从数据库层面上对负载做优化的方法各式各样。从书上看到分表分库等常见手段,后来学习别人博客才明白分表分库各自天生缺点使他无法成为主流而并没有那么多人用,正好毕业设计想尝试一下主从的架构,所以这里一边搭建一边做记录。
目录:
1.介绍
2.应用层面实现mysql读写分离
3.mycat实现mysql读写分离
4.mysql proxy实现mysql读写分离
5.amoeba实现mysql读写分离
6.mysql的自带主从复制搭建
<!--分割线-->
1.介绍
读写分离:
让master(主数据库)来响应事务性操作,让slave(从数据库)来响应select非事务性操作,然后再采用主从复制来把master上的事务性操作同步到slave数据库中。在多读少写(大部分web项目)的场景下性能优化明显。
系统结构:
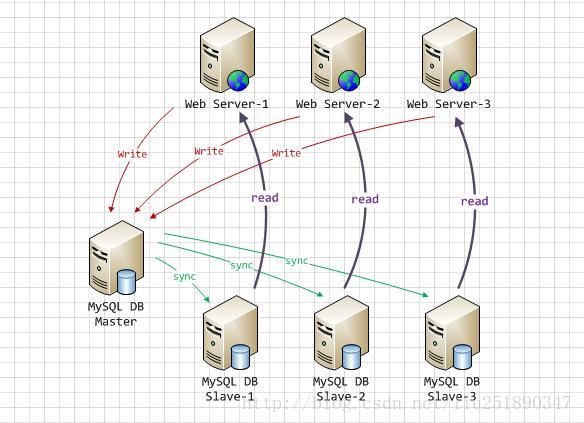
读写分离的好处:
增加了数据的冗余
降低单个节点的负载
优化方式:
可根据实际业务自由变化,比如可以增加从库对并发性能做横向扩展,比如对于读写平衡的项目可以主主互备(相互复制)
由于读写分离去除了读写锁的竞争,提升读写效率
可以各自根据需求配置或新开发更优化的数据库引擎,比如读库可以使用读性能更高的MyIsam引擎
由于从库根据主库的binlog来数据同步(数据同步是异步操作不会阻塞业务)
2.应用层实现mysql读写分离
实现思路:
其实就是在应用服务器里面判断某一个sql语句是读还是写,然后分别发送到对应的数据库中去。
例如:在spring项目中配置多个数据源,使用aop切入点根据save*、update*、delete*等方法调用master数据源,根据find*、get*、query*来调用slave数据源。基本上重点就在于动态切换数据源上面,其他就没什么问题。
优缺点:
优点在于不需要依赖于相关中间件,理论上支持各种类型数据库,多数据源由程序自动切换
缺点在于运维难以涉足,且增加数据源不能自动完成
具体实现:
(1)DynamicDataSource
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法即可
*
* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成。
*/
public class DynamicDataSource extends AbstractRoutingDataSource{
@Override
protected Object determineCurrentLookupKey() {
// 使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源key
return DynamicDataSourceHolder.getDataSourceKey();
}
}
/**
*
* 使用ThreadLocal技术来记录当前线程中的数据源的key
*
* @author zhijun
*
*/
public class DynamicDataSourceHolder {
//写库对应的数据源key
private static final String MASTER = "master";
//读库对应的数据源key
private static final String SLAVE = "slave";
//使用ThreadLocal记录当前线程的数据源key
private static final ThreadLocal<String> holder = new ThreadLocal<String>();
/**
* 设置数据源key
* @param key
*/
public static void putDataSourceKey(String key) {
holder.set(key);
}
/**
* 获取数据源key
* @return
*/
public static String getDataSourceKey() {
return holder.get();
}
/**
* 标记写库
*/
public static void markMaster(){
putDataSourceKey(MASTER);
}
/**
* 标记读库
*/
public static void markSlave(){
putDataSourceKey(SLAVE);
}
}
(3)DataSourceAspect
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.JoinPoint;
/**
* 定义数据源的AOP切面,通过该Service的方法名判断是应该走读库还是写库
*
* @author zhijun
*
*/
public class DataSourceAspect {
/**
* 在进入Service方法之前执行
*
* @param point 切面对象
*/
public void before(JoinPoint point) {
// 获取到当前执行的方法名
String methodName = point.getSignature().getName();
if (isSlave(methodName)) {
// 标记为读库
DynamicDataSourceHolder.markSlave();
} else {
// 标记为写库
DynamicDataSourceHolder.markMaster();
}
}
/**
* 判断是否为读库
*
* @param methodName
* @return
*/
private Boolean isSlave(String methodName) {
// 方法名以query、find、get开头的方法名走从库
return StringUtils.startsWithAny(methodName, "query", "find", "get");
}
}
(4)jdbc.properties
jdbc.master.driver=com.mysql.jdbc.Driver jdbc.master.url=jdbc:mysql://127.0.0.1:3306/mybatis_1128?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true jdbc.master.username=root jdbc.master.password=123456 jdbc.slave01.driver=com.mysql.jdbc.Driver jdbc.slave01.url=jdbc:mysql://127.0.0.1:3307/mybatis_1128?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true jdbc.slave01.username=root jdbc.slave01.password=123456
(5)spring-context.xml
配置数据量连接池、数据源
<!-- 配置连接池 -->
<bean id="masterDataSource" class="com.jolbox.bonecp.BoneCPDataSource"
destroy-method="close">
<!-- 数据库驱动 -->
<property name="driverClass" value="${jdbc.master.driver}" />
<!-- 相应驱动的jdbcUrl -->
<property name="jdbcUrl" value="${jdbc.master.url}" />
<!-- 数据库的用户名 -->
<property name="username" value="${jdbc.master.username}" />
<!-- 数据库的密码 -->
<property name="password" value="${jdbc.master.password}" />
<!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 -->
<property name="idleConnectionTestPeriod" value="60" />
<!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 -->
<property name="idleMaxAge" value="30" />
<!-- 每个分区最大的连接数 -->
<property name="maxConnectionsPerPartition" value="150" />
<!-- 每个分区最小的连接数 -->
<property name="minConnectionsPerPartition" value="5" />
</bean>
<!-- 配置连接池 -->
<bean id="slave01DataSource" class="com.jolbox.bonecp.BoneCPDataSource"
destroy-method="close">
<!-- 数据库驱动 -->
<property name="driverClass" value="${jdbc.slave01.driver}" />
<!-- 相应驱动的jdbcUrl -->
<property name="jdbcUrl" value="${jdbc.slave01.url}" />
<!-- 数据库的用户名 -->
<property name="username" value="${jdbc.slave01.username}" />
<!-- 数据库的密码 -->
<property name="password" value="${jdbc.slave01.password}" />
<!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 -->
<property name="idleConnectionTestPeriod" value="60" />
<!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 -->
<property name="idleMaxAge" value="30" />
<!-- 每个分区最大的连接数 -->
<property name="maxConnectionsPerPartition" value="150" />
<!-- 每个分区最小的连接数 -->
<property name="minConnectionsPerPartition" value="5" />
</bean>
<!-- 定义数据源,使用自己实现的数据源 -->
<bean id="dataSource" class="cn.itcast.usermanage.spring.DynamicDataSource">
<!-- 设置多个数据源 -->
<property name="targetDataSources">
<map key-type="java.lang.String">
<!-- 这个key需要和程序中的key一致 -->
<entry key="master" value-ref="masterDataSource"/>
<entry key="slave" value-ref="slave01DataSource"/>
</map>
</property>
<!-- 设置默认的数据源,这里默认走写库 -->
<property name="defaultTargetDataSource" ref="masterDataSource"/>
</bean>
(6)spring-context.xml
配置事务管理器、自定义切面实现
<!-- 定义事务管理器 -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 定义事务策略 -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<!--定义查询方法都是只读的 -->
<tx:method name="query*" read-only="true" />
<tx:method name="find*" read-only="true" />
<tx:method name="get*" read-only="true" />
<!-- 主库执行操作,事务传播行为定义为默认行为 -->
<tx:method name="save*" propagation="REQUIRED" />
<tx:method name="update*" propagation="REQUIRED" />
<tx:method name="delete*" propagation="REQUIRED" />
<!--其他方法使用默认事务策略 -->
<tx:method name="*" />
</tx:attributes>
</tx:advice>
<!-- 定义AOP切面处理器 -->
<bean class="cn.itcast.usermanage.spring.DataSourceAspect" id="dataSourceAspect">
<!-- 指定事务策略 -->
<property name="txAdvice" ref="txAdvice"/>
<!-- 指定slave方法的前缀(非必须) -->
<property name="slaveMethodStart" value="query,find,get"/>
</bean>
(7)DataSourceAspect
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.JoinPoint;
import org.springframework.transaction.interceptor.NameMatchTransactionAttributeSource;
import org.springframework.transaction.interceptor.TransactionAttribute;
import org.springframework.transaction.interceptor.TransactionAttributeSource;
import org.springframework.transaction.interceptor.TransactionInterceptor;
import org.springframework.util.PatternMatchUtils;
import org.springframework.util.ReflectionUtils;
/**
* 定义数据源的AOP切面,该类控制了使用Master还是Slave。
*
* 如果事务管理中配置了事务策略,则采用配置的事务策略中的标记了ReadOnly的方法是用Slave,其它使用Master。
*
* 如果没有配置事务管理的策略,则采用方法名匹配的原则,以query、find、get开头方法用Slave,其它用Master。
*
* @author zhijun
*
*/
public class DataSourceAspect {
private List<String> slaveMethodPattern = new ArrayList<String>();
private static final String[] defaultSlaveMethodStart = new String[]{ "query", "find", "get" };
private String[] slaveMethodStart;
/**
* 读取事务管理中的策略
*
* @param txAdvice
* @throws Exception
*/
@SuppressWarnings("unchecked")
public void setTxAdvice(TransactionInterceptor txAdvice) throws Exception {
if (txAdvice == null) {
// 没有配置事务管理策略
return;
}
//从txAdvice获取到策略配置信息
TransactionAttributeSource transactionAttributeSource = txAdvice.getTransactionAttributeSource();
if (!(transactionAttributeSource instanceof NameMatchTransactionAttributeSource)) {
return;
}
//使用反射技术获取到NameMatchTransactionAttributeSource对象中的nameMap属性值
NameMatchTransactionAttributeSource matchTransactionAttributeSource = (NameMatchTransactionAttributeSource) transactionAttributeSource;
Field nameMapField = ReflectionUtils.findField(NameMatchTransactionAttributeSource.class, "nameMap");
nameMapField.setAccessible(true); //设置该字段可访问
//获取nameMap的值
Map<String, TransactionAttribute> map = (Map<String, TransactionAttribute>) nameMapField.get(matchTransactionAttributeSource);
//遍历nameMap
for (Map.Entry<String, TransactionAttribute> entry : map.entrySet()) {
if (!entry.getValue().isReadOnly()) {//判断之后定义了ReadOnly的策略才加入到slaveMethodPattern
continue;
}
slaveMethodPattern.add(entry.getKey());
}
}
/**
* 在进入Service方法之前执行
*
* @param point 切面对象
*/
public void before(JoinPoint point) {
// 获取到当前执行的方法名
String methodName = point.getSignature().getName();
boolean isSlave = false;
if (slaveMethodPattern.isEmpty()) {
// 当前Spring容器中没有配置事务策略,采用方法名匹配方式
isSlave = isSlave(methodName);
} else {
// 使用策略规则匹配
for (String mappedName : slaveMethodPattern) {
if (isMatch(methodName, mappedName)) {
isSlave = true;
break;
}
}
}
if (isSlave) {
// 标记为读库
DynamicDataSourceHolder.markSlave();
} else {
// 标记为写库
DynamicDataSourceHolder.markMaster();
}
}
/**
* 判断是否为读库
*
* @param methodName
* @return
*/
private Boolean isSlave(String methodName) {
// 方法名以query、find、get开头的方法名走从库
return StringUtils.startsWithAny(methodName, getSlaveMethodStart());
}
/**
* 通配符匹配
*
* Return if the given method name matches the mapped name.
* <p>
* The default implementation checks for "xxx*", "*xxx" and "*xxx*" matches, as well as direct
* equality. Can be overridden in subclasses.
*
* @param methodName the method name of the class
* @param mappedName the name in the descriptor
* @return if the names match
* @see org.springframework.util.PatternMatchUtils#simpleMatch(String, String)
*/
protected boolean isMatch(String methodName, String mappedName) {
return PatternMatchUtils.simpleMatch(mappedName, methodName);
}
/**
* 用户指定slave的方法名前缀
* @param slaveMethodStart
*/
public void setSlaveMethodStart(String[] slaveMethodStart) {
this.slaveMethodStart = slaveMethodStart;
}
public String[] getSlaveMethodStart() {
if(this.slaveMethodStart == null){
// 没有指定,使用默认
return defaultSlaveMethodStart;
}
return slaveMethodStart;
}
}
一主多从支持:
修改上面DynamicDataSource,采用轮询方式返回读库的key
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
import javax.sql.DataSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.util.ReflectionUtils;
/**
* 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法即可
*
* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成。
*
* @author zhijun
*
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
private static final Logger LOGGER = LoggerFactory.getLogger(DynamicDataSource.class);
private Integer slaveCount;
// 轮询计数,初始为-1,AtomicInteger是线程安全的
private AtomicInteger counter = new AtomicInteger(-1);
// 记录读库的key
private List<Object> slaveDataSources = new ArrayList<Object>(0);
@Override
protected Object determineCurrentLookupKey() {
// 使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源key
if (DynamicDataSourceHolder.isMaster()) {
Object key = DynamicDataSourceHolder.getDataSourceKey();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("当前DataSource的key为: " + key);
}
return key;
}
Object key = getSlaveKey();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("当前DataSource的key为: " + key);
}
return key;
}
@SuppressWarnings("unchecked")
@Override
public void afterPropertiesSet() {
super.afterPropertiesSet();
// 由于父类的resolvedDataSources属性是私有的子类获取不到,需要使用反射获取
Field field = ReflectionUtils.findField(AbstractRoutingDataSource.class, "resolvedDataSources");
field.setAccessible(true); // 设置可访问
try {
Map<Object, DataSource> resolvedDataSources = (Map<Object, DataSource>) field.get(this);
// 读库的数据量等于数据源总数减去写库的数量
this.slaveCount = resolvedDataSources.size() - 1;
for (Map.Entry<Object, DataSource> entry : resolvedDataSources.entrySet()) {
if (DynamicDataSourceHolder.MASTER.equals(entry.getKey())) {
continue;
}
slaveDataSources.add(entry.getKey());
}
} catch (Exception e) {
LOGGER.error("afterPropertiesSet error! ", e);
}
}
/**
* 轮询算法实现
*
* @return
*/
public Object getSlaveKey() {
// 得到的下标为:0、1、2、3……
Integer index = counter.incrementAndGet() % slaveCount;
if (counter.get() > 9999) { // 以免超出Integer范围
counter.set(-1); // 还原
}
return slaveDataSources.get(index);
}
}
3.mycat实现mysql读写分离
mycat和mysqlproxy类似都是单独部署一个服务,web项目的sql语句不直接发送到mysql机器上而是发送到mycat或者mysqlproxy客户端,由客户端通过配置判断读写sql应该分别发送到那个mysql机器,整个过程mycat作为一个代理。mycat使用比较简单,下载压缩包解压,修改三个配置文件然后启动就能用了。当然mycat是一个数据库中间件,用处肯定不止读写分离,还可以实现分表分库等等。
下载压缩包:
解压目录:
| 目录 | 说明 |
|---|---|
| bin | mycat命令,启动、重启、停止等 |
| catlet | catlet为Mycat的一个扩展功能 |
| conf | Mycat 配置信息,重点关注 |
| lib | Mycat引用的jar包,Mycat是java开发的 |
| logs | 日志文件,包括Mycat启动的日志和运行的日志。 |
配置文件目录:
| 文件 | 说明 |
|---|---|
| server.xml | Mycat的配置文件,设置账号、参数等 |
| schema.xml | Mycat对应的物理数据库和数据库表的配置 |
| rule.xml | Mycat分片(分库分表)规则 |
读写分离配置样例:
server.xml:
<user name="test">
<property name="password">test</property>
<property name="schemas">lunch</property>
<property name="readOnly">false</property>
</user> 配置了一个账号test 密码也是test,针对数据库lunch,读写权限都有,没有针对表做任何特殊的权限。
schema.xml:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1" />
</schema>
<!-- 分库配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.0.2:3306" user="root" password="123456">
<readHost host="hostM1" url="192.168.0.3:3306" user="root" password="123456">
</readHost>
</writeHost>
</dataHost>
</mycat:schema> balance改为1,表示读写分离。
以上配置达到的效果就是102.168.0.2为主库,192.168.0.3为从库
mycat服务启动和停止:
命令在解压包bin下
##启动
mycat start
##停止
mycat stop
##重启
mycat restart
mycat start
##停止
mycat stop
##重启
mycat restart
整合到项目中去:
Mycat带来的最大好处就是使用是完全不用修改原有代码的,在mycat通过命令启动后,你只需要将数据库连接切换到Mycat的地址就可以了。登录到mycat客户端之后直接在这里执行sql脚本和在mysql中一样
登录mycat客户端:
mysql -h192.168.0.1 -P8806 -uroot -p123456
4.mysql proxy实现mysql读写分离
环境准备:
准备三个centos分别用来安装mysql主、mysql备、mysqlproxy
安装mysql:
分别在两个centos上面mysql,开启mysql服务
安装mysqlproxy:
解压解包:tar zxvf mysql-proxy-0.8.3-linux-glibc2.3-x86-64bit.tar.gz
解压后文件放到local下:mv mysql-proxy-0.8.3-linux-glibc2.3-x86-64bit /usr/local/mysql-proxy
解压后文件放到local下:mv mysql-proxy-0.8.3-linux-glibc2.3-x86-64bit /usr/local/mysql-proxy
配置mysqlproxy的主配置文件:
创建脚本、日志目录:
cd /usr/local/mysql-proxy
mkdir lua
mkdir logs
mkdir lua
mkdir logs
复制配置文件和管理脚本:
cp share/doc/mysql-proxy/rw-splitting.lua ./lua
cp share/doc/mysql-proxy/admin-sql.lua ./lua
cp share/doc/mysql-proxy/admin-sql.lua ./lua
创建配置文件:
vi /etc/mysql-proxy.cnf
vi /etc/mysql-proxy.cnf
配置文件修改内容如下:
[mysql-proxy]
user=root #运行mysql-proxy用户
admin-username=proxy #主从mysql共有的用户
admin-password=123.com #用户的密码
proxy-address=192.168.0.204:4000 #mysql-proxy运行ip和端口,不加端口,默认4040
proxy-read-only-backend-addresses=192.168.0.203 #指定后端从slave读取数据
proxy-backend-addresses=192.168.0.202 #指定后端主master写入数据
proxy-lua-script=/usr/local/mysql-proxy/lua/rw-splitting.lua #指定读写分离配置文件位置
admin-lua-script=/usr/local/mysql-proxy/lua/admin-sql.lua #指定管理脚本
log-file=/usr/local/mysql-proxy/logs/mysql-proxy.log #日志位置
log-level=info #定义log日志级别,由高到低分别有(error|warning|info|message|debug)
daemon=true #以守护进程方式运行
keepalive=true #mysql-proxy崩溃时,尝试重启
保存修改后的配置文件,同时设置文件权限:
chmod 660 /etc/mysql-porxy.cnf
[mysql-proxy]
user=root #运行mysql-proxy用户
admin-username=proxy #主从mysql共有的用户
admin-password=123.com #用户的密码
proxy-address=192.168.0.204:4000 #mysql-proxy运行ip和端口,不加端口,默认4040
proxy-read-only-backend-addresses=192.168.0.203 #指定后端从slave读取数据
proxy-backend-addresses=192.168.0.202 #指定后端主master写入数据
proxy-lua-script=/usr/local/mysql-proxy/lua/rw-splitting.lua #指定读写分离配置文件位置
admin-lua-script=/usr/local/mysql-proxy/lua/admin-sql.lua #指定管理脚本
log-file=/usr/local/mysql-proxy/logs/mysql-proxy.log #日志位置
log-level=info #定义log日志级别,由高到低分别有(error|warning|info|message|debug)
daemon=true #以守护进程方式运行
keepalive=true #mysql-proxy崩溃时,尝试重启
保存修改后的配置文件,同时设置文件权限:
chmod 660 /etc/mysql-porxy.cnf
配置mysqlproxy的读写分离配置文件:
vi /usr/local/mysql-proxy/lua/rw-splitting.lua
if not proxy.global.config.rwsplit then
proxy.global.config.rwsplit = {
min_idle_connections = 1, #默认超过4个连接数时,才开始读写分离,改为1
max_idle_connections = 1, #默认8,改为1
is_debug = false
}
end
if not proxy.global.config.rwsplit then
proxy.global.config.rwsplit = {
min_idle_connections = 1, #默认超过4个连接数时,才开始读写分离,改为1
max_idle_connections = 1, #默认8,改为1
is_debug = false
}
end
启动mysqlproxy服务:
/usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/etc/mysql-proxy.cnf
netstat -tupln | grep 4000 #已经启动
tcp 0 0 192.168.0.204:4000 0.0.0.0:* LISTEN 1264/mysql-proxy
netstat -tupln | grep 4000 #已经启动
tcp 0 0 192.168.0.204:4000 0.0.0.0:* LISTEN 1264/mysql-proxy
关闭mysql-proxy使用:killall -9 mysql-proxy
读写分离测试:
登录主mysql,创建主从mysql机器公用的用户名和密码(和上面主配置文件相对应):mysql> grant all on *.* to 'proxy'@'192.168.0.204' identified by '123.com';
登录mysqlproxy(使用proxy机器的ip以及上面创建的用户名密码):mysql -u proxy -h 192.168.0.204 -P 4000 -p123.com
从mysqlproxy客户端创建数据表、插入数据:
mysql> create table user (number INT(10),name VARCHAR(255));
mysql> insert into test values(01,'zhangsan');
mysql> insert into user values(02,'lisi');
mysql> insert into test values(01,'zhangsan');
mysql> insert into user values(02,'lisi');
分别登录主从mysql,确保主从数据一致后(需要搭建主从复制的支持)接下来
登录mysqlproxy分别执行读、写操作可以发现上面的创建表、写数据操作会映射到主mysql中。读操作被映射到从mysql中
可以查看架构中中主从机器状态:
mysql -uadmin -padmin -h192.168.0.204:4000 --port=4000
5.amoeba实现mysql读写分离
amoeba和mycat一样也是一个开源的数据库中间价,是chinese开发的支持的功能也比较多包括负载均衡、高可用性、Query过滤、读写分离、可路由相关的query到目标数据库、可并发请求多台数据库合并结果等,使用也很方便直接修改xml配置文件就能搭建读写分离。
下载amoeba:
解压解包:
tar -zxvf amoeba-mysql-binary-2.2.0.tar.gz
解压后可以重命名为amoeba并复制到/usr/local下
修改配置文件:
所有配置文件都在解压包的conf下,在amoeba.xml下配置用户名密码、端口、读写区分(见注释)。dbServers.xml下配置两个物理mysql机器
amoeba.xml完整配置样例:
<amoeba:configuration xmlns:amoeba="http://amoeba.meidusa.com/">
<proxy>
<!-- service class must implements com.meidusa.amoeba.service.Service -->
<service name="Amoeba for Mysql" class="com.meidusa.amoeba.net.ServerableConnectionManager">
<!-- 端口 -->
<property name="port">8066</property>
<!-- bind ipAddress -->
<property name="ipAddress">192.168.168.253</property>
<property name="manager">${clientConnectioneManager}</property>
<property name="connectionFactory">
<bean class="com.meidusa.amoeba.mysql.net.MysqlClientConnectionFactory">
<property name="sendBufferSize">128</property>
<property name="receiveBufferSize">64</property>
</bean>
</property>
<property name="authenticator">
<bean class="com.meidusa.amoeba.mysql.server.MysqlClientAuthenticator">
<!--用户名密码,用户客户端登录-->
<property name="user">root</property>
<property name="password">123456</property>
<property name="filter">
<bean class="com.meidusa.amoeba.server.IPAccessController">
<property name="ipFile">${amoeba.home}/conf/access_list.conf</property>
</bean>
</property>
</bean>
</property>
</service>
<!-- server class must implements com.meidusa.amoeba.service.Service -->
<service name="Amoeba Monitor Server" class="com.meidusa.amoeba.monitor.MonitorServer">
<!-- port -->
<!-- default value: random number
<property name="port">9066</property>
-->
<!-- bind ipAddress -->
<property name="ipAddress">127.0.0.1</property>
<property name="daemon">true</property>
<property name="manager">${clientConnectioneManager}</property>
<property name="connectionFactory">
<bean class="com.meidusa.amoeba.monitor.net.MonitorClientConnectionFactory"></bean>
</property>
</service>
<runtime class="com.meidusa.amoeba.mysql.context.MysqlRuntimeContext">
<!-- proxy server net IO Read thread size -->
<property name="readThreadPoolSize">20</property>
<!-- proxy server client process thread size -->
<property name="clientSideThreadPoolSize">30</property>
<!-- mysql server data packet process thread size -->
<property name="serverSideThreadPoolSize">30</property>
<!-- per connection cache prepared statement size -->
<property name="statementCacheSize">500</property>
<!-- query timeout( default: 60 second , TimeUnit:second) -->
<property name="queryTimeout">60</property>
</runtime>
</proxy>
<!--
Each ConnectionManager will start as thread
manager responsible for the Connection IO read , Death Detection
-->
<connectionManagerList>
<connectionManager name="clientConnectioneManager" class="com.meidusa.amoeba.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.amoeba.net.ConnectionManager</property>
<!--
default value is avaliable Processors
<property name="processors">5</property>
-->
</connectionManager>
<connectionManager name="defaultManager" class="com.meidusa.amoeba.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.amoeba.net.AuthingableConnectionManager</property>
<!--
default value is avaliable Processors
<property name="processors">5</property>
-->
</connectionManager>
</connectionManagerList>
<!-- default using file loader -->
<dbServerLoader class="com.meidusa.amoeba.context.DBServerConfigFileLoader">
<property name="configFile">${amoeba.home}/conf/dbServers.xml</property>
</dbServerLoader>
<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="ruleLoader">
<bean class="com.meidusa.amoeba.route.TableRuleFileLoader">
<property name="ruleFile">${amoeba.home}/conf/rule.xml</property>
<property name="functionFile">${amoeba.home}/conf/ruleFunctionMap.xml</property>
</bean>
</property>
<property name="sqlFunctionFile">${amoeba.home}/conf/functionMap.xml</property>
<property name="LRUMapSize">1500</property>
<property name="defaultPool">master</property>
<!--读写分离的配置,这里设置的是读库和写库的名称-->
<property name="writePool">master</property>
<property name="readPool">slave</property>
<property name="needParse">true</property>
</queryRouter>
</amoeba:configuration>
dbServers.xml:
<amoeba:dbServers xmlns:amoeba="http://amoeba.meidusa.com/">
<!--
Each dbServer needs to be configured into a Pool,
If you need to configure multiple dbServer with load balancing that can be simplified by the following configuration:
add attribute with name virtual = "true" in dbServer, but the configuration does not allow the element with name factoryConfig
such as 'multiPool' dbServer
-->
<dbServer name="abstractServer" abstractive="true">
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">${defaultManager}</property>
<property name="sendBufferSize">64</property>
<property name="receiveBufferSize">128</property>
<!-- mysql port -->
<property name="port">3306</property>
<!-- mysql schema -->
<property name="schema">minishop</property>
<!-- mysql user -->
<property name="user">root</property>
<!-- mysql password -->
<property name="password">123456</property>
</factoryConfig>
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive">500</property>
<property name="maxIdle">500</property>
<property name="minIdle">10</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
<dbServer name="master" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">192.168.168.253</property>
</factoryConfig>
</dbServer>
<dbServer name="slave" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">192.168.168.119</property>
</factoryConfig>
</dbServer>
<dbServer name="multiPool" virtual="true">
<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
<!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA-->
<property name="loadbalance">1</property>
<property name="poolNames">slave1</property>
</poolConfig>
</dbServer>
</amoeba:dbServers> 接下来和上面类似,直接登录代理客户端执行sql脚本
6.mysql的主从复制搭建
mysql自带的主从复制是slave机器利用mater机器的log日志来同步更新数据,其中log日志记录了master机器对数据表的操作。slave同步数据的整个过程是异步的。
(1)mysql安装
首先下载mysql:
官网下载mysql-5.7.21-linux-glibc2.12-x86_64.tar.gz然后使用xftp5上传至centos的/usr/local/下
解压:tar -zxvf mysql-5.7.21-linux-glibc2.12-x86_64.tar.gz
重命名为mysql
添加系统mysql用户组:sudo groupadd mysql
添加mysql用户:sudo useradd -r -g mysql mysql
查看用户组:id mysql
进入mysql目录:cd mysql
安装:bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
末尾会生成临时密码:cig%*nktl
配置ssl:bin/mysql_ssl_rsa_setup --datadir=/usr/local/mysql/data
配置my.cnf:
如果mysql/support-files下没有my-default.cnf则需要我们自己创建(这个文件是配置文件,mysql默认从他来启动,等会儿主从复制也要修改这个文件)
创建空文件:touch /etc/my.cnf
编辑:vim /etc/my.cnf(修改basedir、datadir分别为usr/local/mysql/和usr/localmysql/data/。其余配置先全部注释掉)
守护进程启动mysql:
使用bin/mysqld_safe启动mysql:bin/mysqld_safe &
把mysql添加到后台运行成为服务:
cp mysql.server /etc/init.d/mysql
chmod +x /etc/init.d/mysql
chkconfig --add mysql //把mysql注册为开启启动项
chkconfig --list mysql 查看是否添加成功
修改登录密码:
进入mysql/bin使用刚刚临时密码登录:./mysql -uroot -p
mysql> set password=password("root");
修改mysql远程登陆
use mysql;
update user set host='%' where user='root';
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%' IDENTIFIED BY 'mypwd' WITH GRANT OPTION;
FLUSH PRIVILEGES;
exit;
service mysql restart;
(2)准备两个安装好mysql服务的centos
(3)配置master
在原有/etc/my,cnf配置上面增加主从复制的配置:
## replication server_id=6 binlog-ignore-db=mysql log-bin=master-mysql-bin binlog_cache_size=1M binlog_format=mixed expire_logs_days=7 slave_skip_errors=1062 参数解释如下: serverid 全局唯一的 binlog-ignore-db=mysql复制过滤,我们不同步mysql系统自带的数据库 log-bin=master-mysql-bin 开启logbin功能并设置logbin文件的名称 binlog_format=mixed 混合型复制模式,默认采用基于语句的复制
[client] port = 3306 socket = /usr/local/mysql/mysql.sock [mysqld] character-set-server = utf8 collation-server = utf8_general_ci skip-external-locking skip-name-resolve user = mysql port = 3306 basedir = /usr/local/mysql datadir = /home/mysql/data tmpdir = /home/mysql/temp # server_id = ..... socket = /usr/local/mysql/mysql.sock log-error = /home/mysql/logs/mysql_error.log pid-file = /home/mysql/mysql.pid open_files_limit = 10240 back_log = 600 max_connections=500 max_connect_errors = 6000 wait_timeout=605800 #open_tables = 600 #table_cache = 650 #opened_tables = 630 max_allowed_packet = 32M sort_buffer_size = 4M join_buffer_size = 4M thread_cache_size = 300 query_cache_type = 1 query_cache_size = 256M query_cache_limit = 2M query_cache_min_res_unit = 16k tmp_table_size = 256M max_heap_table_size = 256M key_buffer_size = 256M read_buffer_size = 1M read_rnd_buffer_size = 16M bulk_insert_buffer_size = 64M lower_case_table_names=1 default-storage-engine = INNODB innodb_buffer_pool_size = 2G innodb_log_buffer_size = 32M innodb_log_file_size = 128M innodb_flush_method = O_DIRECT ##################### thread_concurrency = 32 long_query_time= 2 slow-query-log = on slow-query-log-file = /home/mysql/logs/mysql-slow.log ## replication server_id=6 binlog-ignore-db=mysql log-bin=master-mysql-bin binlog_cache_size=1M binlog_format=mixed expire_logs_days=7 slave_skip_errors=1062 [mysqldump] quick max_allowed_packet = 32M [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid
重启mysql服务,并登录客户端下执行下面命令:
grant replication slave, replication client on *.* to 'root'@'192.168.1.5' identified by 'root'; //解释:账号和密码都是root ,允许192.168.1.5这台机器向master发送同步请求
刷新master配置信息:
flush privileges
查看master状态信息:
show master status
(4)配置slave
原有/etc/my.cnf配置文件基础上增加主从复制配置,完整样例如下:
[client] port = 3306 socket = /usr/local/mysql/mysql.sock [mysqld] character-set-server = utf8 collation-server = utf8_general_ci skip-external-locking skip-name-resolve user = mysql port = 3306 basedir = /usr/local/mysql datadir = /home/mysql/data tmpdir = /home/mysql/temp # server_id = ..... socket = /usr/local/mysql/mysql.sock log-error = /home/mysql/logs/mysql_error.log pid-file = /home/mysql/mysql.pid open_files_limit = 10240 back_log = 600 max_connections=500 max_connect_errors = 6000 wait_timeout=605800 #open_tables = 600 #table_cache = 650 #opened_tables = 630 max_allowed_packet = 32M sort_buffer_size = 4M join_buffer_size = 4M thread_cache_size = 300 query_cache_type = 1 query_cache_size = 256M query_cache_limit = 2M query_cache_min_res_unit = 16k tmp_table_size = 256M max_heap_table_size = 256M key_buffer_size = 256M read_buffer_size = 1M read_rnd_buffer_size = 16M bulk_insert_buffer_size = 64M lower_case_table_names=1 default-storage-engine = INNODB innodb_buffer_pool_size = 2G innodb_log_buffer_size = 32M innodb_log_file_size = 128M innodb_flush_method = O_DIRECT ##################### thread_concurrency = 32 long_query_time= 2 slow-query-log = on slow-query-log-file = /home/mysql/logs/mysql-slow.log ## replication server_id=5 binlog-ignore-db=mysql log-bin=mysql-slave-bin binlog_cache_size = 1M binlog_format=mixed expire_logs_days=7 slave_skip_errors=1062 relay_log=mysql-relay-bin log_slave_updates=1 read_only=1 [mysqldump] quick max_allowed_packet = 32M [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid
重启mysql服务,登录客户端。执行命令连接master(首先在master和slave上面建立相同的数据库和数据表):
change master to master_host='192.168.1.6' , master_user='root' , master_password='root' , master_port=3306 , master_log_file='edu-mysql-bin.000002' , master_log_pos=427 , master_connect_retry=30; //master_host=master主机的ip地址 //master_user='root',master_password='root',我们刚刚在master有执行过授权的账号密码就是这个 //master_port=3306,master数据库的端口号 //master_log_file='edu-mysql-bin.000002',master_log_pos=427,这个是我们通过show master status看到的position
查看slave状态:
show slave status\G
开始主从复制:
start slave
回到master客户端查看slave信息:
show processlist\G
(5)测试
进入主数据库服务器,在表中插入一条数据,然后到从数据库服务器中查看是否含有刚刚插入的数据。