AlignedReID: Surpassing Human-Level Performance in Person Re-Identification
AlignedReID: Surpassing Human-Level Performance in Person Re-Identification
前言
开题结束了,又要开始肝论文的日子,这次要整理的是旷视2017年的一篇文章AlignedReID,为了防止自己忘记,这次会把代码部分也一起整理出来。这篇文章的创新点主要是利用了行人的局部区域之间的联系实现对行人的对齐,从而减少局部不对齐导致的距离过大。
Abstract(可借鉴)
提炼了一下本文的核心:
- 方法:在提取全局特征(global feature)时加入了局部特征(local feature)
- 实现:在无监督(extra supervision)下,通过计算两组局部特征之间的最短路径,实现了performs an alignment/matching
- 在计算图像相似度的时候只使用了全局特征(这个地方为啥会只使用全局特征、而不是融合特征,后面会说)
- 成果:就是识别率啥的。。。

Introduction(可借鉴)
Introduction部分就相当于一个引入,通过看别人的这部分,有利于我们进行这一部分的写作,那么接下来看一看这边论文的结构吧!
1. 现在行人reid存在的挑战
- 不同时间和地点识别出来是同一个人
- 在大数据集中跨摄像头识别同一个人
- 相册分组
- 零售店访客分析

2.旧的解决方案
- 传统:集中在底层的特征 颜色、形状、local descriptors
- CNN:端到端的方式学习特征 对抗损失、三元损失、增强三元损失、四元损失等损失度量方式

3.存在的一些问题
现在的CNN方法仅学习全局特征,都没有考虑到空间结构(spatial structure),有下面一些弊端:
- 不准确的行人检测框
- 模糊的体态
- 无关的内容信息
- 相似的行人
当前的解决思路主要是使用集中于part-based、local feature方法,或者将完整的身体切割成固定的部分,没有考虑到各部分之间的alignment。
pose estimation需要而外的监督所以也不行

4.我们的方法(重点来了,这就引入了)
本文仍然使用全局变量,但是加入了自动部位对齐(automatic part alignment),且不需要额外的监督或者姿态检测(pose estimation)。
训练阶段共有两个分支,其中局部分支使用最短路径损失来对其局部。
测试阶段,只是用全局特征,忽略局部特征,因为实验发现单用global feature和联合两个特征效果相差不大。
在metric learningsetting下,采用了a mutual learning approach方法,使得两个模型能够互相学习,达到更好的效果。
最后又体现了以下自己的贡献,什么超越人类之类的。。。。


相关工作(后边的内容就不贴论文了,自己打开链接看)
这部分就是介绍这几种方法分别是啥,并且简要说明实现的方法。
1.Metric Learning
深度度量学习(Deep Metric Learning,DML)将原始图片(raw images)转化为嵌入特征(Embedding feature),然后计算他们之间的相似度距离。
使用的一些方法和技巧:
- 正负样本对,使用三元损失的方法
- 加入了(hard minning)难样本,会有效果
- 加入分类损失(softmax loss)到度量损失(metric loss)可以提升速度
2.Feature Alignments
这个地方和我之前整理的那个姿态对齐博客差不多,就不在写了。。。
3.Mutual learning
相互学习就是字面上的互相学习,这篇文章是把相互学习的方法加入到了度量学习中。
4.Re-Ranking
这个地方就是说提出了一个re-ranking方法,融合传统距离(original distance)和乔氏距离(Jaccard distance 好像是这样,我记不清了)
Our Approach
1.AlignedReID
话不多说,直接上图,下面这个就是AlignedReID的整体网络结构:

框架部分主要阐述了以下几点内容:(细节会在代码阶段更详细介绍)
- 使用单一的global feature作为输入图像的最终输出,在输入阶段为全局变量加入了局部变量
- 使用L2 distance作为相似度度量
L2 distance - 原始图片经过CNN(这里用的是resnet50)得到一个C×W×H的tensor,也就是feature map(由下面resnet50的结构图可以看出,经过第五层卷积层,输出为2048×7×7)

- global feature是由feature map直接通过global pooling得到的一个C-d vector
- 对feature map进行horizontal pooling,得到C×H的local feature,然后通过1×1的卷积核进一步缩小channel的个数
- 对于每一组local feature通过DMLI(最短路径)求损失
- 最终,每个行人的损失由global feature和H个loca feature联合表达
- 两张照片的距离(相似度)= global距离 + local 距离
- global距离通过L2计算
那么接下来就看一看local 距离如何计算的吧:
-
两张图片分别被分成了H个部分

-
假设两张图片分别为F、G, f i f_{i} fi、 g i g_{i} gi分别表示图片的第i行,即第i个vector的大小或者距离
-
对所有的 f i f_{i} fi、 g i g_{i} gi进行归一化处理,使得值出现在[0,1)之间
-
根据公式可以计算任意两个local feature之间的距离
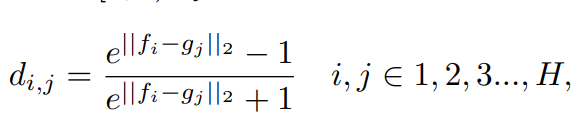
-
总共可以得到H×H个d,把它们放到一个H×H的矩阵中,类似上边的右边
-
两张图片之间的local distance就是从(1,1)到(H,H)最短路径的总和

需要注意的是论文还提到一点: -
最短路径是由corresponding parts的alignment构成的,比如上图的(1,4)
-
但是non-corresponding parts的alignment也有辅助构建作用
-
并且无需担心 non-corresponding parts 会对结果产生过多的影响,因为根据公式一,不对齐的部分贡献度很低,因为不对齐的部位距离接近于0。
最后说明了一下如何构建损失函数:
-
两张图片的相似度由global distance 和 local distance共同决定
-
使用trihard loss 作为 metric learn loss
-
对于任意一个样本,需要有两个global distance
- (难样本)同一个行人的相似度最差的另一张图的global distance,不同行人相似度最近的global distance
- 这里使用global distance来挖掘hard sample的原因有两点:一是使用global distance或者local distance不会有实质性的区别;二是global distance的计算效率更高
-
在预测中只使用global feature来计算相似度:使用global和使用local feature效果相似
-
原因解释:
- 训练的时候,local feature 已经体现了它的作用,帮助我们探索到了图片中人体的部位和结构
- 训练时,local feature帮助寻找对应的身体部位,global feature就能更多的专注人体识别,而不会关注于背景导致过拟合
2.Mutual learning for metric learning
使用Mutual learning的原因:
- 为了增强模型的效果
- 还有前人在这方面的研究贡献
本文:
- 同时训练一组student models,相互学习
- 采取了损失函数联合体(包括下面这些)
- metric loss:由global、local distance共同决定
- matric mutual loss:由global distance决定
- classification loss:
- classification mutual loss:由KL divergence classification决定
话不多说,继续贴图:

对于mutual learning approach 的结构图:
- 输入层为N张图像,a batch(N,W,C,H)
- 经过两个不同的CNN网络 ,global feature进行特征提取,
- 各自得出两个tensor
- 一个是关于classification probability的tensor(没有细节)
- 另一个是batched Feature Distance的tensor,实质上应该是一个N×N的matrix ,由N张图片之间的global feature distance构建了matrix里的每一个值
- 由上面的4个 matrices,可以构建4个损失值
- 图中classification mutual loss帮助实现两个模型在classification上的相互教学
- matric mutual loss 帮助实现两个模型在metric learning(相似性)上的相互教学
接下来从公式的角度来介绍一下mutual learning loss 是如何帮助训练的:
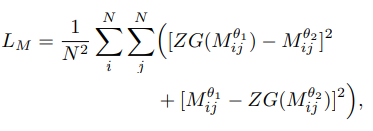
亮点就在于使用了ZG函数(zero gradient function),这个函数在计算梯度的时候可以把变量当做常量进行计算,可以停止在训练阶段的反向回馈。
通过使用这个函数,可以使的第二个主要梯度为0。
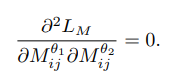
优点就在于可以提升convergence,并且提升了accuracy。
总结
本篇文章的亮点主要包括两部分:
一个是使用最短路径求到局部特征损失融合到了全局中;
一个是使用了相互学习的方式,提升了模型的准确度。
那么接下来会把这篇文章使用的算法完整的复现以下,等到这个系列的博客写完之后,我应该会在这个地方贴出来。