异常
在理想状态下 , 用户输人数据的格式永远都是正确的 , 选择打开的文件也一定存在, 并且永远不会出现 bug 。然而, 在现实世界中却充满了不良的数据和带有问题的代码,对于异常情况, 例如 , 可能造成程序崩溃的错误输入, Java 使 用 一 种称为异常处理( exception handing ) 的错误捕获机制处理 。
处理错误
异常分类
在 Java 程序设计语言中, 异常对象都是派生于 Throwable 类的一个实例 。 稍后还可以看到 , 如果 Java 中内置的异常类不能够满足需求 , 用户可以创建自己的异常类 。
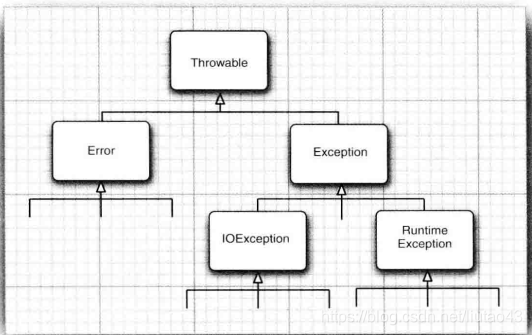
Error和Exception
需要注意的是, 所有的异常都是由 Throwable 继承而来, 但在下一层立即分解为两个分支 : Error 和 Exception*
Error 类层次结构描述了 Java 运行时系统的内部错误和资源耗尽错误 。 应用程序不应该’抛出这种类型的对象 。 如果出现了这样的内部错误, 除了通告给用户, 并尽力使程序安全地终止之外 , 再也无能为力了 。 这种情况很少出现 。
在设计 Java 程序时 , 需要关注 Exception 层次结构 。 这个层次结构又分解为两个分支 :一个分支派生于 RuntimeException ; 另一个分支包含其他异常。 划分两个分支的规则是 : 由程序错误导致的异常属于 RuntimeException ; 而程序本身没有问题 , 但由于像 I / O 错误这类
问题导致的异常属于其他异常 :
Java 语 言 规 范 将 派 生 于 Error 类或 RuntimeException 类的所有异常称为非受查( unchecked ) 异常 , 所有其他的异常称为受查 (checked) 异常 这是两个很有用的术语 。编译器将核查是否为所有的受査异常提供了异常处理器 。
理解: 非受检查的这种异常是不用捕获的,因为这种情况只能手动修改,程序本身无能为力,然后受检查的异常类程序可以处理
声明受查异常
如果遇到了无法处理的情况 , 那么 Java 的方法可以抛出一个异常 。 这个道理很简单 : 一个方法不仅需要告诉编译器将要返回什么值, 还要告诉编译器有可能发生什么错误 。
一段读取文件的代码知道有可能读取的文件不存在, 或者内容为空, 因此 , 试图处理文件信息的代码就需要通知编译器可能会抛出 IOException 类的异常 。
方法应该在其首部声明所有可能抛出的异常 。 这样可以从首部反映出这个方法可能抛出哪类受査异常 。 例如, 下面是标准类库中提供的 FilelnputStream 类的一个构造器的声明:
public FilelnputStream ( String name ) throws FileNotFoundException
这个声明表明这个构造器将根据给定的 String 参数产生一个 FilelnputStream 对象 , 但也有可能抛出一个 FileNotFoimdException 异常 。 如果发生了这种糟糕情况, 构造器将不会初始化一个新的 FilelnputStream 对象, 而是抛出一个 FileNotFoundException 类对象 。 如果这个方法真的抛出了这样一个异常对象 , 运行时系统就会开始搜索异常处理器 , 以便知道如何处理FileNotFoundException 对象 。
什么在方法中throws
在自己编写方法时 , 不必将所有可能抛出的异常都进行声明 。 至于什么时候需要在方法中用 throws 子句声明异常 , 什么异常必须使用 throws 子句声明 , 需要记住在遇到下面 4 种情况时应该抛出异常 :
1 ) 调用一个抛出受査异常的方法, 例如 , FilelnputStream 构造器 。
2 ) 程序运行过程中发现错误 , 并且利用 throw 语句抛出一个受查异常 。
3 ) 程序出现错误 , 例如, a [ - l ] = 0 会抛出一个 ArraylndexOutOffloundsException 这样的非受查异常 。
4 ) Java 虚拟机和运行时库出现的内部错误 。
如果出现前两种情况之一, 则必须告诉调用这个方法的程序员有可能抛出异常 。 为什么 ? 因为任何一个抛出异常的方法都有可能是一个死亡陷阱 。 如果没有处理器捕获这个异常, 当前执行的线程就会结束 。
对于那些可能被他人使用的 Java 方法, 应该根据异常规范 ( exception specification ), 在方法的首部声明这个方法可能抛出的异常 。
class HyAnimation
{
public Image loadlmage ( String s ) throws IOException
{
...
}
}
如果一个方法有可能抛出多个受查异常类型 , 那么就必须在方法的首部列出所有的异常类 。 每个异常类之间用逗号隔开 。 如下面这个例子所示 :
class MyAnimation
{
public Image loadlmage (String s) throws FileNotFoundException , EOFException
{
}
}
但是, 不需要声明 Java 的内部错误 , 即从 Error 继承的错误 。 任何程序代码都具有抛出那些异常的潜能 , 而我们对其没有任何控制能力 。同样, 也不应该声明从 RuntimeException 继承的那些非受查异常。
同样, 也不应该声明从 RuntimeException 继承的那些非受查异常。
class MyAnimation
{
void drawlmage ( int i ) throws ArraylndexOutOfBoundsException // bad style
{
}
}
这些运行时错误完全在我们的控制之下 。 如果特别关注数组下标引发的错误 , 就应该将更多的时间花费在修正程序中的错误上, 而不是说明这些错误发生的可能性上 。
总之, 一个方法必须声明所有可能抛出的受查异常 , 而非受查异常要么不可控制 ( Error ),要么就应该避免发生 ( RuntimeException ) 。 如果方法没有声明所有可能发生的受查异常 , 编译器就会发出一个错误消息 。
当然, 从前面的示例中可以知道 : 除了声明异常之外 , 还可以捕获异常 。 这样会使异常不被抛到方法之外, 也不需要 throws 规范 。
如果在子类中覆盖了超类的一个方法 , 子类方法中声明的受查异常不能比超类方法中声明的异常更通用 (也就是说, 子类方法中可以抛出更特定的异常, 或者根本不抛出任何异常 )。 特别需要说明的是, 如果超类方法没有抛出任何受查异常, 子类也不能抛出任何受查异常 。 例如 , 如果覆盖 JComponent . paintComponent 方法 , 由于超类中这个方法没有抛出任何异常, 所以 , 自定义的 paintComponent 也不能抛出任何受查异常 。
如何抛出异常
假设在程序代码中发生了一些很糟糕的事情 。
一个名为 readData 的方法正在读取一个1024长度的文件 ,然而, 读到 733 个字符之后文件就结束了 。 我们认为这是一种不正常的情况 , 希望抛出一个异常 。
首先要决定应该抛出什么类型的异常 。 将上述异常归结为 IOException 是一种很好的选择 。 仔细地阅读 Java API 文档之后会发现 : EOFException 异常描述的是 “ 在输人过程中, 遇到了一个未预期的 EOF 后的信号 ” 。 这正是我们要抛出的异常 。 下面是抛出这个异常的语句 :
throw new EOFExceptionQ ;
或者
EOFException e = new EOFExceptionO ;
throw e;
下面将这些代码放在一起 :
String readData (Scanner in) throws EOFException
while ( ... )
{
if ( !in. hasNext() )
{
if ( n < len )
throw new EOFExceptionQ ;
}
}
EOFException 类还有一个含有一个字符串型参数的构造器 。 这个构造器可以更加细致的描述异常出现的情况 。
String gripe = " Content - length: " + len + " , Received : " + n;
throw new EOFException ( gripe ) ;
对于一个已经存在的异常类 , 将其抛出非常容易,在这种情况下 :
1 ) 找到一个合适的异常类 。
2 ) 创建这个类的一个对象 。
3 ) 将对象抛出 。
一旦方法抛出了异常, 这个方法就不可能返回到调用者 。 也就是说, 不必为返回的默认值或错误代码担忧 。
创建异常类
在程序中, 可能会遇到任何标准异常类都没有能够充分地描述清楚的问题 。 在这种情况下 , 创建自己的异常类就是一件顺理成章的事情了 。
我们需要做的只是定义一个派生于Exception 的类, 或者派生于 Exception 子类的类 。 例如, 定义一个派生于 IOException 的类 。习惯上, 定义的类应该包含两个构造器 , 一个是默认的构造器; 另一个是带有详细描述信息的构造器。
超类 Throwable 的 toString 方法将会打印出这些详细信息 , 这在调试中非常有用
class FileFormatException extends IOException
{
public FileFormatExceptionO {
}
public FileFormatException ( St ring gripe )
{
super ( gripe ) ;
}
}
现在 , 就可以抛出自己定义的异常类型了 。
```bash
String readData (Scanner in) throws FileFormatException
while ( ... )
{
if ( !in. hasNext() )
{
if ( n < len )
throw new EOFExceptionQ ;
}
}
捕获异常
已经知道如何抛出一个异常 。 这个过程十分容易 。 只要将其抛出就不用理踩了 。
当然, 有些代码必须捕获异常 。 捕获异常需要进行周密的计划 。
捕获异常
如果某个异常发生的时候没有在任何地方进行捕获 , 那程序就会终止执行 ,并在控制台上打印出异常信息, 其中包括异常的类型和堆栈的内容 。
要想捕获一个异常, 必须设置 try / catch 语句块 。 最简单的 try语句块如下所示:
try
{
code
more code
more code
}
catch ( ExceptionType e )
{
handler for this type
}
如果在 try 语句块中的任何代码抛出了一个在 catch 子句中说明的异常类, 那么
1 ) 程序将跳过 try 语句块的其余代码 。
2 ) 程序将执行 catch 子句中的处理器代码 。
如果在 try 语句块中的代码没有拋出任何异常, 那么程序将跳过 catch 子句 。
如果方法中的任何代码拋出了一个在 catch 子句中没有声明的异常类型, 那么这个方法就会立刻退出 (希望调用者为这种类型的异常设设计了catch 子句 。
为了演示捕获异常的处理过程, 下面给出一个读取数据的典型程序代码 :
public void read ( String filename )
{
try
{
InputStream in = new FileInputStream(filename) ;
int b;
while (( b = in read () 3 != - 1 )
{
process input
}
}
catch ( IOException exception )
{
exception printStackTrace () ;
}
}
需要注意的是 , try 语句中的大多数代码都很容易理解 : 读取并处理字节, 直到遇到文件结束符为止 。
正如在 Java API 中看到的那样, read 方法有可能拋出一个 IOException 异常 。
在这种情况下 , 将跳出整个 while 循环 , 进入 catch 子旬, 并生成一个栈轨迹 。
实际的一个案例:
public static void main(String[] args){
try{
int[] arr = new int[10];
arr[-1] = 1;
}catch (ArrayIndexOutOfBoundsException e){
System.out.println("error");
e.printStackTrace();
}
}
编译器严格地执行 throws 说明符 。 如果调用了一个抛出受查异常的方法, 就必须对它进行处理 , 或者继续传递 。
如果想传递一个异常 , 就必须在方法的首部添加一个 throws 说明符, 以便告知调用者这个方法可能会抛出异常 。
捕获多个异常
在一个 try 语句块中可以捕获多个异常类型 , 并对不同类型的异常做出不同的处理 。 可以按照下列方式为每个异常类型使用一个单独的 catch 子句 :
try
{
code that might throw exceptions
}
catch ( FileNotFoundException e )
{
emergency action for missing files
}
catch ( UnknownHostException e )
{
emergency action for unknown hosts
}
catch ( IOException e )
{
emergency action for all other I / O problems
}
在写异常处理的时候,一定要把异常范围小的放在前面,范围大的放在后面,Exception这个异常的根类一定要放在最后一个catch里面,如果放在前面或者中间,任何异常都会和Exception匹配的,就会报已捕获到…异常的错误。
例如, 假设对应缺少文件和未知主机异常的动作是一样的 , 就可以合并 catch 子句 :
try
{
code that might throw exceptions
}
catch ( FileNotFoundException | UnknownHostExceptio e )
{
emergency action for missing files
}
catch ( UnknownHostException e )
{
emergency action for unknown hosts
}
catch ( IOException e )
{
emergency action for all other I / O problems
}
只有当捕获的异常类型彼此之间不存在子类关系时才需要这个特性 。
finally 子句
当代码抛出一个异常时, 就会终止方法中剩余代码的处理, 并退出这个方法的执行 。 如果方法获得了一些本地资源 , 并且只有这个方法自己知道, 又如果这些资源在退出方法之前必须被回收 , 那么就会产生资源回收问题 。
无论在 try 语句块中是否遇到异常, finally 子句中的 in . close () 语句都会被执行 。 当然 ,如果真的遇到一个异常 , 这个异常将会被重新抛出, 并且必须由另一个 catch 子句捕获 。
如果使用 Java 编写数据库程序, 就需要使用同样的技术关闭与数据库的连接 。
不管是否有异常被捕获, finally 子句中的代码都被执行 。 在下面的示例中, 程序将在所有情况下关闭文件 。
InputStream in = new FileInputStream (...);
try
{
// 1
code that might throw exceptions
// 2
}
catch ( IOException e )
{
// 3
show error message
// 4
}
finally
{
// 5
in.close() ;
}
// 6
在上面这段代码中, 有下列 3 种情况会执行 finally 子句 :
1 ) 代码没有抛出异常 。 在这种情况下, 程序首先执行 try 语句块中的全部代码 , 然后执行 finally 子句中的代码。随后, 继续执行 try 语句块之后的第一条语句 。 也就是说 , 执行标注的 1 、 2 、 5 、 6 处 。
2 ) 抛出一个在 catch 子句中捕获的异常 。 在上面的示例中就是 IOException 异常 。 在这种情况下, 程序将执行 try 语句块中的所有代码, 直到发生异常为止 。 此时, 将跳过 try 语句块中的剩余代码, 转去执行与该异常匹配的 catch 子句中的代码 , 最后执行 finally 子句中的代码 。
如果 catch 子句没有抛出异常, 程序将执行 try 语句块之后的第一条语句 。 在这里 , 执行标注 1 、 3 、 4 、 5 、 6 处的语句。
如果 catch 子句抛出了一个异常 , 异常将被抛回这个方法的调用者 。 在这里 , 执行标注1 、 3 、 5 处的语句 。
3 ) 代码抛出了一个异常, 但这个异常不是由 catch 子句捕获的 。 在这种情况下 , 程序将执行 try 语句块中的所有语句, 直到有异常被抛出为止 。 此时, 将跳过 try 语句块中的剩余代码, 然后执行 finally 子句中的语句, 并将异常抛给这个方法的调用者 。
带资源的 try 语句
open a resource
try
{
work with the resource
}
finally
{
close the resource
}
泛型程序设计
泛型正是我们需要的程序设计手段 。 使用泛型机制编写的程序代码要比那些杂乱地使用Object 变量, 然后再进行强制类型转换的代码具有更好的安全性和可读性 。
定义简单泛型类
一个泛型类 ( generic class ) 就是具有一个或多个类型变量的类 。 使用一个简单的Pair 类作为例子 。 对于这个类来说 , 我们只关注泛型, 而不会为数据存储的细节烦恼 。 下面是 Pair 类的代码 :
public class Pair <T>
{
private T first;
private T second;
public Pair () {
first = null ; second = null ;}
public Pairf(T first , T second) {
this , first = first ; this . second = second;}
public T getFirstO {
return first ;}
public T getSecondO {
return second ;}
public void setFirst (T newValue) {
first = newValue;}
public void setSecond (T newValue) {
second = newValue;}
}
Pair 类引人了一个类型变量 T , 用尖括号 ( < > ) 括起来, 并放在类名的后面 。 泛型类可以有多个类型变量 。 例如, 可以定义 Pair 类, 其中第一个域和第二个域使用不同的类型 :
public class Pair <T,U>{
...}
类型变量使用大写形式 , 且比较短 , 这是很常见的 。 在 Java 库中 , 使用变量 E 表示集合的元素类型, K 和 V 分别表示表的关键字与值的类型 。T ( 需要时还可以用临近的字母 U 和 S ) 表示 “ 任意类型 ” 。
用具体的类型替换类型变量就可以实例化泛型类型 , 例如 :
Pair < String >
可以将结果想象成带有构造器的普通类:
Pair < String > ()
Pair < String > ( String , String )
和方法 :
String getFirst()
String get Second ()
void set First (String )
void setSecond ( String )
案例
public class Pair<T>
{
private T first;
private T second;
public Pair() {
first = null; second = null; }
public Pair(T first, T second) {
this.first = first; this.second = second; }
public T getFirst() {
return first; }
public T getSecond() {
return second; }
public void setFirst(T newValue) {
first = newValue; }
public void setSecond(T newValue) {
second = newValue; }
}
public class PairTest1
{
public static void main(String[] args)
{
String[] words = {
"Mary", "had", "a", "little", "lamb" };
Pair<String> mm = ArrayAlg.minmax(words);
System.out.println("min = " + mm.getFirst());
System.out.println("max = " + mm.getSecond());
}
}
class ArrayAlg
{
/**
* Gets the minimum and maximum of an array of strings.
* @param a an array of strings
* @return a pair with the min and max value, or null if a is null or empty
*/
public static Pair<String> minmax(String[] a)
{
if (a == null || a.length == 0) return null;
String min = a[0];
String max = a[0];
for (int i = 1; i < a.length; i++)
{
if (min.compareTo(a[i]) > 0) min = a[i];
if (max.compareTo(a[i]) < 0) max = a[i];
}
return new Pair<>(min, max);
}
}
泛型方法
可以定义一个带有类型参数的简单方法 。
class ArrayAlg
{
public static <T > T getMiddle (T... a)
{
return a[a.length / 2]
}
}
这个方法是在普通类中定义的 , 而不是在泛型类中定义的 。 然而, 这是一个泛型方法 ,可以从尖括号和类型变量看出这一点 。 注意, 类型变量放在修饰符 (这里是 public static ) 的后面 , 返回类型的前面 。

类型变量的限定
有时 , 类或方法需要对类型变量加以约束 。 下面是一个典型的例子 。 我们要计算数组中的最小元素 :
public static <T extends Comparable> Pair<T> minmax(T[] a)
{
if (a == null || a.length == 0) return null;
T min = a[0];
T max = a[0];
for (int i = 1; i < a.length; i++)
{
if (min.compareTo(a[i]) > 0) min = a[i];
if (max.compareTo(a[i]) < 0) max = a[i];
}
return new Pair<>(min, max);
}
但是 , 这里有一个问题 。 请看一下 minmax方法的代码内部 。 变量min和max类型为 T , 这意味着它可以是任何一个类的对象 。 怎么才能确信T 所属的类有 compareTo 方法呢 ?
解决这个问题的方案是将 T 限制为实现了 Comparable 接口 (只含一个方法 compareTo 的标准接口 ) 的类 。 可以通过对类型变量 T 设置限定 ( bound ) 实现这一点 :
public static <T extends Comparable> Pair<T> minmax(T[] a)
为什么用extends,这和继承没有什么特殊关系,就是单纯的语法规则,表示这个类一定要实现Comparable借口。
当然T也可以限定类,T extends 类名,代表T必须要继承这个类。
泛型代码和虚拟机
虚拟机没有泛型类型对象,所有对象都属于普通类 。
类型擦除,泛型类
无论何时定义一个泛型类型 , 都自动提供了一个相应的原始类型(raw type) 。原始类型的名字就是删去类型参数后的泛型类型名 。 擦除类型变 , 并替换为限定类型或者Object。
例如 , Pair < T > 的原始类型如下所示 :
public class Pair
{
private Object first;
private Object second;
public Pair() {
first = null; second = null; }
public Pair(Object first, Object second) {
this.first = first; this.second = second; }
public Object getFirst() {
return first; }
public Object getSecond() {
return second; }
public void setFirst(Object newValue) {
first = newValue; }
public void setSecond(Object newValue) {
second = newValue; }
}
因为 T 是一个无限定的变量 , 所以直接用 Object 替换 。
Java的泛型是由编译器在编译时实行的,编译器内部永远把所有类型T视为Object处理,但是,在需要转型的时候,编译器会根据T的类型自动为我们实行安全地强制转型。
因此,Java使用擦拭法实现泛型,导致了:
编译器把类型视为Object
编译器根据实现安全的强制转型
使用泛型的时候,我们编写的代码也是编译器看到的代码:
Pair<String> p = new Pair<>("Hello", "world");
String first = p.getFirst();
String last = p.getLast();
而虚拟机执行的代码并没有泛型:
Pair p = new Pair("Hello", "world");
String first = (String) p.getFirst();
String last = (String) p.getLast();
在需要转型的时候,编译器会根据T类型自动为我们实行安全地强制转型,T类型的就是< T >中的内容
原始类型用第一个限定的类型变量来替换, 如果没有给定限定就用 Object 替换 。 例如,类 Pair < T > 中的类型变量没有显式的限定 , 因此 , 原始类型用 Object 替换 T 。 假定声明了一个不同的类型 。
public class Interval<T extends Comparable & Serializable> implements Serializable{
private T lower;
public Interval(T first, T second){
...}
}
//原始类型如下:
public class Interval implements Serializable{
private Comparable lower;
public Interval(Comparable first, Comparable second){
...}
}
像上面这种多个泛型上限的类型,应该尽量把标识接口上限类型放在边界列表的尾部,这样做可以提高效率。&符号代表限定在多个的接口或者类。
类型擦除,泛型接口
泛型接口和类很类似,只提供方法,不提供具体实现,实现泛型接口有两种情况:
- 定义子类:在子类的定义上也声明泛型类型
interface Info<T>{
// 在接口上定义泛型
public T getVar() ; // 定义抽象方法,抽象方法的返回值就是泛型类型
}
class InfoImpl<T> implements Info<T>{
// 定义泛型接口的子类
private T var ; // 定义属性
public InfoImpl(T var){
// 通过构造方法设置属性内容
this.setVar(var) ;
}
public void setVar(T var){
this.var = var ;
}
public T getVar(){
return this.var ;
}
};
public class GenericsDemo24{
public static void main(String arsg[]){
Info<String> i = null; // 声明接口对象
i = new InfoImpl<String>("李兴华") ; // 通过子类实例化对象
System.out.println("内容:" + i.getVar()) ;
}
};
如果现在实现接口的子类不想使用泛型声明,则在实现接口的时候直接指定好其具体的操作类型即可:
interface Info<T>{
// 在接口上定义泛型
public T getVar() ; // 定义抽象方法,抽象方法的返回值就是泛型类型
}
class InfoImpl implements Info<String>{
// 定义泛型接口的子类
private String var ; // 定义属性
public InfoImpl(String var){
// 通过构造方法设置属性内容
this.setVar(var) ;
}
public void setVar(String var){
this.var = var ;
}
public String getVar(){
return this.var ;
}
};
public class GenericsDemo25{
public static void main(String arsg[]){
Info i = null; // 声明接口对象
i = new InfoImpl("李兴华") ; // 通过子类实例化对象
System.out.println("内容:" + i.getVar()) ;
}
};
类型擦除,泛型方法
类型擦除也会出现在泛型方法中 。 程序员通常认为下述的泛型方法
public static <T extends Comparable〉 T min ( T[] a )
是一个完整的方法族 , 而擦除类型之后, 只剩下一个方法 :
public static Comparable min (Comparable [] a )
注意 , 类型参数 T 已经被擦除了 , 只留下了限定类型 Comparable 。
总之 , 需要记住有关 Java 泛型转换的事实 :
• 虚拟机中没有泛型 , 只有普通的类和方法 。
• 所有的类型参数都用它们的限定类型替换 。
擦拭的局限
- 局限一:不能是基本类型,例如int,因为实际类型是Object,Object类型无法持有基本类型
- 局限二:无法取得带泛型的Class。因为T是Object,我们对Pair和Pair类型获取Class时,获取到的是同一个Class,也就是Pair类的Class。换句话说,所有泛型实例,无论T的类型是什么,getClass()返回同一个Class实例,因为编译后它们全部都是Pair,T为Object。
- 局限三: 泛型类的静态上下文中类型变量无效,因为T都是实例变量
- 局限四:无法判断带泛型的类型,原因和前面一样,并不存在Pair.class,而是只有唯一的Pair.class。
Pair<Integer> p = new Pair<>(123, 456);
// Compile error:
if (p instanceof Pair<String>) {
}
- 局限四:不能实例化T类型:
public class Pair<T> {
private T first;
private T last;
public Pair() {
// Compile error:
first = new T();
last = new T();
}
}
上述代码无法通过编译,因为构造方法的两行语句:
first = new T();
last = new T();
擦拭后实际上变成了:
first = new Object();
last = new Object();
这样一来,创建new Pair()和创建new Pair()就全部成了Object,显然编译器要阻止这种类型不对的代码。
要实例化T类型,我们必须借助额外的Class参数:
public class Pair<T> {
private T first;
private T last;
public Pair(Class<T> clazz) {
first = clazz.newInstance();
last = clazz.newInstance();
}
}
上述代码借助Class参数并通过反射来实例化T类型,使用的时候,也必须传入Class。例如:
Pair<String> pair = new Pair<>(String.class);
因为传入了Class的实例,所以我们借助String.class就可以实例化String类型。但是反射只能调用无参构造函数,所以用处不大。
泛型类型的继承规则
泛型继承很简单,一句话就是,所有的泛型参数在使用时都能被指定为特定的类型,要么开发者指定要么编译器可以推断出来
class Father<T> {
T data;
public Father(T data) {
this.data = data;
}
@Override
public String toString() {
return "Father [data=" + data + "]";
}
}
class Son1<T> extends Father<T> {
// 最正常的继承,子类的泛型参数和父类的参数是一致的
public Son1(T data) {
super(data);
}
@Override
public String toString() {
return "Son1 [data=" + data + "]";
}
}
class Son2<E, F> extends Father<F> {
// 子类增加了一个泛型参数,父类的泛型参数不能遗漏,所以仍然要定义
E otherData;
public Son2(F data, E otherData) {
super(data);
this.otherData = otherData;
}
@Override
public String toString() {
return "Son2 [otherData=" + otherData + ", data=" + data + "]";
}
}
class Son3 extends Father {
// 继承时不指定父类的泛型参数,会有警告信息:Father is a raw type.
// References to generic type Father<T> should be
// parameterized
public Son3(Object data) {
// 这个的data类型为Object
super(data);
}
@Override
public String toString() {
return "Son3 [data=" + data + "]";
}
}
// 继承时指定父类的泛型参数,子类就不用再写泛型参数,如果写了,那就是子类自己新增加的
class Son4 extends Father<Integer> {
public Son4(Integer data) {
super(data);
}
@Override
public String toString() {
return "Son4 [data=" + data + "]";
}
}
// 父类指定了类型,子类又增加了,这时子类的只是新增加的泛型参数,跟父类没有关系
class Son5<T> extends Father<Integer> {
T otherData;
public Son5(Integer data, T otherData) {
super(data);
this.otherData = otherData;
}
@Override
public String toString() {
return "Son5 [otherData=" + otherData + ", data=" + data + "]";
}
}
// 子类的泛型参数是Integer 这个是我无意使用的,当然真实项目是绝对不允许这样使用的,一般泛型参数命名都是单个大写字母
// 这里使用只是来说明万一泛型参数和一个类名相同了,别糊涂了(相同了都是来故意迷糊人的)
// 这里的Integer 不是java.lang.Integer 它只是一个泛型参数名称 ,恰好相同,跟Son1是没有区别的
// 它出现这里会把类中所有的Integer(java.lang.Integer) 都替换成 泛型参数
// 警告提示:The type parameter Integer is hiding the type Integer
// 所以传给父类的Integer,也不是java.lang.Integer,也只是一个类型参数
class Son6<Integer> extends Father<Integer> {
Integer otherData;// 它是什么类型呢?java.lang.Integer?NONONO 只能说不确定!
public Son6(Integer data, Integer otherData) {
super(data);
this.otherData = otherData;
}
@Override
public String toString() {
return "Son6 [otherData=" + otherData + ", data=" + data + "]";
}
}
// 下面是错误的情况 父类的类型参数不明确,这会让编译器迷糊 ,让它迷糊了,就是错了!
// class Son7 extends Father<T>{}
// 父类和子类的泛型参数具有关系
class Son8<T, E extends T> extends Father<T> {
E otherData;
public Son8(T data, E otherData) {
super(data);
this.otherData = otherData;
}
@Override
public String toString() {
return "Son8 [otherData=" + otherData + ", data=" + data + "]";
}
}
public class Pair
{
public static void main(String[] args) {
// 这里只测试Son6和Son8 其他很简单,自己测试吧!
System.out.println(new Son6<String>("son6", "son6"));// 构造函数两个参数类型一样的
System.out.println(new Son8<Number, Long>(8, 8L));// 构造函数 两个参数具有父子关系
}
}
// 下面的写法也是错误的,要是父类的T为Object 这时E为什么呢?
// class Son9<E, E super T> extends Father<T> {
//
// public Son9(T data) {
// super(data);
// }
// }
通配符类型
自己的理解:
Pair不是Pair的子类,不仅不是子类,而且这两个泛型类没有任何关系,这是语法,就算擦出之后是同样的Pair类,但是为了告诉别人,类属性使我们设定的确切数据类型,所以像这种泛型类就是两个不同的类,所以无法相互赋值,尽管逻辑上允许。
public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
int n = add(p);
System.out.println(n);
}
static int add(Pair<Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
return first.intValue() + last.intValue();
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
以上代码逻辑上完全允许,但是报错,因为这两个泛型类没有任何关系。和下图非常类似。永远可以将参数化类型转换为一个原始类型。
所以报错原因就是,这两个泛型类没有任何关系,Pair不是Pair的子类,因此,add(Pair)不接受参数类型Pair,但是又符合逻辑规则,所以可以利用通配符改变。
使用Pair<? extends Number>使得方法接收所有泛型类型为Number或Number子类的Pair类型。
public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
int n = add(p);
System.out.println(n);
}
static int add(Pair<? extends Number> p) {
Number first = p.getFirst(); // 这是因为实际的返回类型可能是Integer,也可能是Double或者其他类型,编译器只能确定类型一定是Number的子类(包括Number类型本身),但具体类型无法确定。
Number last = p.getLast();
return first.intValue() + last.intValue();
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
这样一来,给方法传入Pair类型时,它符合参数Pair<? extends Number>类型。这种使用<? extends Number>的泛型定义称之为上界通配符(Upper Bounds Wildcards),即把泛型类型T的上界限定在Number了。
除了可以传入Pair类型,我们还可以传入Pair类型,Pair类型等等,因为Double和BigDecimal都是Number的子类。
同理是规定上界,自然就有下界,使用下界来接受泛型类型的父类泛型类型,Pair<? super Integer>表示,方法参数接受所有泛型类型为Integer或Integer父类的Pair类型
例如:
public class Main {
public static void main(String[] args) {
Pair<Number> p1 = new Pair<>(12.3, 4.56);
Pair<Integer> p2 = new Pair<>(123, 456);
setSame(p1, 100);
setSame(p2, 200);
System.out.println(p1.getFirst() + ", " + p1.getLast());
System.out.println(p2.getFirst() + ", " + p2.getLast());
}
static void setSame(Pair<? super Integer> p, Integer n) {
p.setFirst(n);
p.setLast(n);
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
public void setFirst(T first) {
this.first = first;
}
public void setLast(T last) {
this.last = last;
}
}
考察Pair<? super Integer>的setFirst()方法,它的方法签名实际上是:
void setFirst(? super Integer);
因此,可以安全地传入Integer类型。
再考察Pair<? super Integer>的getFirst()方法,它的方法签名实际上是:
<? super Integer > getFirst();
这里注意到我们无法使用Integer类型来接收getFirst()的返回值,即下面的语句将无法通过编译:
Integer x = p.getFirst();
因为如果传入的实际类型是Pair,编译器无法将Number类型转型为Integer。
所以用了上边界限定通配符:<? extends T>,取出的元素转型为 T。dest 是要写入的目标 List,所以用了下边界限定通配符:<? super T>,可以写入的元素类型是 T 及其子类型。