概述
1)namespace和crgoup是linux内核的特性。namespace负责[ 进程视野上 ]的环境隔离,cgroup负责[ 进程组 ]的资源配额限制。
2)进程和namespace、crgoup的关系
1 )父进程通过 fork 创建子进程时,使用 namespaces 技术(带上namespace相关的参数),实现子进程与父进程以及其他进程之间命名空间的隔离。
2 )子进程创建完毕之后,使用 cgroups技术来处理该进程,实现进程的资源限制。
3)docker项目其实就是通过以上两个步骤来创建一个进程,这样的进程就是一个docker container了。
namespace与docker container
用户执行docker run命令启动一个新容器, [ Docker Daemon ] 会[ fork ] 出容器中的第一个进程 A (暂且称为进程 A ,也就是 Docker Daemon 的子进程),执行此fork操作时带入5个参数标志 CLONE NEWNS , CLONE NEWUTS 、 CLONE NEWIPC 、 CLONEPID 和 CLONE_NEWNET (Docker 1. 2.0 还没有完全支持 user namespace) 。 Clone系统调用一旦传入了这些参数标志,[ 子进程 ] 将不再与[ 父进程 ]共享相同的命名空间( namespaces),而是由Linux为[ 子进程 ] 创建新的命名空间( namespaces),从而保证子进程与父进程使用隔离的环境。
另外,如果子进程 A 再次 fork 出子进程 B ,而此fork操作时没有传入相应的 namespaces 参数标志时,子进程B将会与A共享相同的命名空间( namespaces) 。如果 Docker Daemon再次创建
一个 Docker 容器,内部进程有 D 、 E 和 F ,那么这三个进程也会处于另外全新的 namespaces中。刚刚创建的这两个容器的 namespaces 均与 Docker Daemon 所在的 namespaces 不同。
小结:
Docker Daemon 与 Docker container 之间的 namespaces 关系,如图所示。

cgroup与docker container
cgroup的使用是在创建容器内进程[ 之后 ] 完成,最终使得容器进程处于资源控制的状态。换言之, cgroups 的运用必须要等到容器内第一个进程被真正创建出来之后才能实现。当容器内进程创建完毕, Docker Daemon 可以获知容器内主进程的 PID 信息,随后将该 PID 放置在宿主机的cgroups文件系统的指定位置,做相应的资源限制。如此一来,当容器主进程fork新的子进程时,新的子进程同样受到与主进程相同的资源限制,效果就是整个进程组受到资源限制。


测试
cpu限制


在容器内部查看cgroup配置

在宿主机上查看cgroup配置


开始压测:
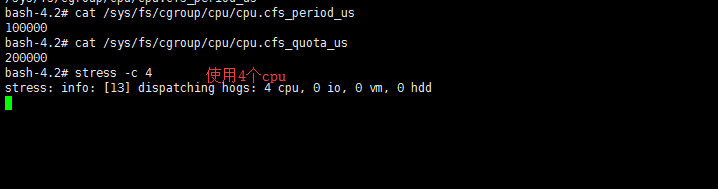
而容器进程最多使用200%的cpu,虽然容器内部进程企图使用4个cpu(即400%cpu)

宿主机上查看,发现容器中一共有6个进程,因为容器中执行[ stress -c 4 ]会另外再启动4个进程,加上容器主进程后,一共是6个进程


内存限制
情景1:关闭swap

情景2:开启了swap

