目录
一、实验目的
1、掌握非递归下降的预测分析;
2、了解如何使用Yacc、bision等工具完成语法分析
二、实验任务
1、针对书上第三章中的表达式文法,采用LL(1)、LR(1)进行分析(必做),不需要做词法分析,输入为记号流。可以手工构造预测分析表,但鼓励自动生成。
2、使用Yacc或bision等工具,实现对表达式文法的语法分析析(附加)。
三、实验原理
1 LL(1)文法
任何两个产生式A ®a | b 都满足下列条件:
(1)FIRST(a ) Ç FIRST(b ) = Æ;
(2)若b Þ* e ,那么FIRST(a) Ç FOLLOW(A) = Æ。
把满足这两个条件的文法称为LL(1)文法。先定义两个和文法有关的函数FIRST(a ) = { a | a Þ* a…, a Î VT},特别是,a Þ* e时,规定e Î FIRST(a ) ;FOLLOW(A) = { a | S Þ* …Aa…,aÎVT},如果A是某个句型的最右符号,那么$属于FOLLOW(A)。
- 查找非终结符的First集
Step 1:按产生式顺序来,从开始符找起;
Step 2:如果右部的串首为终结符,则直接将该终结符填入左部非终结符的First集中;
Step 3:如果右部的串首为非终结符,则左部非终结符的First集等价于串首非终结符的First集。因而,需要利用Step 2和Step 3继续寻找串首非终结符的First集。
- 查找非终结符的Follow集
Step 1:按产生式顺序来,从开始符找起(开始符的Follow集必定包含$);
Step 2:从所有产生式右部寻找目标非终结符,若其后紧跟终结符,则将终结符填入目标非终结符的Follow集。特别地,若其后紧跟$,则目标非终结符的Follow集等价于产生式左部非终结符的Follow集。
Step 3:从所有产生式右部寻找目标非终结符,若其后紧跟非终结符,则将该非终结符的First集元素填入目标非终结符的Follow集。特别地,若该非终结符的First集元素中包含e,则需针对e情况时做特殊处理,即目标非终结符的Follow集等价于产生式左部非终结符的Follow集。
LL(1)文法有一些明显的性质:没有公共左因子;不是二义的;不含左递归。
- 构造预测分析表
(1)对文法的每个产生式A ® a ,执行(2)和(3);
(2)对FIRST(a)的每个终结符a,把A ® a 加入M[A, a];
(3)如果e在FIRST(a)中,对FOLLOW(A)的每个终结符b(包括$),把A ® a加入M[A, b];
(4)M中其它没有定义的条目都是error。
2 LR文法
LR分析器的模型如图所示,它包括输入、输出、栈、驱动程序和含动作和转移两部分的分析表。驱动程序对所有的LR分析方法都一样,不同的分析方法构造的分析表不同。分析程序每次从输入缓冲区读一个符号,它使用栈存储形式为s0X1s1X2s2⋯Xmsm 的串,sm 在栈顶。Xi 是文法符号,si是叫做状态的符号,状态符号概括了栈中它下面部分所含的信息。栈顶的状态符号和当前的输入符号用来检索分析表,以决定移进—归约分析的动作。
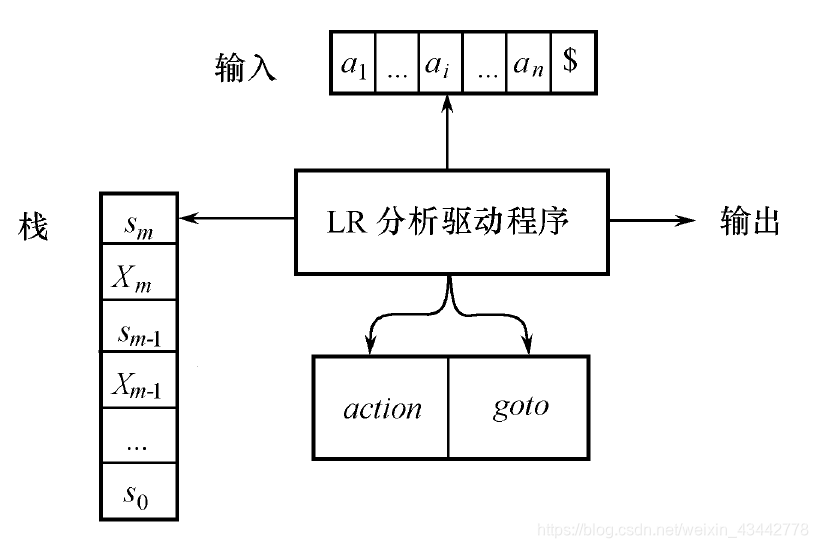
图 3.1:LR分析器的模型
2.1 LR(0)文法
文法G的LR(0)项目(简称项目)是在右部的某个地方加点的产生式。如产生式A→XYZ对应有四个项目:
A→·XYZ
A→X·YZ
A→XY·Z
A→XYZ·
产生式A→ε只有一个项目A→·和它对应。直观地讲,项目表示在分析过程的某一点,已经看见了产生式的多大部分(点的左边部分)和下面希望看见的部分。
让状态含有更多的信息,使之能够剔除无效归约是完全可能的。定义项目,使之包含一个终结符作为第二个成分,这样就把更多的信息并入了状态。项目的一般形式也就成了[A→α·β,a],其中A→αβ是产生式,a是终结符号或$,这种项目叫做LR(1)项目,1是第二个成分的长度,这个成分叫做项目的搜索符。搜索符对β非空的项目[A→α·β,a]是不起作用的,但对形式为[A→α·,a]的项目,它表示只有在下一个输入符号是a时,才能要求按A→α归约。这样,分析器只有在输入符号是a时才按A→α归约,其中[A→α·,a]在栈顶状态的LR(1)项目集中。这样的a的集合是FOLLOW(A)的子集,完全可能是真子集。我们说LR(1)项目[A→α·β,a]对活前缀γ是有效的,如果存在着推导S=>*rmδAw=>rmδαβw,其中:
(1) γ=δα;
(2) a是w的第一个符号,或者w 是ε且a是$。
在LR(1)文法中,栈中的文法符号总是形成一个活前缀,分析表的转移函数本质上是识别活前缀的DFA,栈顶的状态符号包含了确定句柄所需要的一切信息,是已知的最一般的无回溯的移进归约方法,能及时发现语法错误,但是,手工构造分析表的工作量太大。
LR分析法的规约过程是规范推倒的逆过程,所以LR分析过程是一种规范规约的逆过程,L表示从左到右扫描输入串, R表示最左规约(即最右推导的逆过程),括号中的1表示向右查看输入符号数为1。LR(1)项目可以看成两个部分组成,一部分和LR(0)项目相同,这部分成为心,另一部分为向前搜索符集合。所以只有当面临的输入符属于向前搜索符的集合,才做规约动作,其他情况均出错。LR(1)方法恰好解决LR(0)(1)方法在某些情况下存在的无效规约问题。
四、实验过程
1 LL(1)文法
LL(1)文法的分析模型如图4.1所示,课本上要分析的文法(3.8)如下:
E→TE′
E′→+TE′|ε
T→FT′
T′→*FT′|ε
F→(E)|id

图4.1:LL(1)文法的分析模型
(1)构造LL(1)预测分析表,按照实验原理中描述的流程,最终分析表如下表所示。
表4.1:LL(1)预测分析表

在实际编程中,用字典进行存储,其中P代表E′,p代表T′,e代表e,如下所示:
| #Epie=P;Tpie=p;yimuxitong=e dicM={ "E":{"i":"TP","C":"TP"}, "P":{"+":"+TP",")":"e","$":"e"}, "T":{"i":"Fp","(":"Fp"}, "p":{"+":"e","*":"*Fp",")":"e","$":"e"}, "F":{"i":"i","(":"(E)"} } |
(2)按照LL(1)文法分析的伪代码进行编程,具体代码详见附录1.

图4.2:LL(1)文法的伪代码
2 LR文法
LR(1)文法的分析模型如图3.1所示.
利用LR(0)课本上要分析的文法(3.11)如下:
E->E+T
E->T
T->T*F
T->F
F->(E)
F->i
(1)构造LR(0)预测分析表,按照实验原理中描述的流程,最终分析表如下表所示。
表4.2:LR(0)预测分析表

在实际编程中,用字典进行存储,如下所示:
| action={0: {'i': 's5', '(': 's4'}, 1: {'+': 's6', '$': 'acc'}, 2: {'+': 'r2', '*': 's7', ')': 'r2', '$': 'r2'}, 3: {'+': 'r4', '*': 'r4', ')': 'r4', '$': 'r4'}, 4: {'i': 's5', '(': 's4'}, 5: {'+': 'r6', '*': 'r6', ')': 'r6', '$': 'r6'}, 6: {'i': 's5', '(': 's4'}, 7: {'i': 's5', '(': 's4'}, 8: {'+': 's6', ')': 's11'}, 9: {'+': 'r1', '*': 's7', ')': 'r1', '$': 'r1'}, 10: {'+': 'r3', '*': 'r3', ')': 'r3', '$': 'r3'}, 11: {'+': 'r5', '*': 'r5', ')': 'r5', '$': 'r5'}} goto={0: {'E': 1, 'T': 2, 'F': 3}, 4: {'E': 8, 'T': 2, 'F': 3}, 6: {'T': 9, 'F': 3}, 7: {'F': 10}} |
(2)按照LR(0)文法分析的伪代码进行编程,具体代码详见附录2.

图4.3:LR(0)文法的伪代码
课本上要分析的文法(3.13)如下:
对下列文法,用LR(1)分析法对任意输入的符号串进行分析:
E->S
S->BB
B->bB|a
程序的流程图如图所示,其中输入以#结束的符号串(包括a、b、#),如:abb#。此文法采用C++进行编程,对应文法分析表Action的存储结构为字符型二维数组,Goto的存储结构为整数型二维数组,如下所示:

图4.4: LR(1)分析流程图

图4.5:LR(1)分析表的存储结构示意图
五、实验结果
1 LL(1)文法
程序识别出文法的非终结符VN集合为:['E', 'P', 'T', 'p', 'F'];终结符VT集合为['(', 'C', '+', ')', '*', 'i', '$', 'e'],其中P代表E′,p代表T′,e代表e。输入符号串i*i+i,分析结果如下图所示,经过17步分析,最终判断该句子属于该文法,分析结束。当然,如果输入i*+i,不符合该文法的句子,结果如图5.2所示,最终判断该句子不属于该文法。说明程序编写正确。

图5.1: 句子“i*i+i”的LL(1)分析过程

图5.2: 句子“i*+i”的LL(1)分析过程
2 LR(0)文法
输入句子“i*i+i$”,采用LR(0)文法进行分析的结果如下,经过14步分析,最终判断该句子属于该文法,分析结束;当然,如果输入i*+i,不符合该文法的句子,结果如图5.4所示,最终判断该句子不属于该文法。程序编写正确。

图5.3: 句子“i*i+i”的LR(0)分析过程

图5.4: 句子“i*+i”的LR(0)分析过程
3 LR(1)文法
输入句子“abb#”,采用LR(1)文法进行分析的结果如下,经过8步分析,最终判断该句子属于该文法,分析结束;输入句子“abbab#”,采用LR(1)文法进行分析的结果如下,经过6步分析,最终判断该句子不属于该文法,分析结束。
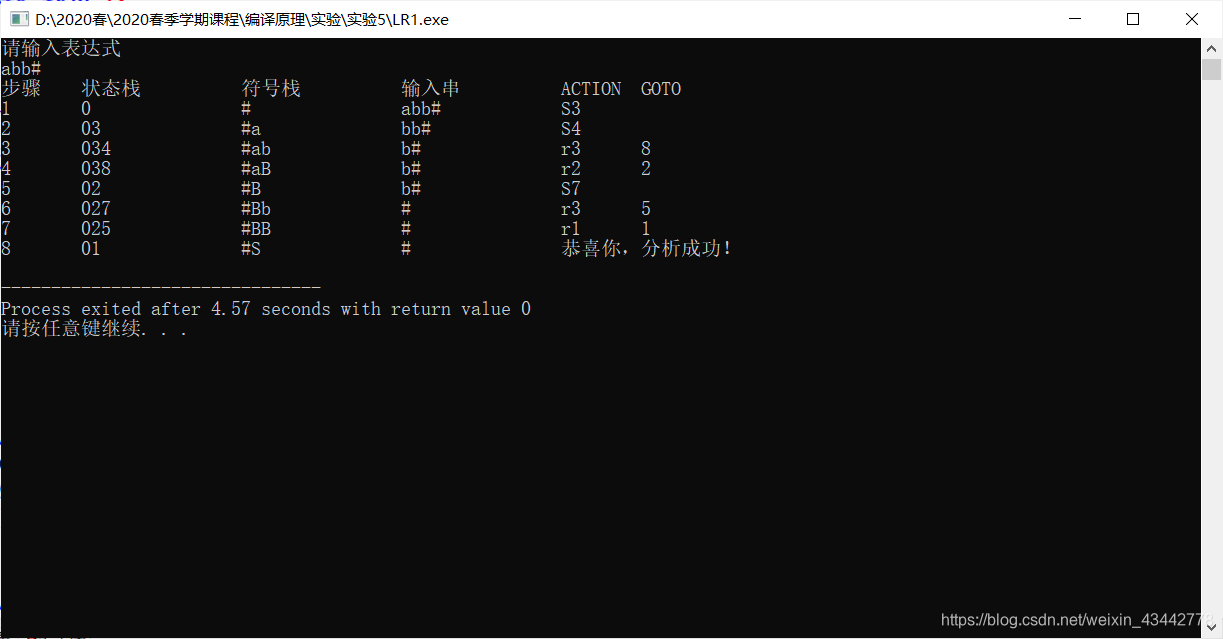

图5.5:LR(1)文法的分析过程
参考资料
- 自上而下语法分析器python:https://blog.csdn.net/zhengjue3343/article/details/80042782
- 基于LR(1)的语法检查器(一):https://blog.csdn.net/Maxners/article/details/78974766
- LR(1)文法实现:https://blog.csdn.net/int_Brosea/article/details/106022936
- LR(1)文法:https://wenku.baidu.com/view/556116976bec0975f465e223.html
附录
1 LL(1)代码
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 16 10:41:01 2020
@author: 郭百海
"""
#分析表M
#dicM={
# "S":{"(":"A", ")":"A"},
# "A":{"(":"CB", ")":"CB" },
# "B":{"i":"iCB","*":"e", "$":"e"},
# "C":{"(":"ED", ")":"ED" },
# "D":{"i":"e","+":"+ED","*":"e", "$":"e"},
# "E":{"(":"(", ")":")A*" }
#}
#Epie=P;Tpie=p;yimuxitong=e
dicM={
"E":{"i":"TP","C":"TP"},
"P":{"+":"+TP",")":"e","$":"e"},
"T":{"i":"Fp","(":"Fp"},
"p":{"+":"e","*":"*Fp",")":"e","$":"e"},
"F":{"i":"i","(":"(E)"}
}
#非终结符
VN=[]
for item in dicM.keys():
VN.append(item);
print("非终结符VN集合为:{0}".format(VN))
#终结符
VT=[]
# print(len(dicM))
for item in dicM.values():
for it in item:#遍历key值
VT.append(it)
VT=list(set(VT))
VT.append("e")
print("终结符VT集合为{0}:".format(VT))
#翻转字符串,返回字符串
def convertStr(arg):
conarg=arg[::-1]
return conarg
#找产生式,返回产生式右部
def findCSS(argS,argstr):
if argS in dicM.keys() :
temp_value=dicM[argS]
if argstr in temp_value.keys():
temp=temp_value[argstr]
return temp
return ""
#截取列表 除去最后一个元素
def substr(arg):
# print(arg,"fdsfs")
Listarg=list(arg)
le=len(Listarg)
args=Listarg[0:le-1]
return args
def addS(arg,args):
Listargs=list(args)
for i in arg:
Listargs.append(i)
return Listargs
#strString=input("请输入要分析的符号串:")#输入串
strString="i*i+i"
str=list(strString)
str.append("$")
COUNT=0#步骤
#符号栈
S=["$"]
S.append(VN[0])
# print(S)
CSRight=""
print("步骤\t符号栈S[i]\t\t\t输入串str[j]\t\t\t产生式")
while len(S)!=0:
COUNT += 1
ch = str[0]
CSRight0 = findCSS(S[-1], str[0])
if CSRight0!="" and S[-1] not in VT:
print("%s\t%s\t\t\t\t%s\t\t\t\t%s" % ( COUNT, "".join(S).center(10), "".join(str).center(10),S[-1] + "->" +CSRight0))
elif CSRight0 in VT or S[-1] in VT:
print("%s\t%s\t\t\t\t%s" % ( COUNT, "".join(S).center(10), "".join(str).center(10)))
elif CSRight0=="":
print("\033[0;31m%s\033[0m" % "该句子不是该文法!")
break
CHS = S.pop()
CSRight = findCSS(CHS, str[0])
if CHS not in VT :#如果栈顶元素不是终结字符
if CSRight!="":
if CSRight[0] in VN :
temp = convertStr(CSRight)
S = addS(temp,S)
elif CSRight[0] in VT and CSRight[0]!="e":
temp = convertStr(CSRight)
S = addS(temp, S)
elif CSRight[0]=="e" and CSRight[0] in VT:
pass
elif CSRight=="":
pass
elif CHS in VT:
if ch==CHS:
if CHS=="$":
# print("该句子属于该文法!")
print("\033[1;31;40m该句子属于该文法!\033[0m")
elif CHS!="$":
str = str[1:]
elif ch!=CHS:
if CHS=="$":
print("\033[0;31m%s\033[0m" % "该句子不是该文法!")
pass
2 LR(0)文法
#使用已经建立好的分析表
action={0: {'i': 's5', '(': 's4'},
1: {'+': 's6', '$': 'acc'},
2: {'+': 'r2', '*': 's7', ')': 'r2', '$': 'r2'},
3: {'+': 'r4', '*': 'r4', ')': 'r4', '$': 'r4'},
4: {'i': 's5', '(': 's4'},
5: {'+': 'r6', '*': 'r6', ')': 'r6', '$': 'r6'},
6: {'i': 's5', '(': 's4'},
7: {'i': 's5', '(': 's4'},
8: {'+': 's6', ')': 's11'},
9: {'+': 'r1', '*': 's7', ')': 'r1', '$': 'r1'},
10: {'+': 'r3', '*': 'r3', ')': 'r3', '$': 'r3'},
11: {'+': 'r5', '*': 'r5', ')': 'r5', '$': 'r5'}}
goto={0: {'E': 1, 'T': 2, 'F': 3},
4: {'E': 8, 'T': 2, 'F': 3},
6: {'T': 9, 'F': 3},
7: {'F': 10}}
gramma=open('wx.txt').readlines()
i=0
while i<len(gramma): #去掉'->'符号
gramma[i]=gramma[i][0:1]+gramma[i][3:len(gramma[i])-1]
i+=1
#sen='i*i+i$'
sen='i*+i$'
ip=0#sen的指针
stack=['$',0]
a=sen[ip]
while True:
print(stack, end="")
print("\t",end="")
s=stack[len(stack)-1] #s为栈顶状态
if a in action[s]:#存在action[s][a]
if action[s][a]=='acc': #若为acc 则成功,并结束
print("\033[1;31;40mAccept,该句子属于该文法!\033[0m")
break
elif action[s][a][0]=='s':#若为 si 则把a和i依次入栈 a指向下一个
print('移进'+action[s][a])
t=int(action[s][a][1])
stack.append(a)
stack.append(t)
ip+=1
a=sen[ip]
elif action[s][a][0]=='r':#若为ri i为第i个文法(gramma[i-1]) 则栈回退2*gramma[i-1]表达式表达式右端的长度
print('规约'+gramma[int(action[s][a][1])-1][0:1]+'->'+gramma[int(action[s][a][1])-1][1:])
size=len(gramma[int(action[s][a][1])-1])-1 #rj 对应的第j个产生式右端的长度
j=0
while j<2*size:
stack.pop()
j+=1
t=stack[len(stack)-1]#t为现在栈的状态
stack.append(gramma[int(action[s][a][1])-1][0])#表达式左端入栈
stack.append(goto[t][gramma[int(action[s][a][1])-1][0]])#goto[t,表达式左端]入栈
else:
#调用错误恢复例程
print('error')
break;
*注:最后一行有换行。
E->E+T
E->T
T->T*F
T->F
F->(E)
F->i
3 LR(1)代码
#include<stdio.h>
#include<string.h>
char *action[10][3]= {"S3#","S4#",NULL, /*ACTION表*/
NULL,NULL,"acc",
"S6#","S7#",NULL,
"S3#","S4#",NULL,
"r3#","r3#",NULL,
NULL,NULL,"r1#",
"S6#","S7#",NULL,
NULL,NULL,"r3#",
"r2#","r2#",NULL,
NULL,NULL,"r2#"
};
int goto1[10][2]= {1,2, /*QOTO表*/
0,0,
0,5,
0,8,
0,0,
0,0,
0,9,
0,0,
0,0,
0,0
};
char vt[3]= {'a','b','#'}; /*存放非终结符*/
char vn[2]= {'S','B'}; /*存放终结符*/
char *LR[4]= {"E->S#","S->BB#","B->bB#","B->a#"};/*存放产生式*/
int a[10];
char b[10],c[10],c1;
int top1,top2,top3,top,m,n;
int main()
{
int g,h,i,j,k,l,p,y,z,count;
char x,copy[10],copy1[10];
top1=0;
top2=0;
top3=0;
top=0;
a[0]=0;
y=a[0];
b[0]='#';
count=0;
z=0;
printf("请输入表达式\n");//abb#
do {
scanf("%c",&c1);
c[top3]=c1;
top3=top3+1;
} while(c1!='#');
printf("步骤\t状态栈\t\t符号栈\t\t输入串\t\tACTION\tGOTO\n");
do {
y=z;
m=0;
n=0; /*y,z指向状态栈栈顶*/
g=top;
j=0;
k=0;
x=c[top];
count++;
printf("%d\t",count);
while(m<=top1) {
/*输出状态栈*/
printf("%d",a[m]);
m=m+1;
}
printf("\t\t");
while(n<=top2) {
/*输出符号栈*/
printf("%c",b[n]);
n=n+1;
}
printf("\t\t");
while(g<=top3) {
/*输出输入串*/
printf("%c",c[g]);
g=g+1;
}
printf("\t\t");
while(x!=vt[j]&&j<=2) j++;
if(j==2&&x!=vt[j]) {
printf("error\n");
return 0;
}
if(action[y][j]==NULL) {
printf("error\n");
return 0;
} else strcpy(copy,action[y][j]);
if(copy[0]=='S') {
/*处理移进*/ z=copy[1]-'0';
top1=top1+1;
top2=top2+1;
a[top1]=z;
b[top2]=x;
top=top+1;
i=0;
while(copy[i]!='#') {
printf("%c",copy[i]);
i++;
}
printf("\n");
}
if(copy[0]=='r') {
/*处理归约*/ i=0;
while(copy[i]!='#') {
printf("%c",copy[i]);
i++;
}
h=copy[1]-'0';
strcpy(copy1,LR[h]);
while(copy1[0]!=vn[k]) k++;
l=strlen(LR[h])-4;
top1=top1-l+1;
top2=top2-l+1;
y=a[top1-1];
p=goto1[y][k];
a[top1]=p;
b[top2]=copy1[0];
z=p;
printf("\t");
printf("%d\n",p);
}
} while(action[y][j]!="acc");
printf("恭喜你,分析成功!\n");
return 0;
}