配置了NILMTK包的环境之后,想找数据测试一下,在NILMTK官网的API Docs里边发现dataset_converters模块中有内置的数据集处理函数,如图:
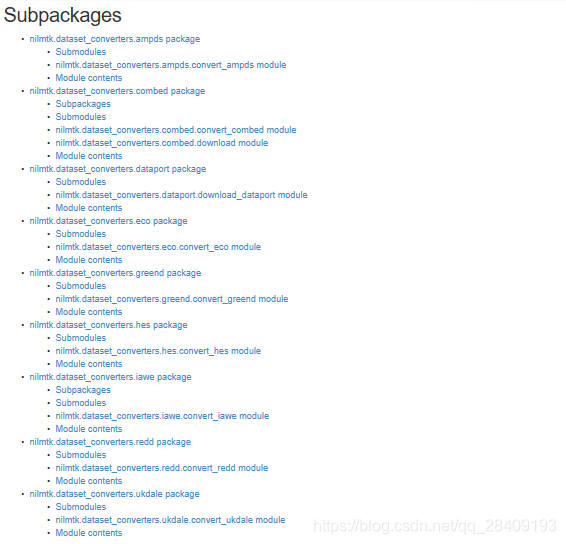
将数据转换成HDF文件,这些数据都是比较优秀的,其中,常用的数据集是REDD和UK_DALE。
1. REDD数据集
目前版本的下载地址为: http://redd.csail.mit.edu,需要向作者发送邮件,才能获取用户名和密码进行下载!
论文为:J. Zico Kolter and Matthew J. Johnson. REDD: A public data set for energy disaggregation research. In proceedings of the SustKDD workshop on Data Mining Applications in Sustainability, 2011. [pdf]
数据集的文件为:

文件主要包含低频功率数据和高频电压电流数据
low_freq:1Hz功率数据
high_freq:校准和分组之后的电压电流波形数据
high_freq_row:原生电压电流波形数据
(1)low_freq的文件目录

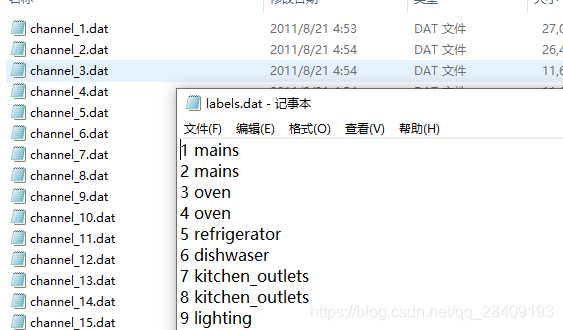
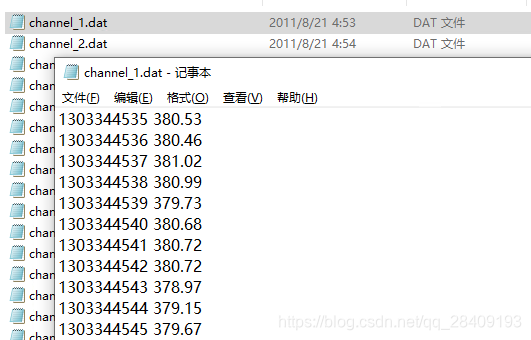
总共收集了6个家庭的数据,labels记录了每个channel的设备类型,channel是记录每个channel的UTC时间戳的功率数据。
labels:
channel(一秒一个点):
(2)high_freq的文件目录

总共收集了6个家庭的数据,current_1记录了第一电源的电流数据,current_1记录了第二电源的电流数据,voltage记录了电压数据。
需要注意的是:
a、十进制的UTC时间戳,与低频的UTC时间戳是一样的格式,但是这个允许有小数部分。
b、循环计数,虽然它在文件中表示为双精度,但实际上它是一个整数,表示该特定波形保留多少交流周期。
c、在等间隔的周期中,275个十进制数值,表示波形的数值
下载完数据集之后,可通过dataset_converters 的函数将数据改为HDF格式:
from nilmtk.dataset_converters import convert_redd
convert_redd(r'C:\Users\admin\Anaconda3\nilm_metadata\low_freq',r'C:\Users\admin\Anaconda3\nilm_metadata\low_freq\redd_low_new.h5')2. REDD数据集的使用
a、负荷分解算法
通过NILMTK官网的API知道负荷分解包的算法有组合优化(CombinatorialOptimisation)、因子隐马尔可夫(FHMM)、Hart 1985(Hart 1985 algorithm),常用的是CO和FHMM。

b、负荷分解实现
以下例子是通过CO和FHMM计算的,文件获取在:
FHMM:nilmtk.legacy.disaggregate文件下的fhmm_exact文件。
- 获取数据:
from __future__ import print_function, division
import pandas as pd
import numpy as np
from nilmtk.dataset import DataSet
#from nilmtk.metergroup import MeterGroup
#from nilmtk.datastore import HDFDataStore
#from nilmtk.timeframe import TimeFrame
from nilmtk.disaggregate.combinatorial_optimisation import CombinatorialOptimisation
from nilmtk.legacy.disaggregate.fhmm_exact import FHMM
train = DataSet('C:/Users/admin/PycharmProjects/nilmtktest/low_freq/redd_low.h5') # 读取数据集
test = DataSet('C:/Users/admin/PycharmProjects/nilmtktest/low_freq/redd_low.h5') # 读取数据集
building = 1 ## 选择家庭house
train.set_window(end="30-4-2011") ## 划分数据集,2011年4月20号之前的作为训练集
test.set_window(start="30-4-2011") ## 四月40号之后的作为测试集
## elec包含了这个家庭中的所有的电器信息和总功率信息,building=1-6个家庭
train_elec = train.buildings[1].elec
test_elec = test.buildings[1].elec
top_5_train_elec = train_elec.submeters().select_top_k(k=5) ## 选择用电量排在前5的来进行训练和测试
选取了第一个家庭,用电量在前5的电器数据进行测试。
- 计算:
def predict(clf, test_elec, sample_period, timezone): ## 定义预测的方法
pred = {}
gt= {}
#获取总的负荷数据
for i, chunk in enumerate(test_elec.mains().load(sample_period=sample_period)):
chunk_drop_na = chunk.dropna() ### 丢到缺省值
pred[i] = clf.disaggregate_chunk(chunk_drop_na) #### 分解,disaggregate_chunk #通过调用这个方法实现分解,这部分代码在下面可以见到
gt[i]={} ## 这是groudtruth,即真实的单个电器的消耗功率
for meter in test_elec.submeters().meters:
# Only use the meters that we trained on (this saves time!)
gt[i][meter] = next(meter.load(sample_period=sample_period))
gt[i] = pd.DataFrame({k:v.squeeze() for k,v in gt[i].items()}, index=next(iter(gt[i].values())).index).dropna() #### 上面这一块主要是为了得到pandas格式的gt数据
# If everything can fit in memory
gt_overall = pd.concat(gt)
gt_overall.index = gt_overall.index.droplevel()
pred_overall = pd.concat(pred)
pred_overall.index = pred_overall.index.droplevel()
# Having the same order of columns
gt_overall = gt_overall[pred_overall.columns]
#Intersection of index
gt_index_utc = gt_overall.index.tz_convert("UTC")
pred_index_utc = pred_overall.index.tz_convert("UTC")
common_index_utc = gt_index_utc.intersection(pred_index_utc)
common_index_local = common_index_utc.tz_convert(timezone)
gt_overall = gt_overall.ix[common_index_local]
pred_overall = pred_overall.ix[common_index_local]
appliance_labels = [m.label() for m in gt_overall.columns.values]
gt_overall.columns = appliance_labels
pred_overall.columns = appliance_labels
return gt_overall, pred_overall
classifiers = { 'CO':CombinatorialOptimisation(),'FHMM':FHMM()} ### 设置了两种算法,一种是CO,一种是FHMM
predictions = {}
sample_period = 120 ## 采样周期是两分钟
for clf_name, clf in classifiers.items():
print("*"*20)
print(clf_name)
print("*" *20)
clf.train(top_5_train_elec, sample_period=sample_period) ### 训练部分
gt, predictions[clf_name] = predict(clf, test_elec, 120, train.metadata['timezone'])先用clf.train训练这5种电器的特征规律,然后在用总的功率数据进行各种电器特征分解。gt记录了每个电器的功率数据,采样周期是两分钟一个点,后边根据预测的电器种类选取了用电量排名比较高的5种电器。
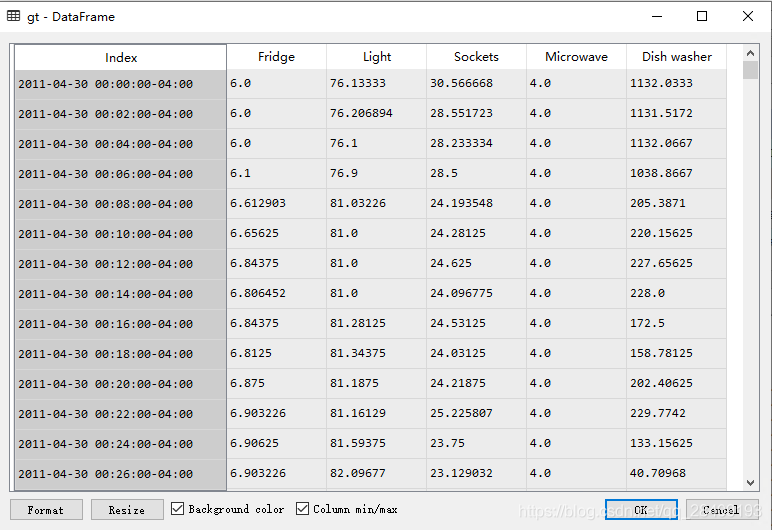
predictions变量记录了两个算法的计算结果:

- 评估:
def compute_rmse(gt, pred): ### 评估指标 rmse
from sklearn.metrics import mean_squared_error
rms_error = {}
for appliance in gt.columns:
rms_error[appliance] = np.sqrt(mean_squared_error(gt[appliance], pred[appliance])) ## 评价指标的定义很简单,就是均方根误差
return pd.Series(rms_error)
rmse = {}
for clf_name in classifiers.keys():
rmse[clf_name] = compute_rmse(gt, predictions[clf_name])
rmse = pd.DataFrame(rmse)计算结果为:

参考博客:https://blog.csdn.net/baidu_36161077/article/details/81144037