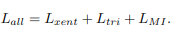Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification
Abstract
- 新的基于图的框架 Multi-Granular Hypergraph (MGH)
- 通过在多个粒度方面对时空依赖性进行建模来追求更好的表示能力
- 使用各种级别的part-based特征来构建不同粒度的Hypergraph
- 对于每个hypergraph,连接一组图节点的超边可以跨越不同的时间范围获得不同的时间粒度。
- hypergraph propagation and feature aggregation 解决了不对齐和遮挡问题
- 最后再混合信息最小化的基础上,通过学习更多不同粒度的图级表示进一步增强了整体视频的表现
- MGH在mars上top-1能达到90的准确度
1.Introduction
行人重识别是为了解决跨摄像头行人再识别问题。从基于图像的行人重识别到现在基于视频的行人重识别。
基于视频的行人重识别具有丰富的运动信息,关键是如何利用视频序列的空间和时间信息。

1.1 Multi-granularity of spatial clues
- 与fixed partition相比,基于多粒度的模型通过将人体分为了多个粒度进一步提高了性能。
- 不同级别的粒度可以捕捉到不同分区之间的差异,解决了空间不对齐问题
- 在整个序列中对齐不同的身体部位,以实现更稳健的重新识别性能。
- 开发一个框架能够系统捕捉不同位置的相关性,同时可以利用多个空间粒度。
1.2 Multi-granularity of temporal clues
时间特征已经有很多这方面的研究了:
- short-term 的比如提取光流信息
- long-term 的比如3D CNN或者时间特征融合(RNN)
- 使用短期时间特征存在遮挡问题
- 使用长期时间特征可以解决这个问题,但是这方面的研究不多
- 因此一个多粒度的时间特征模型很重要
1.3总结
如图二所示:
- 每个图模型都是一个特定的空间粒度
- 每一个边缘连接在一个特定范围内的多个节点,捕获特定的时间粒度
- 节点特征形成了所有图的图级表示
- 最种种的视频表示中融合这些图级特征,提升鲁棒性
三个优点: - 将不同的时间信息和空间信息融合结合在一个框架,空间信息利用图来捕获,时间信息通过边的传播来挖掘
- 与传统的图相比,超图可以得到多个节点之间的高阶依赖,显式解决不对齐问题
- 超图神经网络可以从序列中的时空信息中拟合出节点特征,促进了信息的传递
主要贡献: - 将基于视频的行人重识别定义为一个超图任务,基于节点传播和特征聚合
- 设计HGNN(MGN)展现视频的空间和时间依赖性
- 通过采用基于混合信息最小化的直观损失,保持了对应于不同空间粒度的图表示的多样性。
-
- MARS识别率达到90%
2.Related Work
2.1Hypergraph Learning
- 图论现在在计算机视觉任务中的应用:动作识别、图像分类、person-reID
- 传统的图只能对两两关系建模
- 超图可以对感兴趣对象之间的高阶关系进行建模
- 在超图框架中同时使用多种时空粒度,最终发现全局表示具有最好的鲁棒性
3. Multi-Granular Hypergraph Learning
3.1. Multi-Granular Feature Extraction
- 最近的研究表面 多粒度的空间特征在对人体产生更具区别性的表征上具有优势
- 对于给定的图像序列I,I包含T张图片,使用CNN提取特征F(F.sizr() = [C,W,H])
- 对特征映射进行水平方向的划分,并进行平均池化处理,构建局部特征向量 如图二(a)
3.2. Multi-Granular Hypergraph
- 在提取每个个体的初始全局特征或基于部分的特征后,即初始节点特征,下一步就是通过学习不同节点之间的相关性来更新节点特征。
- 为了有更好的鲁棒性 要同时考虑时间和空间的相关性
- HGNNS允许节点通过在图中传递消息与相邻节点通信
3.2.1Hypergraph Construction
- 我们建议通过构造一组超图G = {Gp}p∈{1,2,4,8}来捕获空间和时间相关性,其中每个超图对应一个特定的空间粒度。
- Gp = (Vp, Ep)由Np个顶点Vp和一组超边Ep组成。这里,我们利用vi∈Vp,其中i∈{1,…, Np}表示第i个图节点
- 定义了一组超边来模拟超图中短期到长期的相关性。为了学习短期相关性,hyperedge只连接时间上相邻的特征。通过超边缘连接不同时间长度的特征,建立了中长期相关关系模型
- 每个图节点vi,我们根据节点之间的特征亲和力,在特定的时间范围内找到其K个最近的邻居
- 使用超边连接这K+1个节点 如图2(b)
公式:
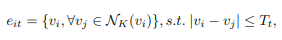
NK是包含顶部k个邻居的邻域集,|∗|是序列中顶点之间的时间距离,Tt是时间范围的阈值。在我们的框架中,我们采用三个阈值(即T1、T2、T3)分别建模短期、中期和长期长期依赖性。
3.2.2Hypergraph Propagation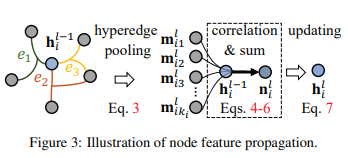
- 基于超图,我们设计了一个用于传播图信息和更新节点特征的超图神经网络,如图3
- 给定一个节点vi,我们使用Adj(vi) = {e1, e2,…, eki}表示包含该节点的所有超边。这些超边包含与vi有最高相关性的节点,然后在超边上定义一个聚合操作来捕获特征相关性。
公式:
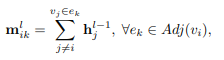 取一个超边上所有节点的平均值作为边的特征,其中 h j i − 1 h^{i-1}_j hji−1作为HGNN的第l-层的节点特征。然后,通过测量节点特征和超边特征的相关性来计算每个超边的重要性:
取一个超边上所有节点的平均值作为边的特征,其中 h j i − 1 h^{i-1}_j hji−1作为HGNN的第l-层的节点特征。然后,通过测量节点特征和超边特征的相关性来计算每个超边的重要性:
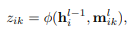 φ测量特征之间的相似性(我们在我们的框架中使用余弦相似性)。然后,我们使用Softmax函数将重要性权重归一化,并将hyperedge消息聚合如下:
φ测量特征之间的相似性(我们在我们的框架中使用余弦相似性)。然后,我们使用Softmax函数将重要性权重归一化,并将hyperedge消息聚合如下:
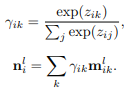 在包含图信息之后,再全连接层通过之前的节点信息和图信息更新当前节点信息
在包含图信息之后,再全连接层通过之前的节点信息和图信息更新当前节点信息
 其中 W l W^l Wl是权矩阵,σ是激活函数。重复上述特征更新步骤L轮,得到一组输出节点特征Op ={
h i L h^L_i hiL},∀vi∈Vp。我们总结了算法1中超图的传播过程。
其中 W l W^l Wl是权矩阵,σ是激活函数。重复上述特征更新步骤L轮,得到一组输出节点特征Op ={
h i L h^L_i hiL},∀vi∈Vp。我们总结了算法1中超图的传播过程。

3.2.3 Attentive Hypergraph Feature Aggregation
在对每个空间粒度的每个超图的最终更新节点特征进行提取之后,我们还需要将门节点/部分级特征合并为每个超图的图/视频级表示表述。在推导聚合方案时,我们应该考虑到,在一个超级图中,不同的节点的重要性是不同的。因为在的立场,遮挡部分或背景的重要性不如人体部分重要。因此,有必要建立一种特殊的注意机制[1,38]来解决这个问题。如图4所示,我们提出了一个注意力模型,它为每个超图生成节点级注意,以便选择最具区别性的局部特征。对于每个超图,我们计算节点的注意 αp = {α1,…, αNp}:
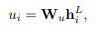
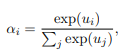 其中,Wu为权矩阵。然后,超图特征被计算为节点特征的加权和:
其中,Wu为权矩阵。然后,超图特征被计算为节点特征的加权和:
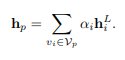
3.3Model Learning
交叉熵损失:
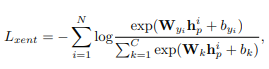 triplet loss:
triplet loss:
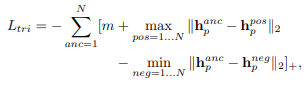 根据上述两个损失项训练模型后,每个超图将输出判别图级别特征。
根据上述两个损失项训练模型后,每个超图将输出判别图级别特征。
最后一步是对不同空间粒度的图特征进行聚合,形成最终的视频表示。
在实践中,我们发现直接汇集图级特征可能会导致显著的信息损失,因为每个超图都捕获了对应粒度的唯一特征。
因此,我们应该保持不同层次图特征的多样性。受信息论的启发,我们试图通过互信息最小化来实现这一目标。
具体地说,我们采用了一个额外的损失,减少了来自不同超图的特征之间的互信息,从而通过将所有的特征合并到一起来增加最终视频表示的辨别力。
这里我们表示Hp = {hi p}Nc i=1为具有p个空间分区的图级特征,其中Nc为训练集中的tracklet数目。根据[20],我们定义互信息损失为:
 最后,如图4所示,总的损失函数是上述三个术语的组合:
最后,如图4所示,总的损失函数是上述三个术语的组合: