1 概述:
1.1 环境
版本信息如下:
a、操作系统:centos 7.6
c、kubernetes版本:v1.15.0
1.2 故障恢复时期下的dns查询延时的现象
kubernetes dns的实现是coredns,以Deployment的形式双副本分别部署两个节点
。一个coredns实例立刻死亡(服务器瞬间宕机,k8s service流量未进行切除),业务pod查询dns时,有机会得到dns服务器的时间长达15秒的失败响应(因为/etc/resolv.conf文件默认超时5秒,重试2次)。等kuberntes将service流量进行了摘除(体现在iptables nat表或lvs规则,摘除效果一般是服务器宕机后的40秒左右生效),此15秒延时的现象会消失,因为10.96.0.10只能被DNAT为正常运行的pod的IP。
对cni0网卡进行抓包,udp日志如下,一共三条日志,一个日志条目就是一次限制为5秒超时的查询(随机的源端口保持不变,在这次日志中是41805),重试2次,因此一共是3条记录,一共15秒。可见在故障恢复期间,业务容器使用同一个源端口往目标已宕机的dns容器狂干15秒。
# 10.96.0.10 被DNAT成 10.244.1.52.53,狂干15秒
21:27:52.521261 IP 10.244.0.80.41805 > 10.244.1.52.53: 51985+ AAAA? kubernetes.default.svc.cluster.local. (54)
21:27:57.521607 IP 10.244.0.80.41805 > 10.244.1.52.53: 51985+ AAAA? kubernetes.default.svc.cluster.local. (54)
21:28:02.522524 IP 10.244.0.80.41805 > 10.244.1.52.53: 51985+ AAAA? kubernetes.default.svc.cluster.local. (54)
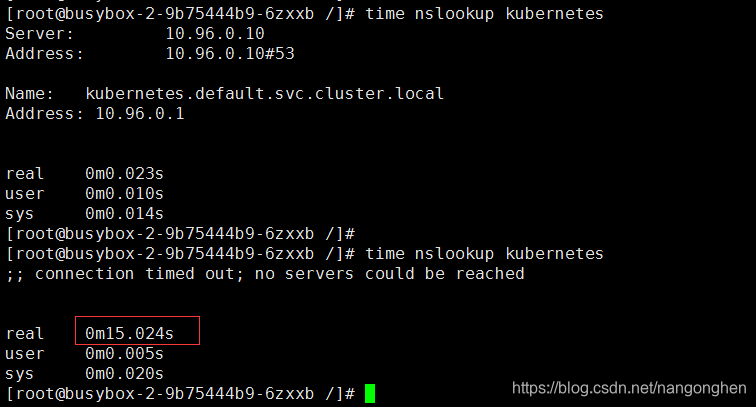
2 延时缓解方式:
在/etc/resolv.cnf文件中使用多个nameserver字段,竟然可奇妙地将延时从15秒降至2秒(centos7容器是2秒,并且通过抓包分析,2秒大部分消耗在往宕机的coredns查询A记录和AAAA记录)。我将Deployment形式的coredns换成Statefulset模式,每个pod都有一个固定的service,这些service的IP就写入/etc/resolv.cnf文件中的nameserver字段。
2.1 coredns StatefulSet的yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
k8s-app: kube-dns
name: coredns
namespace: kube-system
spec:
replicas: 2
selector:
matchLabels:
k8s-app: kube-dns
serviceName: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostname
containers:
- args:
- -conf
- /etc/coredns/Corefile
image: 192.168.1.70:5000/coredns:1.3.1
imagePullPolicy: IfNotPresent
readinessProbe:
failureThreshold: 2
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
livenessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
name: coredns
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 8080
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
volumeMounts:
- mountPath: /etc/coredns
name: config-volume
readOnly: true
dnsPolicy: Default
nodeSelector:
beta.kubernetes.io/os: linux
priorityClassName: system-cluster-critical
restartPolicy: Always
serviceAccount: coredns
serviceAccountName: coredns
terminationGracePeriodSeconds: 30
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- effect: NoSchedule
key: node-role.kubernetes.io/master
volumes:
- configMap:
defaultMode: 420
items:
- key: Corefile
path: Corefile
name: coredns
name: config-volume
2.2 coredns configmap的yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
2.4 coredns service的yaml(两个service)
apiVersion: v1
kind: Service
metadata:
labels:
statefulset.kubernetes.io/pod-name: coredns-0
k8s-app: kube-dns
name: coredns-0
namespace: kube-system
spec:
clusterIP: 10.96.0.11
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
- name: metrics
port: 9153
protocol: TCP
targetPort: 9153
selector:
k8s-app: kube-dns
statefulset.kubernetes.io/pod-name: coredns-0
sessionAffinity: None
type: ClusterIP
---
apiVersion: v1
kind: Service
metadata:
labels:
statefulset.kubernetes.io/pod-name: coredns-1
k8s-app: kube-dns
name: coredns-1
namespace: kube-system
spec:
clusterIP: 10.96.0.12
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
- name: metrics
port: 9153
protocol: TCP
targetPort: 9153
selector:
k8s-app: kube-dns
statefulset.kubernetes.io/pod-name: coredns-1
sessionAffinity: None
type: ClusterIP
3 缓解的效果:
coredns-0运行在master服务器,coredns-1运行在node1服务器,他们前面都有一个同名的k8s service。

位于master服务器上的业务容器centos会优先去查询node1上的coredns,因为nameserver第一个值是10.96.0.12(正是node1服务器上的实例coredns-1的service)。
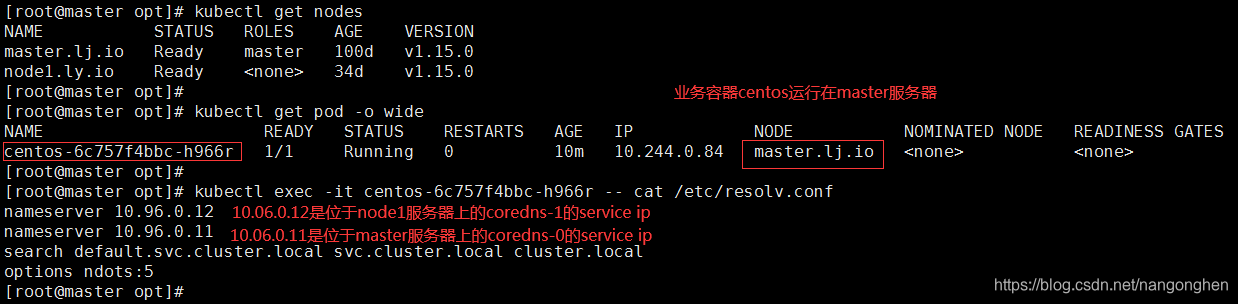
node1服务器立马关机,业务容器中的nslookup命令消耗了2秒(如果彻底关闭ipv6,则消耗会变成1秒,因为不查询AAAA记录。)。在本文的情景中,此2秒现象会一直持续,直到node1上的coredns恢复正常运行。
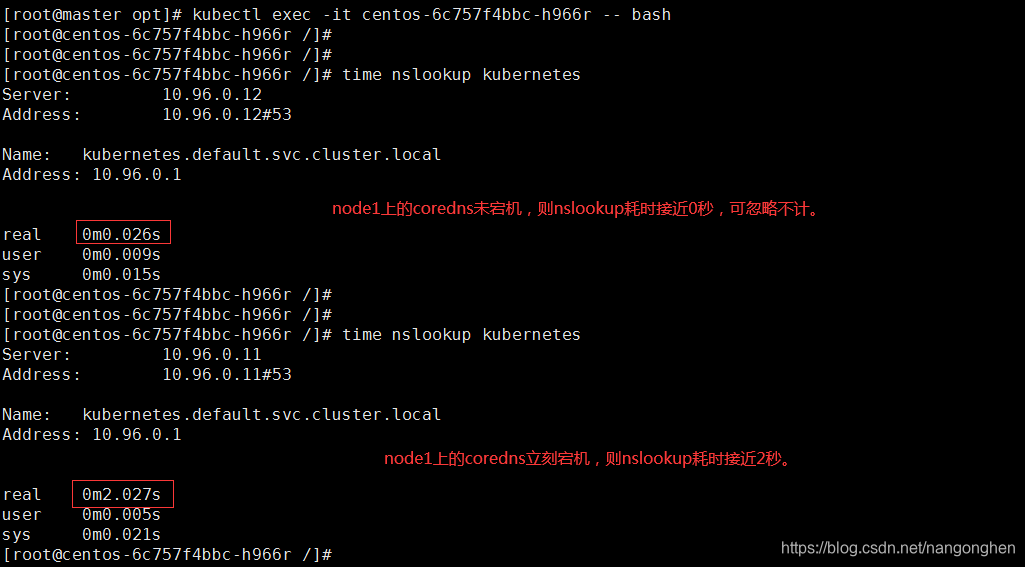
4 总结:
在/etc/resolv.conf文件中使用多个nameserver,能产生一个dns查询请求快速失败的效果,查询一个nameserver失败则快速向下一个nameserver进行请求。在kubernetes集群中容器,如果/etc/resolv.conf中只包含一个nameserver(例如是10.96.0.10),在故障恢复期间有概率产生多倍延时的效果(业务重试性地向不正常的dns服务器进行查询)。