本篇博客主要参考了周志华老师团队在2017年IJCAI上发表的论文《Deep Forest: Towards an Alternative to Deep Neural Networks》。这篇文章的主要贡献是把深层次的神经网络的原理运用到了传统的机器学习算法“random forest”中去,并取得了和深度学习神经网络相当的效果。
众所周知,现在深度学习在工业界和学术界都非常的火,各种基于卷积神经网络和循环神经网络的各种模型在图像、文本处理方面都取得了很好的效果。在机器学习领域,现在几乎所有人的目光都转移到了基于深度学习模型的各种任务上来,即通过构建更加合理的神经网络结构提高基础模型的准确率;与之相对,那些传统的机器学习算法貌似被忽略了不少。而在这篇文章中,周志华老师就另辟蹊径,将随机森林模型进行有机的组合(主要是在深度上进行扩展),在文本和图像处理方面达到了和深度神经网络相当的效果。
首先,周老师提了一下目前深度神经网络的2个重要弊端:1 需要较大量的训练数据;2 针对A任务训练出来的网络结构,往往在B任务中效果非常的差,即基于深度神经网络的模型对任务敏感度更高,这样训练神经网络的过程更像是一种艺术技巧而非一种工程技巧。针对以上的两个问题,周老师将传统机器学习模型中的随机森林作为基础模型,提出了如下具有层级结构的网络:
Cascade Forest structure
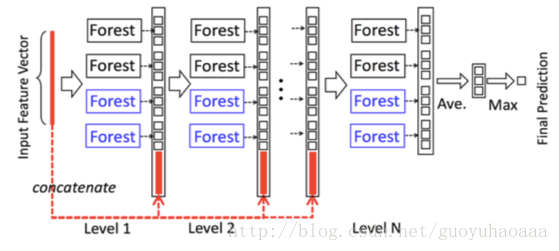
图中的示例任务是一个三分类的任务,从上图可以清楚的看出,输入的特征向量在经过level 1的4个随机森林之后,转换为了4个维度为3的向量,向量每一维的含义是该样例属于该类别的概率,接下来在输入level 2的时候是将这12维的向量和之前的输入拼接起来进行输入,依次类推直到最后一层,然后把最后一层的4个3维向量对位取平均,最大的那一维就是该样例所属的类别。在每一层的4个forest中,两个黑的代表了2棵包含了500棵树的“Random forest”(即每一棵树的生成样本都是对原始数据进行有放回的抽样获得,所依赖的特征是随机从所有特征中抽取
,在树节点进行分裂的时候采取Gini指数进行特征筛选);而两个蓝的代表了2棵包含了500棵树的“Complete-random forest”(即每一棵树的生成样本都是对原始数据进行有放回的抽样获得,但是在树节点进行分裂的时候是随机选取一个特征进行分裂,这样得到的树模型会具有更高的鲁棒性)。但是针对每一层森林进行训练的时候,为了增强整体模型的鲁棒性,使用k-fold交叉验证的方式来确定每一个数据的概率分布向量值,具体执行起来就是将所有的数据划分成k份,每次都挑选其中的k-1份来进行训练,这样就会生成k个不同的模型。很显然每一个数据都会在其中的k-1模型中训练到,然后平均这k-1个模型的输出概率向量值来作为这个样本针对下一层的输入值。
大家可能注意到的是,在该应用场景中每一个森林的输出都是一个三维的向量,每一维度都代表了属于该类别的概率,具体是通过下图做到的:
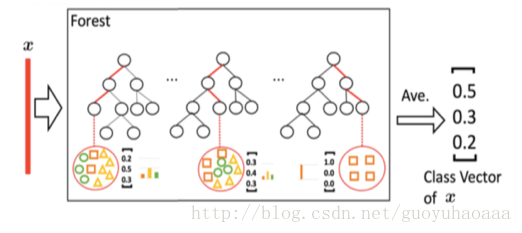
可以看出在该森林中,每一棵决策树的输出都是一个三维的向量,然后把这些三维向量进行平均就得到了该森林的三维输出向量。那么每一棵树的三维向量是如何得到的呢,就是在训练集上落在每一个叶子节点中各个类别样本的比例。
在深度神经网络中有两种基本的模型:卷积神经网络和循环神经网络,分别用力处理具有序列特征和二维空间的数据,周老师结合这两种网络的本质原理,提出了一种被称之为Multi-Grained Scanning的网络结构,当然肯定也是基于随机森林,其结构如下所示:
Multi-Grained Scanning
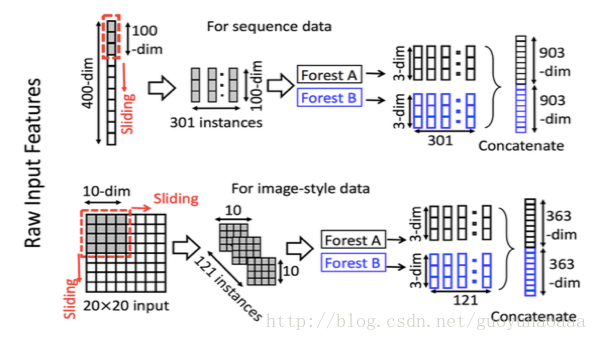
首先采用滑窗法进行特征的提取,上面那个是进行序列数据的特征提取,下面按个是进行二维空间数据的特征提取,我们以下面那个为例来进行说明。这个图片本身大小是20*20,采用卷积窗口的大小是10*10,那么采用slide为1的移动步长就会产生(20-10+1)*(20-10+1)=121 个扫描结果。这里需要注意的“ All feature vectors extracted from positive/negative training examples are regarded as positive/negative instances”,也就是说这121个结果的label都是一致的(反正我这里感觉有点不太对劲),然后同样是两颗具有500棵树的森林(一蓝一黑),把这121个扫描碎片变成了121个3维向量,然后把这些向量进行拼接,就得到了原始图像的向量化表示。(这里训练forest A和forest B的时候,应该是把所有的图像一起输入,把这些图像对应的121个碎片一起进行训练)
我们从上面可以看到,把Multi-Grained Scanning和Cascade Forest structure进行组合,就可以得到了一个能够对图片进行分类的类深度卷积网络,如下图所示:
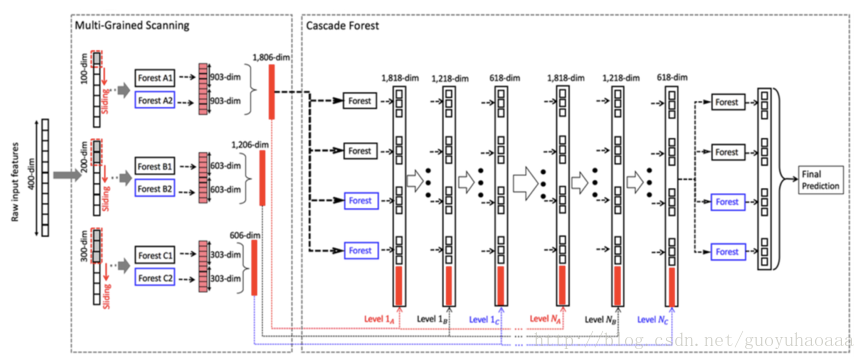
该例子以一个处理序列输入信号为例,来说明了该网络的工作原理。首先在Multi-Grained Scanning部分,可以看到有三个逻辑构建组成,这三个唯一的不同就是扫描的窗口大小不同(对应了CNN中不同的卷积器大小),这样一个样本在经过了Multi-Grained Scanning之后就变成了三个向量(分别对应了三个不同的卷积窗口,为了方便表示我们称之为A,B和C)。 然后首先A向量给level 1的4个forest进行训练,然后把level 1的4个输出向量和A拼起来进行level 2的4个forest的训练,以此类推知道最后一层输出结果。我个人感觉这样的层级连接结构和深度神经网络特别的像,只不过在训练模型的时候,深度神经网络采用了误差反向传播的方式,而该模型则是一层一层的进行训练,他的停止条件感觉也很特别:就是在新加一层之后模型在validate set上的准确率没有明显提升的话,就停止增长。
接下来周老师在多个数据集合多个任务上把他提出的模型和传统的深度神经网络进行对比,充分说明他提出模型的有效性和对不同任务的鲁棒性(即同一种结构的模型可以适配多种应用场景,就像图中的forest都是500棵树,在Multi-Grained Scanning中每一个扫描都采用了2个forest进行编码,在cascade forest部分每一个level的forest数量都是4个,而且是两黑两蓝)。同时周老师还提到,如果把最后一层的4个random forest换成GBDT的话效果还能够提升。
在未来工作方面,周老师指出该论文中在随机森林输出部分只是采取了最简单的一种对输入的编码方式,因为只利用到了随机森林的输出概率向量,其他的信息并没有利用到:比方说落入点的父节点信息,或者每一棵决策树对于一个样本判定的路径信息等。
不管怎样,周老师的这篇文章为我们打开了一个全新的视角来审视当下最火的深度神经网络模型和传统的机器学习算法的结合,还是挺有意义的。另外该模型的代码地址为:https://github.com/kingfengji/gcforest