文章目录
MR与远程数据库的交互
♦ 创建数据库及其表数据
Windows系统、Linux系统上都使用mysql创建表,录入数据~
DROP TABLE IF EXISTS `school`.`student`;
CREATE TABLE `school`.`student` (
`id` int(11) NOT NULL default '0',
`name` varchar(20) default NULL,
`sex` varchar(10) default NULL,
`age` int(10) default NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
mysql> insert into student values(201201, '张三', '男', 21);
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(201202, '李四', '男', 22);
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(201203, '王五', '女', 20);
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(201204, '赵六', '男', 21);
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(201205, '小红', '女', 19);
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(201206, '小明', '男', 22);
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+--------+------+------+------+
| id | name | sex | age |
+--------+------+------+------+
| 201201 | 张三 | 男 | 21 |
| 201202 | 李四 | 男 | 22 |
| 201203 | 王五 | 女 | 20 |
| 201204 | 赵六 | 男 | 21 |
| 201205 | 小红 | 女 | 19 |
| 201206 | 小明 | 男 | 22 |
+--------+------+------+------+
6 rows in set (0.00 sec)
一、远程数据库数据 —— 保存到本地
封装数据库表类
package MySQL;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class StudentRecord implements Writable, DBWritable {
public int id;
public String name;
public String sex;
public int age;
public StudentRecord() {
}
// 序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(id);
dataOutput.writeUTF(name);
dataOutput.writeUTF(sex);
dataOutput.writeInt(age);
}
// 反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
id = dataInput.readInt();
name = dataInput.readUTF();
sex = dataInput.readUTF();
age = dataInput.readInt();
}
// 向数据库中写数据
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setInt(1,this.id);
statement.setString(2,this.name);
statement.setString(3,this.sex);
statement.setInt(4,this.age);
}
// 从数据库中获取数据
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.id = resultSet.getInt(1);
this.name = resultSet.getString(2);
this.sex = resultSet.getString(3);
this.age = resultSet.getInt(4);
}
// 重写toString()
@Override
public String toString() {
return
id +"\t"+ name +"\t"+ sex +"\t"+ age;
}
}
Map阶段
package MySQL;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import java.io.IOException;
public class Map extends MapReduceBase implements Mapper<LongWritable, StudentRecord,Text, NullWritable> {
@Override
public void map(LongWritable key, StudentRecord value, OutputCollector<Text, NullWritable> output, Reporter reporter) throws IOException {
output.collect( new Text(value.toString()),NullWritable.get());
}
@Override
public void close() throws IOException {
}
@Override
public void configure(JobConf job) {
}
}
Driver驱动类
package MySQL;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import java.io.IOException;
public class Driver {
public static void main(String[] args) {
try {
JobConf conf = new JobConf(Driver.class);
conf.set("mapred.job.tracker","192.168.80.1:9000");
DistributedCache.addFileToClassPath(new Path("G:\Projects\IdeaProject-C\MapReduce\src\main\java\lib\mysql-connector-java-5.1.40-bin.jar"),conf);
// 设置出入类型
conf.setInputFormat( DBInputFormat.class);
// 设置输出类型
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(NullWritable.class);
// 设置map、reduce
conf.setMapperClass(Map.class);
// 设置输出目录
FileOutputFormat.setOutputPath(conf,new Path("G:\\Projects\\IdeaProject-C\\MapReduce\\src\\main\\java\\MySQL\\output"));
// 建立远程数据库连接
DBConfiguration.configureDB(conf,"com.mysql.jdbc.Driver","jdbc:mysql://192.168.64.178:3306/school","root","123456");
// 读取远程数据库中student表的数据
String[] fields = {
"id","name","sex","age"};
DBInputFormat.setInput(conf, StudentRecord.class,"student",null,"id",fields);
JobClient.runJob(conf);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e){
e.printStackTrace();
}
}
}
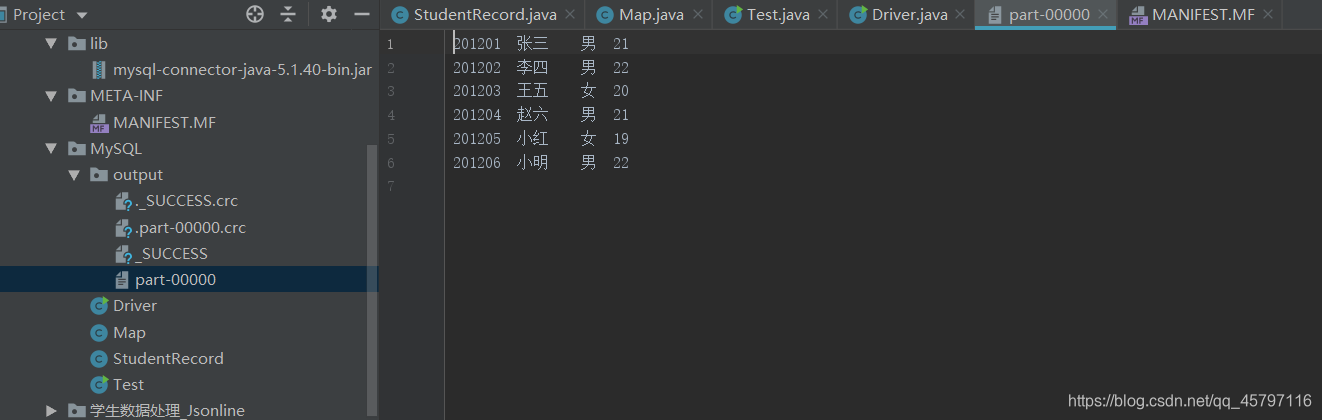
二、远程数据库数据 —— jar包运行_保存到HDFS
前面的部分都一样,主要是Driver驱动类里的改动。
- 1.设置虚拟机为文件获取的主机
- 2.更改文件输出路径为hdfs目录
- 3.
关键点:将第三方数据库连接包上传到hadoop_share_hadoop_common目录下

- 4.启动hadoop;启动数据库服务
- 5.运行jar包:
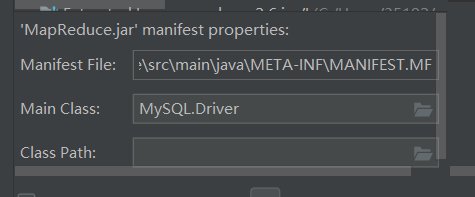
hadoop jar jar包名称(路径) 加载的主类,加载类的主类直接写成打的jar包中的 Main Class
package MySQL;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import java.io.IOException;
public class Driver {
public static void main(String[] args) {
try {
JobConf conf = new JobConf(Driver.class);
// 配置主节点(伪分布式、完全分布式) 改虚拟机为主机
conf.set("fs.default","hdfs://192.168.64.178:9000");
//conf.set("mapred.job.tracker","192.168.80.1:9000");
// 这里是对数据库连接工具包的声明 --- 不再需要
//DistributedCache.addFileToClassPath(new Path("G:\\Projects\\IdeaProject-C\\MapReduce\\src\\lib\\mysql-connector-java-5.1.40-bin.jar"),conf);
//DistributedCache.addFileToClassPath(new Path("/user/MR/mysql-connector-java-5.1.40-bin.jar"),conf);
// 设置出入类型
conf.setInputFormat( DBInputFormat.class);
// 设置输出类型
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(NullWritable.class);
// 设置map、reduce
conf.setMapperClass(Map.class);
// 设置输出目录 --- 改为hdfs的路径
//FileOutputFormat.setOutputPath(conf,new Path("G:\\Projects\\IdeaProject-C\\MapReduce\\src\\main\\java\\MySQL\\output"));
FileOutputFormat.setOutputPath(conf,new Path("/usr/output/mysqlTest/"));
// 建立数据库连接
DBConfiguration.configureDB(conf,"com.mysql.jdbc.Driver","jdbc:mysql://192.168.64.178:3306/school","root","123456");
// 读取student表中的数据
String[] fields = {
"id","name","sex","age"};
DBInputFormat.setInput(conf, StudentRecord.class,"student",null,"id",fields);
JobClient.runJob(conf);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e){
e.printStackTrace();
}
}
}
上传jar包
集群运行jar包
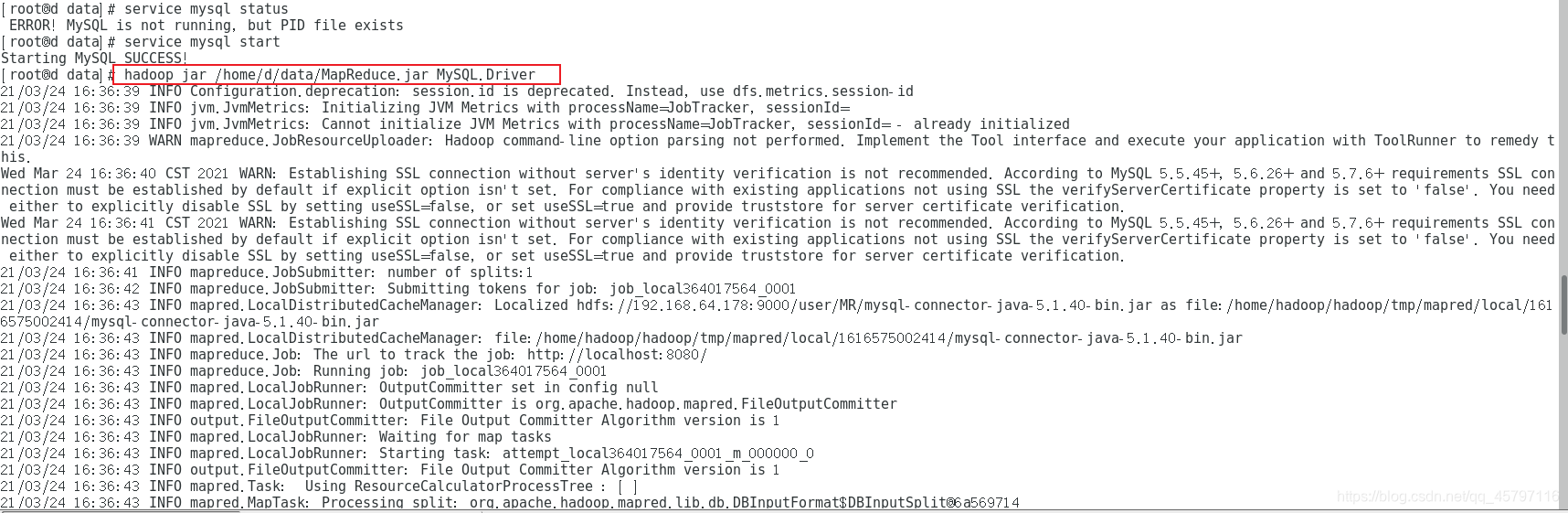
结果输出至hdfs,下载查看
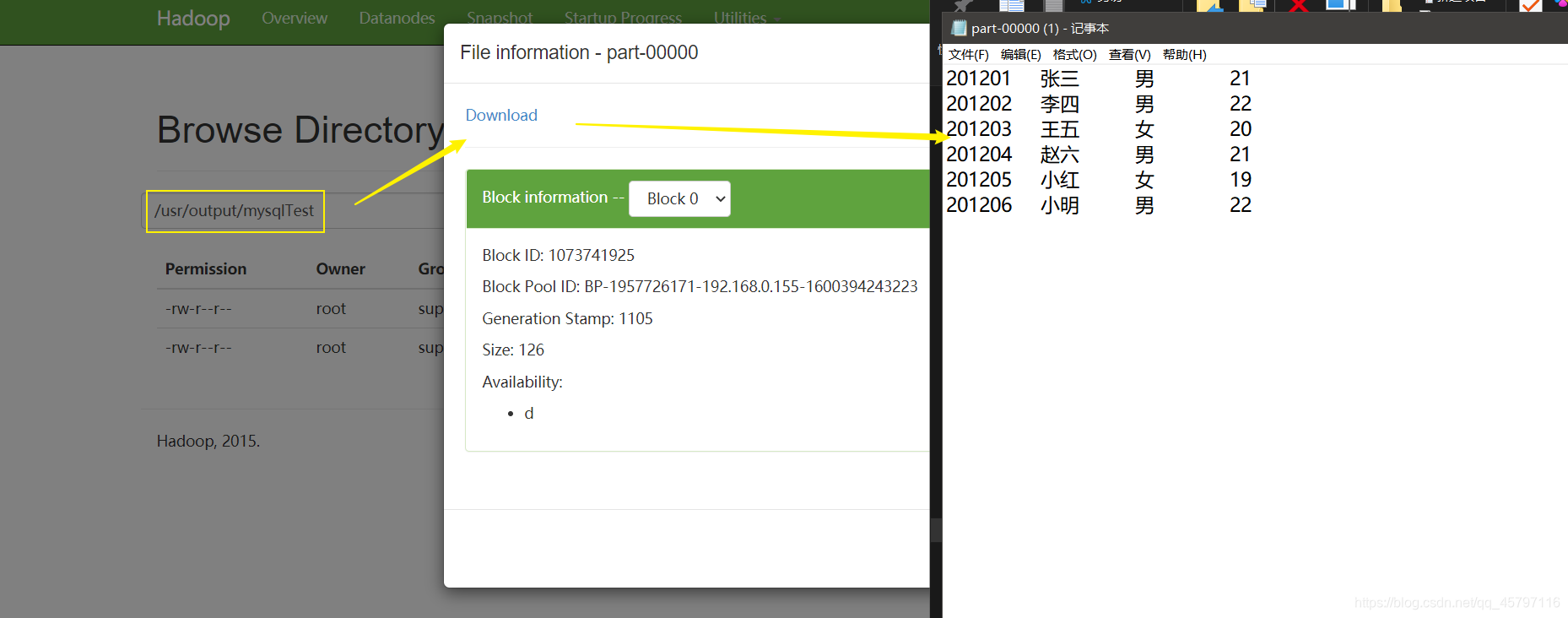
返回顶部
三、远程文件数据处理 —— 输出到数据库
下面展示一个小案例,就是读取虚拟机上的文件,然后进行wordcount计数统计,将结果存储到虚拟机上的数据库中。
数据库建表,用于存储结果:
DROP TABLE IF EXISTS school.wordcount;
USE school;
CREATE TABLE school.wordcount (
id int(11) NOT NULL auto_increment,
word varchar(20) default NULL,
number int(11) default NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
WordCount类:
package MySQL_word;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class WordRecord implements Writable, DBWritable {
public String word;
public int number;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(word);
dataOutput.writeInt(number);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
word = dataInput.readUTF();
number = dataInput.readInt();
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1,this.word);
statement.setInt(2,this.number);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.word = resultSet.getString(1);
this.number = resultSet.getInt(2);
}
@Override
public String toString() {
return word + '\t'+ number;
}
}
Map类:
package MySQL_word;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import java.io.IOException;
import java.util.StringTokenizer;
public class Map extends MapReduceBase implements Mapper<Object, Text,Text, IntWritable> {
private static IntWritable one = new IntWritable(1);
private Text k = new Text();
@Override
public void map(Object key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
// 获取一行数据
String line = value.toString();
// 使用StringTokenizer分割
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreElements()){
k.set(tokenizer.nextToken());
output.collect(k,one);
}
}
}
Combin类:
package MySQL_word;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import java.io.IOException;
import java.util.Iterator;
public class Combine extends MapReduceBase implements Reducer<Text, IntWritable, Text,IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()){
// 统计局部MapTask中的词频
sum += values.next().get();
}
// 写出
output.collect(key,new IntWritable(sum));
}
}
Reduce类:
package MySQL_word;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import java.io.IOException;
import java.util.Iterator;
public class Reduce extends MapReduceBase implements Reducer<Text, IntWritable,WordRecord,Text> {
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<WordRecord, Text> output, Reporter reporter) throws IOException {
// ReduceTask中的词频统计
int sum = 0;
while (values.hasNext()){
sum += values.next().get();
}
// 封装数据库表对象
WordRecord word = new WordRecord();
word.word = key.toString();
word.number = sum;
// 写出
output.collect(word,new Text());
}
}
Driver类:
package MySQL_word;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
public class Driver {
public static void main(String[] args) {
try {
JobConf conf = new JobConf(Driver.class);
conf.set("mapred.job.tracker","192.168.64.178:9000");
//conf.set("mapred.job.tracker","192.168.80.1:9000");
// 配置主类
conf.setMapperClass(Map.class);
conf.setCombinerClass(Combine.class);
conf.setReducerClass(Reduce.class);
// 设置输入输出类型
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(DBOutputFormat.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
// 设置文件输入路径
FileInputFormat.setInputPaths(conf,new Path("file:///home/d/data/word.txt")); // 虚拟机文件存储的路径
// FileOutputFormat.setOutputPath(conf,new Path("/usr/output/mysqlWrite/"));
// FileInputFormat.setInputPaths(conf,new Path("E:\\data\\word.txt"));
//FileOutputFormat.setOutputPath(conf,new Path("G:\\Projects\\IdeaProject-C\\MapReduce\\src\\main\\java\\MySQL_word\\output"));
// 建立数据库连接
DBConfiguration.configureDB(conf,"com.mysql.jdbc.Driver","jdbc:mysql://192.168.64.178:3306/school","root","123456");
// 写入数据库表中的数据
String[] fields = {
"word","number"};
DBOutputFormat.setOutput(conf,"wordcount",fields);
JobClient.runJob(conf);
}catch (Exception e){
e.printStackTrace();
}
}
}
编写好程序后,进行打包,然后发送至虚拟机上,启动hadoop,集群运行jar包,运行完成后,进入数据库查看结果。
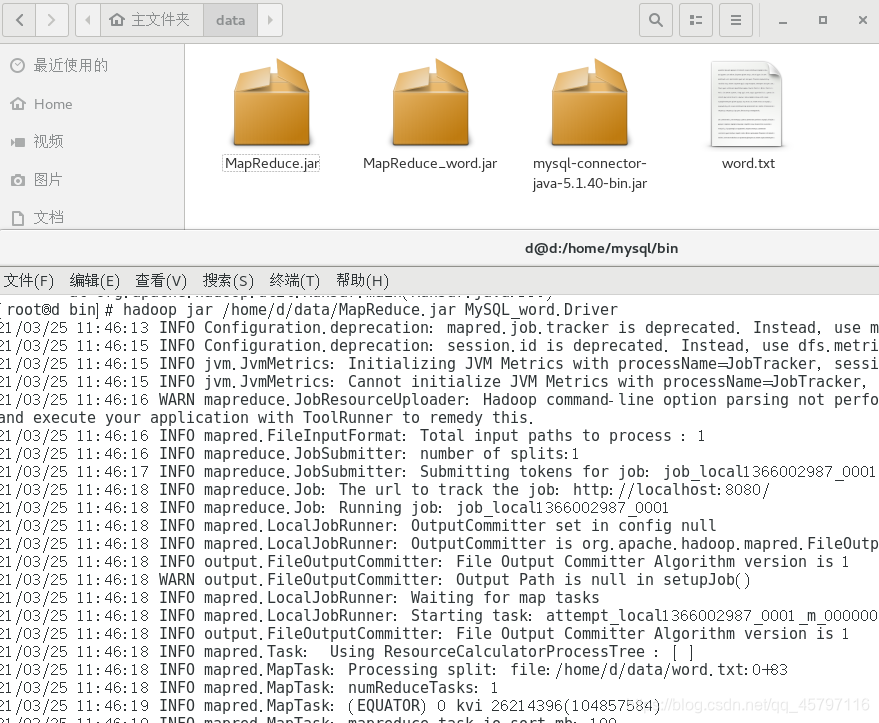
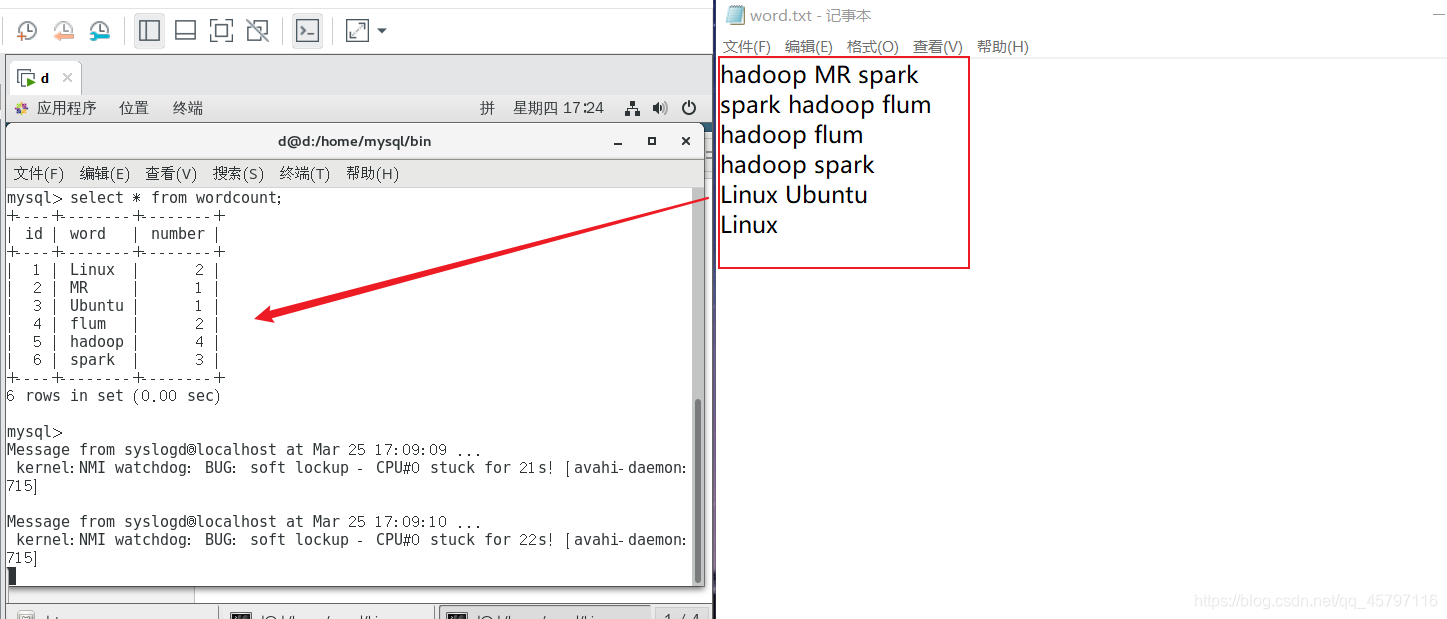
四、远程数据库数据处理 —— 输出到数据库
远程数据库建表添加数据:
mysql> create table words
-> (
-> chars varchar(20) not null
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> insert into words values("a");
Query OK, 1 row affected (0.00 sec)
mysql> insert into words values("b");
Query OK, 1 row affected (0.01 sec)
mysql> insert into words values("e");
Query OK, 1 row affected (0.01 sec)
mysql> insert into words values("a");
Query OK, 1 row affected (0.00 sec)
mysql> insert into words values("c");
Query OK, 1 row affected (0.01 sec)
mysql> insert into words values("v");
Query OK, 1 row affected (0.00 sec)
mysql> insert into words values("c");
Query OK, 1 row affected (0.00 sec)
mysql> insert into words values("c");
Query OK, 1 row affected (0.00 sec)
mysql> insert into words values("f");
Query OK, 1 row affected (0.00 sec)
mysql> insert into words values("l");
Query OK, 1 row affected (0.00 sec)
mysql> select * from words;
+-------+
| chars |
+-------+
| a |
| b |
| e |
| a |
| c |
| v |
| c |
| c |
| f |
| l |
+-------+
10 rows in set (0.00 sec)
创建结果集存储表:
mysql> create table answer
-> (
-> word varchar(20) primary key not null,
-> count int(100) not null
-> ) engine=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.01 sec)
package MySQL_wc;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class Words implements Writable,DBWritable {
public String chars;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(chars);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
chars = dataInput.readUTF();
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1,this.chars);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.chars = resultSet.getString(1);
}
public String getChars() {
return chars;
}
public void setChars(String chars) {
this.chars = chars;
}
}
package MySQL_wc;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class Answer implements Writable, DBWritable {
private String word;
private int count;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(word);
dataOutput.writeInt(count);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.word = dataInput.readUTF();
this.count = dataInput.readInt();
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1,this.word);
statement.setInt(2,this.count);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.word = resultSet.getString(1);
this.count = resultSet.getInt(2);
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}
package MySQL_wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class Map extends Mapper<LongWritable, Words,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Words value, Context context) throws IOException, InterruptedException {
// 获取一行数据
k.set(value.toString());
// 以(word,1)的形式写出
context.write(k,v);
}
}
package MySQL_wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class Reduce extends Reducer <Text, IntWritable,Answer, NullWritable> {
Answer k = new Answer();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 遍历相同key --- 相同的词
int count = 0;
for (IntWritable value:values){
count += value.get();
}
// 数据封装进数据库
k.setWord(key.toString());
k.setCount(count);
// 写出
context.write(k,NullWritable.get());
}
}
package MySQL_wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.Job;
public class Driver {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.64.178:9000");
// 创建数据库连接
DBConfiguration.configureDB(conf,"com.mysql.jdbc.Driver","jdbc:mysql://192.168.64.178:3306/school","root","123456");
// 获取job
Job job = Job.getInstance(conf);
// 配置
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setJarByClass(Driver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Answer.class);
job.setOutputValueClass(NullWritable.class);
// 配置读取、输出数据库信息
String[] field1 = {
"chars"};
String[] field2 = {
"word","count"};
DBInputFormat.setInput(job,Words.class,"words",null,"chars",field1);
DBOutputFormat.setOutput(job,"answer",field2);
// 提交job
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (Exception e){
e.printStackTrace();
}
}
}
运行后报错:
java.lang.Exception: java.io.IOException: Data truncation: Data too long for column 'word' at row 1
短眼一看,就知道这是因为数据库中的表keyWord中的某个字段设置的太短,导致出错。但是不明白为什么会长度不够,原始数据都是一个长度的字母,没办法只好修改表结构增大word字段的长度。
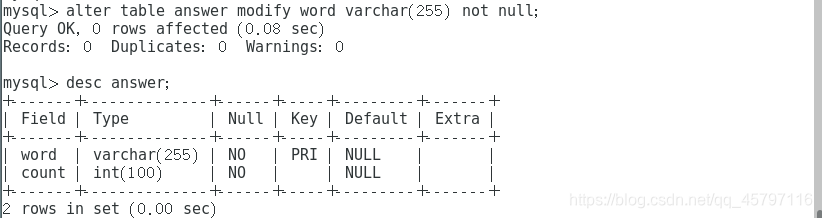
之后再次运行,成功了!但是结果有点惊喜,同时也解决了为什么上面会报错的问题~

这里输出的是一个内存地址?what?不过按照这样子,最后结果没问题,就是10。也就是说Map阶段我们输出的时候,输出错了,唯一的可能就是将某个对象输出了。
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Words value, Context context) throws IOException, InterruptedException {
// 获取一行数据
k.set(value.toString()); // 修改为 k.set(value.getChars());
// 以(word,1)的形式写出
context.write(k,v);
}
果不其然,这里我们输出了value.toString(),再看看value是啥?Words,也就是那张唯一映射过来的数据表类,由于没有重写toString()方法,所以返回的是内存地址。也就是这里返回的是一个对象,同一个key。而实际上我们需要的是里面的单词chars字段的值,所以进行修改: k.set(value.getChars());
然后再次运行,结果如下:
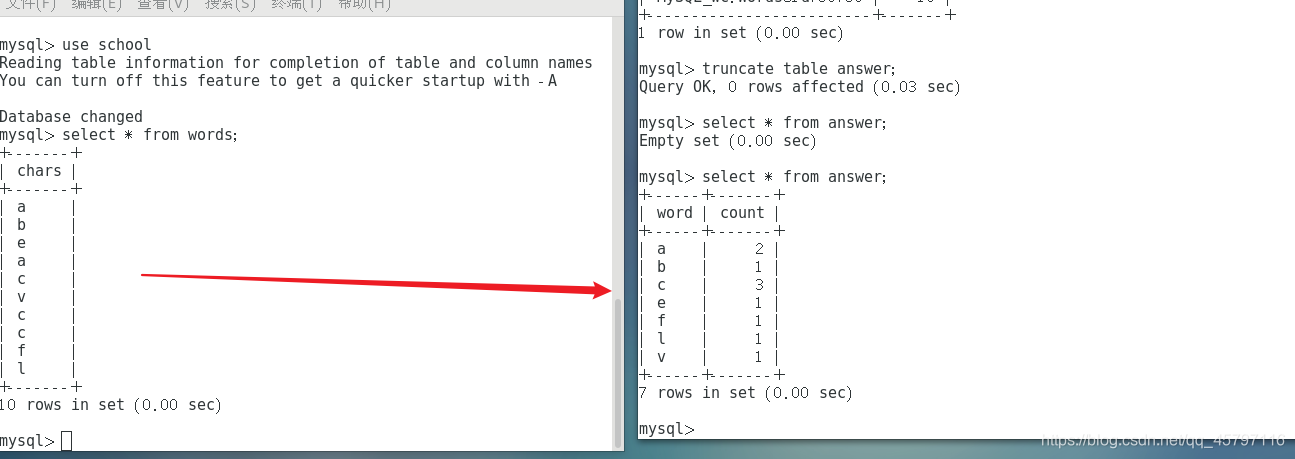
这里也可以打jar包放到集群上去运行~
参考1:https://blog.csdn.net/heiren_a/article/details/115137881?spm=1001.2014.3001.5502
参考2:Hadoop项目实战之将MapReduce的结果写入到Mysql
参考3:MapReduce与MySQL交互