写在前面
在使用SQL进行各种各样的数据提取时,一个常用的操作是按照某种标准为数据分组。不仅是使用SQL的时候,在日常生活中整理或者分析数据时,我们也经常需要给数据分组。
SQL的语句中具有分组功能的是GROUP BY和PARTITION BY,它们都可以根据指定的列为表分组。区别仅仅在于,GROUP BY在分组之后会把每个分组聚合成一行数据。
集合论和group by
有如下表
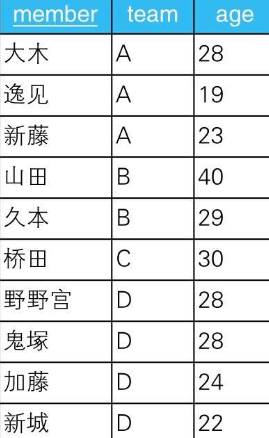
对这张表使用GROUP BY或者PARTITION BY,可以获取以团队为单位的信息。无论使用哪一个,都可以将原来的表Teams分割成下面几个子集,然后通过SUM函数进行聚合,或者通过RANK函数计算位次。
SELECT member, team, age ,
RANK() OVER(PARTITION BY team ORDER BY age DESC) rn,
DENSE_RANK() OVER(PARTITION BY team ORDER BY age DESC) dense_rn,
ROW_NUMBER() OVER(PARTITION BY team ORDER BY age DESC) row_num
FROM Members
ORDER BY team, rn;

分割后的子集如下图所示。

它们有下面这3个性质。
1.它们全都是非空集合。
2.所有子集的并集等于划分之前的集合。
3.任何两个子集之间都没有交集。
因为这些子集都是通过表中存在的“team”列的值分割出来的,所以不可能存在空集。而且,将分割后的子集全部加起来,很明显就是原来的集合。换句话说,分割之后不存在没有归属的成员。
不存在同时属于两个子集(=同时属于多个团队)的成员。一个成员一定只属于分割后的某个子集。所以我们也可以认为,GROUP BY和PARTITION BY都是用来划分团队成员的函数。
在数学中,满足以上3个性质的各子集称为“类”(partition),将原来的集合分割成若干个类的操作称为“分类”。这些都是群论等领域的术语。被分割出来的类,和“分类”中的“类”意思是相同的,很好理解。
SQL中PARTITION BY子句的名字就来自于类的概念(即partition)。虽然我们可以让GROUP BY子句也使用这个名字,但是因为它在分类之后会进行聚合操作,所以为了避免歧义而采用了不同的名字。一般来说,我们可以采取多种方式给集合分类。在SQL中也一样,如果改变GROUP BY和PARTITION BY的列,生成的分组就会随之变化。
在SQL中,GROUP BY的使用非常频繁,由此可以知道我们身边存在着很多类。例如学校中的班级和学生的出生地等。没有学生的班级是没有存在意义的,而出生地为两个省的人应该也是不存在的(出生地不详的人可能会有,但是这样的人应该属于列为NULL的类)。
SQL中的取模可以做什么?
求剩余类会将自然数集合分割成大小相等的一些类,所以在需要***从大量数据中按照特定比例抽样的时候非常方便***。例如,使用下面的查询语句可以随机地将数据减为原来的五分之一(表中没有连续编号的列时,使用ROW_NUMBER函数重新编号就可以了)。
原表大小约是9W笔数据,使用如下sql可取出其中的1/5.
select count( 1 )
from( select *, row_number() over(
order by glass_id ) as seq1
from sor.wpp_adefect_f_n ) t
where mod( seq1, 5 )= 0;
上面的查询语句肯定满足“随机地等分数据”这一随机抽样的需求。