简介: 很多客户使用MaxCompute和Hologres的集成方案同时满足大规模离线分析、实时运营分析、交互式查询及在线Serving等多业务场景。MaxCompute和Hologres之间支持相互读写对方数据,能够消除不必要的数据冗余,形成有效的数据分层并支持离线/实时统一视图和联合分析。本文重点介绍了MaxCompute如何访问Hologres数据的开发实践。
使用MaxCompute连接访问Hologres开发实践
前言
MaxCompute(大数据计算服务)是阿里云Serverless、全托管、支持多种分析场景的云数据仓库服务,Hologres(交互式分析)是阿里云实时交互式分析产品。Hologres具备高并发地实时写入和查询数据的能力,同时支持数据不迁移高性能加速分析MaxCompute数据的能力、联邦分析Hologres实时数据与MaxCompute离线数据,实现离线实时一体化的数据仓库产品解决方案。很多客户使用MaxCompute和Hologres的集成方案同时满足大规模离线分析、实时运营分析、交互式查询及在线Serving等多业务场景。
在Hologres的产品官方文档也给出了"联邦分析实时数据和离线数据"的典型应用场景说明。如下图所示:
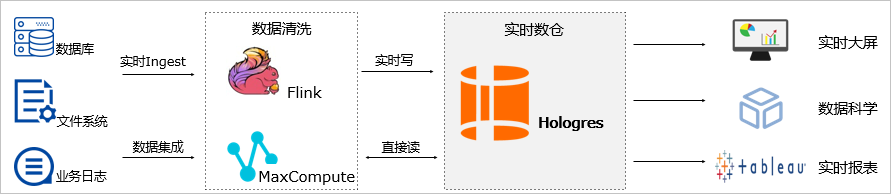
从MaxCompute和Hologres数据交互链路上看,包含2个部分:
- Hologres能够"直接读"MaxCompute:Hologres借助IMPORT FOREIGN SCHEMA语法批量创建MaxCompute外表,在Hologres侧并高性能加速分析保存在MaxCompute中的数据,例如,Hologres中可进行当日实时消费与MaxCompute中的近30天的消费数据对比分析;具体操作使用参见Hologres产品文档相关内容。
- MaxCompute能够"直接读"Hologres:当日实时数据进入Hologres中,在Hologres侧进行实时运营分析。到T+1时,MaxCompute的ETL逻辑、数据模型加工需要使用当日新增数据,此时Hologres的数据作为MaxCompute数仓的ODS层,MaxCompute无需数据导入,"直接读"取Hologres对应的数据表,完成增量+全量数据的模型加工。
本文将主要介绍在MaxCompute、Holgres的组合方案下,MaxCompute直读Hologres数据源的开发实践。
MaxCompute访问Hologres数据源包含以下2种手段:
- MaxCompute SQL以外部表方式访问Hologres数据源
- MaxCompute Spark以JDBC方式直接访问Hologres数据源
MaxCompute SQL外部表方式读写Hologres
详细内容参见MaxCompute产品文档-Hologres外部表部分,以下仅作简要介绍。
首先,在MaxCompute创建Hologres外部表。
在MaxCompute创建Hologres外部表时,您需要在建表DDL语句中指定StorageHandler,并配置JDBC驱动机制参数实现访问MC-Hologres数据源。建表语句定义如下:
create external table <table_name>( <col1_name> <data_type>, <col2_name> <data_type>, ...... ) stored by '<com.aliyun.odps.jdbc.JdbcStorageHandler>' location '<jdbc:postgresql://<accessid>:<accesskey>@<endpoint>:<port>/<database>?currentSchema=<schema>&preferQueryMode=simple&table=<holo_table_name>/>' tblproperties ( 'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver', 'odps.federation.jdbc.target.db.type'='holo', ['odps.federation.jdbc.colmapping'='<col1:column1,col2:column2,col3:column3,...>'] );
示例如下:
create external table if not exists my_table_holo_jdbc ( id bigint, name string ) stored by 'com.aliyun.odps.jdbc.JdbcStorageHandler' LOCATION 'jdbc:postgresql://LTAI4FzxmCwzb4BJqFce****:hKZMEFjdLe8ngRT5qp75UYufvT****@hgprecn-cn-oew210utf003-cn-hangzhou-internal.MC-Hologres.aliyuncs.com:80/mc_test?currentSchema=public&preferQueryMode=simple&useSSL=false&table=holo/' TBLPROPERTIES ( 'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver', 'odps.federation.jdbc.target.db.type'='holo', 'odps.federation.jdbc.colmapping'='id:id,name:name' );
创建的Hologres外部表将映射到指定的Hologres实例下db的某张表。
其次,创建完成后,使用MaxCompute SQL查询该外部表以获得Hologres表的数据。
命令示例如下:
--访问MC-Hologres外部表需要添加如下属性。 set odps.sql.split.hive.bridge=true; set odps.sql.hive.compatible=true; --查询MC-Hologres外部表数据。 select * from my_table_holo_jdbc limit 10;
MaxCompute SQL同时可以写入数据到Hologres外部表,实现将MaxCompute加工后的消费数据直接导入Hologres,借助Hologres高性能存储的分析引擎,获得最佳的分析体验。
--访问MC-Hologres外部表需要添加如下属性。 set odps.sql.split.hive.bridge=true; set odps.sql.hive.compatible=true; --向MC-Hologres外部表插入数据。 insert into my_table_holo_jdbc values (12,'alice'); --查询MC-Hologres外部表数据。 select * from my_table_holo_jdbc;
MaxCompute Spark使用JDBC连接访问Hologres
MaxCompute原生集成Apache Spark分析引擎,借助Spark不仅可以直接分析MaxCompute数据,MaxCompute Spark还可以使用JDBC方式连接Hologres数据源。习惯使用Spark的用户,可以在Spark代码中实现更灵活的业务逻辑。
笔者分别使用以下3种提交模式验证Spark如何访问Hologres。关于MaxCompute Spark支持的几种模式,具体请参考MaxCompute产品官方文档,本文不作展开。
本地(Local)提交模式
熟悉MaxCompute Spark的用户经常使用这个模式做本地测试,验证代码逻辑是否正确。本文主要是用于验证、跑通Spark的JDBC方式能够正常访问Hologres数据源。
样例代码(PySpark):
spark = SparkSession \
.builder \
.appName("MC spark") \
.getOrCreate()
jdbcDF = spark.read.format("jdbc"). \
options(
url='jdbc:postgresql://hgpostcn-cn-xxx-cn-shanghai.hologres.aliyuncs.com:80/test_holo',
dbtable='test',
user='xxx',# e.g.Access_id
password='xxx', # e.g.Secret_key
driver='org.postgresql.Driver'). \
load()
jdbcDF.printSchema()
这里使用Spark的JDBC连接方式,通过postgresql驱动连接Hologres,访问test_holo数据库下的test表,打印出该表的schema信息。由于是本地测试,选择使用公网方式连接Hologres,其中url为hologres实例的公网访问域名。
使用spark-submit方式提交作业:
#本地Spark访问Holo spark-submit --master local --driver-class-path /drivers/postgresql-42.2.16.jar --jars /path/postgresql-42.2.16.jar /path/read_holo.py
Postgresql的JDBC驱动可访问pg驱动官网下载。
提交后查看spark打印日志:

打印的test表的schema信息与Holo中创建的test表schema一致,访问成功。其他关于JDBC数据源表的数据处理可以参考Apache Spark文档,本文主要介绍如何打通访问,其他处理逻辑不再展开。
MaxCompute集群(yarn-cluster)提交模式
样例代码(PySpark):
spark = SparkSession \
.builder \
.appName("MC spark") \
.getOrCreate()
jdbcDF = spark.read.format("jdbc"). \
options(
url='jdbc:postgresql://hgpostcn-cn-xxx-cn-shanghai-internal.hologres.aliyuncs.com:80/test_holo',
dbtable='test',
user='xxx',# e.g.Access_id
password='xxx', # e.g.Secret_key
driver='org.postgresql.Driver'). \
load()
jdbcDF.printSchema()
由于是集群提交模式,代码需要上传到MaxCompute云上集群运行,在集群中MaxCompute通过Hologres的经典网络域名以内网方式访问,这里不能使用公网地址。
配置MaxCompute Spark客户端(为MaxCompute适配进行了定制改造,相关介绍和下载,详见产品文档)spark-defaults.conf,增加spark.hadoop.odps.cupid.trusted.services.access.list参数项,添加需要访问的目标hologres实例的经典网络域名地址。增加该配置,主要是为了在MaxCompute安全运行沙箱环境中开启到对应Hologres实例的网络策略,否则MaxCompute集群默认无法访问外部服务。
# OdpsAccount Info Setting spark.hadoop.odps.project.name = your_maxc_project spark.hadoop.odps.access.id = xxx spark.hadoop.odps.access.key = xxx # endpoint spark.hadoop.odps.end.point = http://service.cn.maxcompute.aliyun.com/api spark.hadoop.odps.runtime.end.point = http://service.cn.maxcompute.aliyun-inc.com/api #Access holo instance spark.hadoop.odps.cupid.trusted.services.access.list = hgprecn-cn-xxx-cn-shanghai-internal.hologres.aliyuncs.com:80
使用spark-submit方式提交作业:
#本地Spark访问Holo spark-submit --master yarn-cluster --driver-class-path /drivers/postgresql-42.2.16.jar --jars /path/postgresql-42.2.16.jar /path/read_holo.py
提交后查看spark打印日志,作业正常完成会打印作业的Logview以及Spark-UI的Job View链接地址,可供开发者进一步诊断作业。
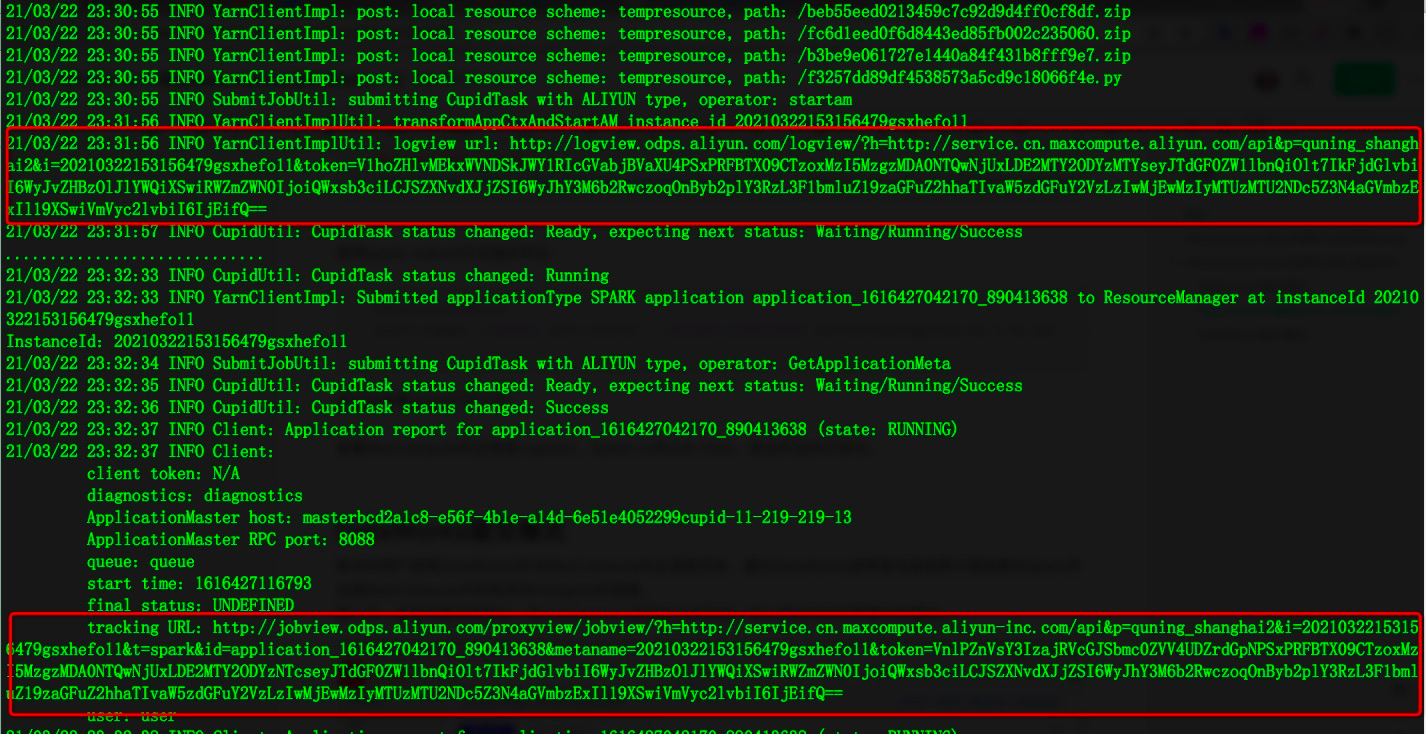
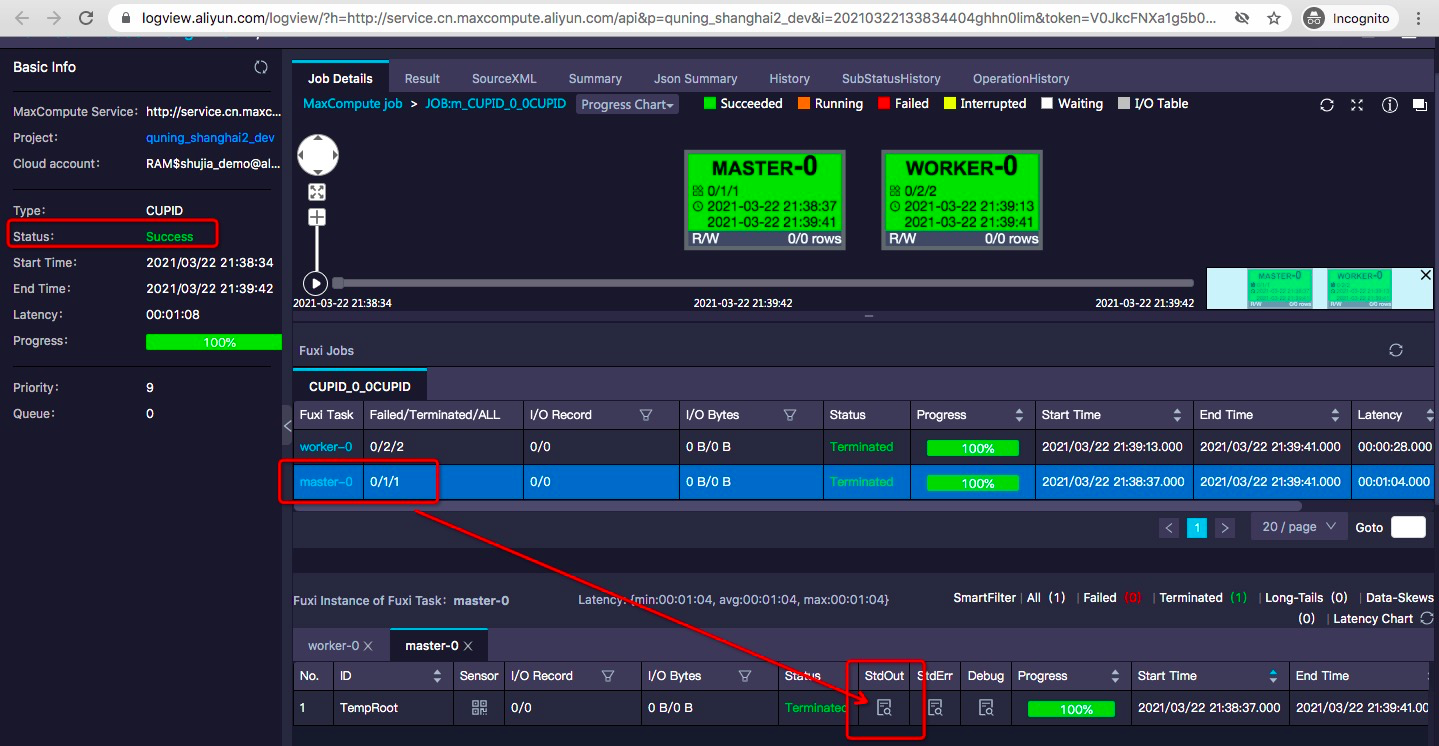
查看MaxCompute作业信息Logview、Spark-UI的Job View,验证作业执行成功。
查看日志有无报错,同时打开logview链接,查看作业执行状态。
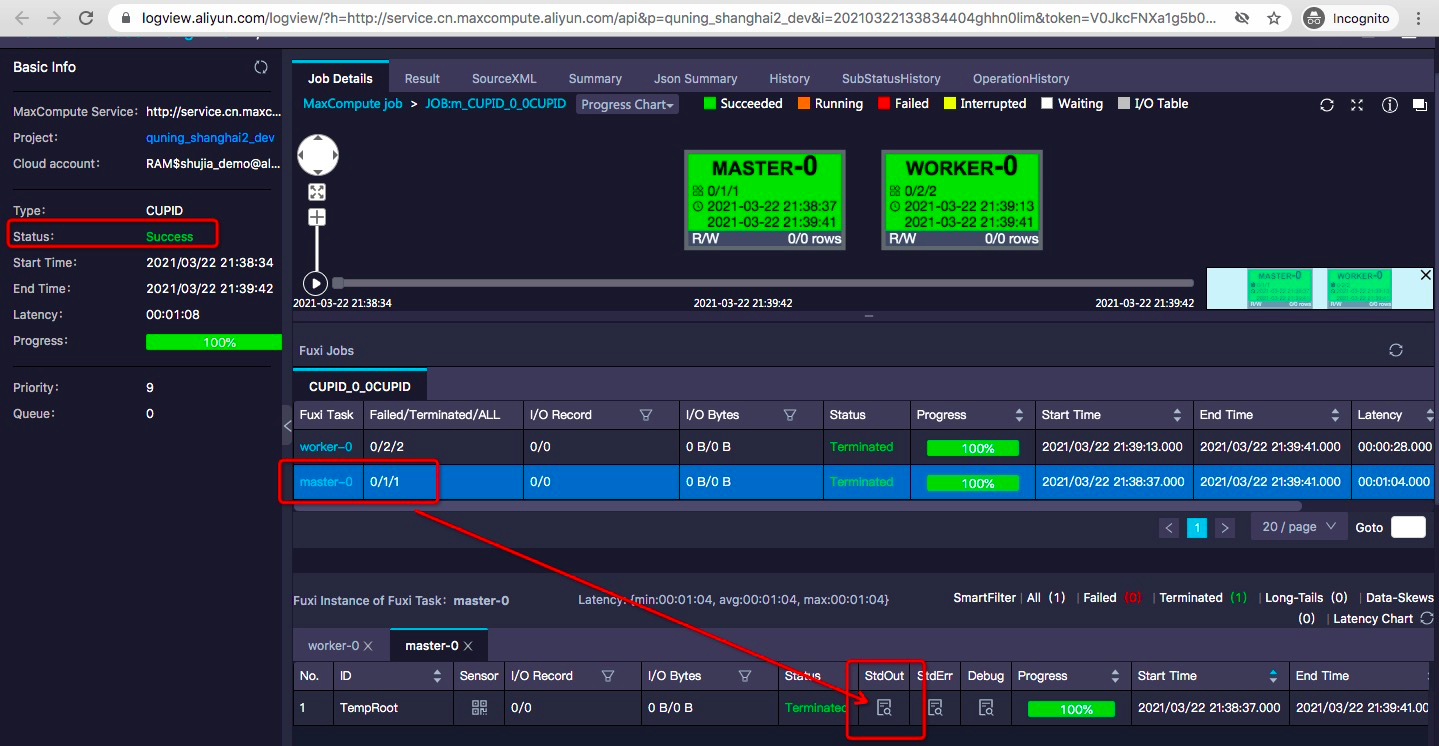
查看作业状态为Success,同时点击master-0下的worker的StdOut输出按钮。
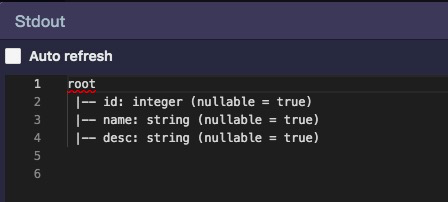
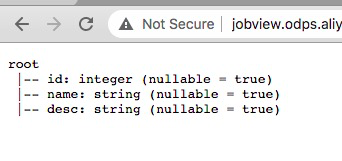
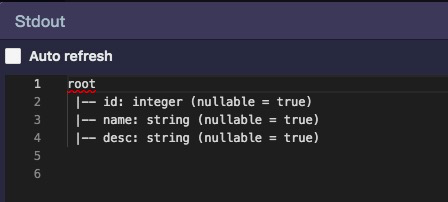
这里是spark代码中jdbcDF.printSchema()的返回结果,与预期一致,验证完成。
MaxCompute Spark同时提供Spark web-ui进行作业诊断,打开日志中的job view链接地址即可访问。
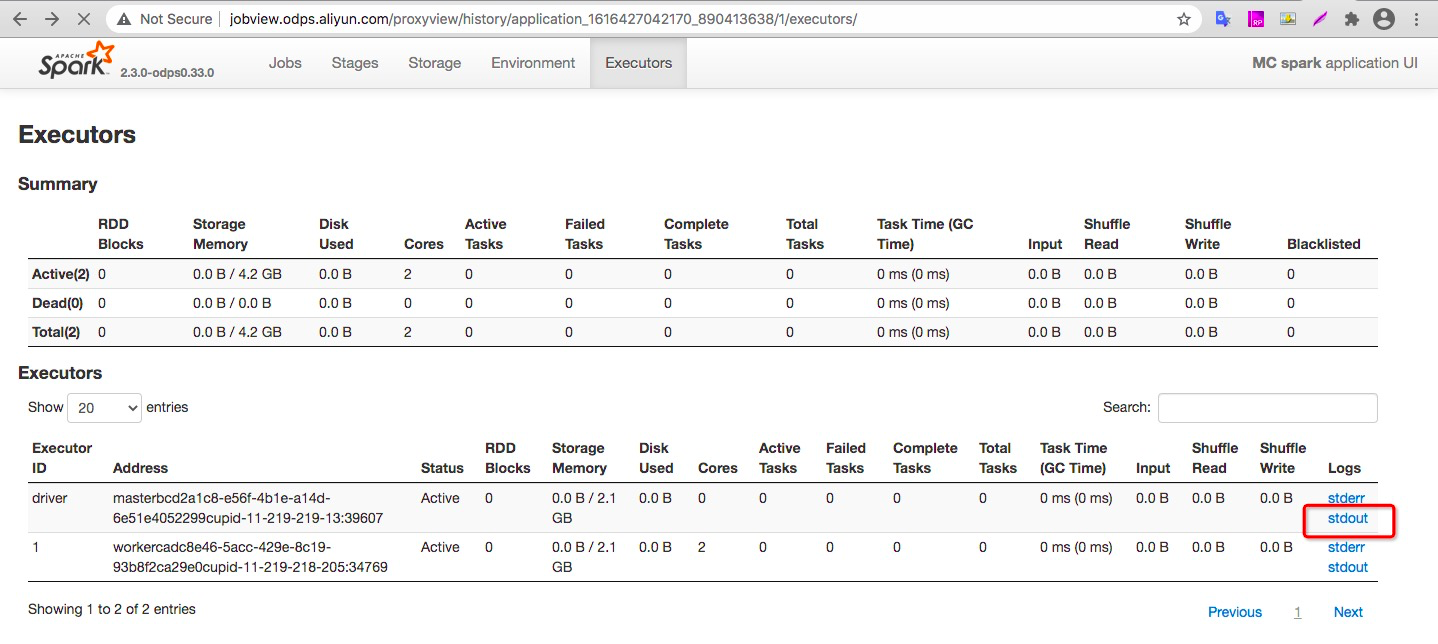
点击driver的stdout按钮,可查看应用的打印输出是否符合业务预期:
DataWorks提交模式
更多的用户使用DataWorks作为MaxCompute作业调度系统,通过DataWorks使用者也能够很方便地提交Spark作业到MaxCompute中实现访问Hologres的逻辑。
第一步,登录阿里云控制台,进入dataworks指定的工作空间,进入项目对应的数据开发模块。
第二步,创建/调整业务流程
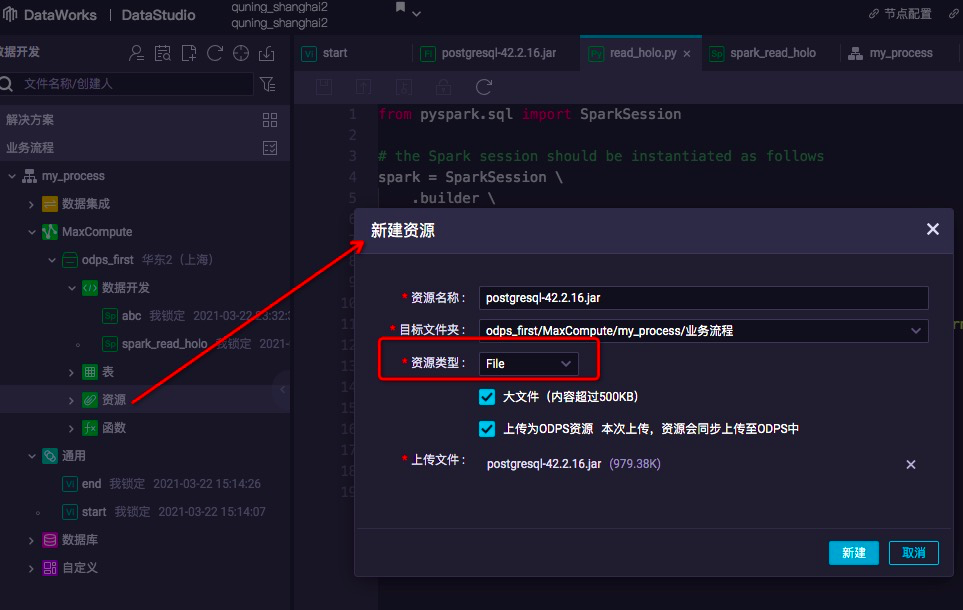
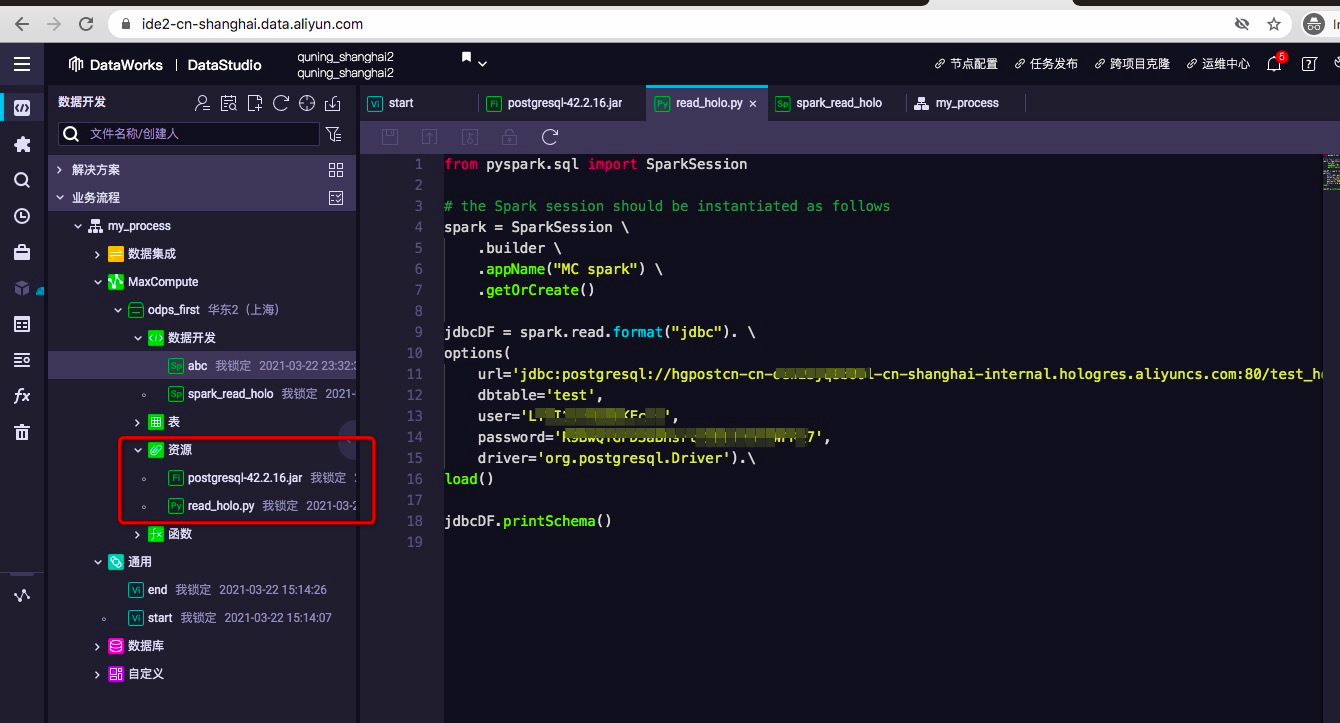
1.在业务流程中的MaxCompute节点下,上传postgresql jdbc jar文件,以便spark程序引用驱动。注意,这里要选择使用文件(File)资源类型。
2.在资源节点下,上传python代码。本文提交了pyspark代码用于测试。
3.在业务流程画布中选择odps spark节点并填写spark作业的参数信息
- 业务流程画布中选择MaxCompute引擎支持的ODPS Spark节点
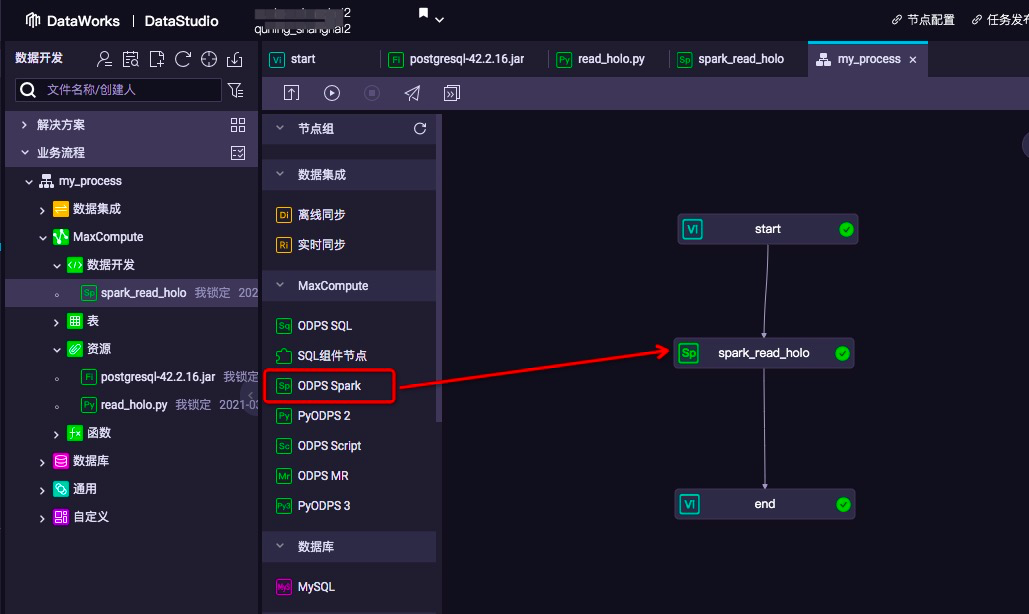
- 双击画布中ODPS Spark节点图标,编辑该任务节点,填写任务信息
本文使用了pyspark,因此该节点选择python语言,同时在"选择主python资源"选项中,选择刚才上传的python文件资源。
其中在配置项中为该任务添加hologres目标地址的网络白名单,地址仍然使用Hologres实例的经典网络域名,如图所示:
配置项:spark.hadoop.odps.cupid.trusted.services.access.list
配置项取值:hgpostcn-cn-xxx-cn-shanghai-internal.hologres.aliyuncs.com:80
同时,在"选择file资源"选项中,选择刚才上传到资源中的postgres的驱动jar文件。
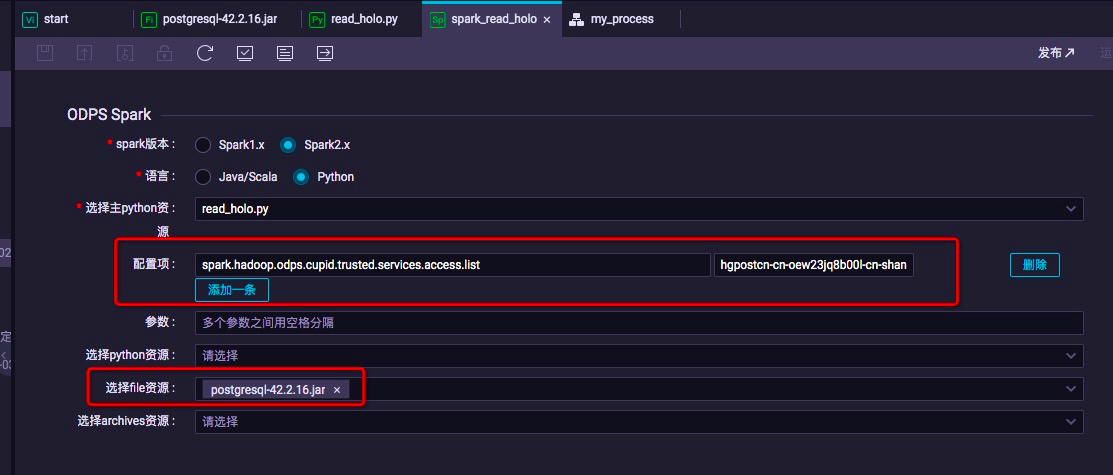
点击保存并提交。
4.在dataworks运行ODPS Spark节点任务进行验证
点击"运行节点",在dataworks页面下方将打印作业日志,其中包含MaxCompute作业的诊断信息Logview链接地址。
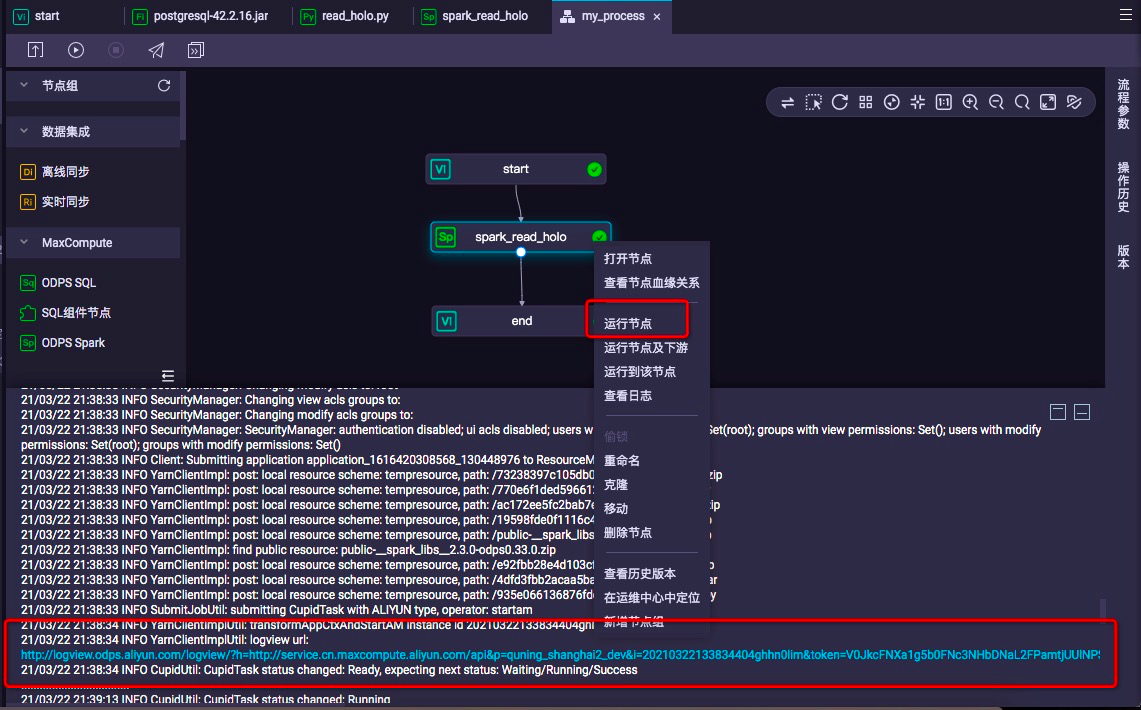
查看日志有无报错,同时打开logview链接,查看作业执行状态。
查看作业状态为Success,同时点击master-0下的worker的StdOut输出按钮。
这里是spark代码中jdbcDF.printSchema()的返回结果,与预期一致,验证完成。