Redis 常用知识总结(二)
Reids 单线程和高性能
单线程
- 单线程指的是网络请求模块使用了一个线程(所以不需考虑并发安全性),即一个线程处理所有网络请求,其他模块仍用了多个线程。
高性能
- 数据在内存中,所有的运算都是内存级别的运算,单线程避免多线程切换消耗资源问题。
Redis单线程处理并发客户端
- Redis 的IO多路复用:redis利用epoll实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
Redis 持久化
RDB(Redis DataBase)
- 不同的时间点,将redis存储的数据生成快照并且存储到磁盘等介质上。
AOF(Append Only File)
-
AOF,则是换了一个角度来实现持久化,那就是将 redis 执行过的所有写指令记录下来,在下次 redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
-
RDB和AOF可以同时使用,在这种情况下,如果Redis重启的话,则会优先采用AOF的方式进行数据恢复,因为AOF的恢复数据的完整度高。
常用数据结构
String
字符串常用操作:key value
用的比较频繁,在redis中key是String类型的,value 是String类型的。
set key value // 存入字符串键值对
get key // 获得key存储的value
del key // 删除key存储的值
mset test1 one test2 two // 存储多个键值
mget test1 test2 // 查找多个key的值
setnx test zhangsan // 只有key 不存在时候插入
expire test 5 // 设置test键5秒过期
原子加减
incr count // 键count存的值+1
decr count // 键count存的值-1
incrby a 7 // 给a存的值加上7
decrbt a 7 // 给a存的值-7
String应用场景
- 单值缓存
set test zhangsan
get test
- 对象缓存
set people:1:id 10001
- 分布式锁
setnx count:1000 true // 1代表获取锁成功
setnx count:1000 true // 0代表获取锁失败
del count:1000 // 释放锁 返回1
set product:1000 true ex 10 nx //防止死锁
- 计数器
incr article:count:{
test} // test这篇文章的阅读量+1
get article:count:{
test}
-
Session共享
-
分布式系统全局序列号
Hash
Hash常用操作:key field value
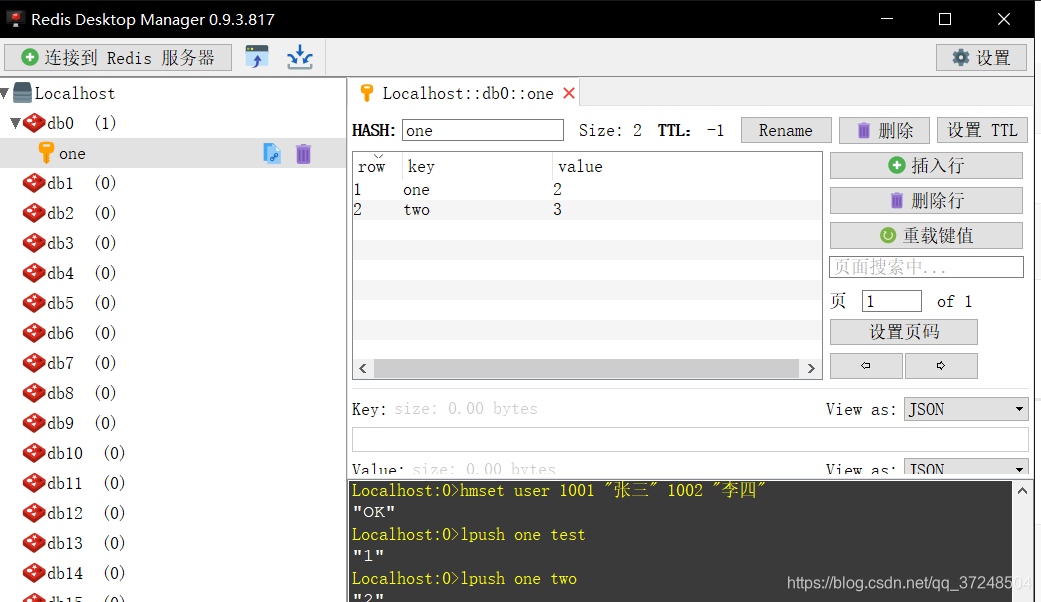
hset one test2 "test2" //存储一个哈希表key的键值
hget one test2 // 获得哈希表中某个键的值
hmset one one "2" two "3" // 存储多个key value 在hash one 中
HSETNX key field value //存储一个不存在的哈希表key的键值
HMGET key field [field ...] //批量获取哈希表key中多个field键值
HDEL key field [field ...] //删除哈希表key中的field键值
HLEN key //返回哈希表key中field的数量
HGETALL key //返回哈希表key中所有的键值
HINCRBY key field increment //为哈希表key中field键的值加上增量
Hash应用场景
- 对象存储
hmset user 1001 "张三" 1002 "李四"
Hash结构优缺点
- 优点:消耗内存和Cpu更小,相比string储存更节省空间
- 缺点:过期功能不能使用在field上,只能用在key上。Redis集群架构下不适合大规模使用。
List
List常用操作
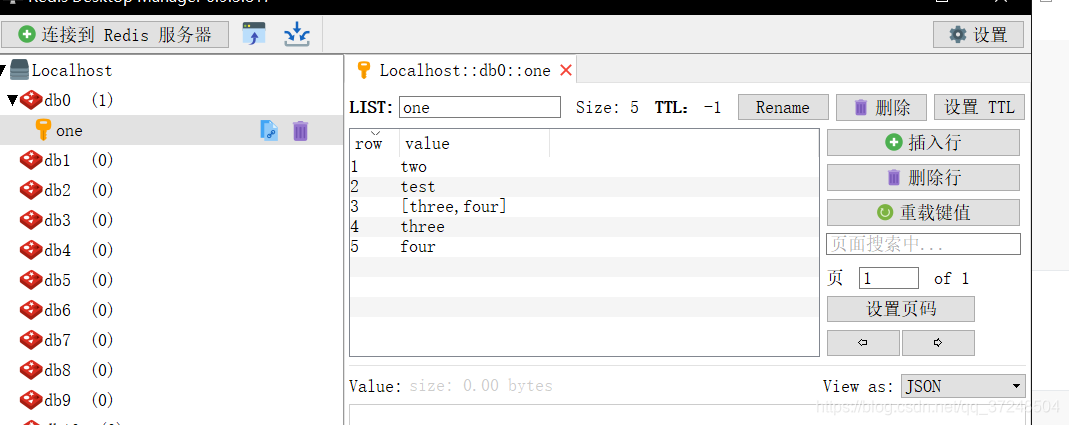
lpush one two //将一个或多个值value插入到key列表的表头(最左边)
rpush key value //将一个或多个值value插入到key列表的表尾(最右边)
LPOP key //移除并返回key列表的头元素
RPOP key //移除并返回key列表的尾元素
LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key ...] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key ...] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待
List应用场景
- 常用数据结构
- Stack(栈) = LPUSH + RPOP (FILO)
- Queue(队列)= LPUSH +LRPOP (FIFO)
- Blocking MQ(阻塞队列)= LPUSH + BRPOP
Set
Set常用操作
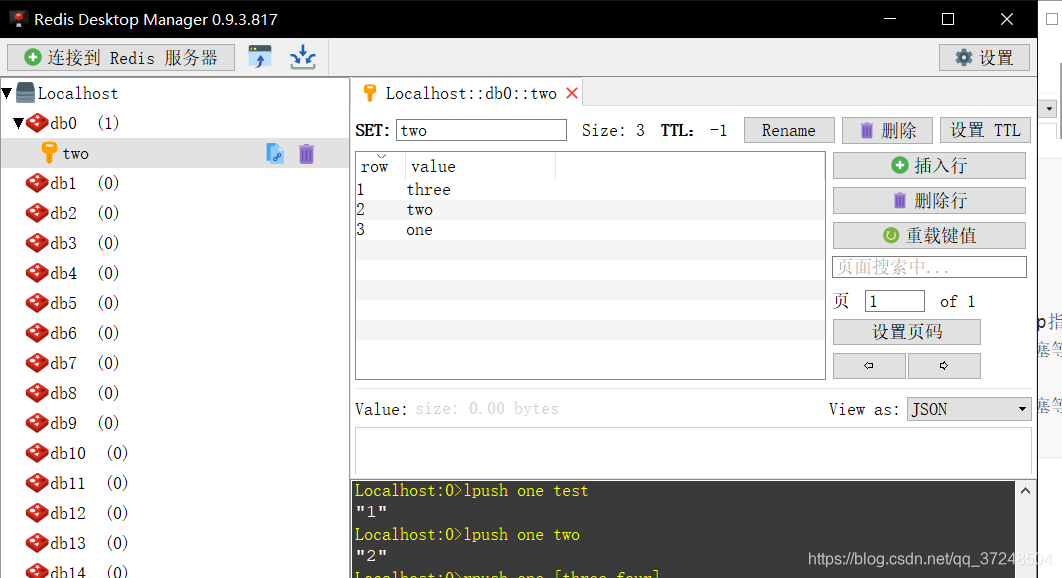
sadd two one two three // 添加key 为two value
SREM key member [member ...] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
- 运算操作
SINTER key [key ...] //交集运算
SINTERSTORE destination key [key ..] //将交集结果存入新集合destination中
SUNION key [key ..] //并集运算
SUNIONSTORE destination key [key ...] //将并集结果存入新集合destination中
SDIFF key [key ...] //差集运算
SDIFFSTORE destination key [key ...] //将差集结果存入新集合destination中
ZSet
ZSet常用操作
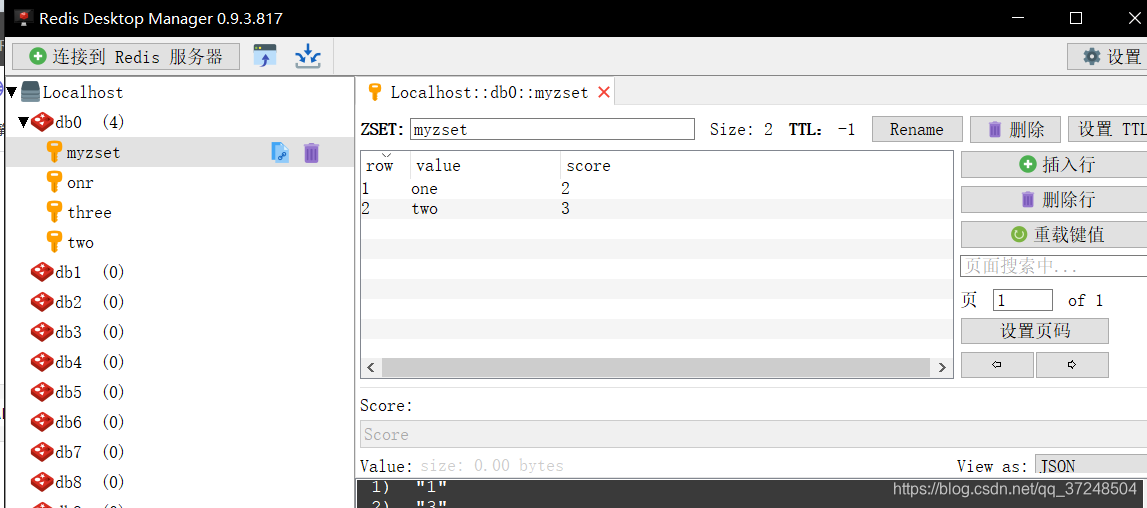
ZADD myzset 1 "one" //往有序集合key中加入带分值元素
ZREM key member [member …] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES]//倒序获取有序集合key从start下标到stop下标的元素
Zset应用
1. 点击新闻:
ZINCRBY hotNews:20201221 1 完善低龄未成年人犯罪规定
2. 展示当日排行前十:
ZREVRANGE hotNews:20201221 0 9 WITHSCORES
3. 七日搜索榜单计算:
ZUNIONSTORE hotNews:20201215-20201221 7
hotNews:20201215 hotNews:20201216... hotNews:20201221
4. 展示七日排行前十:
ZREVRANGE hotNews:20201215-20201221 0 9 WITHSCORES
缓存穿透、缓存雪崩
缓存穿透
- 一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
- 对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
- 对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
缓存雪崩
- 当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
- 做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
- 不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。