MIPS最终还是失败了,不过它并不是败给了对手,也不是败给了技术,而是败给了自己,败给了市场。MIPS的失败充分说明了,人美活儿好不一定能混好,MIPS作为一项设计处理器的技术是顶级的,但是它不识时务,一意孤行,几经贱卖,最终沦落到不得不放弃MIPS架构,转头火热的RISCV阵营,曾几何时,一时风光无两的MIPS是X86服务器的主要挑战者,也曾为RISC阵营扛起过大旗。但风云变幻,三十年河东,三是年河西,曾经的小弟ARM,RISCV,一个成为包括手机在内的移动阵营的核心处理器,另一个在IOT芯片领域做的风生水起.MIPS作为曾经的RISC老大哥的处境,让人唏嘘。
不过,从软件开发的角度,RISCV和MIPS还是很像的,个人感觉他们的相似度至少有90%. RISCV继承了MIPS指令集设计的优雅,辨识度高,设计对称的特点,基本上你认识一半的指令,另一半仅靠猜测就可以识别了。现在写一些关于MIPS相关的记录,一方面是为了纪念自己使用过的六年的MIPS,另一方面,在RISCV的学习中,MIPS的设计思路也有非常好的借鉴意义。
RISCV指令格式有六种,包括R-type, I-type, S-type, B-type, U-type, J-type. 而MIPS只有三种,分别是R-Type,J-Type,I-Type.
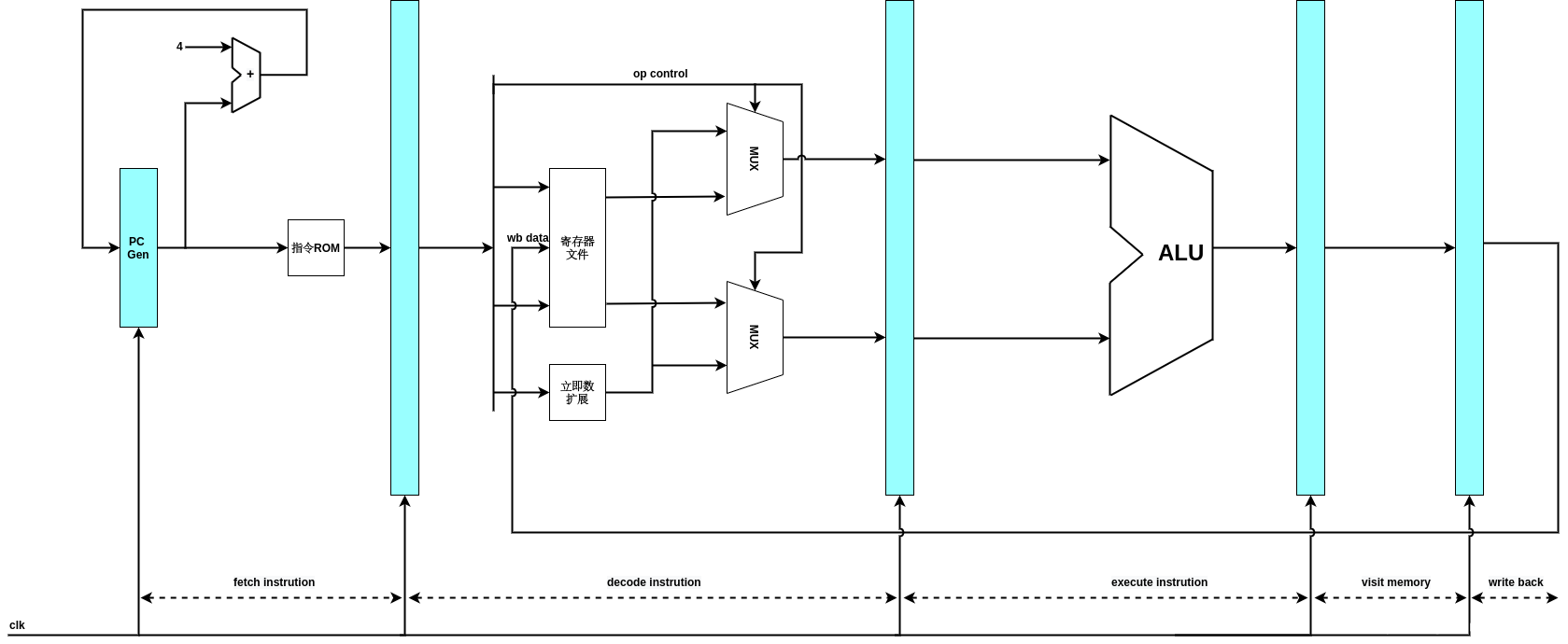
MIPS I-Type的五级流水线如下所示:
I-type指令,有三种类型比如:
运算指令: 例如ori rt, rs, imm16
load/store指令:例如lw rt, rs, imm16
条件分支指令:beq rs, rt, imm16
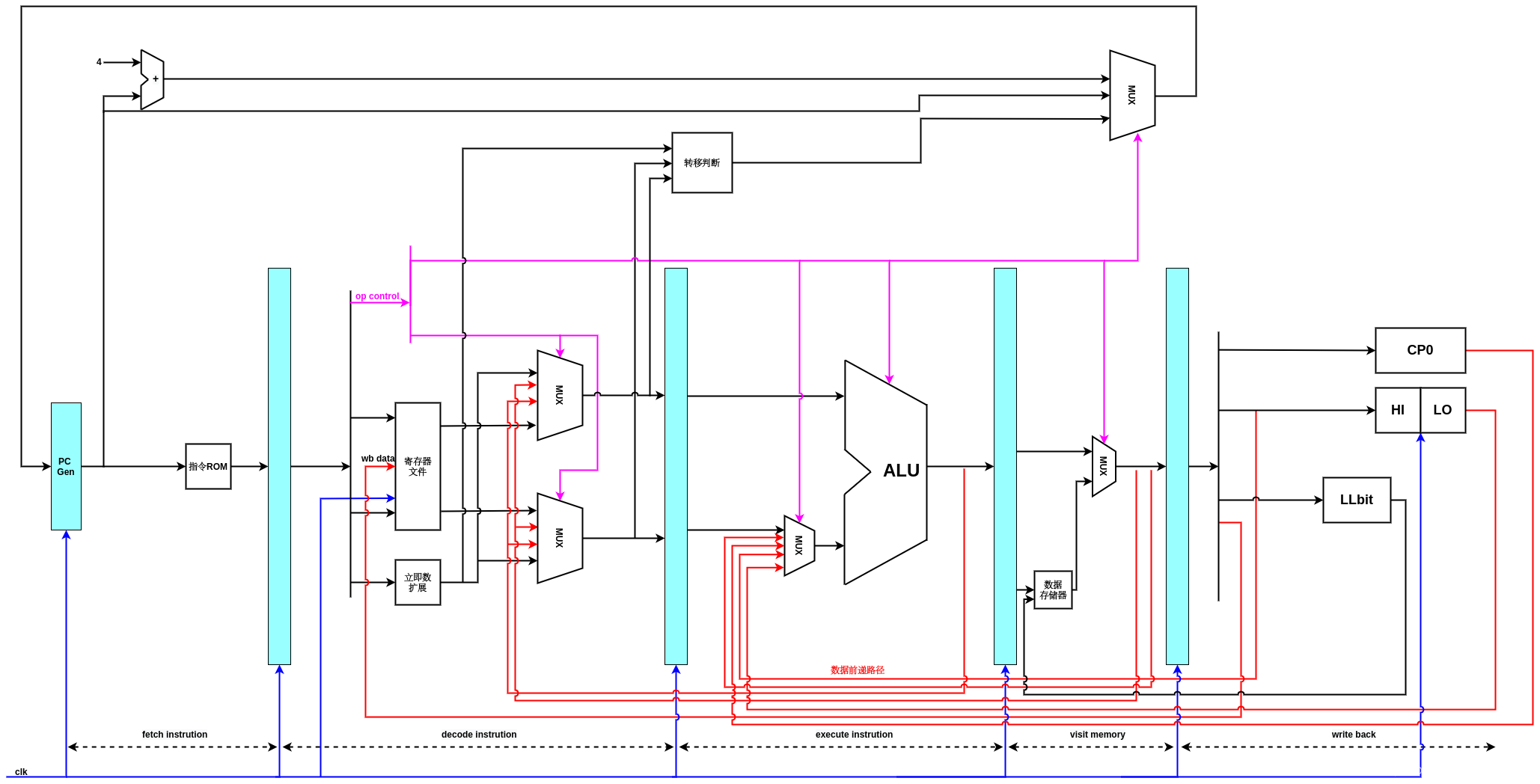
蓝色的部分是时序逻辑,主要是触发器逻辑,用来保存每一级计算的中间结果,它受到时钟信号的驱动,逐级传递.中间是组合逻辑,它的输入来源于上一级的时序逻辑输出部分,经过组合逻辑计算后,将输出送到下一级的时序逻辑输入口.
对于I-type的指令,每一级流水线完成的功能如下:
fetch instruction:取出指令存储器中的指令,PC值递增,准备取下一条指令.
decode:对指令进行译码,根据译码结果,从32个通用寄存器中取出源操作数,有的指令要求两个源操作数都是寄存器的值,比如or指令,有的指令要求其中一个源操作数是指令中立即数的扩展,比如ori指令,所以decode阶段有两个muxer,用于依据指令要求,确定参与运算的操作数,最终确定的两个操作数会送到执行阶段.总结一下,对任意指令而言,译码工作的主要内容是,确定要读取的寄存器情况,要执行的运算,和要写的目的寄存器等三个方面的信息.
execute:依据译码阶段送入的源操作数,操作码,进行运算,这个阶段需要ALU单元的参与,对于ori指令而言,就是在ALU单元中进行逻辑"或"运算,运算结果传递到访存阶段,对于load/store,要进行地址的计算操作.
memory:对于ori指令,在访存阶段没有任何操作,运算结果在这里呆一个时钟周期,会传递到回写阶段,对于访存类指令,这里要进行访问存储器的操作.
writeback:将运算结果保存到目的寄存器.
为了解决指令中出现的RAW相关,将执行阶段的运算结果前递给译码阶段,访存阶段的前递是为了应对装载指令相关的RAW相关.

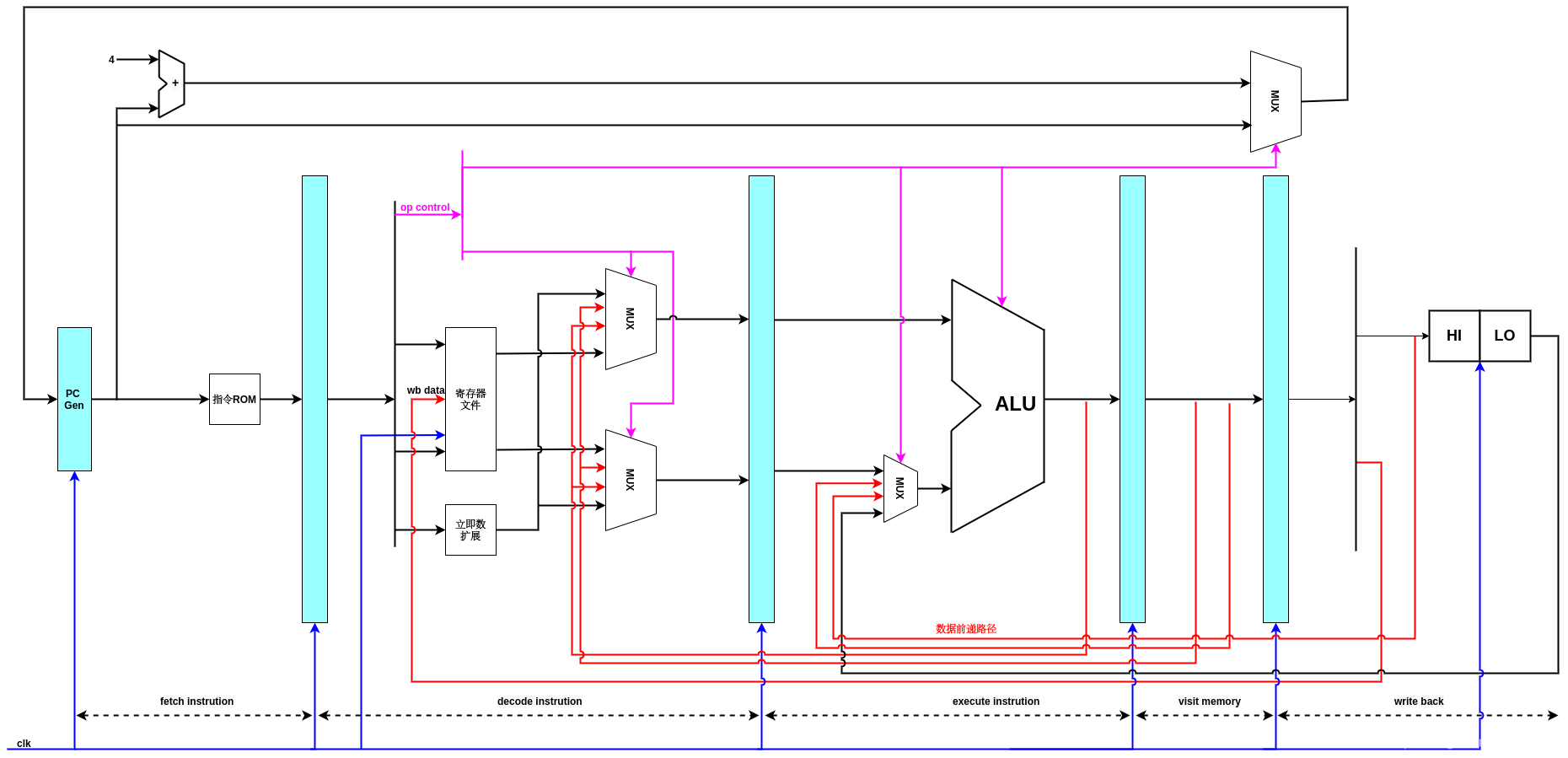
加入了HI,LO寄存器和HI,LO寄存器访存,回写阶段数据前递的数据流图,HI,LO是寄存器,只是它们不能在MIPS指令的5位寄存器字段中编码。这些“已编号”的寄存器通过特殊的指令识别,属于特殊寄存器,用来存放乘除的结果.
在整个流水线中,除了regfile模块和HI.LO模块中由于写入操作引入了时钟信号外,其它阶段都是组合逻辑,不需要始终信号.尤其是ALU单元,进行的纯粹的组合逻辑数学计算.甚至指令ROM都不需要时钟驱动,因为它本身是只写的.在openmips流水线里面,ROM读操作是不需要时钟驱动的.

如同寄存器文件一样,HI,LO寄存器的读是组合逻辑,但是写是时序逻辑,需要一个使能位和时钟触发,所以也需要在回写阶段的写口前进行前递,这里的实现逻辑如下:
Regfile前递:


HI,LO数据前递.
在decode instruction阶段,完整的4字节指令编码便会转换为各种控制信号和数据产生信号,后续流水线阶段不会在出现这条完整的指令编码,但由它产生的各种电信号,时时刻刻影响着整条流水线.所以,你可以看到,在id.v文件里面没有clk输入,但是在regfile.v和hilo.v中需要用时钟信号作为输入.
下一步,增加一个muxer,用来确定PC值,PC值在下一个时钟周期的值可以是PC+4,也可以保持当前值不变,后者对应的就是流水线暂停的情况.
流水线暂停的情况发生在执行阶段需要多个时钟周期才能完成的情况下,比如MACs乘累加和除法操作,尤其是除法,需要较多的时钟周期才能完成,这个时候,需要发出freeze信号(也叫stall信号),冻结执行流水线阶段之前的阶段的推进,等执行阶段完成之后,在继续流水线.
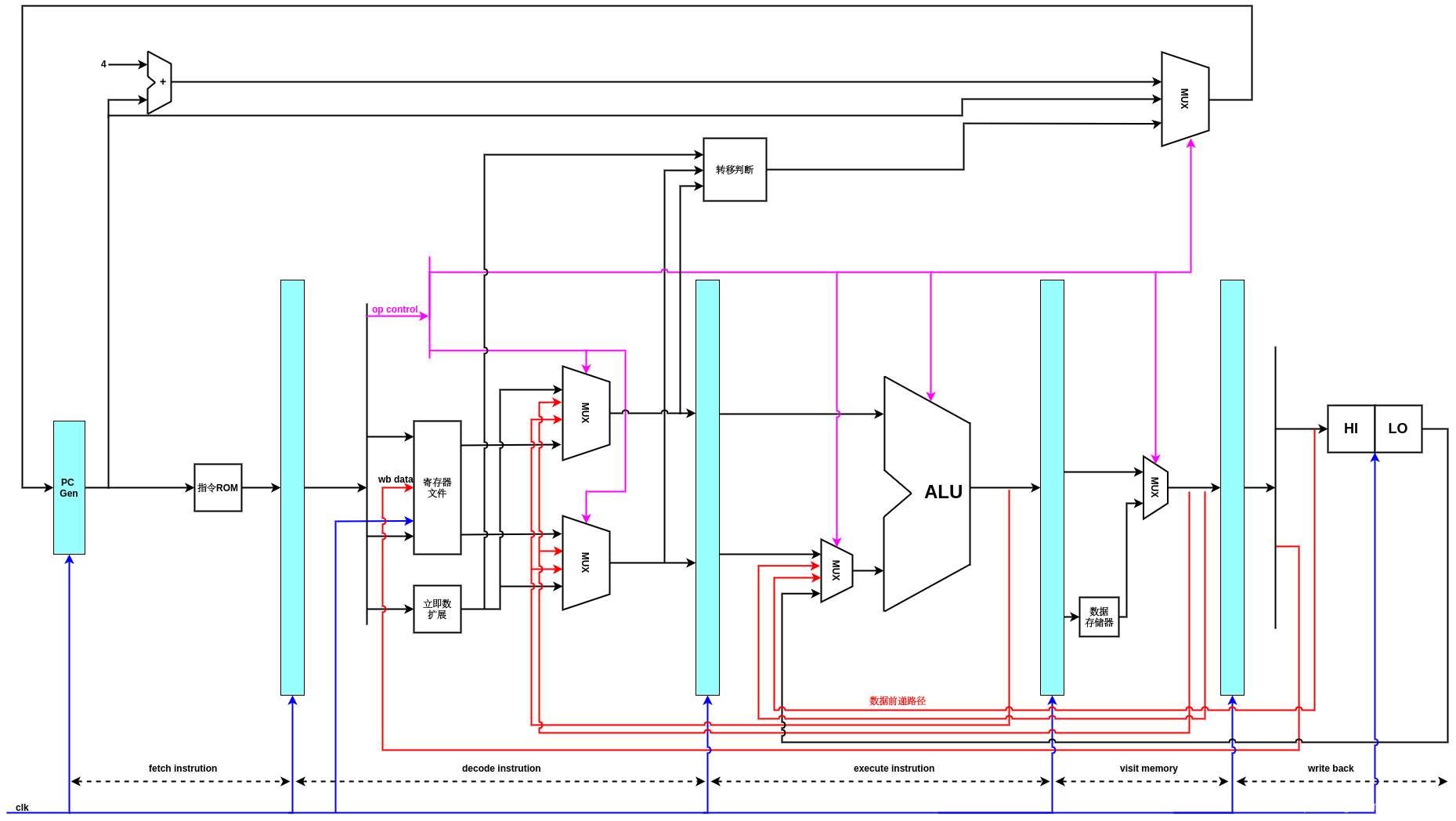
下图是增加了跳转指令逻辑的流水线结构:
增加了跳转逻辑的支持后,PC muxer多了一条输入信号,它代表转移判断的结果,如果是转移指令,且满足转移条件,那么会通过这条路径将转移的目标地址赋给PC.

为了实现数据加载/存储指令,修改数据流图如下所示,主要是在访存阶段增加了对数据存储器SRAM的访问,同时,由于要写入目的寄存器的数据可能是执行阶段的结果,也可能是在访存阶段从数据存储器RAM加载得来的数据,所以在访存阶段增加了一个多路选择器,进行选择.
增加LLBit寄存器的数据流,用来实现链接加载,存储指令(LL,SC)后的流水线:
注意,这里可能还有一些问题,由于sc判断发生在访存阶段,而LLBit的引入之值是基于LLBIt寄存器中的值,这两个中间相隔了两个时钟周期(访存->回写以及LLBIT的写时序),所以如果sc指令紧挨ll指令的情况下,会有一些问题.

增加了协处理CP0的数据流图,在回写阶段增加了CP0模块,并且CP0模块的输出数据传递到执行阶段,用于确定最后参数运算的操作数,比如,mfc0指令在执行极端就会选择从CP0传递过来的数据,作为运算结果,写入目的寄存器.
添加异常处理后的数据流图如下图所示:在访存阶段增加了异常判断模块,主要作用是依据从译码,执行阶段传递过来的信息,以及CP0中寄存器的值,判断是否要处理异常,如果要处理异常,那么按照异常类型给出新的指令地址送入PC.
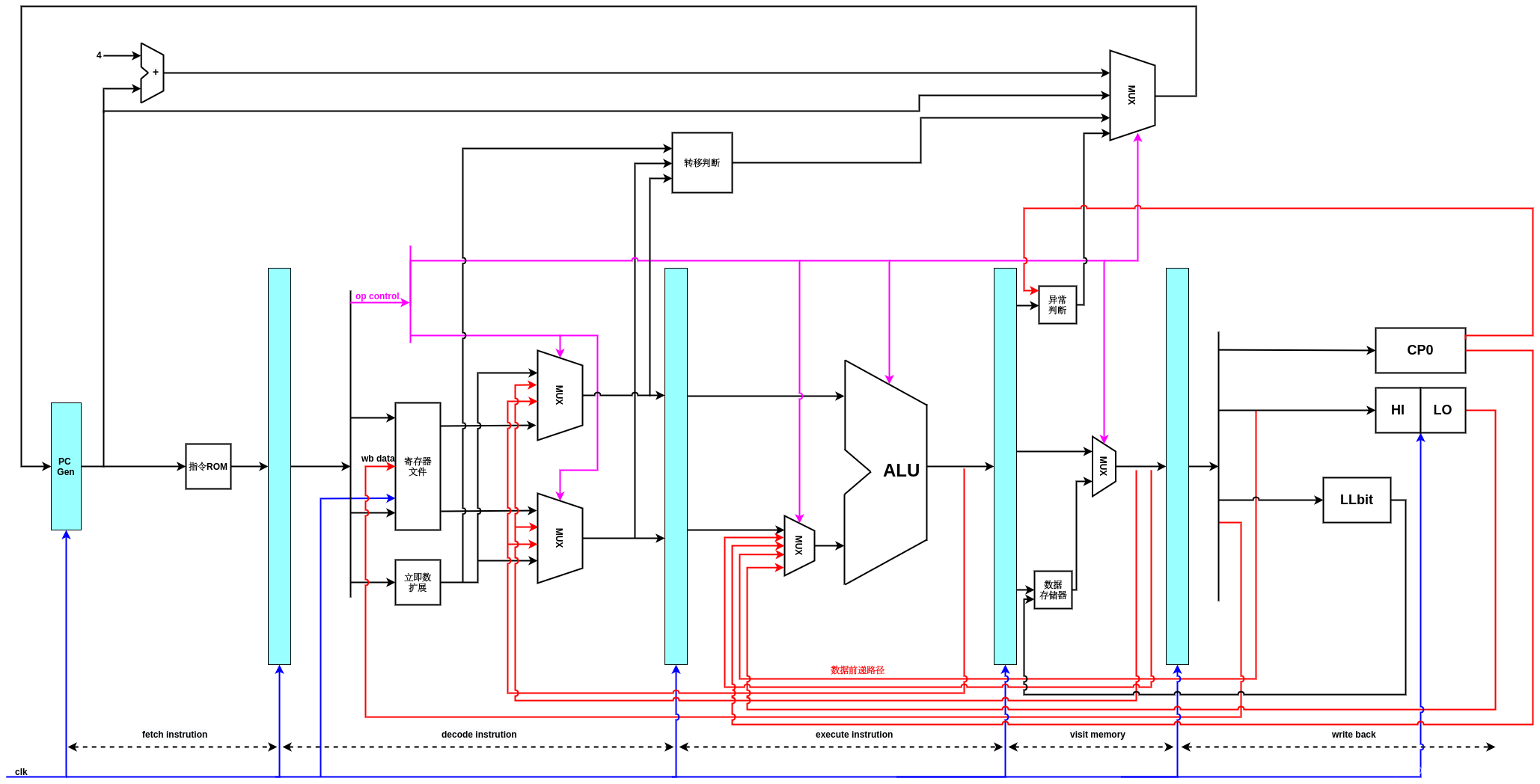
为了实现MIPS精确异常,必须要求异常发生的顺序与指令顺序相同,在非流水线的处理器上,这一点是显然的,但是对于拥有流水线的处理器,就会有些复杂,在流水线处理器上,指令不同,异常会在流水线的不同阶段发生,带来潜在问题,比如,syscall指令在指令译码阶段便会产生一场信号,而装载指令在访存阶段才会发生不对齐的异常,并且代码顺序是syscall位于lw指令后面第一条指令,如果按照产生异常信号的时间来处理异常,便会发生后面的指令(syscall)先于前面指令(lw)进行异常处理的情况,这是错误的.为了避免上述情况,先发生的异常并不立即处理,异常事件只是被标记,并继续运行流水线,在大多数处理器中,会设计一个特殊的流水线阶段,专门用于处理一场,如果能够保证任何阶段,流水线中的异常在这个阶段之前都可以被发现,那么就能够保证,指令顺序和异常顺序保持一直的原则,最终保证,指令按照执行的顺序处理一场,而不是按异常发生的顺序处理异常.