如果允许在中断里面调度出去,由于共享同一个堆栈,只有任务调度回来的时候中断才能恢复运行,但高优先级的中断凭什么依赖地低优先级的任务呢?
根本原因,每个任务有自己的堆栈上下文,用户态和内核态本质上属于顺序执行流,可以绑在一起.
而中断不一样,要么寄生在当前任务的堆栈中执行,要么共享一个独立的堆栈,无论哪种,每个中断都不是独立的上下文,要么依赖任务调度回来,要么没有独立的上下文
34:Linux系统用户任务返回用户态后,内核态堆栈一定是空的,下图中set_saved_sp宏指令设置的t0指针为堆栈最高地址减去32.也就是最高地址
内核态用不到这个地址,而是在当前SP上堆叠, 用户态进入内核态才会使用get_saved_sp获取这里的SP值.
也就是说,内核态线程虽然也设置这里,但是不会用到,用户态才会用到


34:ttwu in linux means, try to wake up
35:ARM处理器关于堆栈对齐的要求:
aapcs要求堆栈八个字节对齐,之所以这样,以我在项目中遇到的一个死机问题说明:
在实现为下图的时候,

系统发生死机,死机现场如下图:

修改成如下图的实现之后,问题消失。

分析原因,死机地址0xc20c2454:处的指令操作为:
c20c2454: f4430a1f vst1.8 {d16-d17}, [r3 :64]
对堆栈中的数据(r3指向)进行64位操作,但是R3并不是按照8字节对齐的,导致死机。

可见这种情况,VFS neon单元如果操作堆栈中的数据,则数据地址要求是8字节对齐的。
GCC编译的C代码默认会满足8字节对齐的要求,但是如果是手写汇编,则一定要注意,忽略此要求可能造成灾难。
36:rt-thread中断唤醒tshell

37:当一个高优先级的线程因为获取一个被低优先级占有的资源而进入阻塞状态时,就不会有(不应该出现)低于此线程的优先级的线程被投入运行。
38:再次强调一遍,线程出让流程中的执行序列
1.从readyqueue就绪表摘除
2.挂入另一个系统唤醒队列
3.出让处理器(主动或者被动抢占)
三步操作中,必须要保证步骤1,步骤2是原子的,否则,如果在已经从就绪队列摘除,但还未被放入系统唤醒队列中的时候,发生一次中断抢占,则此任务就不在可能被调度回来,因为1.readyqueue已经找不到此任务。2.由于没有被成功放入另一个唤醒队列,导致没有系统机制再次让其入队。
所有系统都要保证,不管是linux, rtos.
39:关于shell回显

40.中断唤醒

41: arm lr寄存器是caller还是callee, 不同角度看会得到不同的结果,
由于并非是软件显示操作,而是调用过程中硬件修改,所以其callee saved特性不是那么明显,如果把函数调用+修改lr的操作细分出来看,则在函数调用前后,lr值并没有变化.
认识有误,lr应该是caller saved register,函数保存他的目的是为了在退出时返回用,至于恢不恢复原始值不重要, 例如,r4,r5,.. 为callee saved寄存器,函数保存它是为了在推出前恢复原值,但lr,函数保存它是为了回复PC,而非LR本身


42:Linux timekeeping模块的最原始时间戳,来源于系统RTC等级的UTC时间,会在系统启动阶段设到timekeeping模块

 之后的启动基准时间均来源于当前UTC时间和上面系统初始化记录的UTC时间的差值。
之后的启动基准时间均来源于当前UTC时间和上面系统初始化记录的UTC时间的差值。
可以通过在线时间转换工具将UTC时间转化为北京时间
网址:http://www.matools.com/timestamp

更新xtime_sec的位置在accumulate_nsecs_to_secs,可以看到是在中断上下文执行的。

43:Melis从开机上电到怠速的调度时序:

44:中断期间的重新调度是安全的,只要中断程序让全局数据再重新调度前保持在合法的状态,并且没有函数使能中断回复,除非它先禁止了他们。
这个规则解释了为什么所有的操作系统函数使用的是save/restore处理中断而不是 disable/enable中断,禁止中断的函数总是再返回到调用它的函数前回复中断,没有一个历程能够显示地开启中断。非常有趣又一致的事情是,管理中断的硬件遵循与操作系统相同的范例,发生中断的时候,硬件将会禁止进一步的中断(save),直到处理器从中断处理中返回(restore). 关于禁止和恢复中断的唯一例外就是在系统初始化函数中,在系统启动过程中,处理器禁止所有中断处理,直接多任务条件具备,打开中断触发多任务运行
45:注视十秒,你会有新的想法


46:aarch64内核支持三种用户空间abi: aarch32 ilp32, aarch64 ilp32, aarch64 LP64. aarch32 ilp32由 CONFIG_COMPAT控制,aarch64 ilp32之前在内核staging tree里面,暂时没有合入主线。
aarchxx ilp32/lp64 意思是用aarchxx的指令集和 ilp32/lp64的数据模型来编译程序。
aarch32 ilp32和aarch64 LP64自不必说,native支持的
但aarch64 ilp32,用64位的指令集和ilp32的类型来编译应用会有很多的问题,其他ISA问题更大,例如,当前的编译器,Linux内核和glibc就无法支持在RV64 ISA上运行 ILP32 ABI.编译器更验证,-march=rv64xxxx和-mabi=根本无法同时使用。


46: linux的spin lock具有处理器数主性,不具有线程属主性,处理器属主性的特点是,那个处理器占用,那个处理器释放,占有和释放不必是同一个线程,但一定是同一个处理器.典型的调度队列锁,每个就绪队列都会有一个队列锁. __schedule函数中释放rq->lock的任务是很久之前调度出去的任务,并不是当前调度出去的任务,但一定是在同一个处理器释放锁.
RT-Tthead实现有些不同,它的spinlock实现也是处理器属主的, 但是由于支持了线程嵌套spinlock, 当前线程记录了获取层数,所以只有最后一层释放,才会要求处理器处理器属主性, 并不纯粹,参考代码rt_cpus_lock_status_restore
47:
pthread_mutex_lock(&lock);
while(ready == 0)
pthread_cond_wait(&cond, &lock);
pthread_mutex_unlock(&lock);
为保证检测和加入睡眠队列两个操作的原子性, 必须在pthread_cond_wait函数内部解锁,不能提前.
如果将检测和加入队列顺序反一下,是否就可以不用锁了? 参考linux __wait_on_bit的实现.
48:不同于RTT 里面任何临界区都使用同一个大锁(粗粒度方案),通常大家会用不同的锁保护不同的数据和结构,从而允许更多的线程进入临界区.
49:如果thread->cpus_lock_nest为0, 说明目标线程的切入点不再rt_Schedule里面,也即是初始线程(头一次运行)或者上次的切出是由于中断抢占.
50:中断例程只能调用使运行线程停留在当前或者就绪状态的操作系统函数。外延如下:
1. 如果一个线程在中断发生时刻block的,那中断返回的时候也应该是block的,或者被唤醒为ready的(典型的中断唤醒机制).
例如rt-thread获取信号量操作,线程加入waitlist之后,状态改变为blocked, 随后开启中断准备进入rt_schedule调度,在实际的调度发生之前,可能中断已经进来,在中断里面完成了实际的调度。
2.如果一个线程在中断发生时刻是ready的,那中断返回的时候,也必须是ready的。
51:中断与系统的关系,中断是一种底层机制,它属于底层硬件的一部分,本身并没有带有太多操作系统的色彩。
而操作系统,线程是高层抽象,它们是操作系统设计者想象出来的,并用一套系统函数来定义的,因此,理解中断时只考虑机制而不考虑并发线程(因为没有考虑并发,所以中断实现的时候要考虑不要影响到虚拟出来的世界的一致性).理解并发线程只考虑抽象而不考虑中断(虚拟世界有自己的规则,因为没考虑到中断,但实际上中断是存在的,所以需要做一个处理,比如关中断保护). 这样思考是最简单的。
52.调用者把锁住忽的互斥量传递给函数,函数把调用县城放到等待条件的线程列表上,然后对互斥量解锁,这两个操作是原子操作,这样就关闭了条件检查和县城进入休眠状态等待条件改变这两个操作之间的时间通道,这样线程就不会错过条件的任何变化.
53.如果你用了所有的智慧来写代码,那么你就没有足够的能力来调试它”。这句话有点伤感,不过的确是一个事实。作为一个程序员,不仅仅只是能完成功能,更重要的是当功能出现问题时,你要能很好的找到原因并解决它。
54: ARM debug.

55:Linux资源视图

为什么Linux用户态不需要用关中断的方式保护资源?因为LInux用户态没有中断上下文执行环境,也就没有中断同用户进程争夺空间,即便有一些实现是通过触发用户态入口执行高优先级通知事件的任务,但是这种任务也是在进程环境下执行的,只要是进程环境,就可以通过信号,互斥等粒度较小的机制去同步,保护,所以用户态不需要关闭中断.
56:处理器同步异常和异步异常的一个特征是,同步异常的返回值指向导致异常的指令,而非同步异常的返回值可以是随机指令地址。
57:condition code
58:关于并发的思考

59:关于qemu模拟器的一些理解


CPU执行程序的本质是通过执行一组组有意义的指令改变内存和CPU内部寄存器的状态,改变后的状态反映在物理世界即是程序的执行结果,那么,执行程序的可以不是机器吗?当然没有问题,看过小说三体都知道,由大量的人组成的方阵,按照简单的规则执行动作,即可进行计算.那么在进一步,这些受改变的状态可以是虚拟的吗? 当然也可以,qemu通过TCG翻译技术,将寄生在HOST主机中的一组描述target cpu的context(包括register和内存),按照target程序的规则加以修改,变化,产生出和实际在target cpu执行target程序一样的context状态,就可以了,只不过,这时候target的context没有存储在真正的target cpu寄存器和内存,而是一组存在于host内存中的数据结构而已.
话说回来,即便是在硬件上执行的程序,谁能保证这层“硬件”是真实而不是虚拟的呢? (参考电影,异次元骇客,黑客帝国等).
如果我们的五感都是虚拟的,那IC必然也是虚拟的,所以我们可能从来没有在真正的“硬件”上跑过程序,不是么?
60 FreeRTOS SMP设计,参考linux

61:程序运行的结果是体现在CPU寄存器和内存状态上的,所以虚拟机的主要原理就是模拟程序运行中对内存和ARCH 寄存器的修改,如果能够达到一致的系统状态,跑真机和跑虚拟机有什么区别呢?
62:aapcs 和aapcs-linux的区别在于enums类型的定义不一致
aapcs:enums被编译为可变长度类型,特点是编译器会根据收定义类型的范围界定目标类型。
aapcs-linux: enums 被编译为int类型,在主流处理机上也就是4个字接。

melis默认应该是使用的aapcs abi.






63:一些关于abi的配置参数:

64:软件工程中通常用透密表示某些设施对用户来说是不可见的,这种用法有时候令人困惑,一些人认为,变得透明是把所有的事情细节公之于众,但是再软件领域,变得透明意味着相反的情况,操作系统提供的假象不应该被应用程序看破,因此按照通常的用法,透明系统是一个很难注意到的系统。
65:
Linux系统中每个进程对应用户空间的pgd是不一样的,但是linux内核 的pgd是一样的。当创建一个新的进程时,都要为新进程创建一个新的页面目录PGD,并从内核的页面目录swapper_pg_dir中复制内核区间页面目录项至新建进程页面目录PGD的相应位置,具体过程如下:do_fork() --> copy_mm() --> mm_init() --> pgd_alloc() --> set_pgd_fast() --> get_pgd_slow() --> memcpy(&PGD + USER_PTRS_PER_PGD, swapper_pg_dir +USER_PTRS_PER_PGD, (PTRS_PER_PGD - USER_PTRS_PER_PGD) * sizeof(pgd_t))
这样一来,每个进程的页面目录就分成了两部分,第一部分为“用户空间”,用来映射其整个进程空间(0x0000 0000-0xBFFF FFFF)即3G字节的虚拟地址;第二部分为“系统空间”,用来映射(0xC000 0000-0xFFFF FFFF)1G字节的虚拟地址。可以看出Linux系统中每个进程的页面目录的第二部分是相同的,所以从进程的角度来看,每个进程有4G字节的虚拟空间,较低的3G字节是自己的用户空间,最高的1G字节则为与所有进程以及内核共享的系统空间。每个进程有它自己的PGD( Page Global Directory),它是一个物理页,并包含一个pgd_t数组。
关键字:
- PTE: 页表项(page table entry)
- PGD(Page Global Directory)
- PUD(Page Upper Directory)
- PMD(Page Middle Directory)
- PT(Page Table)
PGD中包含若干PUD的地址,PUD中包含若干PMD的地址,PMD中又包含若干PT的地址。每一个页表项指向一个页框,页框就是真正的物理内存页。
ARM做法:


RISCV做法:

66:关于qemu的用户态模拟和全系统模拟

串口模拟的打印

关于模拟器的是实现策略:

67:Melis4.0的内存映射

68:硬件为操作系统提供的原子性原语有以下几种
1.关闭中断,这个办法只适用于单处理器
2. 测试并设置指令(原子交换)
3.比较并交换(RV的cas指令)
4.链接的加载和条件式存储指令(MIPS的sc,ll, arm的ldrex, strex)
69:关于 IO和处理器设计

70. 虚拟化(内存,CPU,网络接口),并发 和 持久化(文件系统)是操作系统面临的永恒问题
71.RISCV指令编码逻辑的NS图

72:ISA的寄存器数目会限制在复杂流水线中部分执行指令的数量,原因显而易见,寄存器数目过少,会产生更多的数据相关指令,导致流水线不得不暂停或者插入气泡来处理数据相关
程序编译器的质量也会造成一些限制,如果寄存器在指令间调度的不合理,也会造成不必要的数据相关,降低流水效率
一个微架构能否使用比ISA描述的更多的寄存器而不影响ISA的兼容性呢?可以,使用微架构自定义寄存器,来实现在线的寄存器重命名,可以有效提高并发性。
73:模式即维度,安全即宇宙,宇宙包含维度,维度构成宇宙。

74: 关于RV工具链32/64位的支持
RV64:

RV32:
可以看到zephyr sdk中,rv32和rv64两个工具链的multlib属性是一样的,这也是为什么最新的zephyr sdk包中删除了一个冗余的工具链.
GCC 一般都会可以通过组合march和mabi两个选项来生成不同的支持库,但是一般不特别指出,生成的目标库一般不会是你想要的,除非加入 --enable-multilib配置编译工具链,这一点ARM也是类似的, arm支持的multilib包括aprofile和rmprofile.
但是即便加入--enable-multilib选项,也不会生成所有的组合,只会生成GCC当前支持的组合集合,例如上图中,由于目前riscv只有 riscv32 ilp32好riscv64 lp64两类ABI运行环境,还不支持RISCV64 ilp32,所以上图中是看不到riscv64 ilp32的支持库的。
看大牛的解释

75: ILP32 & ISA64做的比较成功的比如x32&AMD64,也就是在普通64位PC上安装unbutu,编译helloworld的时候加上 -m32选项即可得到。
其次是ilp32@aarch64,这不是aarch64支持32位的普遍方式,arm上的普遍做法是处理器设计支持aarch32/aarch64模式切换,这个需要硬件支持,但是目前ilp32@aarch64这种不需要硬件支持,直接在64位ARCh上运行的模式还未普及,已经支持,编译方法是在aarch64 gcc中增加-mabi=ilp32选项。
采用ilp32 & ISA64带来诸多好处,包括:
1.可以使用ISA64提供的便利,比如更多的寄存器可用,效率更高的指令。
2.可以减少内存占用,由于long类型和指针类型从64位变为32位,内存占用变小, 在一个 32位地址空间足够的使用的应用程序上使用64位的指针不会带来任何好处。
3.由于第二个优点,cache效率和命中率会提高,对lp64来说,指针与变量类型的长度变化几乎等同于去掉了处理器上一半的缓存,而这些都可以通过ilp32纠正。
实现起来也并非容易,内核需要能够区分系统调用由真正的64位应用程序的运行x32模式,无论事实处理器运行在相同的模式在这两种情况下。另一个挑战是,这种区别需要在不降低本机64位应用程序速度的情况下进行。
76:之前在某款平台上freertos的移植框架

76:

77:Melis的模块化依赖系统调用,系统设计时为了保证简洁和一致,尽量用较少的CPU状态进行系统调用,比如,在arm平台上,直接在SVC模式下进行SVC系统调用,只要保证保存好clobber(spsr)寄存器,即可保证安全。
但是在RISCV上这样做应该会遇到问题,在使用sbi的情况下,M模式运行SBI, S模式的系统调用需要路由到M模式的SBI呼叫。 supervisor模式下的系统调用无法由Supervisor模式处理,这会是一个问题,要想办法解决。
78: Melis跳转指令编码遇到的问题

79:关于系统的运行域拆解

80:如果一个系统没有任何输入,那么它每次执行的输出应该是一样的,如果一个系统没有任何输出,那执行它就没有任何意义,可见,输入和输出对一个系统来讲,都是必不可少的功能。
81:操作系统不是从外部控制计算机的独立机制,它由软件构成,且操作系统软件和应用软件在同一个处理器下执行,事实上,处理器在执行应用程序的时候,是不能执行操作系统的,反之也是一样,所以,操作系统再设计时需要提供某种机制让操作系统重新夺回控制权。
82:为了支持进程的并发执行,操作系统必须给每个进程提供它可以完全控制硬件寄存器的假象,从进程角度看,一旦进程将一个值存储在某个寄存器中,这个值将会一直保持在那里直到进程改变它,操作系统会对多个进程进行切换,为了能在进程切换时保留这种假象,操作系统必须保存被换下的进程的所有寄存器的值,并将换上进程的最后一次运行状态加载到系统中。
83:又一个通过夹层解决问题的经典范例 ,来自于risc-v.

关于分层的思想,RISCV官方文档中有一段话很有意思,讲的是关于硬件分层的

84:上下文切换的成本不仅仅来自于保存和回复少量寄存器的操作系统操作,程序运行时,它们在cpu cache, tlb,branch predicator,和其它片上硬件中建立了大量的状态,切换到另一个工作会导致此状态被刷新,且与当前运行的作业相关的新状态被引入,这可能导致显著的性能成本.
85.理发师悖论相当的一个计算机科学问题
86:通常的计算机体系结构寄存器堆实现方式

87:threadx分析:

88:单单从寻址模式上看RISC处理器,arm并不像MIPS和RISCV那样是血统纯正,支持太多复杂的寻址模式和多寄存器LS操作。
The general RISC philosophy is to avoid memory access in every instruction, instead only load/store instructions are allowed to touch memory. As a result, RISC architectures need a lot of registers to reduce the need to spill to memory.
Pretty much every other RISC architectures has at least 32 registers, therefore it's worth dedicating one for the zero constant. We can see that: SPARC has %g0, MIPS has $zero or $0, Itanium (strictly speaking not RISC but VLIW, but still tons of registers [128]) has r0, RISC-V has x0, SH-5 has R63, Blackfin has R0, i860 has R0, PA-RISC has R0, ARC has %r0, Motorola 88000 has r0, Alpha with 2 separate zero registers: integer R31 and floating-point F31...
RISC通用处理器的设计哲学是避免使用过多的访存指令,只保留load/store指令可以操作内存,这样既可以简化编译器设计,减少spill到内存的操作,也可以增加并行度,MIPS称为无内部互锁的处理器,一部分原因是在于通过增加寄存器和延时操,减少了大量的数据相关对并行度的负面影响。

89:security mechanism of riscv:

90: ARM ISA
91:关于计算机体系结构,总结了几点,待日后验证
0.编译器编译产生的机器代码,不可能编译产生特权指
1.不允许在核心态下执行一条户指令
2.不允许在用户态下执行一条核心指令

92:关于优先级反转


93:RV64--->(32ISA and 64ISA)
对编译器不支持的扩展指令使用方式。

94.RV Vector ISA Extersion:

95: RISCV Vector Extension.

96:一个超牛的红黑树生成网址
https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
https://zhuanlan.zhihu.com/p/161698859
https://www.cxyxiaowu.com/5653.html
visual group theory:https://www.bilibili.com/video/BV1h4411g7mS?from=search&seid=12987832902266025363
https://zhuanlan.zhihu.com/p/33696410?from_voters_page=true
https://www.matongxue.com/madocs/290
https://www.zhihu.com/question/25524378
https://www.cnblogs.com/tsingke/p/6180167.html
http://www.inrm3d.cn/index.php
https://github.com/pwndbg/pwndbg
https://www.freebuf.com/news/182894.html
http://www.360doc.com/content/20/0815/15/29291909_930482576.shtml
https://www.zhihu.com/question/314879954/answer/638380202
https://blog.csdn.net/genghaihua/article/details/90061194
https://zhuanlan.zhihu.com/p/141923148
https://zhuanlan.zhihu.com/p/161577971
https://www.zhihu.com/question/33325884
https://linearalgebras.com/2a.html
https://zhuanlan.zhihu.com/p/63878975
https://zhuanlan.zhihu.com/p/58920004
https://blog.csdn.net/ouening/article/details/70339341
https://www.wolframalpha.com/input/?i=integrate+x+sin%28x%5E2%29
https://zhuanlan.zhihu.com/p/40783304
https://zhuanlan.zhihu.com/p/40396861
https://mpmath.org/doc/current/calculus/inverselaplace.html
https://www.zhihu.com/question/29721819/answer/664358135
97.

98:与内存有关的错误包括
1):memory overrun
2):double free
3):use after free
4):wild free
5):access uninited
6):read/write invalid
7):memory leak
8):use after return
9):stack overflow
等九种
99:
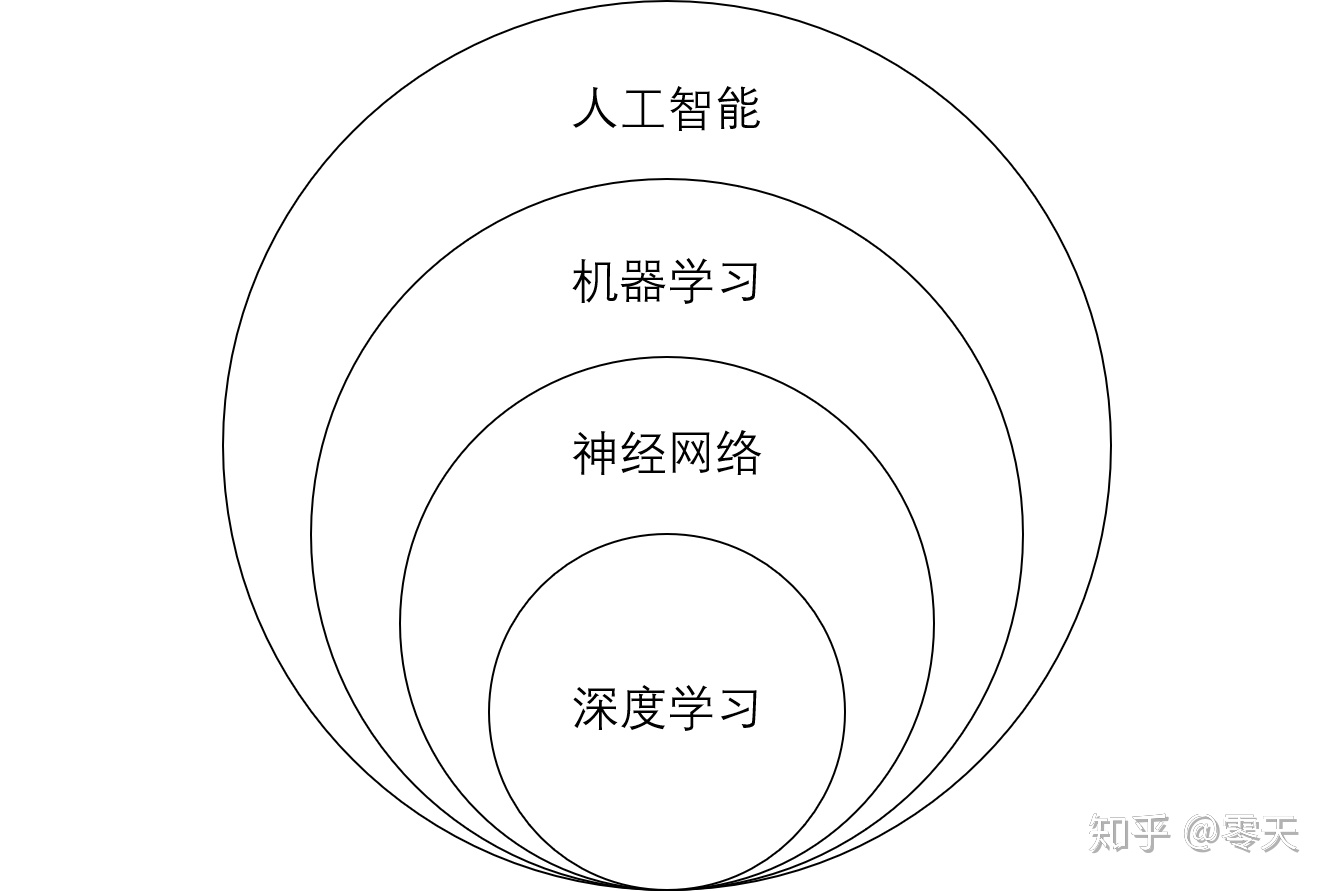
100:算法,算力,数据三驾马车驱动的AI产业如日中天。

101:Tengine OpenAI Lab 架构


102:C906的weak order模型

103:weak order存储模型不保证某核上对不同地址的读写顺序.

举个栗子,小红家楼下有一个邮箱,这个邮箱的工作方式分成两部:
1.邮递员把邮件投入邮箱。
2.按响邮箱旁边的按钮,这样小红就能接收到通知,有邮件了。
小红这边也分成两部:
1.等待按钮控制的指示灯,如果没有亮,就不下楼,原地打转。
2.一旦指示灯亮了,立即下楼,取回放入邮箱中的邮件。
很简单的逻辑,交给人类去做没有问题,因为邮递员和小红(相当于两个处理器核)都只能按照步骤做事,只有一个大脑,翻译成行话就是只有一套流水线,只能做完步骤一在做步骤二。
但是同样的事情,交给CPU做就不是这样了,CPU配备多条流水线,具备乱序执行的能力,由于按灯和投快递是两个独立操作,本身没有关联(是人的意识强加的关联,无法反映到物质上),所以CPU做的邮递员可能会打乱投递和按灯的顺序。
同样的道理,小红在家里等信号灯亮和下楼取快递,也是两条互不相关的操作,没有依赖,如果CPU代替小红执行的话,也可能搞乱顺序,所以,对CPU执行同样的流程来讲,必须人为通过指令把这种联系告诉处理器,让处理器指导,这两个操作是有关联的,不要乱来!
翻译成程序,就是下面这段代码,DMB起到的就是防止步骤乱序的作用。

不加barrier,会导致read指令提前的情况:

104:ARM Cache的工作原理框图。

105:OS标准中定义的服务(一般指函数)被两种实体来使用,中断服务程序(ISR)和任务(Task),不同的实体环境对调用接口的要求也不尽相同,
系统运行时候,有三个处理级别,优先级由低到高分别为任务层,调度层和中断层,处理器需要将高优先级的层任务处理殆尽之后才能进入次级进行处理。

调度曾没有独立的上下文执行实体,比如linux的 schedule, rtos(例如rt-thread, freertos, ucos...)这些都有对应的schedule函数,他们和linux的一个共同点就是,调度器仅仅是一个特殊的函数,调度器都不是独立存在的,需要寄生在任务,中断的环境下被调用。我想知道这是不是可以作为一个OS设计的规则。
任务在四种情况下放弃CPU:
1.任务结束
2.任务切换,OS切换到高优先级的任务上去处理
3.产生中断,CPU执行ISR.
4.阻塞在资源链表

106:排队自旋锁的实现(fifo tickets spinlock),工作模型:
小张来到银行办理业务,先到取票机取票,拿到票号(next),小张看到票面上提示他掐面还有9个人,每个人都有一个next号标识自己的将要在多久之后得到服务。柜台前有一个人正在办理业务,只有它的next号等于柜台前LED屏上打出的号码(owner).当一个人办完业务后,owner增加1,LED显示新的owner值,后面排第一个的人接受柜台服务。每个排队的人手持的next是临时的,不相当于原自旋锁中的next,只是申请时候的快照,真正的自旋锁next存储在取票机中,owner 则显示在LED屏幕上。

过程:

107:链接加载指令实现的状态机

关于arm异常状态的一些spec规范:


108:调用__schedule之前,中断必须是打开的,调度必须是关的,无论任何上下文


109:在使能抢占配置下,linux内核thread_info 结构体定义的preempt_count成员的结构如下图所示:
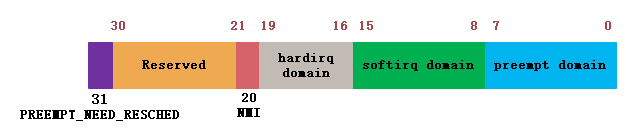
根据执行实际的调度动作前,函数schedule_bug函数的判断逻辑,可以知道,不可调度的上下文有三种:
1.中断,因为hardirq domain不为0
2.软中断,因为softirq不为0
3.preempt domain不为1,说明调用链里面外层函数(驱动等非内核核心函数)有关闭抢占,这时候也不可以执行调度。


110:关于linux 内核ttwu调用关系

111:Linux内核线程正常运行时的上下文

112 :Linux就绪队列的管理,之前一直认为,只要在就绪队列中可以被调度器选中作为next的任务,它的状态一定是TASK_RUNNING,做了一个试验,发现并不是这样。
实验很简单,修改调度器__schedule函数,增加任务状态检查点:


发现还是有比较多的情况下,任务在就绪队列中,但是状态并不是TASK_RUNNING,后面加入了上面第二张图中的dump_stack检查点,查看不符合预期的任务调度点的情况,发现所有在就绪列表中状态不是TASK_RUNNING的任务,最后一次被调度走的原因都是因为被中断抢占。

这就很好理解了,由于不想一般的RTOS那样,任务状态切换和就绪队列的修改是原子的,Linux很多流程里面都是先修改p->state的状态,在打开中断,然后调用schedule出让处理器,由于在开中断和schedule再次关闭中断中间有一个窗口期,在窗口期间就可以发生中断抢占。导致上面的观察情况。
例如 worker_thread的实现就是这个样子,为了放大这种效果,我增加了延时。

__schedule里面操作任务表的逻辑是任务主动出让并且已经更换状态为非就绪态,而抢占不包括其中,这很好理解。

113:CFS调度器,任务在被创建的时候,虚拟运行时间是继承自父进程,这样在初始时刻,它的虚拟运行时间就已经和其它进程在一个数量级上了。
copy_process
|
|
|_ _ _ _sched_fork
|
|
|_ _ _ _ _sched_fork (vruntime = 0)
|
|_ _ _ _ p->sched_class = &fair_sched_class;
|
|_ _ _ _ p->sched_class->task_fork(...)
|
|_ _ _ task_fork_fair(p->se.vruntime = curr->vruntime;)

![]()
114:在多线程程序中使用信号处理程序的时候,一定要注意,信号处理函数中一定不能使用锁,信号处理函数应该尽可能的简单,最好只是对于一些标志位的赋值,然后再其他线程中,对标志位进行轮询查看,在线程中处理更多的逻辑.
原因:信号的执行逻辑是由内核返回用户空间决定 的,对于用户线程来说,任何时刻都可以被内核执行路径抢占,包括持有用户态锁的关健节中,这个时候如果信号处理函数中获取同一把锁,就会造成线程死锁.
115:关于异构的分类

115:关于SMP实现的一些通用思考
RTT实现:
为了保证在调度器启动时刻全局任务队列的安全,RTT划分以下几步:
1).获取_cpus_lock
2).调用rt_system_scheduler_start, 并在其中
1).获取最高优先级目标任务
2)将任务从就序列表摘除,避免释放锁之后被它核根据全局链表访问TCB
3)调用rt_hw_context_switch_to
3)在rt_hw_context_switch_to中,
1)调用rt_cpus_lock_status_restore,由于目标任务没有占有锁,释放_cpus_lock.设置current.
2) 恢复目标任务上下文.
这样,自旋锁的状态达到了平衡,目标任务从entry处开始i执行,不需要像linux那用需要一个fake entry(ret_from_fork) 调用 schedule_tail 来完成后续清理操作,RTT这样做的代价就是,需要在调用rt_system_scheduler_start之前,首先获取一下_cpus_lock锁,看起来和其它的初始化代码画风不太match,不大自然。
所以,对rtt来说,在调度器启动点,中断调度点,和任务主动调度点都需在持锁的情况下调用rt_schedule_remove_thread, 那么有没有可能把这三点个调度点合成一个调度点呢? 这样是否更一致?Linux就是这样做的,看下图。





116.关于不同架构__builtin_apply_args的实现之MIPS


117:SMP任务调度问题可以看成是装箱问题,把处理器集合看成是一堆容积相同的箱子,而各种大大小小的任务则是有不同体积的物品,要解决的问题是如何装箱,使箱子的利用率最高。翻译成SMP的语言就是如何分配大大小小的任务到处理器,使的所有任务都能够得到执行,并且,用的CPU数目最少。
蚁群算法,贪心算法,动态规划,妈妈的,研究生导师是这方面的权威,而我却没有学到皮毛,想想就遗憾!!!

118:消除重复的代码,无论在哪里发现重复的代码,都要消除它们。
消除的方式,一般使用定义一个函数和基类的方式。
消除重复最好的方法就是抽象,毕竟,如果两个事务相似的话,必定存在某种更抽象能够统一它,这样,消除重复的行为会迫使团队提炼许多的抽象,并进一步减少了代码之间的耦合。
119:指令集是程序语义的一种表达方式。同一个算法可以用不同粒度的指令集来表达,但执行效率会有很大的差别。一般而言,粒度越大,表达能力变弱,但是执行效率会变高。

- 领域专用体系结构DSA是未来一段时间体系结构发展趋势;
- 体系结构层面3条优化路线——减少数据移动、降低数据精度、提高处理并行度
120:关于抢占调暗渡和主动调度的堆栈布局,区别仅仅在于是否存在了一个中断现场,由于中断你不允许嵌套,系统中同一时刻,最多情况下,存在taskNUMS个中断现场是左图的样子,也就是每个任务都有一个中断环境。

121:

122:半主机的设计思想

123:可重入和线程安全

124:关于系统调用
系统调用的细节本质上依赖于操作系统,而非硬件或者编译器,比如Linux或者windows用哪个寄存器传递系统调用号,哪些传递参数,完全是操作系统代码定义的,虽然有一些通用的约定,但这些约定不受硬件或者编译器约束。