一、什么是集合?
概念:对象的容器,定义了多个对象进行操作的常用方法。可实现数组的功能。
集合类型主要有3种:list(列表)、set(集)和map(映射)。
和数组的区别:

- 数组长度固定,集合长度不固定。
- 数组可以存储基本类型和引用类型,集合只能存储引用类型。
位置:java.util.*;
举个例子:
刚上大学,班长需要统计班上的学生人数,和学生的信息,可是老师没有告诉他班上一共有多少个学生,班长用一个全新的笔记本(数组)共30张,有60面,要求每个学生把自己的信息(学号、姓名、座位号、电话号码、地址…)写在这个笔记本上,必须每个人写在一张纸上空白的一面,可是不知道班级有多少同学,就经常出现这个笔记本不够用或有剩余的浪费,假设全班人的信息要求需要写在一个笔记本上,出现不够用时,还需要重新换一本更多页数的笔记本,重新记录信息,这样就非常浪费时间和资源,这也就是程序中数组的弊端;为了解决这个问题,集合就诞生了,集合就是班长准备一个容器(如一个文件夹或收纳箱等),然后告诉全班同学,每个人自备一张A4纸,把自己的信息填写好,交给班长,班长把所有收到的A4纸放到文件夹中,收集整理好,这就是集合的基本要领,解决了数组的弊端,同时还优化了处理能力。
光头强分析讲解:
- 文件夹就是集合的容器,也就是创建集合,除了文件夹还可以是收纳盒、箱子、夹子等,所以集合也有很多种类,后面将会一一讲解;
- 学生自备统一A4纸张,说明保存的数据需要统一类型,集合的类型需要引用类型,不能是基本类型,就如学生的信息(学号、姓名、座位号、电话号码、地址…)这些都是基本类型,而A4纸张就是这些信息的类,而学生自备一个A4纸张就创建了类的对象,也就是引用类型。
- 把填写好信息的A4纸张交给班长,也就是集合中的提交方法(不同的集合提交方法也不同,add()、put()方法都是在集合在添加元素),提交到班长的文件夹里(容器),这样就添加了一个元素到文件夹(容器)中,文件夹的大小是可以改变的,继续往里面添加就继续增加容器的大小,这样就不会浪费空间,也不会出现不够用的现象。
- 班长收集整理,这里的班长相当于集合的规则,每个类型的集合都有一套不一样的规则,整理集合也是不一样的规则,就好比每个人的习惯和认知是不一样的,所以做事情的思维和逻辑也是有差别的,但是万变不离其宗,底下的原理还是很相近的,这里的规则也就是集合的特点(Collection的list:有序、有下标、元素可重复;Collection的set:无序、无下标、元素不可重复;等等其他,在这就不再深入,后面将详细讲解),根据班长的逻辑,他可以把每个学生的信息A4纸张根据座位号的顺序进行排列等,班长的这个操作也就是集合容器自带的操作(有序、无序等),进过细致的分析,我们就能赤裸裸的观看什么是集合了。
注:这篇也大多都是概念解释。我个人不是很感冒所谓的碎片化学习,都是自欺欺人罢了。所以看完文章,该坐下来静心学习的还是要花时间去学。在这篇文章中主要与基础和代码讲解,还不足够深入完全理解集合,但是使用是完全足够了,需要精通还需自行去看看源码,多敲几遍代码,加强对数据结构的理解,熟能生巧,在下文中也有部分源码分析,可以初步理解一下主要的源码原理。
二、复习存储数据结构
List 接口下有多个集合,它们存储元素所采用的数据结构方式有所不同,这就导致了不同集合有其不同特点,供程序员在不同的环境下使用。
数据存储的常用结构有:堆栈、队列、数组、链表
- 堆栈
(1) 先进后出
(2) 栈的入口、出口都是栈的顶端位置
(3) 压栈:即存元素
(4) 出栈:即取元素 - 队列
(1) 先进先出
(2) 队列的入口、出口为两端 - 数组
(1) 查找元素快:通过索引快速访问指定元素位置
(2) 增删元素慢:指定位置增加、删除元素都需要创建一个新的数组,将指定新元素存储在指定索引位置,再把原数组索引根据索引复制到新数组对应索引位置 - 链表
(1) 多个节点之间,通过地址进行连接
(2) 查找元素慢:想要查找某个元素,需要通过连接的节点,依次向后查找指定元素
(3) 增删元素快:只需修改连接下个元素的地址即可
三、基础简介(必须过关)
1.集合大纲
常用集合分类
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全(几乎不用了)
├——————├———Properties类,常常用来加载配置文件
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap

注意那些是接口那些是实现类,这个很重要。
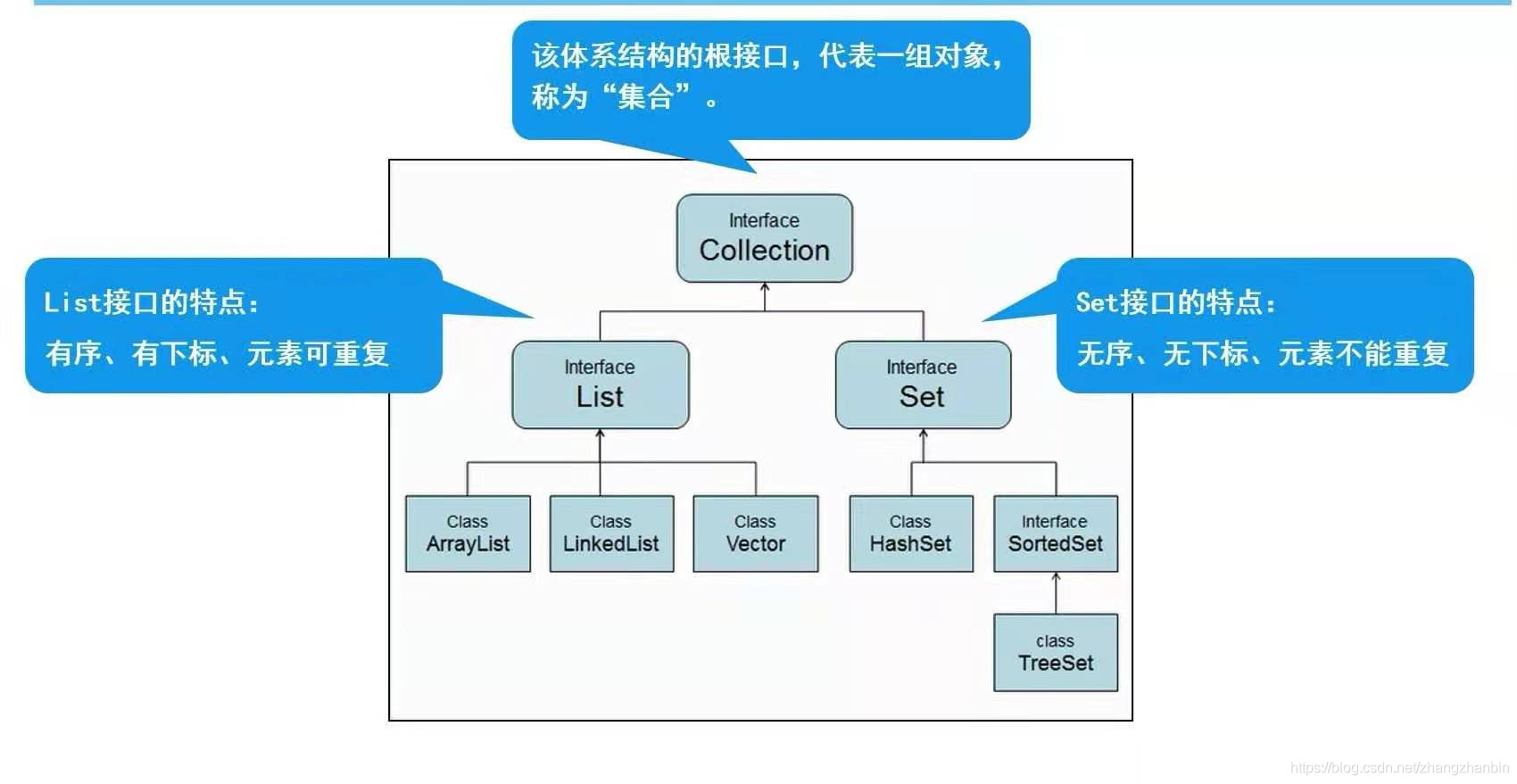

2.Collection
2.1.Collection体系集合

2.2.Collection父接口
特点:代表一组任意类型的对象,无序、无下标、不能重复。
方法:

2.3代码演示:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
* Collection接口的使用
* 1.创建集合
* 2.添加元素
* 3.删除元素
* 4.遍历元素
* 5.判断
*/
public class Demo1 {
public static void main(String[] args) {
//1.创建集合
Collection collection=new ArrayList<>();//只能创建实现类,不能创建(new)接口
//2.添加元素
collection.add("香蕉");
collection.add("苹果");
collection.add("榴莲");
collection.add("葡萄");
System.out.println("元素个数:"+collection.size());
System.out.println(collection.toString());
//3.删除元素
collection.remove("葡萄");
System.out.println("删除后的元素个数:"+collection.size());
System.out.println(collection.toString());
//4.遍历元素
//4.1增强for
System.out.println("--------------4.1增强for----------------");
for (Object object : collection) {
System.out.println(object);
}
//4.2迭代器(专门用来遍历集合的一种方式)【重点】
//hasNext()判断有没有下一个元素
//next()获取下一个元素
//remove()删除当前元素
Iterator it=collection.iterator();
System.out.println("--------------4.2迭代器----------------");
while (it.hasNext()) {
System.out.println(it.next());
it.remove();
//collection.remove(it.next());在创建了迭代器后,不能使用集合的删除方法来删除集合的元素
//需要删除只能使用迭代器定义的删除方法进行删除操作。
}
System.out.println("迭代器中删除元素,删除后的元素个数为:"+collection.size());
//5.判断
System.out.println("--------------5.判断----------------");
System.out.println(collection.contains("香蕉"));
System.out.println(collection.isEmpty());
}
}
结果:

3.List子接口
特点:有序、有下标、元素可以重复。
方法:

- void add(int index,Object o)在index位置插入对象o
- boolean addAll(int index, Collection c)将一个集合中的元素添加到此集合中的index位置
- Object get(int index)返回集合中指定位置的元素
- List subList (int fromIndex,int toIndex)返回fromIndex和toIndex之间的集合元素
- ListIterator< E > listIterator()返回此列表元素的列表迭代器(按适当顺序)
4.List实现类
ArrayList【重点】
- 数组结构实现,查询快、增删慢。
- JDK1.2版本,运行效率快、线程不安全。
Vector
- 数组结构实现,查询快、增删慢。
- JDK1.0版本,运行效率慢、线程安全。
LinkedList
- 链表结构实现,增删快、查询慢。
5.Set
Set 集合里面存储的是无序的不重复元素,没有索引,可以采用迭代器和增强for来获取元素,Set 常用的子类有 HashSet、LinkedHashSet 集合,可以通过 equals 方法来判断是否为重复元素。
5.1.HashSet 集合
HashSet 类实现 Set 接口,由哈希表支持(实际上是一个 HashMap 集合),HashSet 集合不能保证迭代顺序与元素存储顺序相同,采用哈希表结构存储数据结构,保证元素唯一性的方式依赖于:hashCode() 于 equals() 方法。
- 特点:无序集合,存储和取出的顺序不同,没有索引,不存储重复元素
- 在代码编写上和 ArrayList 完全一致
- 存储、取出数据都比较快
- 线程不安全,运行速度快
- 底层数据结构为哈希表(链表数组结合体)
public static void main(String[] args)
{
//使用多态创建哈希表
Set<String> S = new HashSet<>();
S.add("a");
S.add("b");
S.add("c");
//使用迭代器获取元素
Iterator<String> it = S.iterator();
while (it.hasNext())
{
System.out.println(it.next());
}
//使用增强获取元素
for(String s : S)
{
System.out.println(s);
}
}
5.2.HashSet 集合存储数据的结构(哈希表)
哈希表介绍:
哈希表底层使用的是数组机制,数组中也存放对象,而这些对象往数组中存放时的位置比较特殊,当需要把对象在这些数组中存放时,会根据这些对象特有的数据来结合相应的算法,计算出这个对象在数组中的位置(小标值),然后把这个对象存放在数组中。这样的数组就称为哈希数组,即哈希表。
在哈希表存储数组时,会先记录第一个元素的地址,继续存储时,会让先来的元素记录后来的地址,在这里有一个“桶”和“加载因子”的概念,桶:数组的初始容量,初始容量为16;加载因子:数组的长度百分比,默认为0.75。数组的长度:16*0.75 = 12;当存放的数据超出数组长度 12 时,数组就会进行扩容,即复制(这个过程很耗费资源),这个过程也称为数据的再哈希 rehash。
当向哈希表存放元素时,会根据元素的特有数据结合响应的算法,这个算法就是 Object 类中的 hashCode 方法。由于任何对象都是 Object 类的子类,所以任何对象都有这个方法,即:在哈希表中存放对象时,会调用对象的 hashCode 方法,算出对象在表中的位置,需要注意的是,如果两个对象 hashCode 方法算出结果一样,称为哈希冲突,这样会调用对象 equals 方法来比较两个对象是不是同一个对象,如果返回 true,则把第一个对象存放在哈希表中,如果返回 false,就会把这两个值都存放在哈希表中。
总结:保证 HashSet 集合元素的唯一,其实就是根据对象 hashCode 和 equals 方法来决定的。如果往集合中存放自定义对象,为了保证唯一性,就必须重写 hashCode 和 equals 方法建立属于当前对象的比较方法。
5.3.String 类的哈希值
哈希值表示普通的十进制整数, 是父类 Object 方法 public int hashCode() 的计算结果,String 类继承了Object,重写了 hashCode 方法。String 类中 hashCode 源码:
public int hashCode() {
int h = hash; //一开始变量 hash 为 0
if (h == 0 && value.length > 0) {
char val[] = value;
//返回字符串ASCII经过计算的和
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
因此,当使用String类定义两个对象:String S1 = new String(“abc”); String S2 = new String(“abc”); 对象S1和S2哈希值是相同的,然后集合会让后来的对象调用 equals 方法,如果返回 true,则集合判定元素重复,将其去除。
5.4.自定义对象重写hashCode和equals
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一。
创建Person类,在类中重写 hashCode 方法和 equals 方法
public class Person {
private String name;
private int age;
public Person(String name,int age)
{
this.name = name;
this.age = age;
}
public void setName(String name)
{
this.name = name;
}
public void setAge(int age)
{
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public String toString() {
return name + age;
}
//重写hashCode方法
public int hashCode()
{
return name.hashCode() + age;
}
//重写equals方法
public boolean equals(Object obj)
{
if(this == obj)
return true;
if(obj == null)
return false;
if(obj instanceof Person)
{
Person P = (Person)obj;
return name.equals(obj.name) && age == P.age;
}
return false;
}
}
在main中调用,由于重写了 hashCode 和 equals 方法,所以相同类型元素将不会打印出
public static void main(String[] args)
{
//创建存储Person类的哈希表
HashSet<Person> H = new HashSet<>();
H.add(new Person("a",18));
H.add(new Person("a",18));
H.add(new Person("b",19));
H.add(new Person("c",20));
System.out.println(H);
}
5.5.LinkedHashSet集合
LinkedHashSet 类是基于链表的哈希表的实现,继承自 HashSet,是 Set 接口的实现,此实现与 HashSet 的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。
LinkedHashSet 特点:具有顺序,存储和取出元素顺序相同
public class LinkedHashSetDemo {
public static void main(String[] args) {
LinkedHashSet<Integer> link = new LinkedHashSet<Integer>();
link.add(10);
link.add(8);
link.add(1);
link.add(2);
link.add(9);
link.add(0);
System.out.println(link);
}
}
四、总结Collection接口:
— List 有序,可重复
- ArrayList
-优点: 底层数据结构是数组,查询快,增删慢。
-缺点: 线程不安全,效率高 - Vector
-优点: 底层数据结构是数组,查询快,增删慢。
-缺点: 线程安全,效率低 - LinkedList
-优点: 底层数据结构是链表,查询慢,增删快。
-缺点: 线程不安全,效率高
—Set 无序,唯一
-
HashSet
-底层数据结构是哈希表。
-(无序,唯一) 如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals() -
LinkedHashSet
-底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一 -
TreeSet
-底层数据结构是红黑树。(唯一,有序)
1.如何保证元素排序的呢? 自然排序 比较器排序
2.如何保证元素唯一性的呢? 根据比较的返回值是否是0来决定
针对Collection集合我们到底使用谁呢?(掌握)



五、Map细说
Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。
(1)、请注意!!!, Map 没有继承 Collection 接口, Map 提供 key 到 value 的映射,你可以通过“键”查找“值”。一个 Map 中不能包含相同的 key ,每个 key 只能映射一个 value 。 Map 接口提供 3 种集合的视图, Map 的内容可以被当作一组 key 集合,一组 value 集合,或者一组 key-value 映射。
(2)Map:

(3)HashMap和HashTable的比较:

(4)TreeMap:

(5)小结:
HashMap 非线程安全
HashMap:基于哈希表实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。
TreeMap:非线程安全基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。
适用场景分析:
HashMap和HashTable:HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允许空键值,而HashTable不允许。
HashMap:适用于Map中插入、删除和定位元素。
Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
线程安全集合类与非线程安全集合类
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
StringBuilder是非线程安全的,StringBuffer是线程安全的。
数据结构
ArrayXxx:底层数据结构是数组,查询快,增删慢
LinkedXxx:底层数据结构是链表,查询慢,增删快
HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序
六、结束语
参考:feiyan的博客||游走的大千世界的烤腰子的博客需要看原文的可以点击查看
对于集合,GTQ28也是一个小白,很多还是没有深入理解到,GTQ28写此篇作为学习的一个知识汇总,希望可以帮到需要的人。
知识还是有很多欠缺的,有哪里不对的不正确的都可以留言私信我~~
我在后期慢慢更改纠错!!!
大家一起学习进步
白白啦