一、详情介绍
有时候 Hadoop 自带的输入格式,并不能完全满足业务的需求,所以需要根据实际情况自定义 InputFormat 类。而数据源一般都是文件数据,因此自定义 InputFormat时继承 FileInputFormat 类会更为方便,不必考虑如何分片等复杂操作。 自定义输入格式一般分为以下几步:
1、继承 FileInputFormat 基类。
2、重写 FileInputFormat 里面的 isSplitable() 方法。
3、重写 FileInputFormat 里面的 createRecordReader()方法。
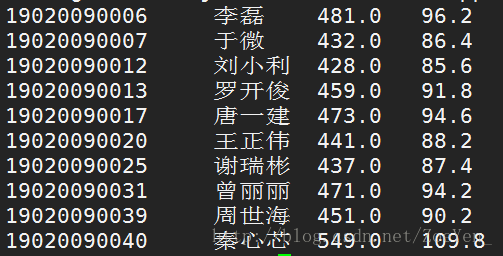
这里有一份学生五门课程的期末考试成绩数据,现在希望统计每个学生的总成绩和平均成绩。 样本数据如下所示,每行数据的数据格式为:学号、姓名、语文成绩、数学成绩、英语成绩、物理成绩、化学成绩。
二、思路分析
1.为了便于每个学生学习成绩的计算,需要先将学生各门成绩封装起来。
2.自定义ScoreInputFormat类,实现数据的读取。
3.编写mapreduce程序,完成成绩的统计。
三、代码
1.自定义一个 ScoreWritable 类实现 WritableComparable 接口,将学生各门成绩封装起来。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class ScoreWritable implements WritableComparable
{
//定义float类型的成员变量
private float Chinese;
private float Math;
private float English;
private float Physics;
private float Chemistry;
//无参构造方法
public ScoreWritable()
{
}
//float类型的参数构造方法
public ScoreWritable(float Chinese,float Math,float English,float Physics,float Chemistry)
{
this.Chinese = Chinese;
this.Chemistry = Chemistry;
this.English = English;
this.Math = Math;
this.Physics = Physics;
}
//set方法
public void set(float Chinese,float Math,float English,float Physics,float Chemistry)
{
this.Chemistry = Chemistry;
this.Chinese = Chinese;
this.English = English;
this.Math = Math;
this.Physics = Physics;
}
//get方法
public float getChinese()
{
return Chinese;
}
public float getMath()
{
return Math;
}
public float getEnglish()
{
return English;
}
public float getPhysics()
{
return Physics;
}
public float getChemistry()
{
return Chemistry;
}
//序列化和反序列化
@Override
public void readFields(DataInput in) throws IOException
{
// TODO Auto-generated method stub
Chinese = in.readFloat();
Math = in.readFloat();
English = in.readFloat();
Physics = in.readFloat();
Chemistry = in.readFloat();
}
@Override
public void write(DataOutput out) throws IOException
{
// TODO Auto-generated method stub
out.writeFloat(Chemistry);
out.writeFloat(Chinese);
out.writeFloat(English);
out.writeFloat(Math);
out.writeFloat(Physics);
}
@Override
public int compareTo(Object o) {
// TODO Auto-generated method stub
return 0;
}
}
2.自定义输入格式 ScoreInputFormat 类,首先继承 FileInputFormat,然后分别重写 isSplitable() 方法和 createRecordReader() 方法。重写createRecordReader()方法,其实也就是重写其返回的对象ScoreRecordReader。ScoreRecordReader 类继承 RecordReader,实现数据的读取。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader;
public class ScoreInputFormat extends FileInputFormat< Text,ScoreWritable >
{
//给定的文件是否可拆分
protected boolean isSplitable()
{
return false;
}
//RecordReader从inputSplit获取key/value键值对
@Override
public RecordReader<Text, ScoreWritable> createRecordReader(InputSplit inputsplit, TaskAttemptContext context)
throws IOException, InterruptedException
{
// TODO Auto-generated method stub
return new ScoreRecordReader();//返回一个新的recordreader
}
//定义新的Recordreader,//RecordReader 中的两个参数分别填写我们期望返回的key/value类型,我们期望key为Text类型,value为ScoreWritable类型封装学生所有成绩
public static class ScoreRecordReader extends RecordReader<Text,ScoreWritable>
{
public LineReader in;//定义行读取器
public Text lineKey;//自定义key
public ScoreWritable lineValue;//自定义value
public Text line;//每行数据类型
//关闭recordreader
@Override
public void close() throws IOException
{
// TODO Auto-generated method stub
if(in != null)
{
in.close();
}
}
//获取当前的key
@Override
public Text getCurrentKey() throws IOException, InterruptedException
{
// TODO Auto-generated method stub
return lineKey;
}
//获取当前的value
@Override
public ScoreWritable getCurrentValue() throws IOException, InterruptedException
{
// TODO Auto-generated method stub
return lineValue;
}
//获取当前进程
@Override
public float getProgress() throws IOException, InterruptedException
{
// TODO Auto-generated method stub
return 0;
}
//初始化
@Override
public void initialize(InputSplit inputsplit, TaskAttemptContext context) throws IOException, InterruptedException
{
// TODO Auto-generated method stub
FileSplit split = (FileSplit) inputsplit;//获取分片内容
Configuration job = context.getConfiguration();//读取配置文件
Path file = split.getPath();//获取文件路径
FileSystem fs = file.getFileSystem(job);//获取文件系统
FSDataInputStream filein = fs.open(file);//通过文件系统打开文件,对文件进行读取
in = new LineReader(filein,job);
line = new Text();
lineKey = new Text();
lineValue = new ScoreWritable();
}
//读取下一对键值对
@Override
public boolean nextKeyValue() throws IOException, InterruptedException
{
// TODO Auto-generated method stub
int linesize = in.readLine(line);//通过line接收读取数据的内容
if(linesize == 0) return false;
String[] i = line.toString().split("\\s+");//解析每行数
if(i.length != 7)
{
throw new IOException("Invalid record received");
}
//将学生的每门成绩转换为 float 类型
float a,b,c,d,e;
try
{
a = Float.parseFloat(i[2].trim());//Chinese
b = Float.parseFloat(i[3].trim());//Math
c = Float.parseFloat(i[4].trim());//English
d = Float.parseFloat(i[5].trim());//Physics
e = Float.parseFloat(i[6].trim());//Chemistry
}
catch(NumberFormatException nfe)
{
throw new IOException("Error parsing floating poing value in record");
}
lineKey.set(i[0]+"\t"+i[1]);
lineValue.set(a, b, c, d, e);
return true;
}
}
}3.编写 MapReduce 程序,统计学生总成绩和平均成绩。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ScoreCount extends Configured implements Tool
{
public static class ScoreMapper extends Mapper<Text,ScoreWritable,Text,ScoreWritable>
{
protected void map(Text key,ScoreWritable value,Context context) throws IOException, InterruptedException
{
context.write(key, value);
}
}
public static class ScoreReducer extends Reducer<Text,ScoreWritable,Text,Text>
{
private Text result = new Text();
protected void reduce(Text key,Iterable<ScoreWritable> values,Context context) throws IOException, InterruptedException
{
float sum = 0.0f;
float avg = 0.0f;
for(ScoreWritable i:values)
{
sum += i.getChemistry()+i.getChinese()+i.getEnglish()+i.getMath()+i.getPhysics();
avg += sum/5;
}
result.set(sum+"\t"+avg);
context.write(key, result);
}
}
public int run(String[] a) throws IOException, ClassNotFoundException, InterruptedException
{
Configuration conf = new Configuration();//读取配置文件
Path myPath = new Path(a[1]);//创建一个mypath对象
FileSystem hdfs = myPath.getFileSystem(conf);//获取hdfs文件系统
//如果输出路径存在就删除
if(hdfs.isDirectory(myPath))
{
hdfs.delete(myPath,true);
}
Job job = new Job(conf,"ScoreCount");//新建一个任务
job.setJarByClass(ScoreCount.class);//设置主类
FileInputFormat.addInputPath(job, new Path(a[0]));//输入路径
FileOutputFormat.setOutputPath(job, new Path(a[1]));//输出路径
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(ScoreWritable.class);
job.setInputFormatClass(ScoreInputFormat.class);
job.waitForCompletion(true);
return 0;
}
public static void main(String a[]) throws Exception
{
String[] abc = {
"hdfs://pc1:9000//home/hadoop/score/score.txt",
"hdfs://pc1:9000/home/hadoop/score/out"
};
int ec = ToolRunner.run(new Configuration(), new ScoreCount(), abc);
System.exit(ec);
}
}四、运行程序
在myeclipse上运行
创建输入路径,并上传score.txt。

debug调试,运行程序
右键刷新score文件夹
修改ScoreCount的文件传输路径,将java程序打包成jar包,导出到本地,打开集群,上传至hdfs文件系统。

执行hadoop脚本命令
[hadoop@pc1 hadoop]$ bin/hadoop jar score.jar com.pc.hadoop.mapreducetest.ScoreCount /home/hadoop/Score.txt /home/hadoop/out

查看运行结果
[hadoop@pc1 hadoop]$ bin/hdfs dfs -cat /home/hadoop/out/part-r-00000