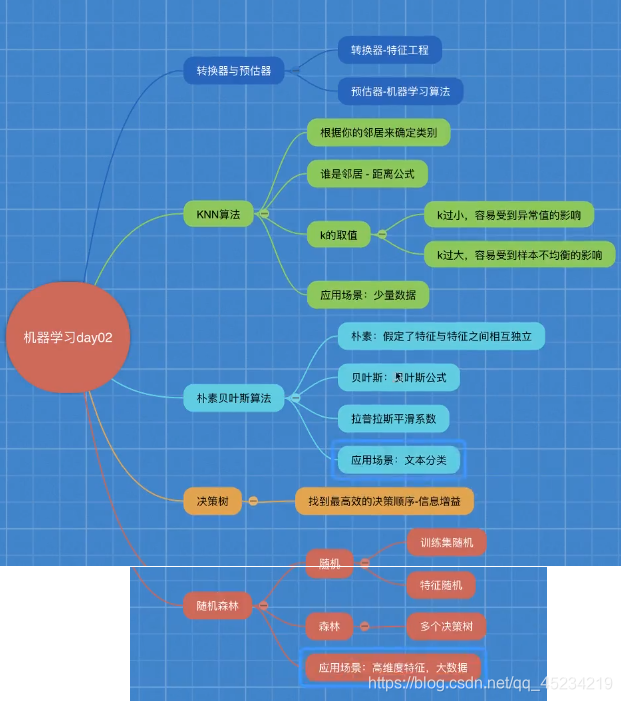
学习目录:

一.sklearn转换器和估计器
1.转换器(特征工程的父类)

2.估计器(sklearn机器学习算法的实现)

第一步:实例化一个estimator
第二步:estimator.fit(x_train,y_train)训练和计算(调用完毕,模型生成)
第三步:模型评估
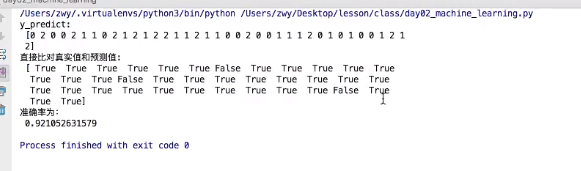
1.直接比对真实值和预测值
y_predice=estimator.predict(x_test)(对测试集进行预测)
y_text==y_predict
2.计算准确率
accuracy=estimator.score(x_text,y_text)
二.KNN算法(K—近邻算法)
原理:根据一个样本,计算出在特征空间中k个与他最相似(即在特征空间中最邻近)的样本,这k个样本中大多数属于的类别,就认为这个样本也属于这个类别。
计算距离公式:欧氏距离,曼哈顿距离,明可夫斯基距离
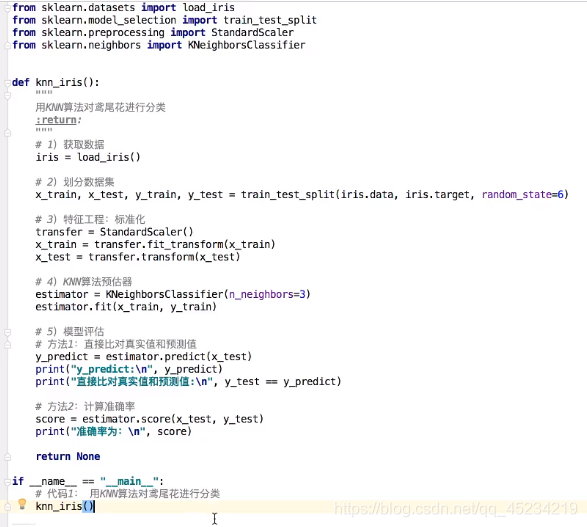
实例:使用KNN算法对鸢尾花数据集进行预测分类
优点:
简单,易于理解,易于实现,无需训练(收到测试集时再计算)
缺点:
懒惰算法:对测试样本分类是计算量大,内存开销大
必须指定k值,但k取很小时易受异常点影响,k取很大时易受样本均衡的影响
使用场景:小数据场景
三.模型选择与调优
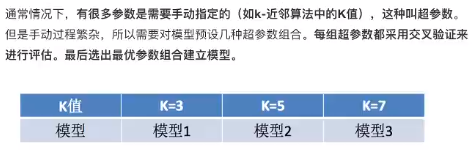
应用:可以方便的帮助我们去选择KNN算法中的k值

1.什么是交叉验证?
将训练数据分为4份,三份训练集和一份验证集,每次都更换不同的验证集,经过4组测试,将四组模型结果取平均,这就是4折交叉验证。

2.超参数搜索——网格搜索
原理:对超参数一个一个试,然后选出一个最优超参折建立模型
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler,StandardScaler
from sklearn.neighbor import KNeighborsClassifer
from sklearn.model_selection import GridSearchCV
def knn_iris_gscv():
"""用KNN算法对鸢尾花数据集进行分类,并添加网格搜索和交叉验证
:return:"""
#获取数据
iris=load_iris()
#划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
#特征工程:标准化
transfer=StandardScaler()#实例化
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)#不使用fit(),因为对验证集进行标准化要按照训练集的标准化标准进行
#KNN算法预估器
estimator=KNeighborsClassifier()#实例化
#加入网格搜索和交叉验证
#参数准备
param_dict={
'n_neighbors':[1,3,5,7,9,11]}#K值分别设为1,3,5,7,9,11
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=10)#10折交叉验证
estimator.fit(x_train,y_train)#把训练数据放进去
#模型评估
#方法一:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
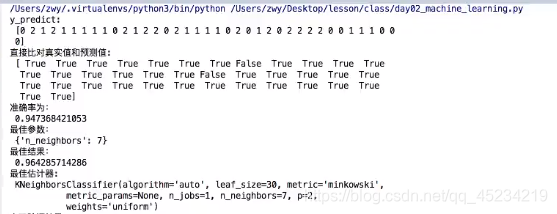
print('y_predict:\n',y_predict)
print('直接比对真实值和预测值:\n', y_test==y_predict)
# 方法二:计算准确率
score = estimator.score(x_test,y_test)
print('准确率:\n', score)
print('最佳参数:\n', estimator.best_params_)
print('最佳结果:\n', estimator.best_score_)
print('最佳估计器:\n', estimator.best_estimator_)
print('交叉验证结果:\n', estimator.cv_results_)
if __name__=='__main__':
knn_iris_gscv()

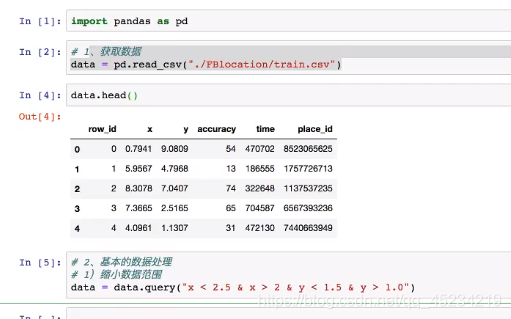
案例:预测facebook签到位置

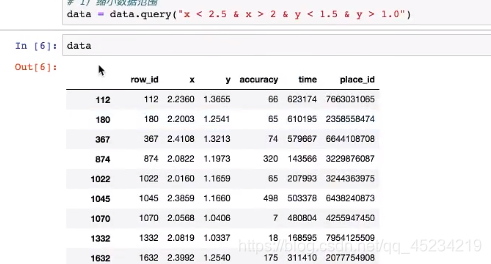
缩小数据范围从两千多万条缩小到八万条:
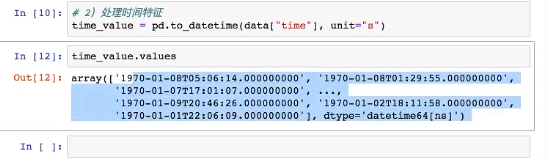
将时间戳转换为年月日时分秒: (pd.to_datatime()可以解析不同种日期表达模式)

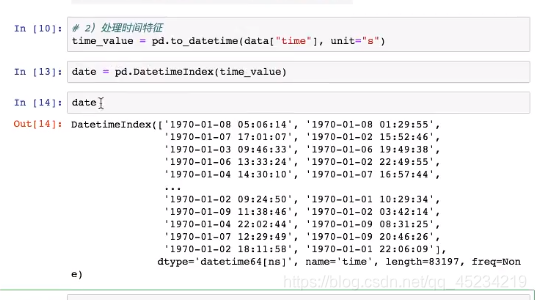
留下 日 时 星期几:(因为年月什么的都是相同的,没必要留下)

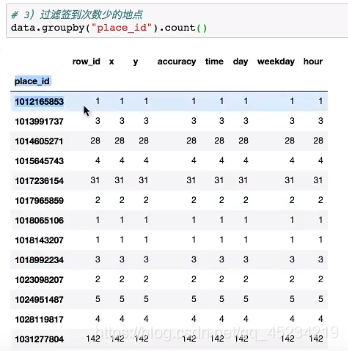
按place_id进行分组用groupby(),使用.count()数一数不同place_id的签到次数,只保留row_id就行:
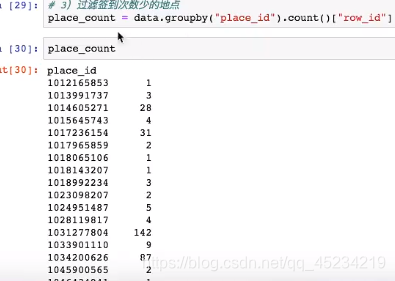
保留签到次数大于三次的地点id:
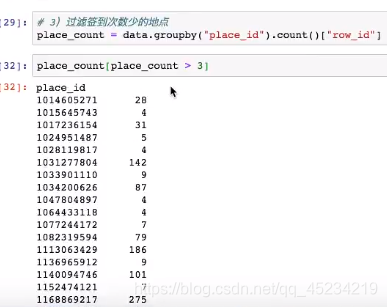
对data中的place_id,返回place_count[place_count>3]的结果,并只保留id的索引(index)的值(values):(place_id中签到次数大于3的为true)

对data进行布尔索引,保留place_count>3的(上面为true)的place_id:
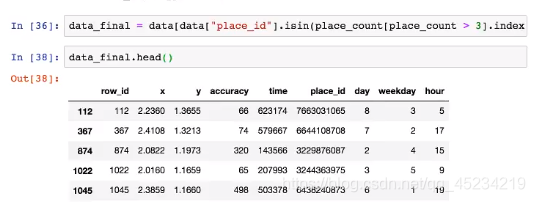
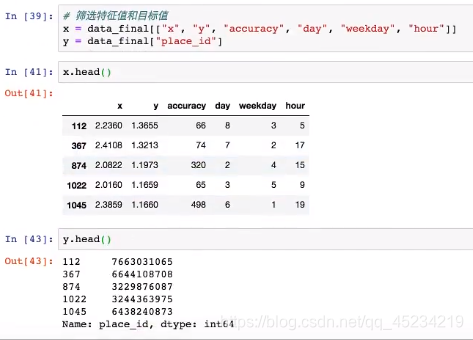
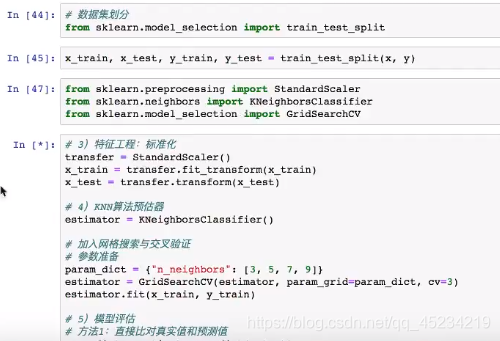


分类算法总结: