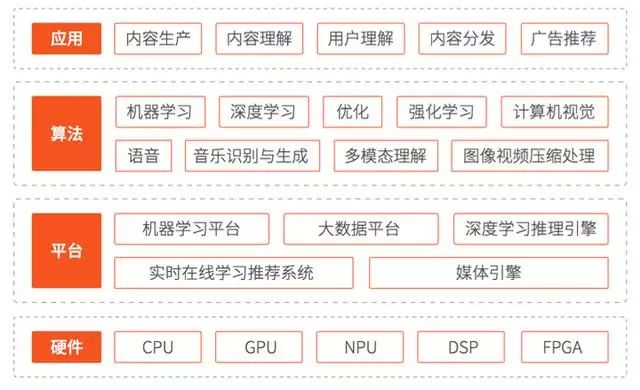
基于历史原因,行业内推荐模型的训练大都通过 CPU 来实现。然而随着模型从 Logistic Regression 到深度神经网络的演化以及硬件的发展,基于 CPU 的训练系统或许已经不再是最合适的解决方案了。本着不盲从、不抄袭、坚持原创技术路线的原则,快手西雅图 FeDA 智能决策实验室推出了名为"Persia"的基于 GPU 的广告推荐训练系统。以往需要 50 台 CPU 机器训练 20 小时的系统,如今只需要一台普通的 GPU 机器在一到两小时完成,单机效率提升高达 640 倍。
这意味着:
以往使用五十台计算机,一天只能尝试一个新想法,新系统只需一台计算机,一两个小时就能尝试一个新想法。
以往同时只能有一两个同学尝试新模型,新系统可以让很多同学同时尝试各自的新想法。
这套系统已经在快手商业化内部迅速推广使用,让大家可以快速试错和测试新模型以及特征。项目发起者是一位来自罗切斯特大学的实习生。他提出的 GPU 解决方案得到他在罗切斯特大学的导师、FeDA 智能决策实验室负责人刘霁和公司内很多算法策略专家的肯定。
FeDA 实验室随即成立了项目组,并决定以项目发起人最喜爱的漫画角色 Persia(“佩尔西亚”)命名,展开了紧锣密鼓的开发。团队首先以 PyTorch 为基础平台着手解决各种技术难题,然后实现并优化 TensorFlow 版本。经过 4 个月的开发和通力合作,Persia GPU 广告训练系统初步成型。系统同时支持 PyTorch 和 TensorFlow 两套方案,以方便模型开发同学的不同偏好。目前,Persia 已支持多个业务项目,每位研发人员只需要一台机器便可以迅速地迭代试错。
Persia 背后的技术
Persia 实现高效训练背后的技术包含 GPU 分布式训练、高速数据读取等多个方面。
GPU 分布式运算加速模型训练效率
近年来,GPU 训练已在图像识别、文字处理等应用上取得巨大成功。GPU 训练以其在卷积等数学运算上的独特效率优势,极大地提升了训练机器学习模型,尤其是深度神经网络的速度。然而,在广告模型中,由于大量的稀疏样本存在(比如用户 id),每个 id 在模型中都会有对应的 Embedding 向量,因此广告模型常常体积十分巨大,以至于单 GPU 无法存下模型。目前往往将模型存在内存中,由 CPU 进行这部分巨大的 Embedding 层的运算操作。这既限制了训练的速度,又导致实际生产中无法使用比较复杂的模型——因为使用复杂模型会导致 CPU 对给定输入计算时间过长,无法及时响应请求。
广告模型的构成:在广告模型中,模型往往由下图中的三部分构成:
用户 id、广告 id 等构成的 Embedding 层。每个 id 对应一个预设大小的向量,由于 id 数量往往十分巨大,这些向量常常会占据整个模型体积的 99% 以上。假设我们有 m1(注:因排版原因,此处 1 为下标,下同)种这样的 id:,它们对应的 Embedding 层 将会输出 m1 个向量。
图像信息、LDA 等实数向量特征。这部分将会与 id 对应的 Embedding vector 组合在一起,输入到 DNN 中预测点击率等。假设我们有 m2 种这样的向量:。
DNN。这部分是一个传统神经网络,接受 Embedding vector 和实数向量特征,输出点击率等希望预测的量:prediction = 。
Persia 使用多种技术训练广告模型,我们将在接下来几节依次介绍。
1. 大模型 Embedding 分片训练
广告模型的 Embedding 部分占模型体积和计算量的大部分。很有可能无法放入单个 GPU 的显存中。为了使用 GPU 运算以解决 CPU 运算速度过慢的问题,但又不受制于单 GPU 显存对模型大小的限制,Persia 系统使用多 GPU 分散存储模型,每个 GPU 只存储模型一部分,并进行多卡协作查找 Embedding 向量训练模型的模式。
Persia 将第 i 个 Embedding 层 Ei 放入第 (i% 总显卡数) 个显卡中,从而使每个显卡只存放部分 Embedding。与此同时,实数向量特征和 DNN 部分则置于第 0 个显卡中。在使用 Persia 时,它将自动在各个显卡中计算出 的值(如果对于一个 Embedding 输入了多个 id,则计算其中每个值对应的 Embedding vector 的平均),并传送给第 0 个显卡。第 0 个显卡会合并这些 Embedding vector 和实数向量特征,输入 DNN 中进行预测。
当求解梯度时,第 0 个显卡会将各个 Embedding 层输出处的导数传回各个显卡,各个显卡各自负责各自 Embedding 的反向传播算法求梯度。大致结构如下图所示:
GPU 分配的负载均衡:由于将 Embedding 依次分配在每个 GPU 上,可能导致部分 GPU 负载显著高于其他 GPU,为了让每个 GPU 都能充分发挥性能,Persia 训练系统还支持对 Embedding 运算在 GPU 上进行负载均衡。
给定 k 个 GPU,当模型的 m1 个 Embedding 层对应 GPU 负载分别为 l1, l2, …,lm1,Persia 将会尝试将 Embedding 分为 k 组 S1, S2, …, Sk,并分别存放在对应 GPU 上,使得每组 大致相等。这等价于如下优化问题:
其中 Vi 是第 i 个模型的大小,C 是单个 GPU 的显存大小。Persia 使用贪心算法得到该问题的一个近似解,并依此将不同 Embedding 均匀分散在不同 GPU 上,以达到充分利用 GPU 的目的。当需要精确求解最优的 Embedding 放置位置时,Persia 还可以通过 integer optimization 给出精确解。
2. 简化小模型多 GPU 分布训练
当模型大小可以放入单个 GPU 时,Persia 也支持切换为目前在图像识别等任务中流行的 AllReduce 分布训练模式。这样不仅可以使训练算法更加简单,在某些情景下还可以加快训练速度。
使用这种训练模式时,每个 GPU 都会拥有一个同样的模型,各自获取样本进行梯度计算。在梯度计算后,每个 GPU 只更新自己显存中的模型。需要注意的是即使模型可以置于一个 GPU 的显存中,往往 Embedding 部分也比较大,如果每次更新都同步所有 GPU 上的模型,会大大拖慢运算速度。因此 Persia 在 AllReduce 模式下,每次更新模型后,所有 GPU 使用 AllReduce 同步 DNN 部分,而 Embedding 部分每隔几个更新才同步一次。这样,即不会损失太多信息,又保持了训练速度。
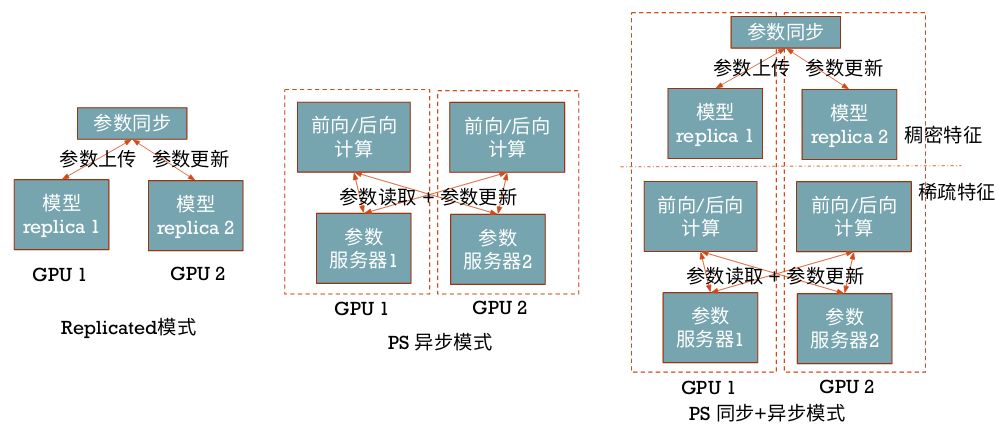
此外,在 TensorFlow 上,Persia 还支持 TensorFlow 的"Replicated", "PS", "PS" + "Asynchronous" 模式多卡训练,它们的主要区别如下图:

模型准确度提升
同步更新:由于普遍使用的传统异步 SGD 有梯度的延迟问题,若有 n 台计算机参与计算,每台计算机的梯度的计算实际上基于 n 个梯度更新之前的模型。在数学上,对于第 t 步的模型 xt,传统异步 SGD 的更新为:

其中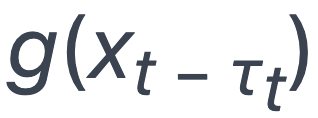 是训练样本的损失函数在τt 个更新之前的模型上的梯度。而τt 的大小一般与计算机数量成正比,当计算机数量增多,
是训练样本的损失函数在τt 个更新之前的模型上的梯度。而τt 的大小一般与计算机数量成正比,当计算机数量增多,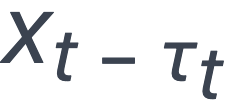 与 xt 相差就越大,不可避免地导致模型质量的降低。Persia 的训练模式在 Embedding 分片存储时没有这种延迟问题,而在 AllReduce 模式下也仅在 Embedding 层有常数量级的延迟,因此模型质量也有所提升。
与 xt 相差就越大,不可避免地导致模型质量的降低。Persia 的训练模式在 Embedding 分片存储时没有这种延迟问题,而在 AllReduce 模式下也仅在 Embedding 层有常数量级的延迟,因此模型质量也有所提升。
优化算法:与此同时,Persia 还可以使用 Adam 等 momentum optimizer,并为其实现了 sparse 版本的更新方式,比 PyTorch/TensorFlow 内置的 dense 版本更新在广告任务上快 3x-5x。这些算法在很多时候可以在同样时间内得到比使用 SGD 或 Adagrad 更好的模型。
训练数据分布式实时处理
快手 Persia 的高速 GPU 训练,需要大量数据实时输入到训练机中,由于不同模型对样本的需求不同,对于每个新实验需要的数据格式可能也不同。因此 Persia 需要:
简单灵活便于修改的数据处理流程,
可以轻易并行的程序架构,
节约带宽的数据传输方式。
为此,Persia 系统实现了基于 Hadoop 集群的实时数据处理系统,可以应不同实验需求从 HDFS 中使用任意多计算机分布式读取数据进行多级个性化处理传送到训练机。传输使用高效消息队列,并设置多级缓存。传输过程实时进行压缩以节约带宽资源。
1. 并行数据处理
数据处理 pipeline:为了使 Persia 获取数据的方式更灵活,Persia 使用 dataflow 构建数据处理 pipeline。在 Persia 中可以定义每一步处理,相当于一个函数,输入为上一个处理步骤的输出,输出提供给下一个处理步骤。我们定义这些函数为 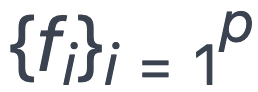 。在 Persia 中,这些函数可以单独定义修改。在每个函数的入口和出口,Persia 有数据队列缓存,以减少每个函数获取下一个输入的时间。这些函数的运行可以完全并行起来,这也是 pipeline 的主要目的。以在食堂就餐为例,pipeline 的运行就像这样:
。在 Persia 中,这些函数可以单独定义修改。在每个函数的入口和出口,Persia 有数据队列缓存,以减少每个函数获取下一个输入的时间。这些函数的运行可以完全并行起来,这也是 pipeline 的主要目的。以在食堂就餐为例,pipeline 的运行就像这样:

数据压缩和传输:全部处理之后,数据处理任务会将数据组成 mini-batch 并使用 zstandard 高速压缩每个 batch,通过 ZeroMQ 将压缩数据传输给训练机进行训练。定义 batching 操作为函数 B,压缩操作为函数 C,则每个数据处理任务相当于一个函数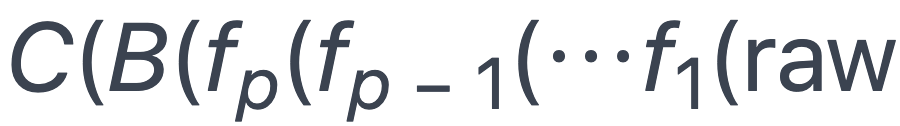
 。
。
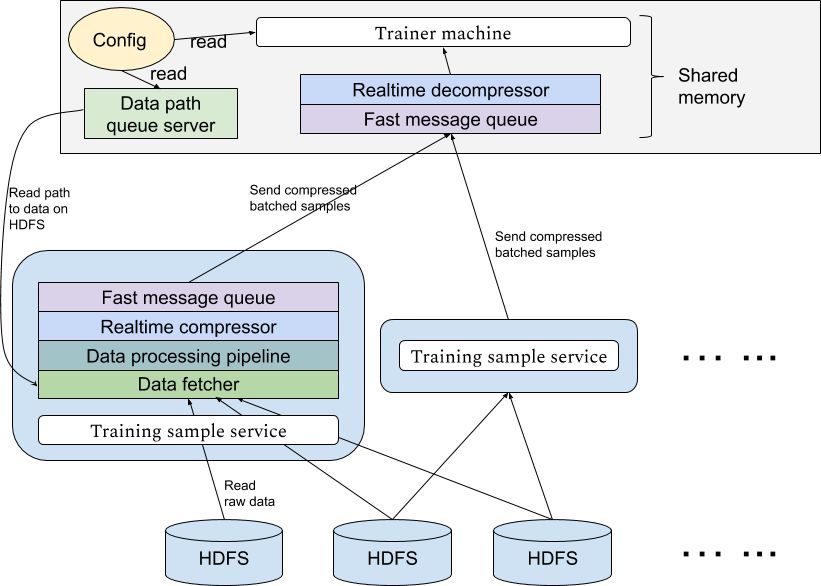
Queue server:在 Hadoop 集群中 Persia 将启动多个数据处理任务,每个数据处理任务之间完全独立。数据处理任务本身并不知道处理哪些数据,而是通过请求训练机得知训练数据的位置。这样的好处是,在 Persia 中训练机可以应自己需求动态控制使用什么样的训练数据,而数据处理任务相当于一个无状态的服务,即使训练机更换了新的训练任务也不需要重启数据处理任务。具体来说,在 Persia 中训练机会启动一个 queue server 进程,该 queue server 将会应数据处理任务的请求返回下一个需要读取的数据文件。Persia 的每个数据处理任务会同时从 queue server 请求多个文件,并行从 HDFS 读取这些文件。
整个系统的构造如下图:
2. 实时训练
由于 Persia 的数据处理任务在获取数据时完全依赖于训练机的指示,Persia 支持对刚刚生成的数据进行在线训练的场景,只需要使 queue server 返回最近生成的数据文件即可。因此,Persia 在训练时的数据读取模式上非常灵活,对 queue server 非常简单的修改即可支持任意数据读取的顺序,甚至可以一边训练一边决定下一步使用什么数据。
3. 更快的数据读取速度:训练机共享内存读取数据
由于训练机要同时接收从不同数据处理任务发送来的大量数据,并进行解压缩和传输给训练进程进行实际训练的操作,接收端必须能够进行并行解压和高速数据传输。为此,Persia 使用 ZeroMQ device 接收多个任务传输而来的压缩数据,并使用多个解压进程读取该 device。每个解压进程独立进行解压,并与训练进程共享内存。当结束解压后,解压进程会将可以直接使用的 batch 样本放入共享内存中,训练任务即可直接使用该 batch 进行训练,而无需进一步的序列化反序列化操作。
训练效果
Persia 系统在单机上目前实现了如下训练效果:
数据大小:百 T 数据。
样本数量:25 亿训练样本。
8 卡 V100 计算机,25Gb 带宽:总共 1 小时训练时间,每秒 64 万样本。
8 卡 1080Ti 计算机,10Gb 带宽:总共不到 2 小时训练时间,每秒 40 万样本。
4 卡 1080Ti 达 30 万样本 / 秒,2 卡 1080Ti 达 20 万样本 / 秒。
Persia 同样数据上 Test AUC 高于原 ASGD CPU 平台。
Persia 支持很大 batch size,例如 25k。
综上,Persia 不仅训练速度上远远超过 CPU 平台,并且大量节省了计算资源,使得同时尝试多种实验变得非常方便。
展望:分布式多机训练
未来,Persia 系统将展开分布式多 GPU 计算机训练。有别于成熟的计算机视觉等任务,由于在广告任务中模型大小大为增加,传统分布式训练方式面临计算机之间的同步瓶颈会使训练效率大为降低。Persia 系统将支持通讯代价更小、系统容灾能力更强的去中心化梯度压缩训练算法。据快手 FeDA 智能决策实验室负责人刘霁介绍,该算法结合新兴的异步去中心化训练 (Asynchronous decentralized parallel stochastic gradient descent, ICML 2018) 和梯度压缩补偿算法 (Doublesqueeze: parallel stochastic gradient descent with double-pass error-compensated compression, ICML 2019),并有严格理论保证,快手 Persia 系统在多机情景下预计还将在单机基础上做到数倍到数十倍效率提升。