文章目录
-
-
- Postgre/Gauss
-
-
-
- 字符串拼接:
- 数据类型转换:
- 当数字类型小于1时转换为字符类型后小数点前面的0不显示:
- coalesce函数:
- 随机数random()函数:
- 日期字段截取:
- 将字符串类型的数据“20200308191233”转换成时间格式并精确到秒:
- 将字符串类型的数据“20200308191233”转换成时间戳格式:
- 字符串截取函数:
- 分割函数:
- replace函数:
- 四舍五入、向上取整、向下取整:
- 取整取余:
- 前10行:
- 实现分页功能:
- not exists用法:
- like用法:
- 正则表达式:
- 转义字符:
- 日期加减:
- bbyf字段格式为“2019-11-01 00:00:00”,csrq(出生日期)字段格式也一样,计算年龄:
- 查询某个日期之前的数据(包括这个日期):
- 使用case when查如果两列不一致则赋个值的需求:
- decode函数:
- 把a表的数据插入到b表时id是以在b表最大id的基础上实现自增:
- 把查询的结果插入另一张表(该表不存在)的两种方式:
- update和select结合使用:
- 用户解锁:
- 删除用户:
- 创建用户并赋予密码:
- 创建数据库并使某用户拥有:
- 修改用户密码:
- 赋予用户所有权限:
- 查询都有什么用户:
- 查询都有什么数据库、库下有什么模式、模式下有什么表、表里什么字段:
- 创建schema:
- 判断某个schema是否存在:
- 创建主键并设置自动递增的三种方法:
- 创建临时表/with:
- 查询临时表属性:
- 查询库下的所有外表:
- 查看指定表、库大小:
- 查看所有表、外表、模式、数据库大小:
- 查看待删除涉及query_id、pid:
- 给列添加备注:
- 给表增加列:
- 索引:
- 在分区的基础上创建索引:
- 查看索引有没有生效:
- 表空间:
- \set用法:
- 将结果集输出到文件:
- 查看表信息:
- 存储过程:
- 查询数据慢效率低下优化语句:
- 数据迁移:
- Data Studio中单双引号的问题:
-
-
-
Postgre/Gauss
字符串拼接:
函数:concat('201911','01')
结果:2011101
数据类型转换:
函数:cast(month_id as timestamp)
注意:当month_id值为2011101时才可以转换为timestamp成功,即转换后值为2019-11-01 00:00:00,如果month_id值为20111时则转换失败
错误代码:[0][SQLErrorCode : 3295]ERROR: date/time field value out of range: "201911"
Hint: Perhaps you need a different "datestyle" setting.
当数字类型小于1时转换为字符类型后小数点前面的0不显示:
目前我也没有找到什么好的方法,只能用case when判断然后再进行拼接了
case
when left(cast(cast(q.jdyysr as numeric(14,4)) as text),1)='.' then concat('0',cast(cast(q.jdyysr as numeric(14,4)) as text))
else cast(cast(q.jdyysr as numeric(14,4)) as text)
end jdyysr
coalesce函数:
select coalesce(success_cnt, 1) from tableA;
解释:当success_cnt 为null值的时候,将返回1,否则将返回success_cnt的真实值。
备注:nvl和ifnull函数也有这个效果,但是经我测试只有coalesce函数在Postgre、SQLserver、mysql中都适用,nvl只在Postgre中可以使用,而ifnull只可以在mysql中使用
随机数random()函数:
--随机字母
select chr(int4(random()*26)+65);
--随机4位字母
select repeat(chr(int4(random()*26)+65),4);
--随机数字 十位不超过6的两位数
select (random()*(6^2))::integer;
--三位数
select (random()*(10^3))::integer;
日期字段截取:
to_char(jsrq,'yyyy')='2019'要比left(jsrq,4)='2019'速度快将近一倍
select count(1) from tpcds.gr_yljf_yzh where left(jsrq,4)='2019'; 用时1 mins, 41 sec
select count(1) from tpcds.gr_yljf_yzh where to_char(jsrq,'yyyy')='2019'; 用时50 sec
注:表中有107675358条数据,jsrq(结算日期)字段数据格式为“2019-11-01 00:00:00”
将字符串类型的数据“20200308191233”转换成时间格式并精确到秒:
select to_date('20200308191233');
结果:2020-03-08 19:12:33
注意:当有想把某一个字符类型字段转换成时间格式时发现该字段有为null的数据该如何办呢,直接转的话会报错the format is not correct!
解决:
select
case
when "合同结束日期" is null then to_date('')
else to_date(concat("合同结束日期",'000000'))
end htjsrq
from
tpcds.hehe;
将字符串类型的数据“20200308191233”转换成时间戳格式:
SELECT cast(EXTRACT(EPOCH FROM TIMESTAMP WITH TIME ZONE '2016-05-25 14:30:50.352')*1000 as character varying(14));
运行结果:1464157850352
SELECT cast(EXTRACT(EPOCH FROM TIMESTAMP WITH TIME ZONE '2016-05-25 14:30:50')*1000 as character varying(14));
运行结果(该结果和用java转换的结果一致):1464157850000
SELECT cast(EXTRACT(EPOCH FROM TIMESTAMP WITHOUT TIME ZONE '2016-05-25 14:30:50.352')*1000 as character varying(14));
运行结果:1464186650352
可以在该页面校验一下:https://tool.lu/timestamp/
业务语句:select cast(EXTRACT(epoch from cast(to_date(sqsj) as TIMESTAMP WITH TIME ZONE))*1000 as character varying(14)) from hehe.shbxhj_jcsj;
备注:sqsj字段的值格式为“20200309105222”
字符串截取函数:
select substr('2019-11-02',6,2);
select substring('2019-11-02',6,2);
备注:运行结果都为11,其中substr函数在gauss中可用,SQLserver中不可用
分割函数:
select split_part('8a59-e88177-ad5e70' ,'-', 3);
如果分割符数量不一样怎么办,这里就要计算分割符的数量了:
select split_part('8a59-e88177-ad5e70' ,'-', length(replace('8a59-e88177-ad5e70','-','--')) - length('8a59-e88177-ad5e70') + 1);
运行结果:ad5e70
replace函数:
问题:select '1294.00'/1000;
报错:ERROR: invalid input syntax for integer: "1294.00"
解决:select REPLACE('1294.00','.00','')/1000;
四舍五入、向上取整、向下取整:
round() 函数是四舍五入用,第一个参数是我们要被操作的数据,第二个参数是设置我们四舍五入之后小数点后显示几位。
如:round(12.555,2) 结果:12.56
向上取整:select ceiling(45.88); 结果:46
向下取整:select floor(45.99); 结果:45
取整取余:
取整:trunc(176/12)
结果:14
取余:mod(176,12)
结果:8
前10行:
SELECT * FROM shbxhjzt.shbxhj_jcsj order by dwdm limit 10;
或者:
SELECT * FROM shbxhjzt.shbxhj_jcsj order by dwdm fetch first 10 rows only;
备注:在SQLserver中只能用top,上面两种都不支持,同样gauss也不支持top用法
select top 10 * from [lf_jybtjcpg].[dbo].[code_hangyexingzhi];
注意:最好加上order by,要不每次结果不一样
补充:
1、SQL server的语法:
SELECT TOP number|percent column_name(s) FROM table_name;
例子:从表persons中选取前2行的数据;
SELECT TOP 2 * FROM persons;
从表persons中去前50%的 数据:
SELECT TOP 50 percent * from persons;
2、MySQL的语法:
SELECT column(s) FROM table_name LIMIT number;
例子:查看前5行数据:
SELECT * FROM persons LIMIT 5;
3、Oracle的语法:
SELECT * FROM table_name where ROWNUM<=number;
例子:查看前5行的数据:
SELECT * FROM persons where ROWNUM <=5;
实现分页功能:
select
*
from
(
select
row_number() over(order by ID asc) as rownumber,*
from
shbxhjzt_tmp.shbxhj_sqhjdwxx
where
sqsj>='2020-03-01' and sqsj<='2020-03-31'
) temp_row
where
rownumber>(4-1)*9 fetch first 9 rows only;
备注:修改where后面的值即可达到分页的功能,如第一页展现9条数据为rownumber>(1-1)*9,第二页为rownumber>(2-1)*9
not exists用法:
select
distinct dwdm
from
shbxhjzt.shbxhj_jcsj a
where
not exists (select 1 from shbxhjzt_tmp.shbxhj_jcsj_eight b where a.dwdm = b.dwdm)
and not exists (select 1 from shbxhjzt_tmp.shbxhj_jcsj_eighteen b where a.dwdm = b.dwdm);
select grid from tpcds.gr_xx_201912 a where exists (select sfzhm from mdl_ddpt_tmp.t_ryhx_zrrpj b where a.bzhm=b.sfzhm)
like用法:
select * from lsxgwbtzt.lsxgwbt_hmcryxx where sfzhm like '%X';
select * from lsxgwbtzt.lsxgwbt_hmcryxx where sfzhm not like '%X';
正则表达式:
说明:在postgresql中使用正则表达式时需要使用关键字“~”,以表示该关键字之前的内容需匹配之后的正则表达式,若匹配规则不需要区分大小写,可以使用组合关键字“~*”;
相反,若需要查询不匹配这则表达式的记录,只需在该关键字前加否定关键字“!”即可。若正则表达式包含转义字符,则需在表达式前加关键字“E”。
匹配email地址以A-H开头的记录:
select * from user where email ~ '^[A-H]';
过滤sfzhm字段不是身份证格式的数据:
select * from lsxgwbtzt.lsxgwbt_hmcryxx where sfzhm !~ '^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$';
转义字符:
在PostgreSQL 9之前的版本中,可以直接使用反斜杠\进行转义;比如:\b表示退格, \n表示换行, \t表示水平制表符,\r标示回车,\f表示换页。除此之外还支持\digits和\xhexdigits,分别表示转义八进制和十六进制数据。
但是在PostgreSQL 9之后的版本,反斜杠已经变成了普通字符;如果想要使用反斜杠来转义字符,就必须在需要转义的字符串前面加上E(E就是Escape),如下:select E'张\t小明';
对单引号的两种转义方式:
在SQL标准中字符串是用单引号括起来的,而在PostgreSQL中遵守了该标准,双引号则是用来表示变量的,如果在字符串中需要使用到单引号,就需要对其进行转义。
方式一:使用E和反斜杠进行转义select E'\'233';
方式二:直接用一个单引号来转义单引号select '''233';
这两种方式都能得到'233的结果而不会报错,第二种方式比较简单,也可以通过修改standard_conforming_strings参数的值来让反斜杠从普通字符变回转义字符:
show standard_conforming_strings;
SET standard_conforming_strings = on;
SET standard_conforming_strings = off;
当该参数的值为off时就可以直接使用反斜杠作为转义字符里,如下:select '\'233';
将会得到'233的结果而不会报错。
来自:https://www.cnblogs.com/yulinlewis/p/9471721.html
注意:在实践中遇到这么个神奇的问题,在gsql里执行这两条语句都没问题,但是在datastudio或者代码中运行则会一条失败一条成功。
失败:
insert into tpcds.hehe(t1,t2,t3,t4,t5,t6,t7,t8,t9,t10,t11,t12,t13,t14,t15,t16,t17,t18,t19,t20,t21,t22,t23,t24,t25,t26,t27,t28,t29,t30,t31) VALUES
('123456','123456','123456','null','123456','123456','1','123456','01','40','1','123456','9','null','0','null','null','null','null','1','小城村\','123456','123456','null','0','null','13521390418','null','null','1','20');
成功:
insert into tpcds.hehe(t2,t3,t4,t5,t6,t7,t8,t9,t10,t11,t12,t13,t14,t15,t16,t17,t18,t19,t20,t21,t22,t23,t24,t25,t26,t27,t28,t29,t30) VALUES
('123456','123456','null','123456','123456','1','123456','01','40','1','123456','9','null','0','null','null','null','null','1','小城村\','123456','123456','null','0','null','13521390418','null','null','1');
失败:
insert into tpcds.hehe(t21,t22,t23,t24,t25,t26,t27,t28,t29,t30,t31) VALUES
(E'小城村\','123456','123456','null','0','null','13521390418','null','null','1','20');
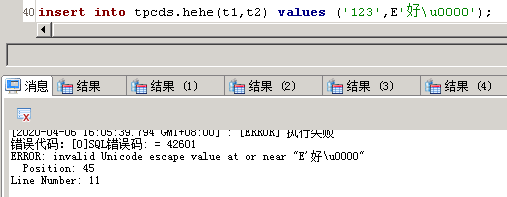
整了半天咋也不知道啥原因,后来改变了思路,可以成功了,就是把反斜杠替换成反斜杠的Unicode码插入则不会报错了。即
insert into tpcds.hehe(t1,t2,t3,t4,t5,t6,t7,t8,t9,t10,t11,t12,t13,t14,t15,t16,t17,t18,t19,t20,t21,t22,t23,t24,t25,t26,t27,t28,t29,t30,t31) VALUES
('123456','123456','123456','null','123456','123456','1','123456','01','40','1','123456','9','null','0','null','null','null','null','1',E'小城村\u005c','123456','123456','null','0','null','13521390418','null','null','1','20');
提供两个转码工具的连接:http://www.bejson.com/ 和 https://www.sojson.com/ascii.html(让这个网站搞蒙了,在里面输入“\”,然后点击字符转换ASCII会生成结果“\u005c”,但前一个网站输入“\u005c”再点击“unicode转中文”生成结果为“\”,那么\u005c到底是Unicode码还是ASCII码呢?有知道的网友可以留下言)
注意:转换成Unicode码插的时候目前测出有两个是无法插入的,一个是\ufeff(还有\ufffd,但是gauss新集群这两个可以插入了,但后面那个还是不行),另一个是\u0000,但是\u0001就可以。(没测试过开源的Postgre数据库有没有这个问题)
日期加减:
postgres=# select sysdate;
sysdate
---------------------
2020-02-12 14:03:25
(1 row)
相加:
postgres=# select sysdate + '2 month';
?column?
---------------------
2020-04-12 14:03:44
(1 row)
相减:
postgres=# select concat(to_char(sysdate + '-2 month','yyyymm'),'01');
concat
----------
20191201
(1 row)
bbyf字段格式为“2019-11-01 00:00:00”,csrq(出生日期)字段格式也一样,计算年龄:
cast((date_part('year',age(sysdate,csrq))*12+date_part('month',age(sysdate,csrq)))/12 as int) nlid
查询某个日期之前的数据(包括这个日期):
select grid,csrq from sdp_jcsj.t_gaj_jc_hujirenkouxinxi_tmp where age(csrq,'1981-02-03')<=0;
使用case when查如果两列不一致则赋个值的需求:
select case when sbkh=jydjh then '12472904100S' else '112' end hehe from sdp_jsc.t_ywdt_sbkjsjk;
而不能写成(报错,语法不对):select case sbkh when sbkh=jydjh then '12472904100S' else '112' end hehe from sdp_jsc.t_ywdt_sbkjsjk;
对的语法:select case sbkh when '12472904100S' then '12472904100S' else '112' end hehe from sdp_jsc.t_ywdt_sbkjsjk;
decode函数:
decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
注:Oracle的DECODE函数功能很强,灵活运用的话可以避免多次扫描,从而提高查询的性能。而CASE是9i以后提供的语法,这个语法更加的灵活,提供了IF THEN ELSE的功能。目前测试DECODE函数gauss中也适用
把a表的数据插入到b表时id是以在b表最大id的基础上实现自增:
INSERT INTO gc_shiyefeirenyuan
(id
,tjrq
,dwid
,sbqncszrs
,btje
,sqxzqhdm
,rdqylx)
SELECT row_number() over(order by bbny) + t2.sk_max,bbny
,dwid
,sbqncszrs
,btje
,sqxzqhdm
,rdqylx
FROM y_shiyebaoxianfeiyongkuanjihua
cross join (select coalesce(max(gc_shiyefeirenyuan.id),0) sk_max from gc_shiyefeirenyuan) t2
where bbny='201906' and if(btje is null,0,btje)>0;
把查询的结果插入另一张表(该表不存在)的两种方式:
(1)select * into hehe from haha;
(2)create table hehe as select * from haha;
注:sqlserver数据库只能用方法(1),方法(2)用不了
update和select结合使用:
UPDATE table1 t1
SET column1 = t2.columnname1,
column2 = t2.columnname2
FROM (select columnname1,columnname2,columnname3 from table2) t2
WHERE t1.column3 = t2.columnname3
AND t1.column = '111';
用户解锁:
ALTER USER jack ACCOUNT UNLOCK;
删除用户:
DROP USER jack CASCADE;
注:如果用该用户执行了插入数据等则上述命令将不能执行成功,即不能删除有数据的用户(我当时是用Jack用户执行了GaussDBTest.jar创建customer_t1并插入了数据,将这个表删除之后就可以将该用户删除了)
postgres=# drop user jack;
ERROR: role "jack" cannot be dropped because some objects depend on it
DETAIL: 1 object in database hwbase
创建用户并赋予密码:
CREATE USER hui PASSWORD 'hehe';
创建数据库并使某用户拥有:
create database hui owner hui;或者CREATE DATABASE hui WITH OWNER=hui;
GRANT CONNECT ON DATABASE hui TO hui;
修改用户密码:
alter user jack identified by "heheda";
注:密码不能复用
赋予用户所有权限:
GRANT ALL PRIVILEGES TO hui;
查询都有什么用户:
SELECT * FROM PG_TOTAL_USER_RESOURCE_INFO;
查询都有什么数据库、库下有什么模式、模式下有什么表、表里什么字段:
查询都有什么库(相当与mysql的show databases):select datname from pg_database;
查询库下有什么模式:SELECT table_catalog,table_schema FROM information_schema.columns where table_catalog='db_perfect' group by table_catalog,table_schema;
查询模式下有什么表(相当于mysql的show tables):SELECT table_name FROM information_schema.tables WHERE table_schema = 'public';或者select tablename from pg_tables where schemaname='public';
查询表里有什么字段(相当与mysql的describe table_name):SELECT column_name FROM information_schema.columns WHERE table_name ='code_jntspxgz' and table_catalog='db_perfect' and table_schema='sdp_jcsj';
创建schema:
CREATE SCHEMA wuxian_shiye;
删除模式:
DROP SCHEMA [ IF EXISTS ] schema_name;
判断某个schema是否存在:
SELECT EXISTS(SELECT 1 FROM information_schema.schemata WHERE schema_name = 'sjhj');
SELECT EXISTS(SELECT 1 FROM pg_namespace WHERE nspname = 'sjhj');
两种方式都可以,第二个更有效率一些。
创建主键并设置自动递增的三种方法:
来自:http://francs3.blog.163.com/blog/static/40576727201111715035318/
方法一:
create table test_a
(
id serial,
name character varying(128),
constraint pk_test_a_id primary key( id)
);
方法二:
create table test_b
(
id serial PRIMARY KEY,
name character varying(128)
);
方法三:
create table test_c
(
id integer PRIMARY KEY,
name character varying(128)
);
CREATE SEQUENCE test_c_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
alter table test_c alter column id set default nextval('test_c_id_seq');
很明显从上面可以看出,方法一和方法二只是写法不同,实质上主键都通过使用 serial 类型来实现的,使用serial类型,PG会自动创建一个序列给主键用,当插入表数据时如果不指定ID,则ID会默认使用序列的NEXT值。
方法三是先创建一张表,再创建一个序列,然后将表主键ID的默认值设置成这个序列的NEXT值。这种写法似乎更符合人们的思维习惯,也便于管理,如果系统遇到sequence 性能问题时,便于调整 sequence 属性;
三个表表结构一模一样, 三种方法如果要寻找差别,可能仅有以下一点,当 drop 表时,方法一和方法二会自动地将序列也 drop 掉, 而方法三不会。
创建临时表/with:
-- 创建之前先看有没有该表,有则删除
drop table if exists temp1 ;
注:该判断表不存在则删除的方法目前测试Gauss和MySQL里是可以这样做的,但是oracle是不行的
create TEMPORARY table temp1 as select * from tpcds.heheda;
其实用with效率更高也更好维护:
with
hehe as
(select * from qie.haha)
select
bbyf
from
hehe ;
查询临时表属性:
select * from pg_catalog."pg_class" where relname = 'temp1';
查询库下的所有外表:
select oid,* from pg_class where oid in (select ftrelid from pg_foreign_table);
查看指定表、库大小:
指定表:
select pg_size_pretty(pg_table_size('tpcds."事_单位信息"'));
指定库
select pg_size_pretty(pg_database_size('postgres'));
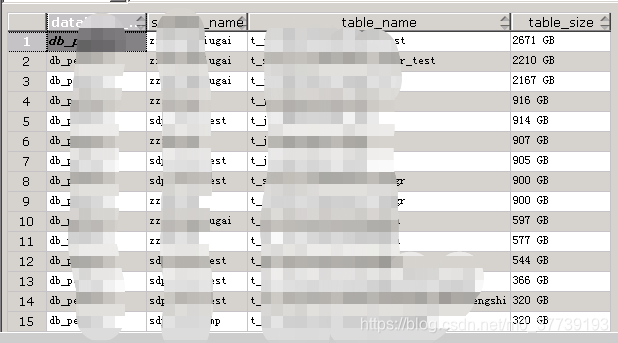
查看所有表、外表、模式、数据库大小:
所有库:
select pg_database.datname, pg_size_pretty(pg_database_size(pg_database.datname)) AS size from pg_database;
查询结果:
template1 88 MB
hwbase 621 GB
wuxian 95 GB
template0 88 MB
postgres 102 MB
所有表:
SELECT
table_catalog AS database_name,
table_schema AS schema_name,
table_name,
pg_size_pretty(relation_size) AS table_size
FROM (
SELECT
table_catalog,
table_schema,
table_name,
pg_total_relation_size(('"' || table_schema || '"."' || table_name || '"')) AS relation_size
FROM information_schema.tables
WHERE table_schema not in ('pg_catalog', 'public', 'public_rb', 'topology', 'tiger', 'tiger_data', 'information_schema')
ORDER BY relation_size DESC
)
AS all_tables
WHERE relation_size >= 1073741824;
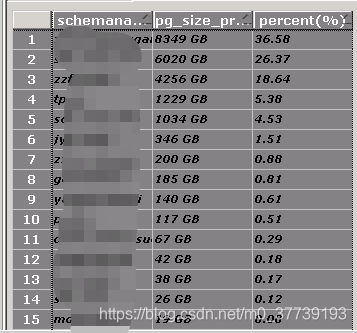
所有模式:
select
schemaname,
pg_size_pretty(cast(sum(pg_relation_size(schemaname||'.'||tablename))as bigint)),
round((sum(pg_relation_size(schemaname||'.'||tablename)) / pg_database_size(current_database())) * 100,2) as "percent(%)"
from
pg_tables t
inner join
pg_namespace d
on
t.schemaname=d.nspname
group by
schemaname
order by
"percent(%)" desc;
后来在两个gauss集群上分别执行上面这个语句,一个报错(报错这个以前也可以执行成功的但是现在不行了)一个不报错也是神奇。

原因:因为访问到了临时表造成的,这种情况下可以把临时表排除在外。
解决:GaussDB 200的临时表都是放在一个特定的schema下面的,以pg_temp开头命名的。因此可以在where条件中加d.nspname not like ‘pg_temp%’ 来过滤。
所有外表:
select
n.nspname as "Schema",
b.relname
from PG_FOREIGN_TABLE a
left join pg_class b
on a.ftrelid=b.oid
left outer join pg_catalog.pg_namespace n
on n.oid = b.relnamespace
order by b.relname;
查看待删除涉及query_id、pid:
Select query,query_id,pid from pg_stat_activity where query like '%faren_heheda_20191115_ext%';
select PG_TERMINATE_BACKEND(140585035888384); --杀死进程
select datname,current_timestamp-query_start,enqueue,query from pgxc_stat_activity where state = 'active' and usename <> 'omm' order by 1 desc; --排查问题可以用到这条语句
给列添加备注:
comment on column sdp_jsc_test.cbfbqk.rq is '创建日期';
给表增加列:
alter table tmp1 add xzqmc varchar(50);
索引:
--查询索引
select * from pg_indexes where tablename='t_source_dwxx';
--创建索引
create index t_source_dwxx_index on ycxjycyfwbt.t_source_dwxx(dwid);
--删除索引
drop index ycxjycyfwbt.t_source_dwxx_index;
在分区的基础上创建索引:
创建分区表:
CREATE TABLE heheda.t_jc_xiaoqiang
(
dwid character varying(50),
lsgxid character varying(10),
bbyf character varying(50),
ylcbzt character varying(10)
)
TABLESPACE huihui1
DISTRIBUTE BY HASH (bbyf)
PARTITION BY RANGE (bbyf)
(
PARTITION P21 VALUES LESS THAN(201910),
PARTITION P22 VALUES LESS THAN(201911),
PARTITION P23 VALUES LESS THAN(201912),
PARTITION P24 VALUES LESS THAN(202001),
PARTITION P25 VALUES LESS THAN(202002),
PARTITION P26 VALUES LESS THAN(202003),
PARTITION P27 VALUES LESS THAN(MAXVALUE) TABLESPACE huihui2
)
ENABLE ROW MOVEMENT;
创建索引:
CREATE INDEX t_jc_xiaoqiang_tmp_hydm_index ON heheda.t_jc_xiaoqiang USING btree (hydm) TABLESPACE pg_default;
报错:partitioned table does not support global index
解决:
CREATE INDEX t_jc_xiaoqiang_tmp_hydm_index ON heheda.t_jc_xiaoqiang(hydm) LOCAL
(
PARTITION t_jc_xiaoqiang_tmp_p2_P21_index,
PARTITION t_jc_xiaoqiang_tmp_p2_P22_index,
PARTITION t_jc_xiaoqiang_tmp_p2_P23_index,
PARTITION t_jc_xiaoqiang_tmp_p2_P24_index,
PARTITION t_jc_xiaoqiang_tmp_p2_P25_index,
PARTITION t_jc_xiaoqiang_tmp_p2_P26_index,
PARTITION t_jc_xiaoqiang_tmp_p2_P27_index
) TABLESPACE huihui1;
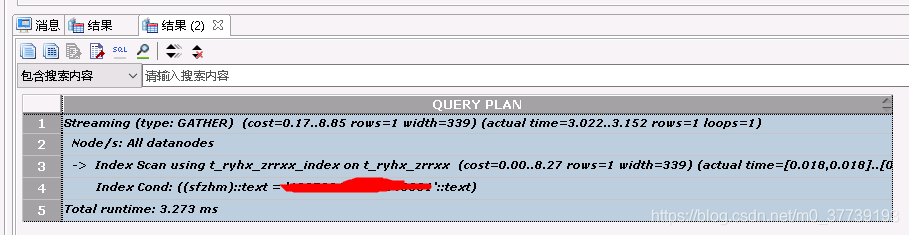
查看索引有没有生效:
explain analyze select * from heheda.haha where sfzhm='110';
或者
explain performance select * from heheda.haha where sfzhm='110';
注:
EXPLAIN PERFORMANCE statement:生成执行计划,进行执行,并显示执行期间的全部信息。
EXPLAIN ANALYZE statement:生成执行计划,进行执行,并显示执行的概要信息。显示中加入了实际的运行时间统计,包括在每个规划节点内部花掉的总时间(以毫秒计)和它实际返回的行数。
注意:执行这个命令可能出不来index,得先执行该命令set enable_fast_query_shipping=off;
每加该条命令之前执行explain analyze命令:

之后:
表空间:
--创建表空间
CREATE TABLESPACE huihui1 RELATIVE LOCATION 'tablespace1/huihui1';
--查询都有什么表空间
SELECT * FROM pg_tablespace;
--删除表空间
DROP TABLESPACE huihui1;
\set用法:
postgres=# \set monthid1 20191001
或者:
postgres=# \set monthid1 '20191001'
postgres=# select :'monthid1';
?column?
----------
20191001
(1 row)
postgres=# select :monthid1;
?column?
----------
20191001
(1 row)
postgres=# \set monthid1 'select 20191001'
或者:
postgres=# \set monthid1 'select '20191001''
postgres=# :monthid1;
?column?
----------
20191001
(1 row)
postgres=# (:monthid1);
?column?
----------
20191001
(1 row)
postgres=# create TEMPORARY table month_table as select concat(to_char(sysdate + '-2 month','yyyymm'),'01') rq;
NOTICE: The 'DISTRIBUTE BY' clause is not specified. Using 'rq' as the distribution column by default.
HINT: Please use 'DISTRIBUTE BY' clause to specify suitable data distribution column.
INSERT 0 1
postgres=# \set monthid1 'select rq from month_table'
postgres=# select rq from month_table where rq=(:monthid1);
rq
----------
20191201
(1 row)
将结果集输出到文件:
postgres=# \o out.txt;
postgres=# select '123';
postgres=# select '234';
然后退出该对话执行vi out.txt
?column?
----------
123
(1 row)
?column?
----------
234
(1 row)
查看表信息:
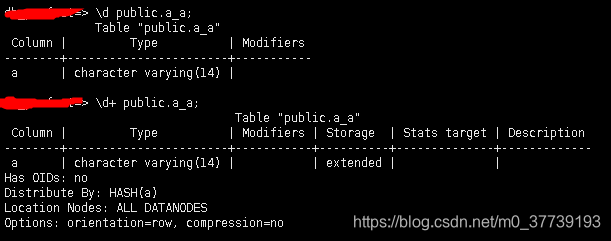
存储过程:
CREATE OR REPLACE PROCEDURE proc_control_structure(i in integer,y out integer)
AS
BEGIN
y := 2;
IF i > 0 THEN
raise info 'i:% is greater than 0. ',y;
ELSIF i < 0 THEN
raise info 'i:% is smaller than 0. ',y;
ELSE
raise info 'i:% is equal to 0. ',y;
END IF;
RETURN;
END;
/
CALL proc_control_structure(3,5);
2
消息栏:
[2020-02-25 17:13:40.156 GMT+08:00] : [NOTICE] i:2 is greater than 0.
CREATE OR REPLACE PROCEDURE proc_control_structure()
AS
declare
i integer := 3;
y integer;
BEGIN
y := 2;
IF i > 0 THEN
raise info 'i:% is greater than 0. ',y;
ELSIF i < 0 THEN
raise info 'i:% is smaller than 0. ',y;
ELSE
raise info 'i:% is equal to 0. ',y;
END IF;
RETURN;
END;
/
CALL proc_control_structure();
结果为空白
消息栏:
[2020-02-25 17:55:33.002 GMT+08:00] : [INFO] 操作影响的记录行数 : 1
[2020-02-25 17:55:33.002 GMT+08:00] : [INFO] 执行时间 : 11 ms
[2020-02-25 17:55:33.002 GMT+08:00] : [INFO] 执行成功...
[2020-02-25 17:55:33.155 GMT+08:00] : [NOTICE] i:2 is greater than 0.
查询数据慢效率低下优化语句:
vacuum full; //清理脏数据。增删操作会产生脏数据,空间碎片,这个操作就是进行清理
analyze; //分析表结构

vacuum full执行之后对磁盘释放很明显:执行之前基本都到百分之八十了,执行之后能达到百分之六十左右

可参考:https://blog.csdn.net/pg_hgdb/article/details/79490875
数据迁移:
导整个模式:
先生成dmp文件:gs_dump -W heheda -U xiaoqiang -f /srv/BigData/mppdb/data3/tmpfiles/shbxhjzt.dmp -p 25308 db_perfect -n shbxhjzt -F c
还原整个模式:gs_restore -W heheda -U xiaoqiang /mnt/shbxhjzt.dmp -p 25308 -d "DB_LSZTK"
只导一张表:
先生成dmp文件:gs_dump -W heheda -U xiaoqiang -f zzfx_tmp-t_jc_danweixinxi.dmp -p 25308 db_perfect -F c -t zzfx_tmp.t_jc_danweixinxi
还原该张表:gs_restore -j 5 -h 172.1.1.1 -W heheda -U xiaoqiang zzfx_ydy-t_jc_danweixinxi.dmp -p 25308 -d "DB_ZTK"
使用gds方式:
db_perfect=> copy tpcds.gaj_hujirenyuandengji20200319 to '/srv/BigData/mppdb/data3/dmpfiles/gaj_hujirenyuandengji20200319.csv' with csv header;
COPY 14013288
DROP FOREIGN TABLE IF EXISTS tpcds.gaj_hujirenyuandengji20200319_ext;
CREATE FOREIGN TABLE tpcds.gaj_hujirenyuandengji20200319_ext (like tpcds.gaj_hujirenyuandengji20200319)
SERVER gsmpp_server OPTIONS
(LOCATION 'gsfs://172.110.110.110:8090/gaj_hujirenyuandengji20200319_ceshi.csv',
FORMAT 'CSV',DELIMITER ',',ENCODING 'utf8',HEADER 'true')
READ ONLY;
INSERT INTO tpcds.gaj_hujirenyuandengji20200319 SELECT * FROM tpcds.gaj_hujirenyuandengji20200319_ext ;
Data Studio中单双引号的问题:
(1)表名只能用双引号或者什么也不加,而绝对不能用单引号
(2)列名的别称可以用双引号或者什么也不加,而绝对不能用单引号
(3)coalesce函数中的参数如果是字符型且不是列名则只能用单引号,如coalesce(b.行政区域描述_合,‘合计’) as “行政区域” 写成 coalesce(b.行政区域描述_合,合计) as "行政区域"则会报错
(4)列名单双引号或者不加都可以