简介: 主要内容: 一、IO 模型和问题 二、资源竞争与分布式锁 三、Redis 抢购系统实例
主要内容:
一、IO 模型和问题
二、资源竞争与分布式锁
三、Redis 抢购系统实例
一、IO 模型和问题
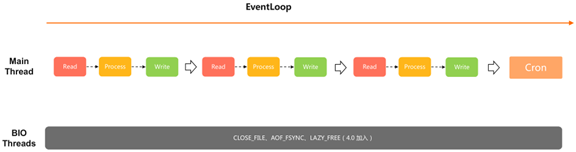
1)Run-to-Completion in a solo thread
Redis社区版的IO模型比较简单,通常是由一个 IO线程实现所有命令的解析与处理。
问题是如果有一条慢查询命令,其他的查询都要排队。即当一个客户端执行一个命令执行很慢的时候,后面的命令都会被阻塞。使用 Sentinel 判活,会导致ping 命令也被延迟,ping 命令同样受到慢查询影响,如果引擎被卡住,则 ping 失败,导致无法判断服务此时是不是可用,因为这是一种误判。
如果此时发现服务没有响应,我们从Master切换到Slave,结果又发现慢查询拖慢了Slave,这样的话,ping又会去误判,导致很难监听服务是不是可靠。
问题总结:
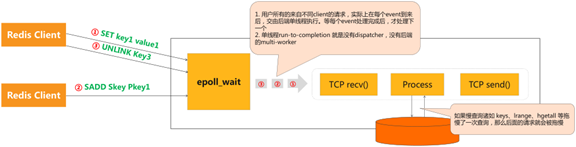
1. 用户所有的来自不同client的请求,实际上在每个事件到来后,都是单线程执行。等每个事件处理完成后,才处理下一个;
2. 单线程run-to-completion 就是没有dispatcher,没有后端的multi-worker;
如果慢查询诸如 keys、lrange、hgetall等拖慢了一次查询,那么后面的请求就会被拖慢。
使用 Sentinel 判活的缺陷:
• ping 命令判活:ping 命令同样受到慢查询影响,如果引擎被卡住,则 ping 失败;
• duplex Failure:sentinel 由于慢查询切备(备变主)再遇到慢查询则无法继续工作。
2)Make it a cluster
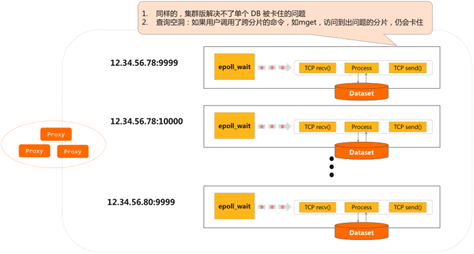
用多个分片组成一个cluster的时候,也是同样的问题。如果其中的某一个分片被慢查询拖慢,比如用户调用了跨分片的命令,如mget,访问到出问题的分片,仍会卡住,会导致后续所有命令被阻塞。
问题总结:
1. 同样的,集群版解决不了单个 DB 被卡住的问题;
2. 查询空洞:如果用户调用了跨分片的命令,如mget,访问到出问题的分片,仍会卡住。
3)“Could not get a resource from the pool”
常见的 Redis客户端如Jedis,会配连接池。业务线程去访问Redis的时候,每一个查询会去里面取一个长连接进行访问。如果该查询比较慢,连接没有返回,那么会等待很久,因为请求在返回之前这个连接不能被其他线程使用。
如果查询都比较慢,会使得每一个业务线程都拿一个新的长连接,这样的话,会逐渐耗光所有的长连接,导致最终抛出异常——连接池里面没有新的资源。因为Redis服务端是一个单线程,当客户端的一个长连接被一个慢查询阻塞时,后续连接上的请求也无法被及时处理,因为当前连接无法释放给连接池。
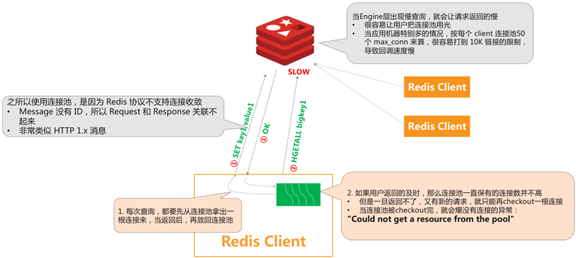
之所以使用连接池,是因为 Redis 协议不支持连接收敛,Message 没有 ID,所以 Request 和Response 关联不起来。如果要实现异步的话,可以每一个请求发送的时候,把回调放入一个队列里面(每个连接一个队列),在请求返回之后从队列取出来回调执行,即FIFO模型。但是服务端连接无法让服务端乱序返回,因为乱序在客户端没有办法对应起来。一般客户端的实现,用 BIO比较简单,拿一个连接阻塞住,等其返回之后,再让给其他线程使用。
但实际上异步也不能提升效率,因为服务端实际上还是只有一个线程,即便客户端对访问方式进行修改,使得很多个连接去发请求,但在服务端一样需要排队,因为是单线程,所以慢查询依然会阻塞别的长连接。
另外一个很严重的问题是,Redis的线程模型,当IO线程到万以上的时候,性能比较差,如果有2万到3万长连接,性能将会慢到业务难以承受的程度。而业务机器,比如有300~500台,每一台配50个长连接,很容易达到瓶颈。
总结:
之所以使用连接池,是因为 Redis 协议不支持连接收敛
• Message 没有 ID,所以 Request 和Response 关联不起来;
• 非常类似 HTTP 1.x消息。
当Engine层出现慢查询,就会让请求返回的慢
• 很容易让用户把连接池用光;
• 当应用机器特别多的情况,按每个 client 连接池50个max_conn 来算,很容易打到 10K 链接的限制,导致回调速度慢;
1. 每次查询,都要先从连接池拿出一个连接,当请求返回后,再放回连接池;
2. 如果用户返回的及时,那么连接池一直保有的连接数并不高
• 但是一旦返回不了,又有新的请求,就只能再checkout一根连接;
• 当连接池被checkout完,就会爆没有连接的异常:"Could not get a resource from the pool"。
补充一点在当下的Redis协议上实现异步接口的方法:
1. 类似上面提到的,一个连接分配一个回调队列,在异步请求发出去前,将处理回调放入队列中,等到响应回来后取出回调执行。这个方法比较常见,主流的支持异步请求的客户端一般都这么实现。
2. 有一些取巧的做法,比如使用Multi-Exec以及ping命令包装请求,比如要调用set k v这个命令,包装为下面的形式:
multi
ping {id}
set k v
exec
服务端的返回是:
{id}
OK
这是利用Multi-Exec的原子执行以及ping的参数原样返回的特性来实现在协议中“夹带”消息的ID的方式,比较取巧,也没见客户端这么实现过。4)Redis 2.x/4.x/5.x 版本的线程模型
Redis5.X之前比较知名的版本,模型没有变化过,所有的命令处理都是单线程,所有的读、处理、写都在一个主IO里运行。后台有几个BIO线程,任务主要是关闭文件、刷文件等等。
4.0之后,添加了LAZY_FREE,有些大KEY可以异步的释放,以避免阻塞同步任务处理。而在2.8上会经常会遇到淘汰或过期删除比较大的key时服务会卡顿,所以建议用户使用4.0以上的服务端,避免此类大key删除问题导致的卡顿。
5)Redis 5.x 版本的火焰图
性能分析,如下图所示:前两部分是命令处理、中间是“读取”、最右侧“写”占比61.16%,由此可以看出,性能占比基本上都消耗在网络IO上。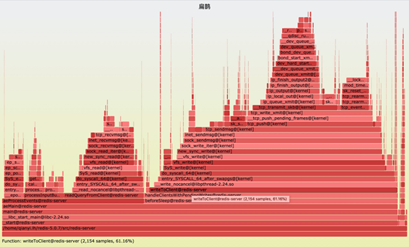
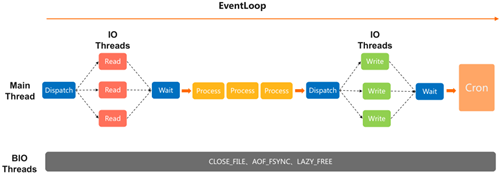
6)Redis 6.x 版本的线程模型
Redis 6.x 版本改进的模型,可以在主线程,可读事件触发之后,把“读”任务委托在IO线程处理,全读完之后,返回结果,再一次处理,然后“写”也可以分发给IO线程写,显而易见可以提升性能。
这种性能提升,运行线程还只有一个,如果有一些O(1)命令,比如简单的“读”、“写”命令,提升效果非常高。但如果命令本身很复杂,因为DB还是只有一个运行线程,提升效果会比较差。
还有个问题,把“读”任务委托之后,需要等返回,“写”也需要等返回,所以主线程有很长时间在等,且这段时间无法提供服务,所以Redis 6.x模型还有提升的空间。
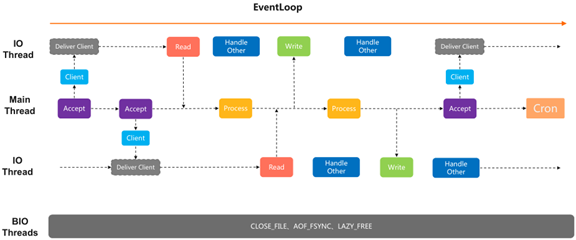
7) 阿里云 Redis 企业版(Tair 增强性能)的线程模型
阿里云 Redis 企业版模型更进一步,把整个事件拆分开,主线程只负责命令处理,所有的读、写处理由IO线程全权负责,不再是连接永远都属于主线程。事件出发之后,读一下而已当客户端连进来之后,直接交给其他IO线程,从此客户端可读、可写的所有事件,主线程不再关心。
当有命令到达,IO线程会把命令转发给主线程处理,处理完之后,通过通知方式把处理结果转给IO线程,由IO线程去写,最大程度把主线程的等待时间去掉,使性能有更进一步提升。
缺点还是只有一个线程在处理命令,对于O(1)命令提升效果非常理想,但对于本身比较耗CPU的命令,效果不是很理想。
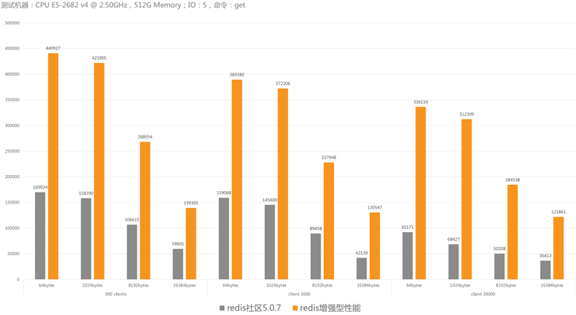
8)性能对比测试
如下图所示,左边灰色是:redis社区5.0.7,右边橙色是:redis增强型性能,redis6.X的多线程性能在这两个之间。下图命令测试的是“读”命令,本身不是耗CPU,瓶颈在IO上,所以效果非常理想。如果最坏情况下,假设命令本身特别耗CPU,两个版本会无限逼近,直到齐平。
值得一提的是,redis社区版7的计划已经出来了,按目前的计划,redis社区版7会采用类似阿里云当下采用的的修改方案,逐渐逼近单个主线程的性能瓶颈。
这里补充一点,性能只是一个方面,把连接全权交给别的IO的另一个好处是获得了连接数的线性提升能力,可以通过增加IO线程数的方式不断的提升更大连接数的处理能力。阿里云的企业版Redis默认就提供数万的连接数能力,更高的比如五六万的长连接也能提工单来支持,以解决用户业务层机器大量扩容时,连接数不够用的问题。
二、资源竞争与分布式锁
1)CAS/CAD 高性能分布式锁
Redis字符串的写命令有个参数叫NX,意思是字符串不存在时可以写,是天然的加锁场景。这样的特性,加锁非常容易,value取一个随机值,set的时候带上NX参数就可以保证原子性。
带EX是为了业务机器加上锁之后,如果因为某个原因被下线掉了(或者假死之类),导致这个锁没有正常释放,就会使得这个锁永远无法被解掉。所以需要一个过期时间,保证业务机器故障之后,锁会被释放掉。
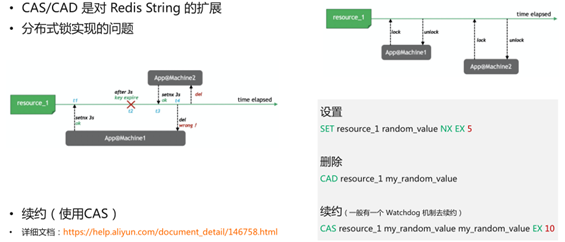
这里的参数“5”只是一个例子,并不一定得是5秒钟,要看业务机器具体要做的事情来定。
分布式锁删除的时候比较麻烦,比如机器加上锁后,突然遇到情况,卡顿或者某种原因失联了。失联之后,已经过了5秒,这个锁已经失效掉了,其他的机器加上锁了,然后之前那个机器又可用了,但是处理完之后,比如把 Key删掉了,使得删掉了本来并不属于它的锁。所以删除需要一个判断,当 value等于之前写的value时,才可以删掉。Redis 目前没有这样的命令,一般通过Lua来实现。
当 value 和引擎中 value 相等时候删除 Key,可以使用“Compare And Delete”的CAD命令。CAS/CAD 命令以及后续提到的 TairString 以 Module形式开源: https://github.com/alibaba/TairString。无论用户使用哪个Redis版本(需要支持Module机制),都可以直接把Module载入,使用这些API。
续约CAS,当加锁时我们给过一个过期时间,比如“5秒”,如果业务在这个时间内没处理完需要有一个机制续约。比如事务没有执行完,已经过了3秒,那需要把及时把运行时间延长。续约跟删除是一样的道理,我们不能直接续约,必须当value 和引擎中 value 相等时候续约 ,只有证明这个锁被当下线程持有,才能续约,所以这是一个CAS操作。同理,如果没有 API,需要写一段Lua,实现对锁的续约。
其实分布式并不是特别可靠,比如上面讲的,尽管加上锁之后失联了,锁被别人持有了,但是突然又可用了,这时代码上不会判断这个锁是不是被当下线程持有,可能会重入。所以Redis分布式锁,包括其他的分布式锁并不是100%可靠。
本节总结:
• CAS/CAD 是对 Redis String 的扩展;
• 分布式锁实现的问题;
• 续约(使用CAS)
• 详细文档:https://help.aliyun.com/document_detail/146758.html;
CAS/CAD 以及后续提到的 TairString 以 module 形式开源: https://github.com/alibaba/TairString。
2)CAS/CAD 的 Lua 实现
如果说没有CAS/CAD命令,需要去写一段Lua,第一是读 Key,如果value等于我的value,那么可以删掉;第二是需续约,value等于我的value,更新一下时间。
需要注意的是,脚本中每次调用会改变的值一定要通过参数传递,因为只要脚本不相同,Redis 就会缓存这个脚本,截止目前社区 6.2 版本仍然没有限制这个缓存大小的配置,也没有逐出策略,执行 script flush 命令清理缓存时也是 同步 操作,一定要避免脚本缓存过大(异步删除缓存的能力已经由阿里云的工程师添加到社区版本,Redis 6.2开始支持 script flush async)。
使用方式也是先执行 script load 命令加载 Lua 到Redis 中,后续使用 evalsha 命令携带参数调用脚本,一来减少网络带宽,二来避免每次载入不同的脚本。需要注意的是 evalsha 可能返回脚本不存在,需要处理这个错误,重新 script load 解决。

CAS/CAD 的 Lua 实现还需要注意:
• 其实由于 Redis 本身的数据一致性保证以及宕机恢复能力上看,分布式锁并不是特别可靠的;
• Redis 作者提出来 Redlock 这个算法,但是争议也颇多: 参考资料1、 参考资料2 、参考资料3;
• 如果对可靠性要求更高的话,可以考虑 Zookeeper 等其他方案(可靠性++, 性能--);
• 或者,使用消息队列串行化这个需要互斥的操作,当然这个要根据业务系统去设计。
3)Redis LUA
一般来说,不建议在Redis里面使用LUA,LUA执行需要先解析、翻译,然后执行整个过程。
第一:因为 Redis LUA,等于是在C里面调LUA,然后LUA里面再去调 C,返回值会有两次的转换,先从Redis协议返回值转成LUA对象,再由LUA对象转成 C的数据返回。
第二:有很多LUA解析,VM处理,包括lua.vm内存占用,会比一般的命令时间慢。建议用LUA最好只写比较简单的,比如if判断。尽量避免循环,尽量避免重的操作,尽量避免大数据访问、获取。因为引擎只有一个线程,当CPU被耗在LUA的时候,只有更少的CPU处理业务命令,所以要慎用。
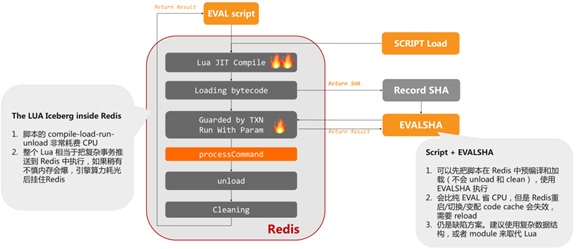
总结:
• “The LUA Iceberg inside Redis”
脚本的 compile-load-run-unload 非常耗费 CPU,整个 Lua 相当于把复杂事务推送到 Redis 中执行,如果稍有不慎内存会爆,引擎算力耗光后挂住Redis。
• “Script + EVALSHA”
可以先把脚本在 Redis 中预编译和加载(不会 unload 和 clean),使用EVALSHA 执行,会比纯 EVAL 省 CPU,但是 Redis重启/切换/变配 code cache 会失效,需要reload,仍是缺陷方案。建议使用复杂数据结构,或者 module 来取代 Lua。
• 对于 JIT 技术在存储引擎中而言,“EVAL is evil”,尽量避免使用 Lua 耗费内存和计算资源(省事不省心);
• 某些SDK(如 Redisson)很多高级实现都内置使用 Lua,开发者可能莫名走入 CPU 运算风暴中,须谨慎。
三、Redis 抢购系统实例
1)抢购/秒杀场景的特点
• 秒杀活动对稀缺或者特价的商品进行定时定量售卖,吸引成大量的消费者进行抢购,但又只有少部分消费者可以下单成功。因此,秒杀活动将在较短时间内产生比平时大数十倍,上百倍的页面访问流量和下单请求流量。
• 秒杀活动可以分为 3 个阶段:
• 秒杀前:用户不断刷新商品详情页,页面请求达到瞬时峰值;
• 秒杀开始:用户点击秒杀按钮,下单请求达到瞬时峰值;
• 秒杀后:少部分成功下单的用户不断刷新订单或者退单,大部分用户继续刷新商品详情页等待机会。
2)抢购/秒杀场景的一般方法
• 抢购/秒杀其实主要解决的就是热点数据高并发读写的问题。
• 抢购/秒杀的过程就是一个不断对请求 “剪枝” 的过程:
1.尽可能减少用户到应用服务端的读写请求(客户端拦截一部分);
2.应用到达服务端的请求要减少对后端存储系统的访问(服务端 LocalCache 拦截一部分);
3.需要请求存储系统的请求尽可能减少对数据库的访问(使用 Redis 拦截绝大多数);
4.最终的请求到达数据库(也可以消息队列再排个队兜底,万一后端存储系统无响应,应用服务端要有兜底方案)。
• 基本原则
1. 数据少(静态化、CDN、前端资源合并,页面动静分离,LocalCache)尽一切的可能降低页面对于动态部分的需求,如果前端的整个页面大部分都是静态,通过 CDN或者其他机制可以全部挡掉,服务端的请求无论是量,还是字节数都会少很多。
2. 路径短(前端到末端的路径尽可能短、尽量减少对不同系统的依赖,支持限流降级);从用户这边发起之后,到最终秒杀的路径中,依赖的业务系统要少,旁路系统也要竞争的少,每一层都要支持限流降级,当被限流被降级之后,对于前端的提示做优化。
3. 禁单点(应用服务无状态化水平扩展、存储服务避免热点)。服务的任何地方都要支持无状态化水平扩展,对于存储有那个状态,避免热点,一般都是避免一些读、写热点。
• 扣减库存的时机
1.下单减库存( 避免恶意下单不付款、保证大并发请求时库存数据不能为负数 );
2. 付款减库存( 下单成功付不了款影响体验 );
3. 预扣库存超时释放( 可以结合 Quartz 等框架做,还要做好安全和反作弊 )。
一般都选择第三种,多前两种都有缺陷,第一种很难避免恶意下单不付款,第二种成功的下单了,但是没法付款,因为没有库存。两个体验都非常不好,一般都是先预扣库存,这个单子超时会把库存释放掉。结合电视框架做,同时会做好安全与反作弊机制。
• Redis 的一般实现方案
1. String 结构
• 直接使用incr/decr/incrby/decrby,注意 Redis 目前不支持上下界的限制;
• 如果要避免负数或者有关联关系的库存 sku 扣减只能使用 Lua。
2. List 结构
• 每个商品是一个 List,每个 Node 是一个库存单位;
• 扣减库存使用lpop/rpop 命令,直到返回 nil (key not exist)。
List缺点比较明显,如:占用的内存变大,还有如果一次扣减多个,lpop就要调很多次,对性能非常不好。
3. Set/Hash 结构
• 一般用来去重,限制用户只能购买指定个数(hincrby 计数,hget 判断已购买数量);
• 注意要把用户 UID 映射到多个 key 来读写,一定不能都放到某一个 key 里(热点);因为典型的热点key的读写瓶颈,会直接造成业务瓶颈。
4.业务场景允许的情况下,热点商品可以使用多个 key:key_1,key_2,key_3 ...
• 随机选择;
• 用户 UID 做映射(不同的用户等级也可以设置不同的库存量)。
3)TairString:支持高并发 CAS 的 String
module里另一个结构TairString,对 Redis String进行修改,支持高并发 CAS 的 String,携带Version 的 String,有Version值,在读、写时带上Version值实现乐观所,注意这个String对应的数据结构是另一种,不能与 Redis 的普通 String 混用。
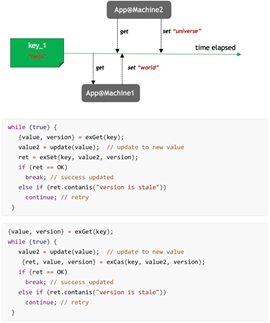
TairString的作用,如上图所示,先给一个exGet值,会返回(value,version),然后基于 value操作,更新时带上之前 version,如果一致,那么更新,否则重新读,然后去改再更新,实现CAS操作,在服务端就是乐观锁。
对于上述场景进一步优化,提供了exCAS接口,exCAS跟exSet一样,但遇到version冲突之后,不光返回version不一致的错误,并且顺带返回新的value跟新的version。这样的话,API调用又减少一次,先exSet之后用exCAS进行操作,如果失败了再“exSet -> exCAS” 减少网络交互,降低对Redis的访问量。
本节总结:
TairString:支持高并发 CAS 的 String。
• 携带 Version 的 String
• 保证并发更新的原子性;
• 通过 Version 来实现更新,乐观锁;
• 不能与 Redis 的普通 String 混用。
• 更多的语义
•exIncr/exIncrBy:抢购/秒(有上下界);
• exSet -> exCAS:减少网络交互。
• 详细文档:https://help.aliyun.com/document_detail/147094.html。
• 以 Module 形式开源:https://github.com/alibaba/TairString。
4)String 和 exString 原子计数的对比
String方式INCRBY,没有上下界;exString 方式是EXINCRBY,提供了各种各样的参数跟上下界,比如直接指定最小是0,当等于0时就不能再减了。另外还支持过期,比如某个商品只能在某个时间段抢购,过了这个时间点之后让它失效。业务系统也会做一些限制,缓存可以做限制,过了时间点把这个缓存清理掉。如果库存数量有限,比如如果没人购买,商品过10秒钟消掉;如果有人一直在买,这个缓存一直续期,可以在EXINCRBY里面带一个参数,每调用一次 INCRBY或者API就会给它续期,提升命中率。


计数器过期时间可以做什么?
1 某件商品指定在某个时间段抢购,需要在某个时间后库存失效。
2. 缓存的库存如果有限,没人购买的商品就过期删除,有人购买过就自动再续期一段时间(提升缓存命中率)。
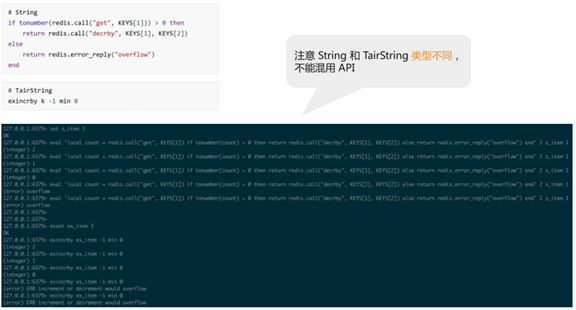
如下图所示,用Redis String,可以写上面这段Lua,“get”KEY[1]大于“0”的时候“decrby”减“1”,否则返回“overflow”错误,已经减到“0”不能再减。下面是执行的例子,ex_item设为“3”,然后减、减、减,当比“0”时返回“overflow”错误。
用exString非常简单,直接exset一个值,然后”exincrby k -1”。 注意 String 和TairString 类型不同,不能混用 API。