代价函数是凸函数
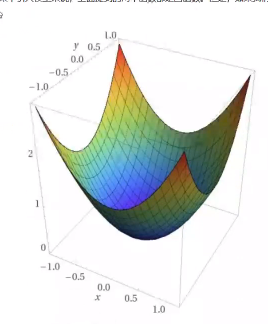
但是模型中加完非线性激活 后,非线性层之间的多次复合变换,使得模型变的极为复杂,求出的预测值带入损失函数后,代价函数就不见得是凸函数了

我们要求出代价函数的全局极小值点,由于有理论指出:代价函数的大部分极小值点足够接近全局极小值点。所以我们求极小值点就可以
方法: 使用梯度下降算法(梯度指函数在该点处沿着该方向增长最快,那么我们沿着梯度的反方向,就可以使该函数在该点出下降最快)

为了使w和b最快达到最优值,从而最小化损失值(就是求出代价函数的极小值),我们使用优化器来更新w和b,不同优化器效果不同




训练的整体流程: 比如batchsize=3,三张图进入网络,一开始先使用初始化的w和b进行训练,前向传播经过每层后,得出每个像素的预测值,然后求出三张预测图的总像素的平均值,与三张标注图的总像素的平均值计算出损失值(损失函数的值),为了最小化损失函数的值,使用上面不同的优化器中的不同方法更新w和b(这些方法的公式的其中都会用到损失函数对w求偏导),更新一层w和b就放到该层,用来当下次进三张图时的w和b,一层一层往前更新(这就是反向传播的过程)。