摘要
学习是一种内在的连续现象。当人类学习一项新任务时,训练和推理之间没有明显的区别。当我们学习一项任务时,我们会在执行任务时不断学习。在不同的学习阶段,我们学习什么和如何学习是不同的。学习如何学习和适应是一个关键属性,它使我们能够毫不费力地推广到新的环境。这与机器学习中的传统设置形成对比,在传统设置中,训练好的模型在推理过程中被冻结。在本文中,我们研究了在视觉导航的环境中,在训练和测试时间学习的问题。导航的一个基本挑战是对看不见的场景进行概括。本文提出了一种自适应视觉导航方法,该方法在没有任何外部监督的情况下学会适应新环境。我们的解决方案是一种元强化学习方法,在这种方法中,代理学习自我监督的交互损失,从而鼓励有效的导航。我们的实验在AI2-托尔框架下进行,显示了在新场景中视觉导航的成功率和SPL方面的重大改进。
介绍
学习是一种内在的连续现象。我们进一步学习我们已经学习过的任务,并可以通过在这些环境中互动来学习适应新环境。当我们学习和执行任务时,训练和测试阶段之间没有硬性的界限:我们边做边学。这与许多现代深度学习技术形成鲜明对比,在这些技术中,网络在推理过程中被冻结。
在不同的学习阶段,我们学习什么和如何学习是不同的。为了学习一项新的任务,我们经常依赖外部的监督。学习完一项任务后,我们会在适应新环境的过程中进一步学习。这种适应不一定需要明确的监督;我们经常通过与环境的互动来做到这一点。

在本文中,我们研究了在视觉导航的背景下,在训练和测试时间学习学习和适应的问题;对于任何视觉智能代理来说,最重要的技能之一。视觉导航的目标是向环境中的某些对象或区域移动。导航中的一个关键挑战是推广到训练中没有观察到的场景,因为场景的结构和对象的外观是不熟悉的。在本文中,我们提出了一个自适应视觉导航模型,该模型在推理过程中学习适应,而无需使用交互损失 的任何显式监督(图1)。
从形式上来说,我们的解决方案是视觉导航的元强化学习方法,其中代理通过自我监督的交互损失来学习适应。我们的方法受到基于梯度的元学习算法的启发,该算法使用少量数据快速学习[13]。然而,在我们的方法中,我们使用少量的自我监督交互来快速学习。在视觉导航中,适应是可能的,不需要任何奖励功能或正面例子。随着代理的训练,它学会了自我监督的损失,鼓励有效的导航。在训练期间,我们鼓励由自监督损失引起的梯度与我们从监督导航损失中获得的梯度相似。因此,当没有明确的监督时,代理能够在推理过程中进行调整。
总之,在训练和测试期间,代理在执行导航的同时修改其网络。这种方法不同于传统的强化学习,在传统的强化学习中,网络在训练后被冻结,与监督元学习形成对比,因为我们在推理过程中学习适应新的环境,而没有获得奖励。
我们使用AI2-托尔[23]框架进行实验。该代理旨在仅使用视觉观察来导航到给定对象类别(例如,微波)的实例。我们表明,在成功率(40.8对33.0)和SPL (16.2对14.7)方面,模拟虚拟神经网络优于非自适应基线。此外,我们证明了学习自我监督的损失比手工制作的自我监督的损失有所改善。此外,我们表明,我们的方法优于记忆增强的非自适应基线。
相关工作
导航深度模型
传统的导航方法通常在给定的环境地图上进行规划,或者随着勘探的进行建立地图。最近,基于学习的导航方法变得流行,因为它们隐含地端到端地执行定位、映射、探索和语义识别。
朱等人[50]针对目标驱动导航给出了一个目标的图片。[15]介绍了一种联合绘图器和规划器。[27]使用闭环等辅助任务来加速导航的RL训练。当我们动态地适应一个新的场景时,我们的方法是不同的。[37]建议将拓扑地图用于导航任务。他们长期探索测试环境来填充内存。在我们的工作中,我们学会了在没有探索阶段的情况下导航。[20]提出了一种用于导航的自监督深度RL模型。但是,没有考虑语义信息。[31]学习基于对象检测器和语义分割模块的导航策略。我们不依赖于严格监督的检测器,而是从有限的例子中学习。[46,44]整合语义知识,以更好地概括未知场景。这两种方法都动态更新它们手动定义的知识图。然而,我们的模型知道哪些参数应该在导航期间更新,以及它们应该如何更新。基于学习的导航已经在其他应用的背景下进行了探索,例如自动驾驶(例如[7])、基于地图的城市导航(例如[5])和游戏(例如[43])。各种著作[3,6,17,47,29]探索了使用语言指令的导航。我们的目标是不同的,因为我们专注于使用元学习来更有效地导航新场景,只使用目标的类标签。
元学习
元学习,或学习学习,一直是机器学习研究中持续感兴趣的话题。最近,各种元学习技术推动了低射问题在不同领域的发展。
芬恩等人[13]介绍了模型不可知元学习(MAML),它使用SGD更新来快速适应新任务。这种基于梯度的元学习方法也可以被解释为学习良好的参数初始化,使得网络仅在几次梯度更新后表现良好。[25]和[48]扩充了MAML算法,使得它在一个域中使用监督来适应另一个域。我们的工作不同,因为我们不使用监督或标签的例子来适应。
徐等人[45]通过鼓励探索演员政策规定之外的状态空间,使用元学习来显著加快训练。此外,[14]使用元学习用结构化噪声增强代理的策略。在推断时间,由于这些事件的可变性,代理能够更好地适应一些事件。相反,我们的工作强调在执行单一视觉导航任务时的自我监督适应。这些作品都没有考虑这个领域。
Clavera等人[8]考虑了使用元学习来适应意外扰动的学习问题。我们的方法是相似的,因为我们也考虑学习适应的问题。然而,我们考虑视觉导航的问题,并通过自我监督的损失来适应。
[18]和[48]都学习一个目标函数。然而,[18]使用进化策略而不是元学习。我们学习亏损的方法是受[48]的启发并与之相似。然而,我们在没有明确监督的情况下在同一个域中进行调整,而他们使用视频演示跨域调整。
自监督
文献[1,19,11,42,49,36,34,32]探讨了不同类型的自我监督。一些工作旨在最大化未来状态表示的预测误差[33,39]。在这项工作中,我们学习一个自我监督的目标,鼓励有效的导航。
自适应导航
在这一节中,我们首先正式介绍任务和我们的基本模型,无需修改。然后,我们解释如何在这种情况下结合适应性并进行培训和测试。

我们的网络优化了两个目标函数,1)自监督交互损失Lφin和2)导航损失Lnav。每次t时网络的输入是来自当前位置的以自我为中心的图像和目标对象类的单词嵌入。网络输出一个策略ψθ(ST)。在训练期间,交互和导航梯度通过网络反向传播,并且在每集结束时使用导航梯度更新自我监督损失的参数。在测试时,交互损失的参数保持固定,而网络的其余部分使用交互梯度来更新。请注意,图中的绿色代表中间输出和最终输出。
任务定义
给定一个目标对象类,例如微波,我们的目标是仅使用视觉观察从这个类导航到一个对象的实例。
形式上,我们考虑一组场景S = {S1,…,Sn}和目标对象类O = {o1,…,om}。任务τ ∈ T由场景S、目标对象类o ∈ O和初始位置p组成。因此,我们用元组τ = (S,O,p)表示每个任务τ。我们考虑训练任务Ttrainand和测试任务Ttest的不相交场景集。我们将导航任务的试验称为一集。
代理需要仅使用以自我为中心的RGB图像和目标对象类进行导航(目标对象类以手套嵌入方式给出[35])。每次t,代理从动作集合A中采取动作A,直到代理发出终止动作。如果在一定数量的步骤内,当来自给定目标类的对象足够接近和可见时,代理发出终止动作,我们认为一集是成功的。如果在任何其他时间发出终止动作,则该集结束,代理失败。
学习
在我们讨论我们的自适应方法之前,我们首先概述我们的基础模型,并讨论传统意义上的导航深度强化学习。
我们让以自我为中心的RGB图像st表示代理在时间t的状态。给定目标对象类,网络(由θ参数化)返回动作的分布,我们用ψθ(ST)和标量vθ(st)表示。分布ψθ(ST)被称为代理的策略,而vθ(st)是状态的值。最后,我们让π(a) θ(st)去记代理选择动作a的概率。
我们使用传统的监督演员-评论家导航损失,如[50,27],我们称之为Lnav。通过最小化Lnav,我们最大化了一个奖励函数,该函数惩罚代理人迈出一步,同时激励代理人到达目标。在整个事件中,损失是代理人的政策、价值观、行动和奖励的函数。
网络架构如图2所示。我们使用在图像网[10]上预处理的图像网18 [16]来提取给定图像的特征图。然后,我们获得由图像和目标信息组成的联合特征图,并执行逐点卷积。然后输出被平坦化,并作为输入提供给长短期记忆网络(LSTM)。在这项工作的剩余部分,我们交替地提到LSTM隐藏状态和代理的内部状态表示。在应用额外的线性层之后,我们获得策略和值。在图2中,我们没有显示我们始终使用的ReLU激活,也没有引用值vθ(st)。
学会学习
在视觉导航中,代理有充分的机会通过与环境交互来学习和适应。例如,代理可以学习如何处理最初无法绕过的障碍。因此,我们提出了一种方法,在这种方法中,代理学习如何从交互中适应。我们的方法的基础在于最近的工作,这些工作提出了基于梯度的学习算法(元学习)。
基于梯度的元学习背景
我们依赖于MAML算法[13]详述的元学习方法。MAML算法优化了对新任务的快速适应。如果训练和测试任务的分布足够相似,那么用MAML训练的网络应该很快适应新的测试任务。
MAML假设,在训练期间,我们可以访问大量的任务t train,其中每个任务τ∈t train都有一个小的元训练数据集Dtrτ和元验证集Dval τ。比如在k-shot图像分类问题中,τ是一组图像类,Dtrτ包含每个类的k个例子。目标是为Dval τ中的每个图像正确分配一个类别标签。测试任务τ∈Ttest然后由看不见的类组成。
MAML的训练目标由下式给出
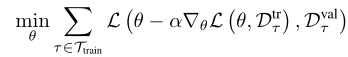
其中损耗L被写成数据集和网络参数θ的函数。此外,α是步长超参数,∇表示微分算子(梯度)。想法是学习参数θ,以便它们为快速适应测试任务提供良好的初始化。在形式上,等式(1)在Dtr τ上以梯度步长适应任务后,优化了Dval τ上的性能。我们使用自适应参数θα∇θl(θ,dtrτ,而不是使用网络参数θ来推断Dval τ。实际上,可以使用多个SGD更新来计算调整后的参数。
导航训练目标
我们的目标是让代理在与环境交互时不断学习。如同在MAML一样,我们使用SGD更新进行这种调整。这些SGD更新在代理与场景交互时修改代理的策略网络,使代理能够适应场景。我们建议这些更新应该发生在Lint上,我们称之为交互丢失。最小化Lint应该有助于代理完成其导航任务,并且它可以是学习的或手工制作的。例如,手工制作的变体可能会惩罚两次访问同一地点的代理。为了使代理能够访问Lintduring推理,我们使用了一个自我监督的损失。然后,我们的目标是学习一个好的初始化θ,这样代理将学习在使用Lint进行几次梯度更新后有效地在环境中导航。
为了清楚起见,我们首先在一个简化的环境中正式展示我们的方法,在这个环境中,我们允许一个关于Lint的SGD更新。对于导航任务τ,我们让力τ表示代理轨迹的前k步的动作、观察和内部状态表示(在第3.2节中定义)。另外,让Dnav τ表示轨迹剩余部分的相同信息。我们的培训目标
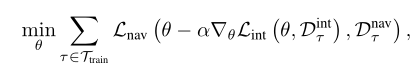
其反映了等式(1)中的MAML物镜。然而,我们已经用交互阶段代替了来自MAML的小训练集Dtrτ。我们对目标的直觉是这样的:首先,我们与环境互动,然后适应环境。更具体地说,摄像机使用参数θ与场景交互。在k步之后,使用关于自监督损失的SGD更新来获得适应的parametersθ−α∇θLint?θ,Dint τ?。
在领域自适应元学习中,两个独立的损失用于从一个领域到另一个领域的自适应[25,48]。[48]采用了类似于等式(2)的目标,用于观察人类的一次性模仿。我们的方法不同之处在于,我们正在通过自我监督的互动学习如何适应同一个领域。
如[25]中所述,一阶泰勒展开为我们的训练目标提供了直觉。等式(2)近似为
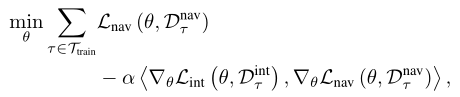
其中h,I表示内积。因此,我们正在学习最小化导航损失,同时最大化我们从自监督交互损失和监督导航损失中获得的梯度之间的相似性。如果我们从两次损失中获得的梯度是相似的,那么当我们不能访问Lnav时,我们可以在推断过程中继续“训练”。然而,可能很难选择允许类似梯度的林分。这直接激发了学习自我监督的交互损失。
学会学习如何学习
我们建议学习一个自我监督的交互目标,这个目标明确地适合我们的任务。我们的目标是让代理在当前环境中通过最小化这种自我监督的损失来改进导航。
在培训过程中,我们既学习这个目标,也学习如何使用这个目标来学习。因此,我们正在“学习如何学习”。作为这种损失的输入,我们使用代理先前的内部状态表示与代理的策略相结合。
形式上,我们考虑Lintis是一个用φ参数化的神经网络的情况,我们把它表示为Lφ int。我们的训练目标就变成了
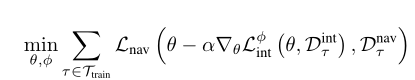
我们在推理过程中冻结参数φ。学习失败没有明确的目标。相反,我们只是鼓励尽量减少这种损失,让代理有效地导航。如果两种损失的梯度相似,就可能发生这种情况。从这个意义上说,我们正在训练自我监督的损失来模仿监督的损失。
正如在[48]中,我们使用一维时间卷积来构建我们所学的损失。我们使用两层,第一层有10×1个滤镜,第二层有1×1个滤镜。作为输入,我们连接LSTM过去的k个隐藏状态和以前的k个策略。为了获得标量目标,我们取输出的2范数。虽然我们忽略了‘2范数,但我们在图2中说明了我们的交互损失。
手工制作的交互目标
我们还实验了两种不同的简单手工交互损失,它们可以作为学习损失的替代。第一个是多样性损失Ldiv,它鼓励代理人采取各种行动。如果代理确实多次达到相同的状态,它绝对不应该重复之前采取的操作。因此,
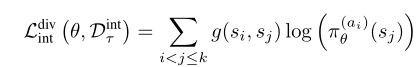
其中STI是代理在时间t的状态,atis是代理在时间t采取的动作,g计算两个状态之间的相似性。为简单起见,如果siand和sj之间的像素差低于某个阈值,我们假设g(si,SJ)为1,否则为0。
此外,我们考虑一个预测损失Lpred int,其中代理旨在预测每个动作的成功。这个想法是为了避免采取网络预测会失败的行动。我们说,如果我们在两个连续的状态中检测到足够的相似性,代理的操作就失败了。当代理撞到物体或墙壁时,可能会出现这种情况。除了对动作产生策略πθ之外,代理还预测每个动作的成功。对于状态stwe,将动作a成功的预测概率表示为q(a) θ(st)。我们使用\θ(ST)=ψθ(ST)∩qθ(ST)来代替从ψθ(ST)采样动作,其中∫表示元素式乘法。
对于Lpred int,我们在我们的成功预测q(a) θ和观察到的成功之间使用标准的二元交叉熵损失。使用等式(5)中相同的g,我们把我们的损失写成
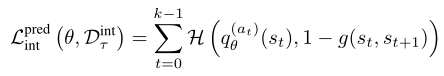
其中,H(,)表示二元交叉熵。
我们承认,在非合成环境中,可能很难产生可靠的函数g。因此,我们只在手工制作的损失变量中使用g。