Python爬虫 - 专栏链接
手把手教你如何入门,如何进阶。
目录
1. 分页爬虫
分页爬虫指的是针对网站数据存在上一页 下一页 翻页情况。
为了分页爬取整个网站,我们得先分析该网站的数据是如何加载的。
还是以豆瓣读书为例,当我们点击第二页后,观察浏览器的地址栏,发现网址变了。网址变成了 https://book.douban.com/top250?start=25,和原来相比后面多了一个 ?start=25。

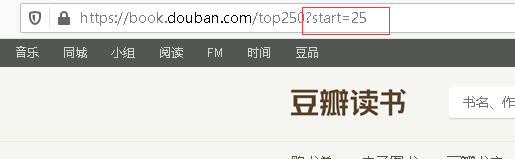
这部分被称为 查询字符串,查询字符串作为用于搜索的参数或处理的数据传送给服务器处理,格式是 ?key1=value1&key2=value2。
? 前面是网页的地址,后面是查询字符串。以键值对 key=value 的形式赋值,多个键值对之间用 & 连接在一起。例如 ?a=1&b=2 表示:a 的值为 1,b 的值为 2。
查询字符串用于信息的传递,服务器通过它就能知道你想要什么,从而给你返回对应的内容。比如你在知乎搜索 python,网址会变成 https://www.zhihu.com/search?type=content&q=python,后面的查询字符串告诉服务器你想要的是有关 python 的内容,于是服务器便将有关 python 的内容返回给你了。
第二页 start=25,第三页 start=50,第十页 start=225,而每页的书籍数量是 25。你有没有发现其中的规律?


因为每页展示 25 本书,根据规律其实不难推测出 start 参数表示从第几本书开始展示,所以第一页 start 是 0,第二页 start 是 25,第三页 start 是 50,第十页 start 是 225。因此 start 的计算公式为 start = 25 * (页码数 - 1)(25 为每页展示的数量)。我们来通过代码自动生成豆瓣图书 Top250 所有数据(10 页)的地址:
url = 'https://book.douban.com/top250?start={}'
# num 从 0 开始因此不用再 -1
for num in range(10):
urls = url.format(num*25)
print(urls)
# 'https://book.douban.com/top250?start=0',
# 'https://book.douban.com/top250?start=25',
# 'https://book.douban.com/top250?start=50',
# 'https://book.douban.com/top250?start=75',
# 'https://book.douban.com/top250?start=100',
# 'https://book.douban.com/top250?start=125',
# 'https://book.douban.com/top250?start=150',
# 'https://book.douban.com/top250?start=175',
# 'https://book.douban.com/top250?start=200',
# 'https://book.douban.com/top250?start=225'有了所有网页的链接后,我们就可以爬取整个网站的数据了!我们来改进一下上一关中爬取豆瓣读书的代码:
import requests
import time
from bs4 import BeautifulSoup
# 将获取豆瓣读书数据的代码封装成函数
def get_douban_books(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'
}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
items = soup.find_all('div', class_='pl2')
for i in items:
tag = i.find('a')
name = tag['title']
link = tag['href']
print(name, link)
url = 'https://book.douban.com/top250?start={}'
for num in range(10):
urls = url.format(num*25)
get_douban_books(urls)
# 暂停 1 秒防止访问太快被封
time.sleep(1)
# 提示:最后的 time.sleep(1) 是防止访问太快被对方服务器封禁,封禁后会导致一段时间内无法再次访问该网站。虽然豆瓣图书的数据有 10 页,但每页数据的格式一样,因此爬取方式和爬虫代码也是一样的。所以,我将获取豆瓣读书数据的爬虫代码封装成函数,唯一会变的网页地址作为参数。再用 for 循环遍历所有的网页地址,依次传入封装好的 get_douban_books() 函数,这样即可实现整个网站的爬取了。
2. 反爬虫
上一节的代码最后,我们用了 time.sleep(1) 来减缓我们爬虫的爬取速度。你可能会问:爬虫不是越快越好吗?这样我们就能高效地获取大量数据了。
没错,这对我们来说是方便了,但网站的目的是给正常用户用浏览器访问的。如果我们过于频繁的爬取数据,很可能使网站服务器过载瘫痪,所以也就有了 反爬虫 措施。
反爬虫 是网站限制爬虫的一种策略。它并不是禁止爬虫(完全禁止爬虫几乎不可能,也可能误伤正常用户),而是限制爬虫,让爬虫在网站可接受的范围内爬取数据,不至于导致网站瘫痪无法运行。
常见的反爬虫方式有 判别身份 和 IP 限制 两种,我们一一介绍,并给出相应的反反爬虫技巧。
2.1 判别身份
有些网站在识别出爬虫后,会拒绝爬虫的访问,比如豆瓣。我们以豆瓣图书 Top250 为例,用浏览器打开是下面这样的:

如果用爬虫直接爬取它,我们看看结果会是什么:
import requests
res = requests.get('https://book.douban.com/top250')
print(res.text)输出结果为空,什么都没有。这是因为豆瓣将我们的爬虫识别了出来并拒绝提供内容。
其实,不管是浏览器还是爬虫,访问网站时都会带上一些信息用于身份识别。而这些信息都被存储在一个叫 请求头(request headers)的地方。
服务器会通过请求头里的信息来判别访问者的身份。请求头里的字段有很多,我们暂时只需了解 user-agent(用户代理)即可。user-agent 里包含了操作系统、浏览器类型、版本等信息,通过修改它我们就能成功地伪装成浏览器。

默认的 user-agent 和在头上贴着“我是爬虫”的纸条没有什么区别,难怪会被服务器识别出来。因此我们需要修改请求头里的 user-agent 字段内容,将爬虫伪装成浏览器。所以接下来我们来看看如何在 requests 库中修改请求头。
我们打开 requests 的官方文档(http://cn.python-requests.org/zh_CN/latest/)并搜索 定制请求头,找到对应的文档: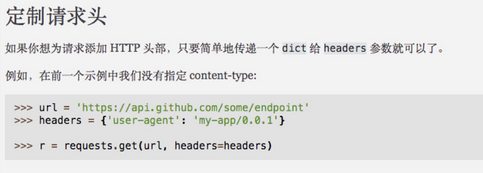
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'
}
res = requests.get('https://book.douban.com/top250',headers=headers)
print(res.text)这样就能搞定获取到数据咯。
除了 user-agent 之外的其他请求头字段也能以同样的方式添加进去,但大部分情况下我们只需要添加 user-agent 字段即可(有些甚至不需要)。当我们加了 user-agent 字段还是无法获取到数据时,说明该网站还通过别的信息来验证身份,我们可以将请求头里的字段都添加进去试试。
如果你访问过于频繁,即使改了 user-agent 伪装成浏览器了,也还是会被识别为爬虫,并限制你的 IP 访问该网站。
我们常常使用 time.sleep() 来降低访问的频率,这样,对网站服务器的压力不会太大,访问的低频率对方也就不理会我们的爬虫。虽然速度较慢,但也能获取到我们想要的数据了。
判别身份是最简单的一种反爬虫方式,我们也能通过一行代码,将爬虫伪装成浏览器轻易地绕过这个限制。所以,大部分网站还会进行 IP 限制 防止过于频繁的访问。
2.2 IP 限制
IP(Internet Protocol)全称互联网协议地址,意思是分配给用户上网使用的网际协议的设备的数字标签。你可以将 IP 地址理解为门牌号,我只要知道你家的门牌号就能找到你家。
我们打开官方文档,看看如何使用代理:
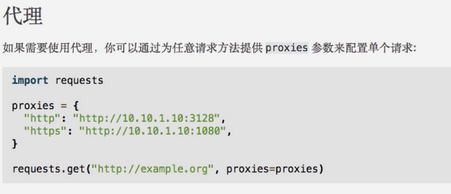
和 headers 一样,也是定义一个字典,但传递给的是 proxies 参数。我们需要将 http 和 https 这两种协议作为键,对应的 IP 代理作为值,最后将整个字典作为 proxies 参数传递给 requests.get() 方法即可。IP 代理有免费的和收费的,你可以自行在网上寻找。
分享一个自动获取免费IP的源代码,仅供参考:(原理是抓取页面免费的IP加以在百度测试)
# /usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import random
ip_list = []
def get_ip_list(url):
headers = {'User-Agent': 'Mozilla/5.0'}
res = requests.get(url, headers=headers)
bs = BeautifulSoup(res.text, 'html.parser')
results = bs.select('#ip_list tr')
for result in results[1:]:
ip = result.select('td')[1].text
port = result.select('td')[2].text
judge(ip, port)
def judge(ip, port):
proxy = {'http': ip+':'+port}
print('-' * 45)
print('正在测试 %s ' % proxy)
try:
print('-' * 45)
res = requests.get('https://www.baidu.com', proxies=proxy)
print('恭喜!%s:%s 测试通过!' % (ip, port))
except Exception:
print('IP:' + ip + '无效!')
return False
else:
if 200 <= res.status_code < 300:
ip_list.append((ip, port))
return True
else:
print('IP:' + ip + '无效!')
return False
def get_random_ip():
ip, port = random.choice(ip_list)
result = judge(ip, port)
if result:
return ip + ':' + port
else:
ip_list.remove((ip, port))
if __name__ == '__main__':
get_ip_list('https://www.xicidaili.com/wt/')
print('-' * 45)
for IP in ip_list: print(':'.join(IP))
print('-' * 35)
print('通过测试的 IP 总数:', len(ip_list))
print('-' * 35)
# ...
# 14.115.107.232:808
# 58.253.158.177:9999
# 112.84.73.53:9999
# 221.237.37.137:8118
# -----------------------------------
# 通过测试的 IP 总数: 100
#-----------------------------------
官方文档中给了代理的基本用法,但在爬取大量数据时我们需要很多的 IP 用于切换。因此,我们需要建立一个 IP 代理池(列表),每次从中随机选择一个传给 proxies 参数。我们来看一下如何实现:
import requests
import time,random
from bs4 import BeautifulSoup
# 将获取豆瓣读书数据的代码封装成函数
def get_douban_books(url,proxies):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'
}
res = requests.get(url, headers=headers,proxies=proxies)
soup = BeautifulSoup(res.text, 'html.parser')
items = soup.find_all('div', class_='pl2')
for i in items:
tag = i.find('a')
name = tag['title']
link = tag['href']
print(name, link)
url = 'https://book.douban.com/top250?start={}'
# IP 代理池(瞎写的并没有用)
proxies_list = [
{
"http": "http://221.237.37.137:8118",
"https": "http://112.84.73.53:9999",
},
{
"http": "http://58.253.158.177:9999",
"https": "http://14.115.107.232:808",
},
{
"http": "http://163.125.71.198:9999",
"https": "http://119.84.84.185:12345",
}
]
for num in range(10):
urls = url.format(num*25)
# 从 IP 代理池中随机选择一个
proxies = random.choice(proxies_list)
get_douban_books(urls, proxies)
# 暂停 1 秒防止访问太快被封
time.sleep(1)这样,我们就能既快速又不会被限制地爬取数据了。但毫无节制的爬虫已经和网络攻击没什么区别了,严重的甚至会导致网站瘫痪。恶意地大量访问别人的网站,消耗服务器资源是非常不道德、甚至违法的。
其实,除了反爬虫措施远不只这两种。比如验证码,当你的操作异常时网站经常会弹出验证码。验证码技术也在不断地升级,从原先简单的随机生成的数字字母,演变成随机汉字,再由按顺序点击图中对应的汉字演变成滑块拼图。
验证码的形式千千万万,破解起来也较为困难。我们本关不会涉及,等你入门爬虫后,再去专门攻克验证码也不迟。
练习题
同学们,先自觉练习,答案在公众号,公众号回复暗号【答案】即可。
1. 网站反爬虫时一般通过请求头里的什么字段来判别访问者的身份?
A.user-agent
B.content-type
C.cache-control
D.Access-Control-Allow-Origin2. 我们通过 requests.get() 的哪个参数可以定制请求头?
A.params
B.proxies
C.cookies
D.headers3. 反反爬虫的策略不包含下列哪项?
A.添加headers信息。
B.更换爬虫IP。
C.设置延迟爬虫sleep()。
D.反爬虫自己会好的。4. 我们以豆瓣图书 Top250 为例学会了爬取整个网站。接下来请你依葫芦画瓢,试着爬取豆瓣电影 Top250 的所有数据吧!豆瓣电影 Top250 的地址是:https://movie.douban.com/top250。
联系我们,一起学Python吧
每周每日,分享Python实战代码,入门资料,进阶资料,基础语法,爬虫,数据分析,web网站,机器学习,深度学习等等。
 微信群(关注「Python家庭」一起轻松学Python吧)
微信群(关注「Python家庭」一起轻松学Python吧)
 QQ 群(983031854)
QQ 群(983031854)
