神经网络的复杂度用:网络层数和神经网络参数的个数来表示;
空间复杂度:
-
层数(仅计算具有计算能力的层) = 隐藏层的层数 +
1个输出层; -
总参数 = 总
w+ 总b;
时间复杂度: -
乘加运算次数
eg.
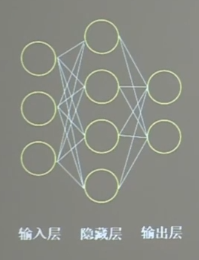
总参数 =3x4+4x1 + 4x2+2x1 = 26
乘加运算次数 =3x4 + 4x2 = 20 -
指数衰减学习率
可先用较大的学习率,快速得到较优解,然后逐步减小学习率,使模型在训练后期稳定。
指 数 衰 减 学 习 率 = 初 始 学 习 率 ∗ 学 习 率 衰 减 率 ( 当 前 轮 数 / 多 少 轮 衰 减 一 次 ) 指数衰减学习率 = 初始学习率 * 学习率衰减率^{(当前轮数/多少轮衰减一次)} 指数衰减学习率=初始学习率∗学习率衰减率(当前轮数/多少轮衰减一次) -
神经网络优化目标是
loss最小化,一共有三种方式:
① mse;② 自定义;③ cross entropy;
① mse,即均方误差,可以用tf.reduce_mean(tf.square(y_-y))来表示;
import tensorflow as tf
x = tf.random.normal([20, 2], mean=2, stddev=1, dtype=tf.float32)
y = [item1 + 2 * item2 for item1, item2 in x]
w = tf.Variable(tf.random.normal([2, 1], mean=0, stddev=1))
epoch = 5000
lr = 0.002
for epoch in range(epoch):
with tf.GradientTape() as tape:
y_hat = tf.matmul(x, w)
loss = tf.reduce_mean(tf.square(y_hat - y))
w_grad = tape.gradient(loss, w)
w.assign_sub(lr * w_grad)
print(w.numpy().T)
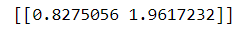
② 自定义;
还是上面的,我们定义损失函数为一个分段函数。当预测值大于真实值,我们认为对我们模型不利,即:
f ( y ^ , y ) = { 3 ( y ^ − y ) y ^ ⩾ y y − y ^ y ^ ⩽ y f(\hat y, y) = \begin{cases} 3(\hat y - y)& \hat y \geqslant y\\ y - \hat y& \hat y \leqslant y \end{cases} f(y^,y)={
3(y^−y)y−y^y^⩾yy^⩽y
import tensorflow as tf
x = tf.random.normal([20, 2], mean=2, stddev=1, dtype=tf.float32)
y = [item1 + 2 * item2 for item1, item2 in x]
w = tf.Variable(tf.random.normal([2, 1], mean=0, stddev=1))
epoch = 5000
lr = 0.002
for epoch in range(epoch):
with tf.GradientTape() as tape:
y_hat = tf.matmul(x, w)
loss = tf.reduce_mean(tf.where(tf.greater(y_hat, y), 3*(y_hat - y), y-y_hat))
w_grad = tape.gradient(loss, w)
w.assign_sub(lr * w_grad)
print(w.numpy().T) # [[0.73728406 0.83368826]]
由于预测大了对模型损失函数影响较大,故而应该尽量往小了预测,也就是这里的结果均偏小。
我们做一个简单的修改,即:
loss = tf.reduce_mean(tf.where(tf.greater(y_hat, y), (y_hat - y), 3*(y-y_hat)))
此时,预测值小于真实值的时候,我们认为对模型不利,也就是要尽量往大了预测,此时的训练结果:[[1.6747012 1.9530903]]
③ 交叉熵损失函数
tf.losses.categorical_crossentropy(y, y_)
交叉熵损失函数表示两个概率分布之间的距离。
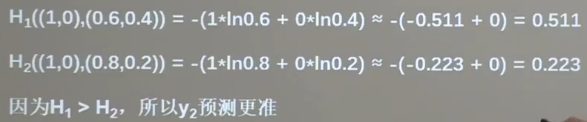
比如,给定已知类别(1, 0),而预测的
y_1 = (0.6, 0.4);
y_2 = (0.8, 0.2);
我们需要衡量,哪个答案更加接近标准答案,就可以使用交叉熵来进行计算衡量。