目录
背景
寒假想当兼职老师却遇到了我不能决定的问题,出师未捷却要先行作罢,无奈只好继续写博客打发时间。。。这是cuda10.0最佳实践的下半部分,内容比前七章要多一些
评价标准
当尝试去优化cuda代码时,我们应该去了解如何准确地测量性能,以及带宽在性能测量中起到的作用。这一章讨论了如何使用cpu计时器和cuda时间来正确测量性能,并且揭示了带宽对性能测量的影响,以及如何缓解出现的问题。
计时器
cuda调用和核的执行时长可以通过CPU或GPU的计时器来统计,这一节检测了两者的功能性及优劣
CPU计时器
任何CPU计时器都可以被用来测量cuda调用和核的执行时长。各种各样的CPU计时方法细节不在本文讨论范围之内,但是开发者应该对他们使用的计时方法的精确度做到心中有数。
当使用CPU计时器时,要知道很多cuda的api函数都是异步的,也就是说它们在完成自己的工作之前就把控制权返还给了调用它的CPU线程。所有的核也是异步启动的,因为很多内存复制函数的名字都有Async后缀,所以为了准确测量某一个或者一系列cuda调用的执行时间,我们就有必要在开启和结束CPU计时器之前通过调用cudaDeviceSynchronize()函数将CPU线程和GPU线程进行同步,这个函数可以阻塞CPU线程,直到此线程调用的所有cuda函数都已经完成。
尽管我们可以让CPU线程和GPU线程在特定的流或者事件上保持同步,但这种同步并不适用于流中的计时器代码段(默认流除外)。cudaStreamSyncronize()函数会阻塞CPU线程,直到指定流调用的cuda函数都已经完成;而cudaEventSynchronize()函数的释放时机则是某个流的特定事件已经被GPU记录。由于驱动可能会梅花间竹地执行被其他非默认流调用的cuda函数,因此别的流可能也会被纳入到计时之中。
这些计时函数可以在默认流上可靠运行,因为默认流(流0)在设备上的工作表现为串行执行。
注意这里的CPU-GPU同步会导致GPU处理过程的暂停,因此应该减少同步的使用,尽量减少对性能的影响
GPU计时器
cuda事件API提供了创建事件、销毁事件、通过时间戳记录事件、将时间戳的差转换成浮点数的毫秒间隔。这些API的用法如下
cudaEvent_t start, stop;
float time;
cudaEventCreate(&start);
cudaEventCreate(&destroy);
cudaEventRecord(start, 0);
kernel<<grid, threads>>(d_odata, d_idata, size_x, size_y, num_reps);
cudaEventRecord(stop, 0);
cudaEventSyncronzie(stop);
cudaEventElapsedTime(&time, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);这里的cudaEventRecord()函数用来把事件start和stop放到默认流中,当GPU在流中遇到了这个时间,它会为事件记录一个时间戳。cudaEventElapsedTime()函数返回start和stop事件之间的消耗时间,这个值的单位为毫秒,精确度大约为半微秒。这段代码中函数的功能、参数列表和返回值在CUDA ToolKit Reference Manual中有所记载。另外,由于这些时间是在GPU时钟上测量的,所以其精确度与平台无关
带宽
带宽——数据传输速率——是最重要的性能指标之一,几乎所有的代码修改都要考虑它对带宽的影响。正如在内存优化一章中所述,选择数据在哪块内存中存储、数据如何表示以及获取数据的顺序等因素都会对带宽带来巨大影响。
为了准确衡量性能,计算理论和有效带宽对我们有所帮助。当后者小于前者时,程序设计可能就抑制了带宽,那么随后的主打任务可能就是对其进行优化。
理论带宽计算
我们可以通过产品文献中可用的硬件规范来计算理论带宽。例如,NVIDIA Tesla M2090使用GDDR5(双倍数据率)内存,其时钟速率为1.85GHz,内存接口为384位,那么这种显卡的理论带宽就是(1.85 * 10^9 * (384 / 8 ) * 2) / 10^9 = 177.6GB/s,这个计算过程中,时钟速率的单位被转换成了Hz,乘上内存接口位数(除以8是为了把位转换成字节),最后除以10^9是为了把结果转换成GB/s
有效带宽计算
有效带宽是通过计时具体的程序活动、了解数据传给程序的方式计算的,公式为:有效带宽 = ((Br + Bw) / 10^9) / time,单位为GB/s,其中Br是每个核读取的字节数,Bw是每个核写入的字节数,time的单位为秒。例如,计算一个2048 * 2048浮点矩阵复制的有效带宽时,上面的公式就被具体化为有效带宽 = ((2048^2 * 4 * 2) / 10^9) / time,2048取平方得到元素总数,乘4是因为一个浮点数占四个字节,乘2是因为读写数据量一样,除以10^9是为了把单位从字节转换成千兆字节,最后的结果除以time就得到了以GB/s为单位的数据有效传输速率。
注意以上两个带宽计算时千兆向字节转换用的进制为1000,也可以用1024,但必须要统一,也就是不能一个用1024,一个用1000,这样比较将没有意义。
通过Visual Profiler得到吞吐量报告
对于计算能力>=2.0的设备来说,可以通过Visual Profiler来收集不同内存吞吐量的测量结果。在Details 或者Details Graphs视图中可以被展示的吞吐量指标有:全局读取吞吐量要求、全局存储吞吐量要求、全局读取吞吐量、全局存储吞吐量、内存读吞吐量和内存写吞吐量。全局读取和存储吞吐量要求是核要求的全局吞吐量,这个可以通过有效带宽计算公式来计算得到,不过实际指标的值要略大于计算结果,因为核对内存吞吐的要求可以包含一些对不被其使用的数据的迁移;而实际的全局内存访问吞吐量表示为全局读取和存储吞吐量。
所有这些指标都是有用的,实际内存吞吐显示了代码性能和硬件限制之间的差距,有效带宽或需求带宽和实际带宽的比较结果可以有效评估有多少带宽被次优的内存联合访问方法浪费了,对于全局内存访问而言。这种比较结果可以通过比较全局内存读取和加载效率指标得到。
内存优化
内存优化是性能提升中最重要的部分,其目的是通过最大化带宽来提高硬件的利用率,而尽可能多地使用快内存、少使用低效访问方法可以显著提高带宽。这一章讨论了主机和设备内存的不同,以及如何优化数据设置来高效使用内存。
主机和设备之间的数据传输
显存和GPU之间的理论传输带宽峰值是很高的(例如我们算过,在英伟达Tesla M2090显卡上为177.6GB/s),远远超过内存和显存之间的理论传输带宽峰值(PCIe x16 Gen2上为8GB/s),因此为了达到整体的最佳性能,我们应该尽量减少主机内存与设备内存之间的数据传输,即便核函数在GPU上的运行速率不比在CPU上的快多少。
中间数据结构应该在设备上被创建、操作和销毁,切忌被映射或者复制到主机上。另外,因此每次传输都有性能损耗,所以把很多小批量传输合并成一个大批量传输会比一次次单独执行小批量传输有着更好的性能,即便这样可能会导致把不连续的内存区域封装成一块连续的缓存并在传输之后进行拆封。
最后,使用锁页内存(也称为钉内存)可以提高主机和设备之间的带宽,这在CUDA C Programming Guide中有所记载,下面也会进行讲述
钉内存
锁页内存或者钉内存迁移可以得到最高的主机设备间的带宽,例如在PCIe x16 Gen2显卡上,钉内存可以得到大约6GB/s的传输效率。
钉内存可以通过调用cudaHostAlloc()函数分配,在cuda官方样例中展示了这些函数的用法以及测量内存迁移性能的方法。关于官方样例的查看、编译和运行,可以先执行/usr/local/cuda-10.0/bin/cuda-install-samples-10.0.sh脚本将样例复制到指定文件夹中,然后进入目录编译即可
root@rtlab-computer:/home/rtlab/szc/cudaTest/NVIDIA_CUDA-10.0_Samples/1_Utilities# cd bandwidthTest/ # 源码就在此目录下,名为bandwidthTest.cu
root@rtlab-computer:/home/rtlab/szc/cudaTest/NVIDIA_CUDA-10.0_Samples/1_Utilities/bandwidthTest# make而后运行就可以了
root@rtlab-computer:/home/rtlab/szc/cudaTest/NVIDIA_CUDA-10.0_Samples/1_Utilities/bandwidthTest# cd ../../bin/x86_64/linux/release
root@rtlab-computer:/home/rtlab/szc/cudaTest/NVIDIA_CUDA-10.0_Samples/bin/x86_64/linux/release# ./bandwidthTest
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: GeForce GTX 1070 Ti
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 2970.0
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 3206.6
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 193296.9
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
root@rtlab-computer:/home/rtlab/szc/cudaTest/NVIDIA_CUDA-10.0_Samples/bin/x86_64/linux/release# 对于已经被提前加载的系统内存,我们可以调用cudaHostRegister()函数把内存就地钉住,而不用另开辟一块内存并复制数据。
钉内存不应该被过度使用,因为它是稀有资源,但是要使用多少是很难被提前知晓的。而且,系统钉内存的分配比普通内存的分配更加耗时,因此和其他优化方法一样,钉内存应该被用来测试应用和系统以获得最优参数
异步迁移
使用cudaMemcpy()函数进行的主机和设备间的数据迁移是阻塞迁移,也就是说只有当数据迁移完成后,控制权才能被返回给主机线程。而cudaMemcpyAsync()函数则是cudaMemcpy()的非阻塞变种,它会立刻返回到主线程中。另外,cudaMemcpyAsync()函数需要主机的钉内存,以及一个额外的参数——流id。流就是在设备上执行的操作序列,不同的流中的操作可以交叉进行,有时又是可以重叠的——这是一个用来隐藏主机和设备之间数据传输的参数。
异步传输在两方面支持了数据传输和计算的同时进行。在所有支持cuda的设备上,用异步数据传输可以并行化主机计算和并行计算,例如下一节会证明在数据传输给设备时,主机计算在函数cpuFuntion()中是如何执行的,以及使用设备的核函数是如何执行的。
计算与迁移的重叠
先看以下代码:
cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, 0);
kernel<<<grid, block>>>(a_d);
cpuFunction();cudaMemcpyAsync()函数的最后一个参数就是流id,这里是0号流也就是默认流。核函数使用的也是默认流,也就是它会等到内存复制完成后才开始执行,但这种阻塞发生在GPU中,因为a_d存储在显存中。因此,不用使用显式的同步。因为内存复制和核函数都会立刻返回,因此主机函数cpuFunction()会和它们并行执行。所以,内存复制和核函数串行执行,在支持并行复制和计算的设备中,将设备上核函数的执行与主机设备间的数据传输并行处理是可能的,而设备是否支持这种操作由cudaDeviceProp结构体中的asyncEngineCount字段指定(或者也可以查看cuda例子中deviceQuery的输出结果)。如果设备支持,那么这种并行会要求主机的钉内存,并且数据迁移和核函数必须执行在不同的非默认流上(也就是流id非0),使用非默认流是因为使用默认流上的内存复制、内存设置函数和核函数只有在设备上所有流的所有前置调用完成后才能进行,而且它们执行时,设备上不能执行任何流的任何操作,也就是默认流操作时独占显卡的。
并行复制与执行
请看以下代码:
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, stream1);
kernel<<<grid, block, 0, stream2>>>(otherData, 0);在这段代码中,两条流被创建,然后被用来做数据传输和执行核函数,如cudaMemcpyAync()和kernel()的最后一个参数和最后一个泛型所示,这就是将数据传输与核函数执行并行的方法。当数据可以被分成块、以多个阶段传输,并且在每块数据到达后需要启动多个核函数时,我们可以使用这个技术。串行复制与执行、阶段化并行复制与执行也演示了这一点,这三者会产生相同的结果。我们来说一下后两者
串行复制与执行
请看以下代码:
cudaMemcpy(a_d, a_h, N * sizeof(float), dir);
kernel<<<N / nThreads, nThreads>>>(a_d);上面这段代码就是串行复制与执行的参考,它传输并在长度为N的浮点数组上执行核函数,这N个浮点数被nThreads个线程均分
阶段化并行复制与执行
请看以下代码:
size = N * sizeof(float) / nStreams;
for (int i = 0; i < nStreams; i++) {
offset = i * N / nStreams;
cudaMemcpyAsync(a_d + offset, a_h + offset, size, dir, stream[i]);
kernel<<<N / (nThreads * nStreams), nThreads, 0, stream[i]>>>(a_d + offset);
}在上面的代码中,N个浮点数被nStreams个流的nThreads个线程均分。因为一个流中的执行是串行的,所以每个核函数都要等待其对应流中的数据传输完成后才会启动。现在的GPU可以同时执行异步的数据传输和核函数。有一个复制引擎的GPU可以同时执行核函数和一个异步数据传输,而有两个复制引擎的GPU可以同时执行核函数、一个主机到设备和一个设备到主机的数据传输。GPU的复制引擎通过cudaDeviceProp结构体的asyncEngineCount字段来指定,或者通过执行cuda官方样例中的deviceQuery来查看(我这里的结果如下图所示,我的GPU有两个复制引擎):

注意,并行化阻塞传输和异步传输是不可能的,因为阻塞传输发生在默认流中,所以直到所有之前的cuda调用完成后,阻塞传输才会开始,并且在它执行的过程中,不允许别的cuda调用发生。
下图描述了串行和阶段化并行传输与复制的时间线,其中nThread为1,nStream为4

如上图所示,假设数据传输和核函数执行的时间是可以比较的。在这种情况下,当执行时间tE > 传输时间tT,那么对于阶段化并行数据传输与复制,总的时间大约分别是tE + tT / nStream和tE + tT;否则,就都是tT + tE / nStream。但对于串行复制与数据传输来说,就都是tE + tT
零复制
零复制是cuda工具包2.2版本加入的特征,它允许GPU线程直接访问主机内存。为此,它要求映射钉内存(即不可分页内存),在集成GPU(也就是cudaDeviceProp结构体的integrated字段值为1)中,映射钉内存总是有利于提升性能,因为它避免了集成GPU和CPU内存之间的无谓复制,因为这两块内存在物理上是一样的。在具体的GPU上,映射钉内存只在某些场景下有优势。由于GPU上的数据不会被缓存,所以映射钉内存应该只被读写一次,对内存的全局性的读写也因此要被合并。零复制可以被用来在不设置最优流数量的情况下代替流,因为面向核的数据传输会自动与核函数的执行并行。以下的主机代码展示了零复制的典型用法:
float *a_h, *a_map;
...
cudaGetDeviceProperties(&prop, 0);
if (!prop.canMapHostMemory) {
return 0;
}
cudaSetDeviceFlags(cudaDeviceMapHost);
cudaHostAlloc(&a_h, nBytes, cudaHostAllocMappeed);
cudaHostGetDevicePointer(&a_map, a_h, 0);
kernel<<<gridSize, blockSize>>>(a_map);在上面的代码中,canMapHostMemory字段在cudaGetDeviceProperties()函数中被赋值,表示设备是否支持把主机内存映射到设备的地址空间中。 把cudaDeviceMapHost传给cudaSetDeviceFlags()函数可以用来开启锁页内存映射,注意这个函数必须在初始化设备或者调用要求状态的cuda函数(特别是创建上下文)之前被调用。锁页映射主机内存使用cudaHostAlloc()函数分配,指向被映射设备地址空间的指针可以通过函数cudaHostGetDevicePointer()获取,kernel()函数因此可以通过使用指针a_map来引用映射主机钉内存,就像a_map指针指向的是设备地址空间一样。
可见,映射主机钉内存可以让我们在不使用cuda流的情况下并行化CPU-GPU数据迁移和计算,但是因为这种内存区域的重复进入会导致重复的PCIe迁移,因此就要考虑在主机内存中手动开辟令一块内存以缓存之前读取的主机内存数据
统一虚地址
计算能力≥2.0的设备在64位的Linux、Mac、Windows XP/7/vista上使用TCC驱动模式时,会支持一种特殊的地址模式——统一虚地址(UVA)。使用UVA时,主机内存、所有支持此功能的设备的内存都会共享一块虚拟地址空间。在使用UVA之前,我们应该记录哪些指针指向设备内存(以及哪些设备的内存),哪些指向主机内存,把这些指针记录保存成独立的元数据,或者硬编码信息。另一方面,使用UVA时指针指向的物理内存空间可以通过cudaPointerGetAttributes()函数来查看指针值来查看。
在UVA下,使用函数cudaHostAlloc()分配的钉主机内存会拥有相等的主机和设备指针,因此对于这种内存无需调用cudaHostGetDevicePointer()来获取新的指针了。但是,使用函数cudaHostRegister()函数分配的钉内存的主机指针和设备指针会继续不同,此时cudaHostGetDevicePointer()来获取新的指针就依旧有调用的必要。
UVA也是在配置支持的情况下为GPU开启直接通过PCIe总线,绕过主机内存来实现数据的P2P传输的必要前提,关于UVA和P2P,CUDA C Programming Guide中有进一步的解释和软件要求。
设备内存空间
cuda设备有几个内存空间,这些空间有着不同的特点,在应用中的用处也不一样。这些空间包括全局、局部、共享、纹理和寄存器空间,如下图所示

在不同的内存空间中,全局内存的容量是最大的,访问延迟从高到低依次是全局、局部、纹理、常量、共享内存和寄存器文件。各个内存类型的主要属性如下表所示

在纹理访问中,如果一个纹理引用和全局内存中的线性数组绑定,那么设备代码就可以对这个数组进行写入操作。绑定到一个cuda数组的纹理引用可以通过表面-写操作被修改,这个操作需要把表面绑定和同一个cuda数组进行绑定。在同一个核中,对一个纹理的读操作和对其在全局内存中对应数组的写操作应该避免同时进行,因为纹理缓存是只读的,而且当对应的全局内存被修改时,这块缓存依旧可读。
全局内存的合并访问
在为支持cuda的GPU架构编程时最重要的性能考量就是对全局内存进行合并访问了,当特定访问要求满足时,一个伪线程产生的对全局内存的读写将被设备压缩成一次事务,这种访问要求取决于设备的计算能力,请参见CUDA C Programming Guide。
对于计算能力为2.X的设备,这些要求可以被总结为:一个伪线程的并发访问可以被合并成的事务数量,等于为这些伪线程提供服务的必要缓存线的数量。默认情况下,所有的访问通过拥有128位线的L1进行缓存,对于多种访问模板,有时只在拥有32位段的L2上进行缓存有助于降低复用率。
对于计算能力为3.X的设备,对全局内存的访问只会被缓存在L2中,L1誊给局部内存访问,一些计算能力为3.5、3.7或5.2的设备也允许在L1上进行全局内存的选择性缓存。
当ECC开启时,用合并的方法访问内存就更加重要,零散的访问会增加ECC内存迁移的负载,特别是向全局内存写数据时,负载的增加会更加明显。
下面的例子为进一步阐释合并的概念,这些例子假设设备计算能力为2.X,对全局内存的访问会缓存在L1上(这也是这些设备的默认行为),而且访问是针对4字节的字进行的,除非特别标注。
- 一个简单访问模板
第一个也是最简单的合并可以被任何支持cuda的设备实现:第k个线程访问缓存线中的第k个字,但不是所有的线程都需要参与。
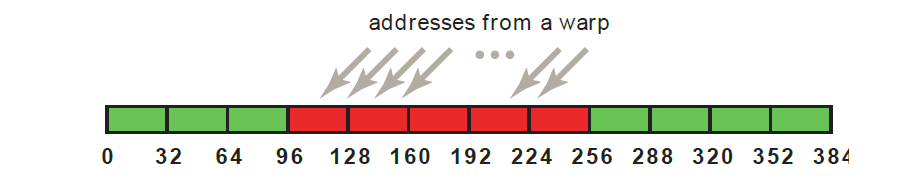
例如,如果一个伪线程访问了连续的4字节的字(比如连续的浮点值),那么一个合并后的事务和一个128字节(32 * 4 = 128)的L1缓存线将会被用来执行这次访存。这个访问模板如下图所示

这种访问模板会导致一个128字节的L1事务,如上图红色矩形所示。如果此缓存线中有的字还没有被任何线程使用(比如一些线程已经访问了相同的字,或者一些线程没有参与到这次访问中),但缓存线中的所有数据还是会被读取。另外,如果伪线程中的线程对这一段的访问顺序发生了变化,还是只有一个128字节的L1事务会被计算能力2.X的设备执行
- 一个串行但不对齐的访问模板
如果一个串行伪线程(其中的线程串行执行)访问连续但不和缓存线对齐的内存,那么就需要两根128字节的L1缓存,如下图所示

无缓存的事务(例如只使用L2缓存的事务)也会产生相似的效果,除了32字节的L2段。下图就反映了这种情况:此图和上图用的访问模板是一样的,只是2个L1事务变成了5个32字节的L2段
通过cuda运行时api(例如cudaMalloc())分配的内存可以保证至少能以256字节为单位对齐,因此选择合理的线程块大小(例如伪线程的容量的整数倍,也就是32的整数倍)可以利用和缓存线对齐的伪线程来进行内存访问。比如,如果一个线程块的访存容量为200字节,那么即便在L2的32字节段上分配,也会发生不对齐的现象。
- 不对齐访问的效果
使用一个简单的复制核函数去探索不对齐访问是容易且有效的,我们就用以下代码来进行实验:
__global__ void offsetCopy(float* outData, float* inData, int offset) {
int xid = blockIdx.x * blockDim.x + threadIdx.x + offset;
outData[xid] = indata[xid];
}在以上代码中,数据从输入数组inData复制到输出数组中,两个数组都存储在全局内存中。核函数在主机代码的一个循环中执行,参数offset的值从0变化到32,下图描述了带缓存和不带缓存时,不对齐访问的结带宽结果,测试显卡为NVIDIA Tesla M2090,计算能力2.0,ECC默认开启

对于NVIDIA Tesla M2090显卡来说,不带偏移和带有32整数倍的偏移的内存访问分别会导致单个L1缓存线事务和4个L2缓存段加载(此时无L1),对应的带宽大约是130GB/s。对于别的情况(偏移量不是32的整数倍),就分别得用两个缓存模式下的L1缓存线或者4到5个无缓存模式下的L2缓存段分别装载每个伪线程,导致带宽降到无偏移情况下的八成左右。
有趣的是,我们可能认为带缓存时可能比无缓存时的性能要差,因为缓存时每个伪线程要读取它要求字节的两倍量,而无缓存时只会读取1.25倍的要求量。在这个例子中,效果差异并不明显,因为相邻的伪线程复用了他们邻居读取过的缓存线。所以,即便在带不带缓存加载的性能依旧有差异,但是比我们预期的要小,如果邻接伪线程对读取过的缓存线的复用率不这么高的话,性能差异就会更加显著。
- 带步长的访问
通过上面的例子,我们可以看到计算能力为2.X的设备可以在不对齐串行访问的情况下达到合理的性能,但非单位步长(步长>1)的访问与其有所不同,而带步长的访问经常出现在处理多维数据或矩阵的情况中,因此,确保在读取的每条缓存线中有尽可能多的数据被实际使用是在这些设备上进行内存访问性能优化的重要部分。
为了说明带步长访问对带宽的影响,请看下面的strideCopy()函数,用来在线程之间将输入数据以跨步的方式复制到输出数据上:
__global__ void strideCopy(float* idata, float* odata, int stride) {
int xid = (blockIdx.x * blockDim.x + threadIdx.x) * stride;
odata[xid] = idata[xid];
}下图描述了这么一种情况:一个伪线程内的线程以步长为2的方式访问内存中的字,这一行为导致要为每个伪线程加载两个L1缓存线或者八个L2无缓存模式的缓存段,测试设备还是Tesla M2090,计算能力为2.0(此图只展示了半个伪线程也就是16个线程对一个L1缓存的访问情况,上面两种颜色表示两个L1缓存线,一个方块表示4个字节,下面的一个黑方块表示一个线程)

步长为2,会导致读写效率减半,因为每个事务中有一半儿的数据没有被使用,从而浪费了带宽。随着步长的增加,有效带宽会逐渐下降,直到缓存中的32条线被用来加载一个伪线程中的32个线程(也就是一个线程独享一条缓存线,这还有什么带宽可言呢),如下图所示

根据上图可以看到,非单位步长(步长>1)的访问应该尽可能避免,一个可行的方法就是使用共享内存,这就是我们下一节要讲述的。
共享内存
因为共享内存在GPU芯片上,所以它有着比局部和全局内存更高的带宽和更低的延迟,只要线程之间没有“银行”冲突。
- 共享内存和内存银行
为了给并发访问提供更高的内存带宽,共享内存被分成了大小相等的内存模块(银行),这些银行可以被同时访问。因此,任何对n个不同银行的读写都可以被同时进行,并且生成的带宽是一次访问单个银行的n倍。
然而,如果一个内存请求的多个地址被映射到了一个内存银行里,那么访问就得被串行化。必要时,硬件会把有着银行冲突的内存请求切分成很多没有银行冲突的独立请求,从而带宽 = 最高带宽 / 独立请求数。此处有个例外,就是当一个伪线程内的多个线程访问同一个共享内存地址时,就会发生广播。计算能力大于等于2.X的设备拥有这种广播共享内存访问的能力(比如对一个伪线程内的多个线程发送一个值的拷贝)。
为了尽量减少银行冲突,理解内存地址如何映射成内存银行以及如何更好地调度内存请求就变得尤为重要。
在计算能力为2.X的设备上,每个银行每两个时钟周期有着32位的带宽(也就是每两个时钟周期内,每个银行可以处理32个位),后面32位的字会被分配给后面的银行(也就是当请求量大于32位或者请求间隔大于两个时钟周期时,会发生跨银行访问)。伪线程容量为32,因此银行的数量也是32,银行冲突可以在伪线程中的任何两个线程之间发生;
在计算能力为3.X的设备上,每个银行每个时钟周期有着64位的带宽(但是3.X设备的时钟周期要长于2.X设备)。而且有两种不同的银行模式:32位模式和64位模式,分别将随后32位或64位的字分配到下一个银行里,同样,银行数量和伪线程容量一样都是32,所以银行冲突还是可以在伪线程中的任何两个线程之间发生。
- 矩阵乘法中的共享内存1
共享内存可以让一个线程块内的线程进行合作。当一个线程块内的多个线程使用全局内存中的相同数据时,我们可以使用共享内存来一次性地从全局内存中访问数据,也可以通过使用合并模板从全局内存中读写数据,然后在共享内存中记录数据的方法来避免内存的非合并访问。除了内存银行冲突之外,使用非串行或者非对齐的伪线程来访问共享内存没有任何风险
下面我们通过一个矩阵乘法C = AB的简单例子来说明共享内存的使用,其中A的维度为M * w,B的维度为w * N,显然C的维度就是M * N。为了让核函数简单,M和N都是32的整数倍,w为32,测试平台为计算能力>=2.0的显卡。
对这个问题的一个自然的解构方法是使用w*w的块矩阵填充C。因此,就这些w * w的块矩阵而言,A是列矩阵,B是行矩阵,C是A和B的外积,如下图所示

那么,表示A和B分别需要M / w个和N / w个块矩阵,一个块矩阵对应一个w * w的线程矩阵(也就是w个线程块),每个线程块计算不同块矩阵中的元素,其中每个线程计算一个元素。为了实现这一点,我们可以写出下面的函数simpleMultiply():
__global__ void simpleMultiply(float* a, float* b, float* c, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
for (int i = 0; i < TILE_DIM; i++) {
sum += a[row * TILE_DIM + i] * b[i * N + col];
}
c[row * N + col] = sum;
}在这段代码中,a、b、c分别是指向全局内存中矩阵A、B、C的指针,blockDim.x、blockDim.y和TILE_DIM都为w,w * w线程块中每个线程负责计算C中的一个元素,row和col就是C中被某个线程计算的元素的行和列(同时也是A和B中的行和列),for循环中的i表示A中的行和B中的列
这个核在NVIDIA Tesla K20X显卡(关闭ecc)僧伽爆发的有效带宽只有6.6GB/s,为了分析性能,我们有必要在for循环中考虑伪线程是如何访问全局内存的。每个伪线程计算C中一个块矩阵的一行,对应着对A中块矩阵的每一行与B中整个块矩阵进行的先乘后加,如下图所示

对于for循环中的每一次迭代,伪线程中的每个线程会对B中块矩阵进行按行读取,对于所有计算能力而言,这一步都是串行且合并访问全局内存的。
然而,在每次迭代中,所有的线程都会从全局内存中读到A矩阵中的同一个元素,因为索引row * TILE_DIM + i在对于同一个伪线程中的同一个线程是个常量。即便在计算力≥2.0的设备中处理这种过程只需要一个事务,那也存在着带宽浪费,因为我们只读取了一个4字节的字,而其他28个字都没有用到。我们可以在随后的迭代中复用这根缓存线,这样就可以最终用到所有的32个字了。然而,当多个线程块在一个处理器上同时执行时,每一次新的迭代都可能会把缓存线清空。
我们可以通过把A中的一个块矩阵读入到共享内存中来提高我们的程序在任何设备上的性能,代码如下所示
__global__ void coalescedMultiply(float* a, float* b, float* c, int N) {
__shared__ float aTile[TILE_DIM][TILE_DIM];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
aTile[threadIdx.y][threadIdx.x] = a[row * TILE_DIM + threadIdx.x];
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i] * b[i * N + col];
}
c[row * N + col] = sum;
}在上面的代码中,每个线程块负责C和A中的每一个块矩阵,线程块中的每个线程负责从全局内存中读取块矩阵一个元素。A中块矩阵的每个元素都只会执行一次全局内存中的读取和一次共享内存的写入,而且读取是以合并的方式进行的。在for循环的每一次迭代中,共享内存中的一个值会被广播给线程块中的所有线程。因为只有线程块中向共享内存中写入数据的线程才会读取数据(因为这里只有列矩阵A在读写共享内存,所以tid.y不变),所以在读取块矩阵之后不用调用__syncthreads()同步栏杆,不过在计算能力≥2.0的设备上,可能需要为__shared__数组加上volatile关键字以确保正确性。这个核在NVIDIA Tesla K20X显卡上的带宽为7.8GB/s,证明了当硬件L1缓存清空策略不能很好地匹配应用需求,或者L1缓存没有用来从全局内存中读取数据时,把共享内存当成用户管理的内存来使用的有效性
对矩阵B也可以做类似的进一步优化,在矩阵C的块矩阵中读取每一行时,B的整个块矩阵都会被读取,因此B块矩阵的重复读取可以通过把它读到一个共享内存中来消除,代码如下所示
__global__ void sharedABMultiply(float* a, float* b, float* c, int N) {
__shared__ float aTile[TILE_DIM][TILE_DIM], bTile[TILE_DIM][TILE_DIM];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
aTile[threadIdx.y][threadIdx.x] = a[row * TILE_DIM + threadIdx.x];
bTile[threadIdx.y][threadIdx.x] = b[threadIdx.y * N + col];
__syncthreads();
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i] * bTile[i][threadIdx.x];
}
c[row * N + col] = sum;
}注意,再向B块矩阵读取完数据后,调用了一次__syncthreads(),这是因为此时从共享内存中读数据的线程块和向共享内存中写数据的线程块不一定是同一个(其实建议即便有一块共享内存,也加一个线程同步)。这个函数在NVIDIA Tesla K20X显卡上的带宽为14.9GB/s,这种表现力的提高原因不是改善了合并访问,而是避免了和全局内存的冗余传输。
- 矩阵乘法中的共享矩阵2
上面矩阵乘法例子的一个变种就是令B = AT(A的转置),这个变种可以被用来说明对共享内存带步长的访问以及共享内存银行矛盾是怎么被处理的。C = AAT的一个简单实现如下所示
__global__ void simpleMultiply(float* a, float* c, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
for (int i = 0; i < TILE_DIM; i++) {
sum += a[row * TILE_DIM + i] * a[col * TILE_DIM + i];
}
c[row * N + col] = sum;
}在以上代码中,C矩阵的第row行第col元素是通过矩阵A的第row行第col列点积得到的,这个函数在NVIDIA Tesla M2090显卡上的带宽为3.64GB/s,比C=AB的结果还要低。差别在于,在这个例子里,我们如何让半个线程块在每一次迭代中读取A中的元素。对于一个线程块来说,列表示A的转置中的列数,因此col * TILE_DIM表示带步长访问全局内存中的步长w,从而导致了大量的带宽浪费。
避免步长访问的方法就是像之前一样使用共享内存,只是在这个例子中,一个线程块把A的一行读到了一列共享数组中去,代码如下所示:
__global__ void coalescedMultiply(float* a, float* c, int N) {
__shared float aTile[TILE_DIM][TILE_DIM], transposedTile[TILE_DIM][TILE_DIM];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
aTile[threadIdx.y][threadIdx.x] = a[row * TILE_DIM + threadIdx.x];
transposedTile[threadIdx.y][threadIdx.x] = a[(blockIdx.x * blockDim.x + threadIdx.y) * TILE_DIM + threadIdx.x];
__syncthreads();
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i] * transposedTile[i][threadIdx.x];
}
c[row * N + col] = sum;
}上述代码,共享的transposedTile来避免点积中对转置矩阵的非合并访问,而共享的aTile则是用来避免对矩阵的非合并访问。这个函数在NVIDIA Tesla M2090显卡上的带宽为27.5GB/s,比C=AB的结果稍差,因为这里有共享内存银行矛盾。
在每一次的迭代内,transposedTile元素的读取是不存在冲突的,因为每半个伪线程的线程跨行读取共享内存,因此导致了跨银行的步长为1的访问。然而,当从全局内存向共享内存中复制数据时就会发生银行矛盾,为了实现合并访问,从全局内存的读取就必须串行化,但是,这要求向共享内存中以列为单位写数据,但此时w * w的共享矩阵正在被使用,所以就导致了w个银行的访问线程之间出现了步长——线程块中的每个线程都命中了同一个银行。这些多步的线程矛盾很耗性能,简单的解决方法就是给共享内存数组加一个间隔,让它拥有一个多余的列,也就是这么声明:__shared__ float transposedTile[TILE_DIM][TILE_DIM + 1],这个间隔就可以完全消除矛盾,因为现在线程间的步长是w + 1个银行,这就导致了用来计算银行索引的取模算法的结果等于1。做了这个改变之后,在NVIDIA Tesla M2090显卡上带宽就达到了39.2GB/s——和C=AB核的结果一样
根据这几个例子,我们可以得到三个使用共享内存的理由:
- 开启对全局内存的合并访问,尤其可以避免大的步长(对于通用的矩阵,步长要远大于32);
- 消除或减少对全局内存的冗余读取;
- 避免带宽浪费
局部内存
局部内存之所以这么命名是因为它的作用范围只是在线程内部,而不是因为它的物理位置,实际上局部内存(本地内存)不是在GPU上的,因此访问局部内存和访问全局内存一样代价昂贵,换言之,局部不代表有更快的访问速率。
局部内存只用来持有自动变量,当nvcc编译器认为没有足够的寄存器空间来保存变量时,它将自动把变量保存到局部内存中。更有可能被放到局部内存中的变量包括大的结构体或数组等消耗太多的寄存器空间、或者(数组)应该被动态索引等。
通过给nvcc加上-ptx或者-keep参数可以来查看ptx汇编指令,以便检查一个变量在第一个编译阶段是被否被放到了局部内存中,如果是的话,它被使用.local助记符声明,然后通过ld.local或st.local助记符访问;即便第一阶段没有将变量放入局部内存,后面的编译阶段如果发现此变量在目标架构中消耗了太多的寄存器空间,还是可能将其放入局部内存。我们无法为某个具体的变量检查这一点,但是可以通过--ptxas-options=-v参数来查看每个核的局部内存(lmem)使用情况
纹理内存
纹理内存是只读的,如果访存失败,那么一个纹理读取只会进行一次设备内存读取;否则就只进行一次纹理内存读取。纹理内存对于2维空间的局部访问是最优的,因此同一个读取纹理内存的线程离得越近,性能越好。另外,纹理内存也是为具有不变延迟的流访问而设计的,也就是说,一次缓存命中会减少主存的带宽需求,而不会减少访问延迟。
在某些特定的取址场景下,通过纹理内存读取设备内存比通过全局或常量内存更具有优势。
- 额外的纹理能力
如果使用text1D()、text2D()、text3D()而不是tex1Dfetch()来访问纹理的话,硬件可以提供一些对例如图像处理应用可能有用的额外功能,如下表所示

在一个核函数中,纹理缓存并不像全局内存写入一样保持连续,因此通过纹理访存从由同一个核中的全局存储写入的内存地址中读取数据,可能会导致未定义数据的返回,也就是说,如果我们通过纹理访存访问由之前的核函数或内存复制更新的内存地址,这将是安全的,但如果我们访问的是由同一个线程或者同一个核函数内其他线程更新的地址,那就不安全了。
常量内存
显卡中总共有64KB的常量内存,因此和纹理内存类似,如果缓存不命中,访问常量内存只会进行一次对设备内存的读取;否则就只会读取一次常量内存。在一个伪线程中,访问不同的常量内存是穿行的,因此时间消耗会随着伪线程内所有线程访问的不同常量内存地址数量的增加而线性增加。所以,当一个伪线程中线程只访问少数的常量内存地址时,常量内存的性能就很好;如果只访问一个地址,那么常量内存的访问就可以和寄存器访问一样快。
寄存器
一般来说,每条指令访问寄存器不会消耗额外的时钟周期,但是在发生写后读的依赖或者寄存器银行冲突时,还是可能出现延迟。
写后读依赖的延迟大约是24个时钟周期,但是这个延迟在每个处理器具有足够多的并发伪线程的平台上可以被忽略,在计算能力2.0、一个处理器有32个cuda内核的设备上,足够多可能要求有24个伪线程(总共768个线程),对于计算能力更高的设备来说亦是如此。
编译器和硬件线程调度器会尽可能从优地调度指令以避免寄存器内存银行冲突,当每个线程块的线程数是64的整数倍时,它们的表现最好。除此之外,应用程序无法直接控制这些银行矛盾,包括把数据封装成float4或int4类型
- 寄存器压力
当没有足够的寄存器可以分配给指定任务时会发生寄存器压力。尽管每个处理器拥有上千个32位寄存器,但这些寄存器会被分配给多个并发线程。为了避免编译器分配太多的寄存器,我们可以通过在编译命令行里加上-maxrregcount=N参数或者为核定义标识启用边界来控制为每个线程分配的最大寄存器数
分配
使用cudaMalloc()和cudaFree()进行的显存分配与释放是代价昂贵的,因此显存应该被尽可能的复用或者使用子分配,以减少对应用整体性能的影响
NUMA最佳实践
一些最近的Linux版本已经默认支持了自动NUMA平衡,但在一些情况下,被自动NUMA平衡执行的操作可能会降低运行在NVIDIA GPU上应用的性能,因此为了更好的表现力,开发者应该为他们的应用手动调节NUMA特征
最好的NUMA调整取决于每个应用和结点的特征和硬件亲和度需求,但对于一般的运行于英伟达GPU上的应用来说,它们可以直接关闭自动NUMA平衡。例如在IBM Newell POWER9结点上,CPU对应NUMA结点0~8,因此可以使用numactl --membind=0,8来把内存分配绑定到CPU上
优化执行配置
提升性能的另一个关键就是让设备上的处理器越忙越好,如果我们的设备工作时不能在处理器之间进行均衡调度,那么表现力就会下降,因此,设计应用的线程与伪线程调度时,最大化硬件的利用率以及尽量让任务均衡分配就很重要,这涉及一个关键概念就是占有率。
在某些情况下,硬件利用率可以通过让多个独立的核同时执行来提升,同时执行多个核又称之为并发核执行。另外一个重要的概念就是为某个特定的任务管理系统资源分配,这些概念都会在这一章有所提及
占有率
cuda中的线程指令时串行执行的,因此避免延迟、让硬件保持忙碌的唯一途径就是当一个伪线程停止时,让别的伪线程工作,因此,一个和在处理器上活跃的伪线程数相关的指标就对判定硬件忙碌的程度非常重要,这个指标就是占有率。
占有率是每个处理器上实际活跃伪线程数和最大活跃伪线程数的比值,后者可以通过deviceQuery样例去查看,另一种查看占有率的方法是查看硬件处理活动伪线程的能力百分比。占有率更高,不代表性能更高——也就是多余的占有率不会提升性能,但是低的占有率总是不利于隐藏内存延迟,从而导致表现力下降
计算占有率
决定占有率的几个因素之一是寄存器利用率,寄存器存储允许线程就近存储局部变量,以便进行低延迟访问。然而,寄存器集合(又称之为寄存器文件)受限于线程所在的处理器的供应量,而且,寄存器一次性被分配给整个线程块。所以,如果每个线程块使用了太多的寄存器,一个处理器能处理的线程块数就会减少,占有率随之下降。每个线程能使用的最大寄存器数量可以在编译时手动通过-maxrregcount参数指定,或者在核函数定义时使用__launch_bounds__设置(参见上文寄存器压力部分)。
为了计算占有率,每个线程使用的寄存器数量时关键因素之一,例如,在计算能力为1.1的设备上,每个处理器可以有8192个32位寄存器,最大能同时处理768个线程(24个伪线程 * 32个线程),这意味着,在这种设备上,每个线程最多使用10个寄存器就可以使每个处理器的利用率为100%。然而,这种计算寄存器数量对占有率影响的方法没有考虑寄存器分配间隔,例如,在计算能力1,1的设备上,假设一个核有着容量为128的线程块、每个线程使用12个寄存器,那么它在一个处理器上就可以最多运行6个线程块(768 / 128 = 6),因此如果这个核有5个满载128线程的活动线程块,其利用率就是5 / 6 = 83%;但如果这个核的线程块容量为256,那么它最多只能在一个处理器上运行两个满载活动线程块,因为768 * 12 > 8192 && 512 * 12 < 8192,所以这时它的利用率就降到了66%。另外,在计算能力1.1的设备上,寄存器是会尽量给每个线程块分配够256个的。
关于自己设备的参数,可以通过deviceQuery样例来查看,如下图所示

可见,我的设备上每个线程块最多拥有65536个寄存器(也是每个处理器拥有的寄存器数),每个处理器支持2048个线程,每个块最大容量为1024个线程,每个伪线程的容量为32
此外,对于不同计算能力的设备,可用寄存器数量、每个处理器最大拥有的并行线程数量以及计算其分配间隔都是不一样的,由于寄存器分配上的细微差别,以及处理器的共享内存也会根据线程块进行分区,寄存器用量和占用率之间的精确关系很难确定。我们可以使用nvcc的--ptxas options=v选项来查看每个核上每个线程使用的寄存器数,请参见CUDA C Programming Guide的硬件多线程部分来查看不同计算能力设备的寄存器分配策略,以及特征和技术规范部分查看这些设备可用的寄存器数量。另外,英伟达提供了Excel形式的使用率计算器,以便让开发者训练以达到最好的平衡、测试更多的场景,这个文件叫做CUDA_Occupancy_Calculator.xls,位于cuda安装目录的tools目录下

打开后内容如下图所示

在Calculator标签下,选择自己设备的计算能力,就可以看到一些详细信息

除了这个Excel文件外,还可以使用NVIDIA Visual Profiler中的Achieved Occupancy指标,这个指标也会在应用分析的多处理器阶段计算
并发核执行
如第九章第一节中异步迁移、计算与迁移的重叠部分所述,cuda流可以被用来让数据迁移与核执行重叠进行,在能够并发执行核函数的设备上,流也可以被用来同时执行多个核函数来充分利用设备的多处理器。设备是否有这种多核函数并发执行的能力保存在cudaDeviceProp结构中的concurrentKernels字段中,也可以通过deviceQuery样例来查看,如下图所示

非默认流必须并行执行,因为系统会串行地、独占式地执行默认流。下面的代码展示了基本技术,由于kernel1、kernel2使用了不同的非默认流,因此这两个核可以并行执行
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
kernel1<<<grid, block, 0, stream1>>>(data_1);
kernel2<<<grid, block, 0, stream2>>>(data_2);多个上下文
cuda在某个GPU中工作的进程空间称为上下文,上下文为GPU封装了核的启动、内存分配以及诸如页表的结构,它在cuda驱动api中是明确的,但是在cuda运行api中是完全模糊的,也就是说运行时api会自动创建管理上下文。
cuda应用程序可以使用cuda驱动api来为一个GPU创建不止一个上下文,如果多个cuda应用进程并发访问一个GPU,这就会发生多上下文问题,因为一个上下文是和一个主机进程绑定的,除非cuda多进程服务正在运行。尽管多个上下文记忆它们相关的资源(分配的全局内存等)可以被并发地分配给一个GPU,但此GPU上一次只能执行一个,而且同一个GPU的上下文共享是基于时间片的。创建额外的上下文会导致为多个上下文数据的内存压力,以及上下文切换的时间消耗,另外,当来自多个上下文的工作可并发执行时,切换上下文会导致利用率的下降。
因此,在一个cuda应用中应该避免为一个GPU创建多个上下文。为了达到这一点,cuda驱动api提供了一些方法来访问和管理一种每个GPU上都存在的名为主上下文的特殊上下文,当一个线程拥有不止一个上下文时,cuda运行时api也提供了抽象使用上下文的函数,如下所示
CUcontext ctx;
cuDevicePrimaryCtxRetain(&ctx, dev); // 持有GPU设备的主上下文,必要时会创建
cuCtxPushCurrent(ctx); // 上下文入栈
kernel<<<...>>>(...);
cuCtxPopCurrrent(ctx); // 上下文出栈
cuDevicePrimaryCtxRelease(dev); // 释放设备的主上下文注意,如果一个非主上下文已经存在,那么cuDevicePrimaryCtxRetain()函数就会失败
隐藏寄存器依赖
当一个指令使用被之前的指令写入在寄存器中的结果时,寄存器以来就会发生,这种延迟在当前支持cuda的GPU上大约为24个周期,因此线程必须等待24个周期才能使用结果。然而,这种延迟可以被其他伪线程中的线程执行而隐藏,也就是一个伪线程中的线程在等待24个周期时,另外一个伪线程的线程依旧可以工作,所以这个等待延迟就被隐藏了,详情参见9.2中的寄存器部分
线程和线程块的探索
每个单元格的线程块的维度与数量、每个线程块中线程的数量都是重要的参数,其中的维度参数不会影响性能,因为它允许我们把多维度问题映射给cuda,因此,本节讨论的参数是数量,而非维度。
延迟隐藏和占有率取决于每个处理器上的活跃伪线程数,这由运行参数和诸如寄存器、共享内存之类的参数一起确定,而选择运行参数就是在延迟隐藏(占有率)和资源使用之间做一个权衡。我们应该同时配置线程块与线程数量这两个参数,但是对于每一个参数都有一些启发式方法。
当选择每个单元格的线程块参数时(也称为grid_size),最主要的考虑就是要让GPU忙,因此一个单元格内的线程块数应该大于处理器数,这样每个处理器就会至少有一个线程块要去执行。而且,每个处理器应该有多个活跃的线程块,这样没有阻塞在__syncthreads()的线程块就可以让硬件繁忙,活跃线程块数的推荐值取决于资源可用性。因此,这个值应该在第二个参数——线程块中的线程数(也称为block_size)和共享内存的上下文中决定,为了适配未来的设备,每个核使用的块的数量应该以千计。
当选择块容量时,要记住多个并发线程块是可以共存于一个处理器上的,因此占有率不仅仅取决于块容量,也就是说大的块容量不意味着更高的占有率。例如,在计算能力≤1.1的设备上,由于每个处理器上的最大线程数为768,所以拥有容量为512的线程块的核的占有率为66%(512 / 768),因为一个处理器最多能执行一个线程块。然而,拥有容量为256的线程块的核的占有率就是100%,因为处理器可以一次执行三个这样的线程块。
如占有率一节中所述,高的占有率也不意味着性能更好,例如把占有率从66%提升到100%不意味着性能也随之上升,因为低占有率的核可以为每个线程提供更多的寄存器,这就可以更好避免数据从寄存器中溢出到局部内存中。典型地,一旦占有率达到50%,再增加占有率也不会进一步改善性能。在某些情况,少量的伪线程也可以完全隐藏延迟,特别是在使用指令集别并行地情况下,详情参见http://www.nvidia.com/content/GTC-2010/pdfs/2238_GTC2010.pdf.
选择块容量是有很多因素需要考虑,因此不可避免要做一些实验,但还是有一些经验之谈:
- 每个块的线程数应该是伪线程数量的整数倍,以利用合并性,还能避免在线程数较少的伪线程上浪费计算能力;
- 当且仅当每个处理器上有多个并发块时,每个块至少要有64个活跃线程;
- 每个块的容量应该在128~256之间,做不同的块容量实验时,这也是一个很好的初始范围
- 如果延迟影响性能时,要使用3~4个小的线程块而不是一个大的线程块,尤其对于那些频繁调用__syncthreads()函数的核来说,好处更大
注意,当给一个线程块分配了大于处理器可用寄存器数量的寄存器,或者请求太多的共享内存或线程时,核函数就会失败。
共享内存的影响
共享内存可以帮助实现合并以及消除对全局内存的多余访问,但是它也影响占有率。在很多情况下,核函数请求的共享内存数和它选择的块容量相关,但是线程和共享内存中元素的映射关系不用非得是一对一的,例如,一个核内可能要使用32 * 32的共享内存数组,但最大线程数为512,那就不可能为这个核启动一个32 * 32线程的块。在这种情况下,我们可以用容量为32 * 16或者32 * 8的块启动核,这样每个线程可以分别处理2个和4个共享元素。即便没有块容量这种限制,一个线程处理多个共享内存元素的方法也是有好处的,因为一些对每个元素都要进行的公共操作可以被线程一次执行,还能把成本均摊到每一个要被处理的元素上(例如某个操作要消耗1K内存,这1K内存就可以被均分给每个元素)。
一个确定性能对占有率的敏感性的有效方法是通过急剧改变共享内存的分配数量来进行实验,就像上一节在讨论块容量参数配置时所讲述的一样。在不修改核函数的情况下,通过修改共享内存大小可以减少核的占有率,并测量其对性能的影响。如前一节所说,一旦占有率超过50%,就没必要调整参数来提高占有率了,方才的实验也可以用来确定是否达到了这个瓶颈。
指令优化
了解指令如何执行的可以允许我们做更底层的优化,对于那些频繁执行的代码(亦称为热点代码)而言更是如此。实践证明,当所有的高层优化完成后,就可以进行这种底层优化了。
算术指令
单精度浮点数的性能最好,因此我们强烈使用它们,单独算术指令的讲解请参见CUDA C Programming Guide
除法与取模指令
整数除法与取模代价很高,所以应该被避免或者用位操作代替:如果n是2的整数倍,那么i / n就等同于i >> log2(n),i % n就等同于i & (n - 1),当n是字面量时,编译器就会执行这些操作,详情请参见CUDA C Programming Guide
倒数取平方
倒数取平方操作应该通过明确调用rsqrtf()或rsqrt()来实现,前者用于单精度,后者用于双精度。当1.0f/sqrtf(x)不违反IEEE-754语义时,编译器才会把它代替为rsqrtf()。
其他算术指令
当出现下列情况时,编译器必须偶尔插入转换指令,包括额外的执行循环:
- 对char、short操作的函数,其操作数通常要被转换成int;
- 双精度浮点指针常量(没有带f这样的类型后缀)被当成单精度浮点计算的操作
第二种情况可以通过使用单精度浮点指针常量来避免,常量值后面要加上f后缀,比如3.141592653589793f、1.0f、0.5f等,这个后缀对性能和准确度都有影响。对准确度的影响已经在单双精度之间的转换部分讲过了,注意f后缀对性能的影响在计算能力为2.x的设备上尤为重要。对于单精度代码,强烈推荐使用float类型和单精度数学函数,当给没有本地双精度支持的设备(比如计算能力≤1.2的设备)编译程序时,每个双精度的浮点变量都会被转换成单精度的浮点变量(但大小还是64位),每个双精度数学运算都会被转换成单精度的运算。
注意,cuda数学库中的通用数学函数erfcf()和单精度配合时特别的快。
指数为小数的指数运算
当指数为小数时,相比通过使用pow()函数,使用平方根、立方根以及倒数大大加速指数运算。对于那些不能被准确表达为浮点数的指数(例如1/3),这么做也可以提供准确得多的结果,而pow()函数会放大初始的表达错误。当x >= 0或x != -0,也就是说signbit(x) == 0时,用以下表格中Formual列来实现对应Computation中的计算效果会好很多


数学库
cuda提供两种运行时数学操作库,可以通过名字来区分它们:一个名字带下划线,一个不带(比如__functionName()与functionName())。带下划线的函数将被直接映射到硬件环节,它们更快但准确率有所下降;相反,不带下划线的函数准确率更高但也更慢。当参数x的大小需要被下降,不带下划线的函数的开销将比带下划线的大一个数量级(特别对于sinf(x)、cosf(x)和expf(x));另外,在这种情况下,参数下降的代码要使用局部内存,这进一步影响了性能,因为局部内存访问延迟较高,更多的细节请参见CUDA C Programming Guide。注意,只要需要对某个参数进行正弦余弦计算时,sincos指令族就应该被用来优化性能:单精度快速运算使用__sincosf()、单精度普通运算使用sincosf()、双精度运算使用sincos()
nvcc的-use_fast_math编译参数让不带下划线的函数等同于带下划线的函数,也关闭了对非正规单精度的支持,降低了单精度除法运算的精确度。这是一种会降低运算准确度、改变特殊情况下的处理结果的激进优化方法,鲁棒性更好的方法是只有以性能做为主要评价标准、处理结果的不同可被接受的情况下才有选择地使用这些快速处理指令,而且要注意这种效率的提升只对单精度浮点数有效。
对于一些指数较小的整数求幂(例如取平方、立方),改用乘法比使用pow()函数更快,尽管编译器会做出优化以尽量减小两者的差距,但乘法(或者使用等价的内联函数或者宏)还是有很大优势,尤其是当要计算相同底数的不同指数的幂时,乘法会有利于编译器进行公共的子表达式消除(CSE)。
对于以2或10为底的指数运算,使用exp2()、expf2()、exp10()或expf10()要比pow()和powf()快得多,因为pow()和powf()为了解决在通用指数运算中大量的特殊情况和在全范围的底数指数中取得更好的准确性,会使用大量的寄存器内存和指令,而exp2()、exp2f()、exp10()、exp10f()的性能和exp()、expf()相似,比pow()、powf()要快大约十倍。
对于指数为1/3的求幂,使用cbrt()或cbrtf()函数要比通用求幂pow()或powf()快得多,因为前者更加轻量级。同样当指数为-1/3时,应该使用rcbrt()或rcbrtf()。
用sinpi(x)、cospi(x)和sincospi(x)分别取代sin(πx)、cos(πx)和sincos(πx),前者的性能和准确性都比后者好。比如,在计算角度而非弧度的正弦函数时,应该使用sinpi(x / 180.0)。类似地,当参数为πx时,单精度函数sinpif()、cospif()和sincospif()应该取代sinf()、cosf()和sincosf(),sinpi()函数的性能比sin()好是因为它参数简单,准确度好是因为sinpi()函数会帮我们隐式地乘上π,因为无限精度的π要比单精度或双精度的近似要更高效。
和精度有关的编译参数
在默认情况下,nvcc编译器在计算能力为2.x的设备上会生成服从IEEE标准的代码,但它也为生成精度更低速度更快的代码(更接近在早期设备上生成的结果)提供了参数:
- -ftz=true(非正规化的数直接清零);
- -prec-div=false(降低除法的精度);
- -prec-sqrt=false(降低取平方根的精度)
另外,如上一节中所述,使用-use_fast_math可以把不带下划线的数学函数强制转换成带下划线的数学函数,这么做会牺牲准确度来换去更快的速度。
内存指令
内存指令包括读写共享、局部或全局内存的指令,当访问没有缓存的局部或全局指令时,会产生400~600个时钟周期的延迟。例如,下面例子中的赋值操作符吞吐量很高,但是从全局缓存中读数据时会产生400~600时钟周期的延迟:
__shared__ float shrared[32];
__device__ float device[32];
shared[threadIdx.x] = device[threadIdx.x];如果当等待全局内存访问结束的同时,有足够多的独立算术指令等待执行,大部分全局内存访问延迟可以被线程调度器隐藏,但最好还是尽量避免访问全局内存。
控制流
分支
if、swith、do、for、while这样的控制流可以通过让同一伪线程中的线程执行不同的代码来显著影响性能,如果这种情况发生,不同的执行路径应该被独立执行,这样的话会增加伪代码中执行的指令数。为了当控制流取决于线程id时获得最好的性能,控制条件应该尽量减少伪线程中的线程分支,这么做是有可能的,因为跨线程块的伪线程分布时确定,正如CUDA C Programming中SIMT结构中所述,一个例子就是控制流只取决于threadIdx / WSIZE的结果,其中WSIZE是伪线程容量,在这种情况下,伪线程内就没有线程分支了,因为threadIdx / WSIZE是严格与伪线程对齐的。
对于那些只包含少量指令的分支,线程分支会造成少量的性能损失,比如编译器可能使用预测来避开一个实际的分支。实际上,所有指令都会被调度,但线程条件代码或者谓词判断会控制哪些线程能够执行这些指令,判断结果为false的线程不会写结果,也不会计算地址或者读取操作数。
从Volta架构开始,独立线程调度允许伪线程在数据无关的控制块外部继续保持分叉,显式调用__syncwarp()可以被用来保证伪线程在执行下游指令之前已然重新聚集。
分支预测
有时,编译器可能会使用分支预测来展开循环或者优化if、switch语句,在这种情况下,线程块不会分叉。程序员可以使用以下代码来控制循环的展开:
#pragma unroll更多的信息请参考CUDA C Programming Guide。
使用分支预测时,任何依赖于控制条件的指令都不会被跳过,但是每条指令都会和由控制条件指令决定为true或false的线程条件或谓词判断相关联,尽管这些指令都会被调度,但只有判断结果为真的指令会被执行,谓词判断为假的指令就不会写结果,也不会计算地址或者读取操作数。
只有当被分支条件控制的指令数≤某个阈值时,编译器才会用预测指令代替分支指令。如果编译器认为条件可能产生很多的分叉伪线程,阈值就是7,反之为4.
无符号循环计数器与有符号循环计数器
在标准C语言中,有符号整数溢出会导致未定义的结果,所以无符号整数溢出语义被完整定义,因此,编译器可以对有符号运算做出比无符号运算更加激进的优化。一个典型例子就是循环计数器:因为循环计数器通常情况下的值都为正,编译器就会尝试把它声明为无符号的,但是有符号循环计数器会产生轻微的性能提升。
例如,请看以下代码:
for (i = 0; i < n; i++) {
out[i] = in[stride * i + offset];
}在上面代码中,自表达式stride * i 可能会造成32位整数溢出,因此如果i是无符号的,溢出语义就会阻止编译器使用一些可能使用的优化,例如长度减少;如果i是有符号的,并且没有定义溢出语义的话,编译器就有了更多的使用这些优化方法的余地
循环中的线程分支同步
在分支代码(例如对数组的循环)内部同步线程可能会导致意想不到的错误。一定要保证所有的线程都能在调用__syncthreads()的地方汇聚(也就是都能执行到这个函数),下面的代码展示了如何为1维的线程块正确实现这种做法:
unsigned int imax = blockDim.x * ((nelements + blockDim.x - 1) / blockDim.x);
for (int i = threadIdx.x; i < imax; i += blockDim.x) {
if (i < nelements) {...}
__syncthreads();
if (i > nelements) {...}
}在这个例子中,imax是数组元素的数量,被舍入到线程块大小的整数倍,那么所有的线程的迭代次数都一样(都是(nelements + blockDim.x - 1) / blockDim.x),如下图所示(blockDim.x = 4, nelements = 5)

再加上已经为防止越界加了判断,所以所有的线程都可以在__syncthreads()处汇合。
当__syncthreads()函数被分支代码中的设备函数调用时,我们也应该加以小心,解决这个问题的一个直接发放就是从无分支代码中调用设备函数,并且把thread_active标志作为参数传给设备函数。这个thread_active标志用来指示哪些线程应该参与到设备函数中的计算中,并且允许所有线程聚集到__syncthread()。
部署cuda应用
当完成了对应用一个或多个组件的GPU加速后,我们就可以把结果和最初的期望做比较了,在此可以回忆一下允许开发者为加速指定热点代码算出加速上界的评估步骤。在处理其他热点代码以达到全面加速之前,开发者应该考虑部分代码的并行实现,并将之付诸产品中,这么做有很多重要的原因:比如它允许用户尽早地看到结果,也可以通过演进化而非革命性地改变应用来减少开发者和用户要承担的风险
理解程序环境
每一次英伟达处理器的更新换代都会加入一些cuda可以使用的gpu新特征,因此我们有必要理解一下架构的特征。程序员起码要注意两个版本:计算能力、cuda运行时和cuda驱动api的版本号
cuda计算能力
计算能力描述了硬件的特征,反映了设备支持的指令集、块内最大线程数、处理器上寄存器数等标准,高计算能力的特征集是低计算能力的父集,因此支持向后兼容。GPU设备的计算能力可以通过deviceQuery来查看(如下图所示),也可以通过调用cudaGetDeviceProperties()函数、查看它返回的结构体信息来获得

显然,我的GPU设备的计算能力为6.1,更多关于不同GPU计算能力的细节请参见CUDA C Programming Guide中支持cuda的GPU和计算能力部分,另外我们也应该注意设备上的处理器数量、寄存器数量、可用内存等有用的特征
额外的硬件数据
计算能力并不描述所有的硬件特征,比如将核执行与主机设备间异步数据传输并行执行是大多数但非全部计算能力为1.1的GPU所拥有的性能,在这种情况下,应该调用cudaGetDeviceProperties()函数来判断设备是否拥有某一具体的特征,例如asyncEngineCount字段就表示是否支持核执行与异步数据传输的并行(以及支持多少个并发传输);canMapHostMemory字段指示零复制数据传输能否被执行。
使用哪个计算能力
当不知道当前硬件的计算能力时,最好假设计算能力为2.0,就像CUDA C Programming Guide中定义的那样。为了指定NVIDIA硬件和cuda软件的具体版本,可以使用nvcc编译器的-arch、-code和-gencode参数,使用伪线程混排操作的代码必须用-arch=sm_30(或更高)的参数编译,同时为多个支持cuda的设备编译代码的参数使用请参加最大适配的编译章节
cuda运行时
cuda软件环境的主机运行时组件只能被主机函数使用,它提供了这些处理函数:设备管理、上下文管理、内存管理、代码模块管理、执行控制、纹理引用管理、OpenGL与Direct3D的交互
相比于低版本的cuda驱动api,cuda运行时api通过提供模糊的初始化、上下文管理和设备代码块管理的方法来减少设备管理的复杂度,被nvcc生成的C/C++代码使用了cuda运行api,所以链接这种代码的应用将依赖cuda运行库;类似地,任何使用cuBLAS、cuFFT和其他cuda工具包的代码也会依赖于CUDA运行时,因为这些函数内部使用了cuda运行api。
组成cuda运行api的函数在CUDA Toolkit Reference Manual中有所解释。
cuda运行时处理核函数加载和设置核函数参数,并且负责在核函数启动前启动配置,再就是隐式地驱动版本检查、代码初始化、cuda上下文管理、cuda模块管理(cubin到函数的映射)、核函数配置、参数传递等。cuda运行库主要有两个部分:C风格的函数接口(cuda_runtime_api.h)和C函数之上的C++风格封装(cuda_runtime.h),关于运行时api的更多信息,请参考CUDA C Programming Guide中CUDA C运行时部分
cuda适配性与升级
企业级用户可以有更大的选择升级cuda工具包的灵活性,参见下文
cuda运行时和驱动api
cuda驱动api和运行时api是面向cuda的编程接口,其版本号可以让开发者检查和这些API相关的特征,并且决定是否需要对现有的api进行升降级以满足应用需要。
例如,1.1版本的cuda驱动可以运行为它编译的应用、插件或者包括cuda运行时的库,也可以运行为早期版本例如1.0编译应用,也就是说,cuda驱动api是向后兼容的。但是,1.1版本的cuda驱动不能运行为更新的版本编译的应用,比如cuda2.0,也就说cuda驱动api是不能向前兼容的,请参见下图

标准升级路径
从cuda9升级到cuda10的标准路径如下图所示

灵活的升级路径
从cuda10开始,使用Tesla的企业用户可以选择更加灵活地更新cuda版本,也就是用户不必更新cuda内核模块驱动组件,只要这些组件在具体的企业驱动分支上保持有效,如下图所示

cuda适配平台包
灵活升级是通过利用cuda10中的cuda适配平台包中的文件实现的,包括三个:CUDA驱动(libcuda.so)、胖二进制加载器(libnvidia-fatbinaryloader.so)和即时编译器(libnvidia-ptxjitcompiler.so)。安装完后,用户和适配平台的系统管理员应该配置系统加载器来选择新的用户模式组件集,常用的方法是更新环境变量LD_LIBRARY_PATH或更新ld.so.conf文件然后通过命令ldconfig来使能这个文件的修改,如此就允许cuda10工具包在现有的核模式驱动组件上运行,也就是说不用将这些驱动组件更新到cuda10版本了。cuda适配平台包的组织结构应该如下图所示

另外,还有一些关于cuda适配平台包的说明:
- cuda适配平台包中的库应该和现有的驱动安装包一起使用;
- cuda适配平台包中的文件应该被放到一起,而不是放到多个目录下;
- cuda适配平台包应该根据它支持的运行时环境来选择其版本
扩展的nvidia-smi
为了帮助管理员和用户,nvidia-smi被扩展以显示它其中的cuda版本号,它将使用当前配置的路径来决定使用哪个cuda版本,关于运行时api的更多信息,请参见CUDA C Programming Guide中关于cuda C运行时的章节
准备部署
测试cuda可用性
当部署cuda应用时,即便目标机没有支持cuda的GPU或者没有安装指定版本的英伟达驱动,我们还是需要保证应用能够持续地正确工作(面向单一且有着明确配置的机器开发的程序员可以跳过这一章)。
检测一个支持cuda的GPU
当一个应用将被部署到没有具体配置的目标机上时,应用应该为一个已有的支持cuda的GPU上先测试一遍,以便当没有者这种设备时我们能够采取正确的行动。函数cudaGetDeviceCount()可以被用来查询可用的设备数量,像所有的cuda运行时API一样,如果没有支持cuda的GPU时这个函数会返回cudaErrorNoDevice,如果没有安装正确版本的英伟达驱动,它会返回cudaErrorInsufficientDriver。如果这两个错误有一个发生,我们就应该在另一个代码路径下运行这个程序。
有多个GPU的系统可能包含不同硬件版本和能力的GPU,当一个应用使用多个GPU时,我们建议使用同一种类型的GPU,而不是使用多种硬件。函数cudaChooseDevice()可以被用来选择最和指定特征集匹配的设备。
检测硬软件配置
当应用能否支持特定功能取决于特定的硬软件应用是否可用时,cuda的api可以被用来查询可用的设备和已安装软件版本的具体信息。cudaGetDeviceProperties()函数汇报了可用设备的各种特征,包括设备的cuda计算能力,详情请参见cuda计算能力和cuda运行时与驱动api相关章节
错误处理
所有的cuda运行时api都会返回错误码cudaError_t,当没有错误发生时,这个代码的值就等于cudaSuccess(除了核启动返回值为void,cudaGetErrorString()函数会返回描述传给它的cudaError_t的字符串这俩函数之外),类似地,cuda工具包的库(cuBLAS、cuFFT等)也会返回它们的错误码。
因为一些cuda api调用和所有的核函数启动都适合主机代码异步的,错误也可能会异步地报给主机。当主机和设备进行下一次同步时(比如调用cudaMemcpy()或cudaDeviceSynchronize()),这种情况时有发生。一定要检查所有cuda api函数的返回值,即便一些函数不太会出错,因为这样会允许应用及早地检测并从错误中恢复,否则,应用可能时不时地在没有注意到被GPU计算的数据是否是不完整的、无效的或者初始化的情况下,就完成了运行(运行完成却出错)。
构建以获得最大的适配性
每一代支持cuda的设备都有相关的计算能力版本,这个版本指明了这个设备支持的特征集(参见上文cuda计算能力一节),编译构建源文件时可以把一个或多个计算能力版本指定给nvcc编译器,为目标GPU拥有的计算能力编译应用对确保应用核达到最佳表现并且可以利用指定版本GPU提供的特征非常重要。
当一个应用为多个计算能力同时编译(给nvcc加入多个-gencode参数)时,支持单一计算能力的二进制文件就被合并到了可执行文件中,cuda驱动会在运行时根据现有机器的计算能力选择最合适的二进制部分进行运行。如果没有可用的正确cu二进制文件,但是ptx中间代码(一种虚拟指令集,用来做向前兼容)可用,那么核就会被JIT编译器将ptx代码为设备编译成本地的cu文件,如果连ptx也没有,那核启动就只能失败了
在linux下的编译命令为
/usr/local/cuda/bin/nvcc -gencode=arch=compute_20,code=sm_20 -gencode=arch=compute_30,code=sm_30 -gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_50,code=compute_50 -O2 -o mykernel.o -c mykernel.cu其中的nvcc编译选项-arch=sm_XX可以被替换成-gencode参数,如下所示
-gencode=arch=compute_XX,code=sm_XX -gencode=arch=compute_XX,code=compute_XX然而,尽管-arch=sm_XX确实会导致ptx的向后兼容(因为有code=compute_XX的存在),但它只能一次制定一个cuda架构,不能在一个命令行中使用多个-arch=sm_XX参数,所以上面的命令才使用了参数-gencode
cuda工具包的重新发布
用cuda运行时构建的cuda应用要处理设备、内存和核,不像cuda驱动,cuda运行时既不保证向前兼容也不保证向后兼容,因此当使用指向cuda运行时的动态或静态链接时,最好重新发布一下应用的cuda运行时库,这样可以保证用户在没有安装与构建应用时使用的相同版本的cuda时也可以执行可执行文件。
静态链接的cuda运行时
最简单的方法就是静态链接cuda运行时,如果使用cuda5.5或更新版本中的nvcc时,这也是默认做法。静态链接让可执行文件略显庞大,但保证了包含在应用二进制文件中的运行时库函数的版本正确性,而不要求cuda运行时库的单独重发布。
动态链接的cuda运行时
如果出于某种原因,对cuda运行时的静态链接不切实际,那么一个动态链接的cuda运行库也是可用的,这在cuda版本5.0或更早时是默认做法。为了在cuda版本>=5.5中的nvcc编译器中动态链接cuda运行时,我们需要为链接命令加上--cudart=shared参数,否则还是默认的静态链接行为。
当应用和cuda运行时动态链接后,运行时库的版本应该和应用绑定,可以直接把指定版本的cuda复制到应用可执行文件的目录下或者应用的安装目录的子目录下
其他cuda库
尽管cuda运行时提供了静态链接选项,但cuda工具包中的其他库(cuBLAS、cuFFT等)只能进行动态链接,所以发布应用时,这些库就得和应用可执行文件绑定在一起,具体方法参见上一段
cuda工具包重发布
cuda工具包的终端用户授权协议(EULA)允许某些情况下对许多cuda库的重新发布,这允许依赖于这些库的应用针对它们构建测试的库重新发布准确的版本,从而避免了对那些可能使用不同版本的cuda的用户(或者压根儿没有cuda的)造成麻烦,详情请参见EULA。
- 重发布哪些文件
当重发布一个或多个cuda库的动态链接版本时,知道哪些文件需要被重发布是很重要的,下面的例子使用cuda工具包10.0的cuBLAS来做解释。
在linux平台上的共享库中,存在着一个名为SONAME的字符串字段来表明库的二进制适配情况,应用使用的SONAME二进制库必须匹配和应用重发布的库的名字。比如,在标准的cuda工具包安装目录中,文件libcublas.so和libcublas.so.10.0都指向一个cuBLAS的具体构建,其名字是libcublas.so.10.0.x(这里x是130)

然而,这个库的SONAME是libcublas.so.10.0

因为如此,即便-lcublas(不指定版本)被用来链接应用,在链接时找到的SONAME暗示着libcublas.so.10.0就是动态加载器在加载应用时要找的文件名,从而这也必须是和应用一起重新发布的文件名(或者符号连接名)。
ldd工具对于识别应用希望在运行时找到的库文件名以及在给定库搜索路径下加载应用时,动态链接器要搜索的库的拷贝的路径(如果有的话)

- 到哪儿安装重新发布的cuda库呢
一旦正确的用来重发布的库文件被识别,他们就必须被配置到应用能够找到他们的路径下以便进行安装,在linux上,链接参数-rpath应该被用来向可执行文件中指示在搜索系统路径前应该上哪儿搜索这些库:
nvcc -I $(CUDA_HOME)/include -Xlinker "-rpath '$ORIGIN'" --cudart=shared -o myprogram myprogram.cu基础设施部署工具
nvidia-smi
nvidia-smi(nvidia系统管理接口)是一个帮助管理监控英伟达GPU设备的命令行工具,这个工具允许管理员查看和修改GPU设备的状态。nvidia-smi是为Tesla和某些Quadro GPU量身定做的,但在别的英伟达gpu上也有有限的支持,它适合linux、64位Windows Server 2008 R2和Win7的英伟达GPU显卡绑定的,可以用XML或人类可读的纯文本来输出查询信息,或者输出到一个文件里,我们可以从nvidia-smi文档中查看细节,但注意新版本的nvidia-smi不能保证向后兼容。
可查询的状态
- ECC错误统计:可纠正的单位误差和可检测的双位误差都会被报告,为GPU当前的启动循环和生命周期的错误计数也在其中
- GPU使用率:GPU计算资源和内存接口的使用率会被报告
- 活动的计算进程:运行在GPU上的活动进程列表,以及相应的进程名、进程id和分配的显存会被报告
- 时钟和性能状态:最大和当前时钟速率,以及当前GPU的性能状态(pstate)会为几个重要的时钟域报告
- 温度和风扇转速:当前GPU内核温度以及积极降温时的产品风扇转速会被保安狗
- 电源管理:当前主板电源功率和电源限制会被报告
- 认证信息:各种动态静态认证信息会被报告,包括主办序列号、PCI设备id、VBIOS/Inforom版本号和产品名字
可修改的状态
- ECC模式:关闭或开启ECC报告
- ECC重置:清空单位双位的ECC错误计数
- 计算模式:指示计算进程能否运行在GPU上,以及他们的运行方式是独占式还是并发式
- 持久模式:指示当没有进程和GPU相关时,英伟达驱动是否应该保持装载,大多数情况下要进行装载(使能这个选项)
- GPU重置:通过副总线重置来重新初始化GPU的硬软件状态
NVML
NVML(英伟达管理库)是一个为构建第三方系统管理应用平台提供通过nvidia-smi暴露的查询和命令的C语言接口。作为Tesla部署包的一部分,nvml api可以让开发者通过引入一个头文件的方式使用,它还有一个pdf文档、打桩库和样例应用,请参见http://developer.nvidia.com/tesla-deployment-kit,另外它是向后兼容的。
nvml api也提供了perl和Python的绑定支持,这些绑定包提供和C接口一样的功能,也是向后兼容的,前者可以通过CPAN获取,后者则可以通过PyPI获取。所有这些产品(nvidia-smi、NVML和NVML语言绑定)随着每个cuda发行版的更新而更新,产品间的功能大多类似
详情请参见http://developer.nvidia.com/nvidia-management-library-nvml
集群管理工具
管理GPU集群可以帮助我们获取最大的GPU利用率和最好的表现,大部分行业中最流行的集群管理工具都通过NVML支持cuda的GPU,详情参见http://developer.nvidia.com/cluster-management
JIT编译缓存管理工具
被应用在运行时加载的任何ptx设备代码被设备驱动进一步编译成二进制文件,这就是即时编译(JIT),即时编译增加了应用的加载时间但是允许应用从最新的编译器升级中收益,这也是应用运行在它编译时还不存在的设备上的唯一方法。当ptx设备代码的即时编译被使用时,英伟达设备会把产生的二进制代码缓存到磁盘上,缓存地址、最大缓存数量等可以通过环境变量的使用来进行控制,详情请参见CUDA C Programming Guide的即时编译部分
cuda可见的设备
通过CUDA_VISIBLE_DEVICES环境变量,可以在cuda应用启动前重新安排它可见、可枚举的已安装cuda设备集合,需要对应用可见的设备做为一个以,为分隔符的列表被包含在一个系统层面的枚举列表中,比如,如果只想使用系统设备列表中的设备0和2,那么在应用启动前,设置CUDA_VISIBLE_DEVICES=0,2即可,应用启动后,会分别把设备0和2枚举称为设备0和1
附录A 最佳实践和建议
此附录包含了本文做出的优化的一个总结
性能优化的演进包含三个基本策略:最大化并行执行、优化内存使用以达到最大内存带宽、优化指令的使用以达到最大的指令吞吐
最大化并行执行起步于用尽可能多的暴露数据并发度的方式组织算法(就是尽量让更多的数据并发处理),一旦算法开始并行执行,就要尽可能有效地将并行映射到硬件上,这可以通过为每个核启动仔细地选择执行配置来实现。应用还应该通过用流来明确地在设备上进行并发执行和最大化主机与设备之间的执行并行度来最大化并行度
优化内存使用起步于减少主机和设备之间的数据传输,因为这种传输有着比设备内部数据传输低得多的带宽,核函数也应该通过尽量访问设备上的共享内存来减少对全局内存的访问。有时,仅仅通过尽量重新计算数据来避免任何数据传输就是最佳优化的开山之斧。
根据各种类型内存访问模式的不同,它们的有效带宽可能差着几个数量级,所以优化内存使用的下一步就是根据最优内存访问模式来组织内存的访问,因为访问延迟的损失可能高达几百个时钟周期。相比之下,只有存在高度银行冲突的时候共享内存才值得去优化。
对于指令使用的优化,低吞吐量的算术指令应该被避免,当准确率不影响最终结果时,建议牺牲它以换取更快的速度(比如使用本地函数而非常规函数,或者用单精度代替双精度)。最后,由于设备的单指令的多线程执行属性,控制流指令应该被格外关注。
附录B nvcc编译切换
英伟达的nvcc编译器可以把cu文件为主机系统转换成c文件,也可以将其为设备转换成cuda汇编或者二进制指令,它支持大量的命令行参数,这些参数对优化和相关的实践很有用:
- -maxrregcount=N指定了每个核在文件层面可以使用的最大寄存器数量,请参见上文寄存器压力一节,也可以参见CUDA C Programming Guide中运行配置中关于__launch_bounds__标识符的讨论,这也是用来控制每个核上能使用的寄存器数量的;
- --ptxas-options=-v或者-Xptxas=-v可以列举每个核的寄存器内存、共享内存和常量内存的使用情况;
- -ftz=true(把非标准化的数清零);
- -prec-div=false(降低除法的准确度);
- -prec-sqrt=false(降低取平方根的准确度);
- -use_fast_math把不带下划线的数学函数转换成带下划线的数学函数,用来牺牲准确度和精度来提高运行速率,参见数学库一节
结语
cuda10.0的最佳实践就翻译完了,有问题欢迎探讨