
上一篇文章介绍了 Pandas 的基本函数的使用方法,这篇文章主要介绍 Pandas 的条件筛选和排序功能,同样也是借助于一个小案例!
1,读入数据
先利用 read_csv() 函数 把数据都进来,这个数据是一个商品类目的数据,里面有 quantity(类)、name(名字)、description(描述)、price(价格)等几个属性:
import pandas as pd
url = "https://raw.githubusercontent.com/justmarkham/DAT8/master/data/chipotle.tsv"
chipo = pd.read_csv(url,sep = '\t')
chipo
2,更改某一列的数据类型、字符名
读入的数据中价格列中存在 “$”字符,做数据处理时,需要把该符号去除,这里提供两种方式:
1,list 与 series 替换;先把 某一列每个数据进行格式替换得到list,list 再赋值给需要替换的那一列;
prices = [float(value[1:-1]) for value in chipo.item_price]
chipo.item_price = prices2,利用 apply() 和 lambda 函数进行替换;
chipo['item_price'] = chipo['item_price'].apply(lambda x:float(x[1:-1]))
3,剔除多列中重复出现的数据
处理数据时经常会出现数据冗余现象,这时需要提前剔除数据中冗余的数据(行中多列数据重复的现象),用到的函数为 drop_duplicates(['列名1','列名2'])函数
这里 去除的是 item_name、quantity、choice_description 三列中同时重复的数据:
chipo_filtered = chipo.drop_duplicates(['item_name','quantity','choice_description'])
chipo_filtered
4,条件筛选
1,筛选出 quantity 值为1的数据:
chipo_one_prod = chipo_filtered[chipo_filtered.quantity==1]
chipo_one_prod
2,在1的基础上,筛选出 item_price大于10 的数据,并利用 nunique 查看 item_name 不重复的数据个数:
chipo_one_prod[chipo_one_prod['item_price']>10].item_name.nunique()
# 输出结果
# 25 3,2 中的条件筛选也可用 语句进行筛选:
chipo.query("item_price>10")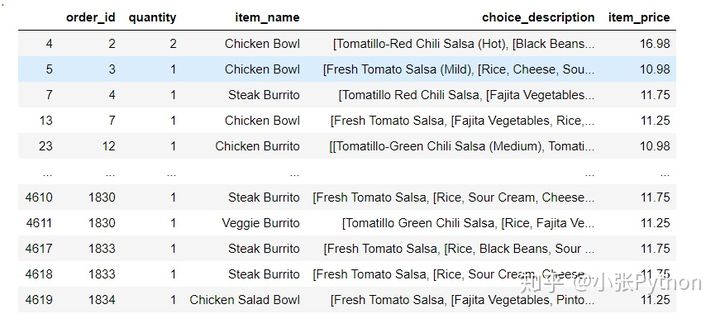
4,多条件筛选数据,筛选出同时满足 item_name 为 Chicken Bowl 和 quantity 为1的数据
chipo[(chipo['item_name']=='Chicken Bowl')&(chipo['quantity']==1)]
5,4 中用的 &(与) 衔接条件语句,这里尝试以下 |(或):
需满足 item_name 不为Chicken Bowl 或者 quantity 为1的数据
chipo[(chipo['item_name']!='Chicken Bowl')|(chipo['quantity']!=1)]
4,对指定列数据排序
1,对某一列数据排序,最终结果只展示排序后这一列的结果,命令语句:data.列名.sort_values() ,例如这里以 item_name 这一列数据进行排序:
chipo.item_name.sort_values()# Sorting the values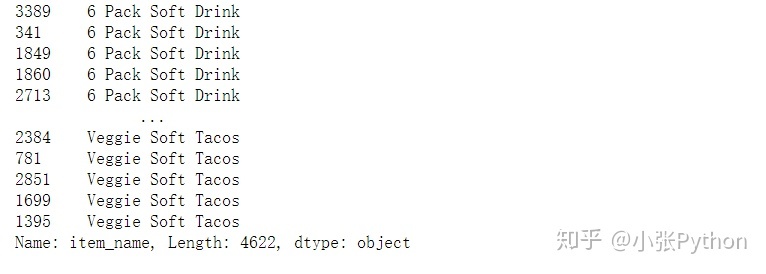
2,而 data.sort_values(by=列名) 是以某列数据进行排序,对应其他列数据下也需要位置改变,最终展示的排序后的全部数据
chipo.sort_values(by = 'item_name')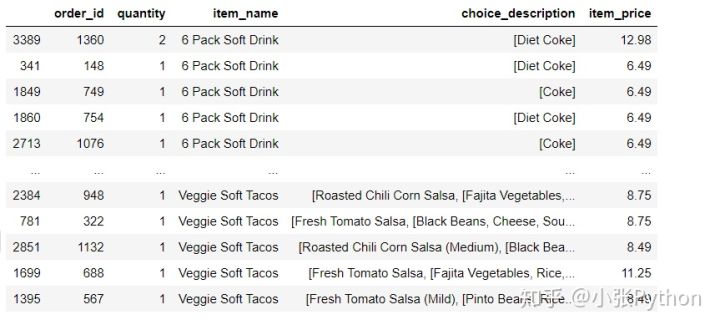
3,2中的进阶应用,例如,这里我想看数据中价格最贵的商品名称,这里先用2的方法 对 item_price 进行逆排,然后提取排序后数据第一行的item_name
chipo.sort_values(by = 'item_price',ascending = False).head(1).item_name
# 打印结果
# 3598 Chips and Fresh Tomato Salsa
Name: item_name, dtype: object5,data.loc 方法筛选数据
注意一下:利用data.loc 方法筛选数据时,只能以 行名、列名作为筛选条件
1,筛选出 行名为2、3,列名为 quantity、item_name、item_price的数据
chipo.loc[[2,3],['quantity','item_name','item_price']]
2,对行名不做限制,只筛选出列名为quantity、item_name 数据
chipo.loc[:,['quantity','item_name']]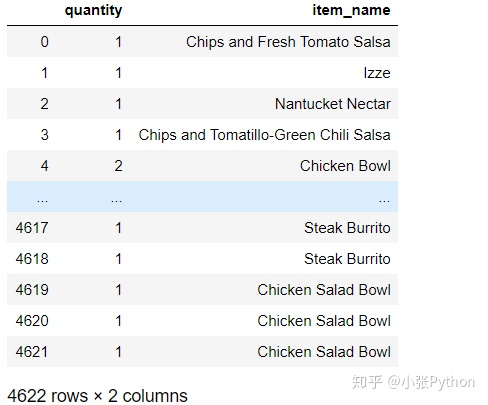
3,对列名不做限制,只筛选出行名为5、6的 数据
chipo.loc[[5,6],:]
4,综合应用筛选出:行名能被8整除、列名为 item_price、item_name 的两列数据
chipo.loc[chipo.index%8==0,['item_name','item_price']]
6,data.iloc 方法筛选数据
data.iloc 与 data.loc 方法想法,只能以索引值进行晒选,不能以列名、行名作为筛选条件
1,筛选出第 5-8行、2-3 列的数据
chipo.iloc[4:8,1:3]
2,筛选出第 2-4 行数据;
chipo.iloc[1:4,:]
3,筛选出前两列数据:
chipo.iloc[:,:2]
以上就时本篇文章的全部内容啦,对里面某些方法的应用不太熟悉的小伙伴们记得跟着代码敲一遍,加深下理解!