RDD:RDD (Resilient Distributed Dataset) 叫做弹性分布式数据集,它归属于SpqrkCore模块中,是Spark中最基本的数据抽象,代码中RDD是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。并且RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作来进行。
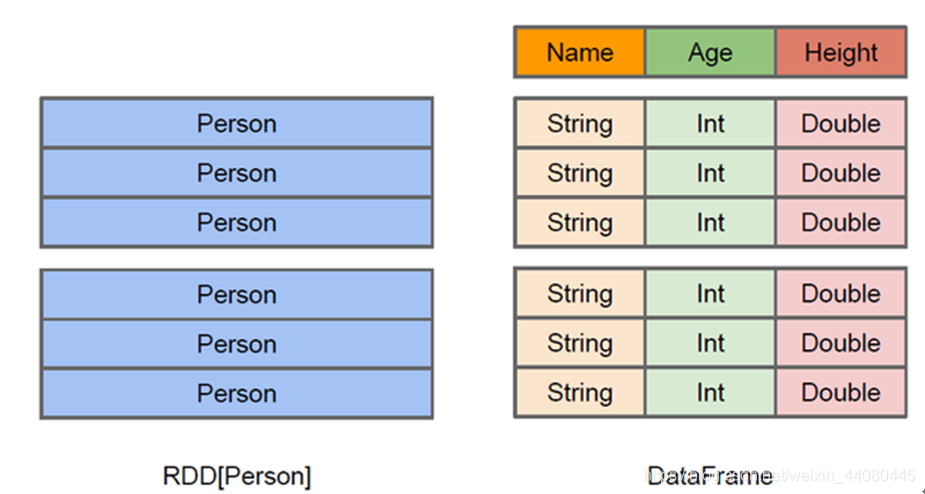
DataFrame: 归属于SparkSql模块里面,是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。相对于RDD来讲它多了schema元信息,即DataFrame它里面是结构化的信息包含了每一列的字段名和类型,这让SparkSql可以很方便的清楚了数据的具体信息,提升了任务的执行效率。
一图看懂DataFrame和RDD的区别:
DataSet: 也是归属于SparkSql模块,具有Spark SQL优化执行引擎的优点,它是建立在DataFrame之上的一个分布式数据集合,DateSet整合了RDD和DataFrame的优点,因为RDD支持的是非结构化的数据,DataFrame支持的是结构化的数据,而DataSet支持结构化和非结构化数据。相对于DataFrame来说DataSet它提供的是一种强类型的获取数据的方法(因为在DataFrame中获取某列数据你需要知道数据的类型以及索引,假设获取第一列的name需要getString(0) ,而在DataSet中只需要_.name就可以了),所以说它和DataFrame的最核心区别是在类型的判定上面,DataFrame在运行期才做类型的检查,而DataSet在程序的编译期就会做类型的检查,多了类型校验的功能。还有就是DataSet既具有类型安全检查也具有DataFrame的查询优化特性。
RDD,DataFrame和DataSet三者的联系:
1.RDD、DataFrame、DataSet全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利;
2.三者都有惰性机制,在进行create、transformation,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算;
3.三者有许多共同的函数,如filter,排序等;
4.在对DataFrame和Dataset进行操作许多操作都需要这个包:import spark.implicits._(在创建好SparkSession对象后尽量直接导入,要不然有的操作会报错)
5.RDD适用于迭代计算和数据这一类的操作,处理结构化的数据一般用DataFrame和Dataset进行。
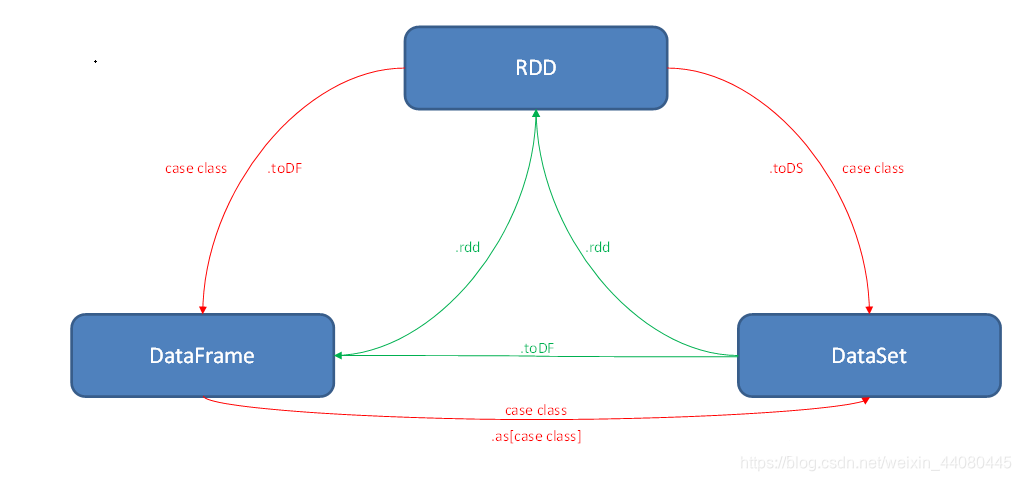
RDD,DataFrame和DataSet三者转换图: