大家好:
在spark的开发中,有时需要将数据按照某个字段进行分开存储,这就需要用到spark的自定义分区的功能。
先说测试数据,放在文件"C:\test\url1.log"中,数据如下所示:
20170721101954 http://sport.sina.cn/sport/race/nba.shtml
20170721101954 http://sport.sina.cn/sport/watch.shtml
20170721101954 http://car.sina.cn/car/fps.shtml
20170721101954 http://sport.sina.cn/sport/watch.shtml说明: 仅仅用四条数据,能说明效果即可,是按照访问网页的主机名进行汇总的。
SPARK中实现自定义分区,代码如下所示:
package day04
import java.net.URL
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import scala.collection.mutable
/**
* 功能: 演示 程序代码中的自定义分区
*
*/
class NewPartiton(fornum:Array[String]) extends Partitioner{
val partmap=new mutable.HashMap[String,Int]()
var count= 0 // 表示分区号
// 对for循环的目的是使 每个host 作为一个分区
for( i <- fornum){
partmap += (i->count)
count += 1
}
// 为了保证每一个域名有一个分区,就用fornum.length的形式 源码用到
override def numPartitions: Int = fornum.length
//获得每个key的分区号 源码用到
override def getPartition(key: Any): Int = {
partmap.getOrElse(key.toString,0)
}
}
object Partition{
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("UrlCount").setMaster("local[2]")
val sc=new SparkContext(conf)
val lines=sc.textFile("c://test//url1.log")
// 20170721101954 http://sport.sina.cn/sport/race/nba.shtml
val text=lines.map(line=>{
val f=line.split("\t")
(f(1),1) //最后一行作为返回值的 先给每个域名 后面增加1
})
val text1=text.reduceByKey(_+_) //统计每个域名的个数
// println(text1.collect.toBuffer)
// http://sport.sina.cn/sport/race/nba.shtml 1
val text2=text1.map(t=>{
val url=t._1 //每个url
val host=new URL(url).getHost
(host,(url,t._2)) //返回每个host
})
val fornum=text2.map(_._1).distinct().collect()
// println(fornum)
val np=new NewPartiton(fornum)
//后面的partitionBy也是一个固定写法
text2.partitionBy(np).saveAsTextFile("c://test//output2")
sc.stop() //关闭
}
}
收获: 1 从url中获取主机名 2 text2的rdd才是真正要进行分区的,前面的切分以及分组等,都是为了获取这个rdd
3 从50--54行才是程序的核心,就是获取分区的个数,调用分区的类,保存分区后的结果。就这三步,想想也是这么一个道 理,后续只需要在这个模板上开发就行了
程序执行结果,会在c盘的test的目录上产生一个outpout2的文件夹,截图以下所示:
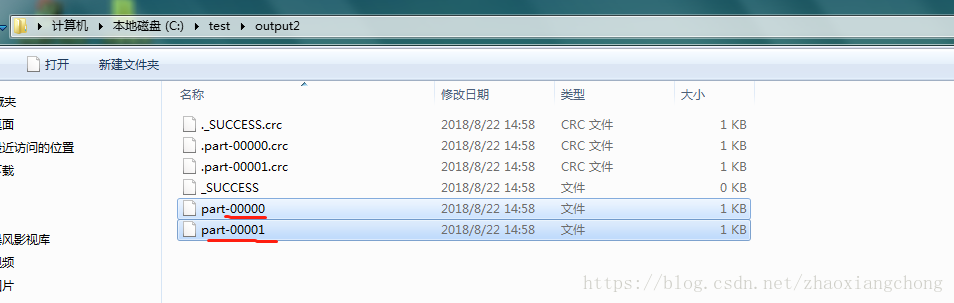
可以看到,文件夹中有part-00000和part-00001这两个文件。因为样例数据中的主机名只有运动和汽车两类,初步符合要求。
查看文件part-00000中的数据,以下所示:
(car.sina.cn,(http://car.sina.cn/car/fps.shtml,1))查看文件part-00001中的数据,以下所示:
(sport.sina.cn,(http://sport.sina.cn/sport/watch.shtml,2))
(sport.sina.cn,(http://sport.sina.cn/sport/race/nba.shtml,1))
从数据中可以看到,访问汽车的主机名的有一个,运动的主机名有三个(watch的子网页2个,nba的子网页1个)。这和样例数据是一致的,符合预期。
说明: 分区的类有固定的格式,直接调用这个类就行了,千万不要逐行的敲。