 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
内核版本:3.15.2
引言
对于这个问题的想法起源于阿里一面面试官提出的问题,在用户态send成功以后我们可以保证对端收到所有的数据吗?
首先简单的考虑就是成功的定义,man手册中这样定义;

所以其实只有返回的数据为不是-1的话都算成功,此时就分为两种情况,完全写入和部分写入,显然后者当然无法保证所有的数据都被接收,因为写入的数据已然不足,当然无法收到全部的数据,这一般是由于拥塞窗口或者滑动窗口小于发送的数据包导致的。
另一种情况,其实也就是面试官想考的点,send完全发送数据以后是否可以保证对端收到数据[2],如果get到这个点的话其实可以看出其实考的就是发送缓冲区的问题,问题到了这里我不禁又对发送缓冲区和窗口的关系产生了疑问,因为在以前学习网络的过程中虽然很清楚滑动窗口和拥塞窗口的关系,但是对它们如何以代码的形式展现出来其实还是不清楚,好了,我们现在就解决这个疑问吧。
套接字
首先是套接字的格式:
struct socket {
socket_state state; // 套接字的状态
short type; // 套接字类型
unsigned long flags; //
struct file *file; // socket对应的file结构体
struct sock *sk; // 套接字维护所有的所有状态
const struct proto_ops *ops; // 里面存着协议相关的一些状态和钩子函数
struct socket_wq wq;
};
其中套接字的state其实就是去表示这个套接字处于哪个状态,比如说维护一个TCP连接的状态,具体可参考[3]:
enum {
TCP_ESTABLISHED = 1,
TCP_SYN_SENT,
TCP_SYN_RECV,
TCP_FIN_WAIT1,
TCP_FIN_WAIT2,
TCP_TIME_WAIT,
TCP_CLOSE,
TCP_CLOSE_WAIT,
TCP_LAST_ACK,
TCP_LISTEN,
TCP_CLOSING, /* now a valid state */
TCP_MAX_STATES /* Leave at the end! */
};
而type则是表示这是一个应用于什么协议的套接字,所以这样看来不同的协议是可以绑定同一个IP:port的,因为它们对应的套接字以及底层维护的状态根本就不是一套的。
在所有成员中struct sock其实是最重要的一个,其中维护了这个套接字上几乎所有的状态,其实在文档中也把这个字段描述为internal networking protocol agnostic socket representation[5],其中包括缓冲区,双方地址信息等等,当然这篇文章旨在搞清楚发送缓冲区与窗口关系,其中很多字段我其实没有深入了解,后面有兴趣研究网络协议栈的时候可以了解一下。
对于用户态来说我们得到一个套接字的方法一般有两种,一个是使用socket系统调用进行创建,其参数如下:
int socket(int domain, int type, int protocol);
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
我们可以看到socket其中指定了网络层和传输层的协议,type字段可以让我们指定对用户态来说套接字的行为,目前有两个选项SOCK_NONBLOCK和SOCK_CLOEXEC[6]。然后使用bind和某个IP:poet绑定在一起。
还有一种方法是accept返回一个套接字。
当accept返回一个fd时,此时其实我们已经持有了一个完成三次握手的可运作的套接字 了,此时就是如何操作它了。
整体套接字的结构体之间可以简单的用下图来描述[7]:
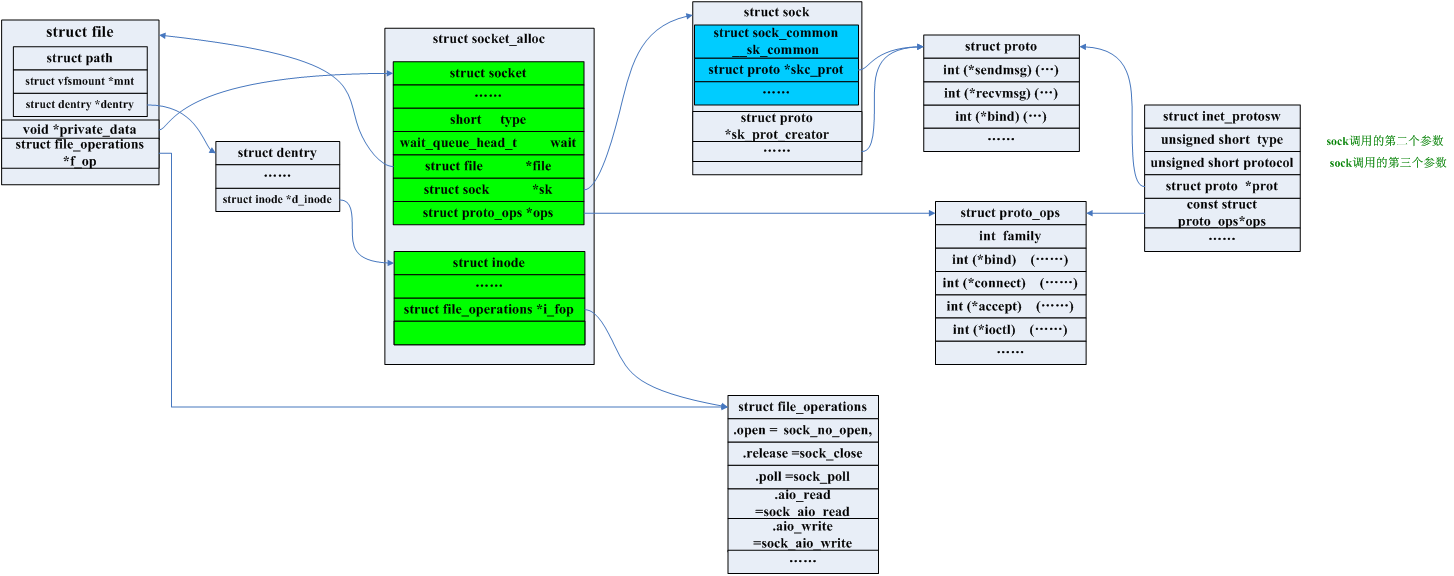
套接字当然是一个文件,我们使用fd可以在task_struct中的files_struct中找到file,struct socket存储在file的private_data字段,这样我们就可以通过fd拿到套接字了。
send过程
其实send本身就是sendto
SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len, unsigned, flags)
{
return sys_sendto(fd, buff, len, flags, NULL, 0);
}
下面这张图的一部分将会贯穿这篇文章:
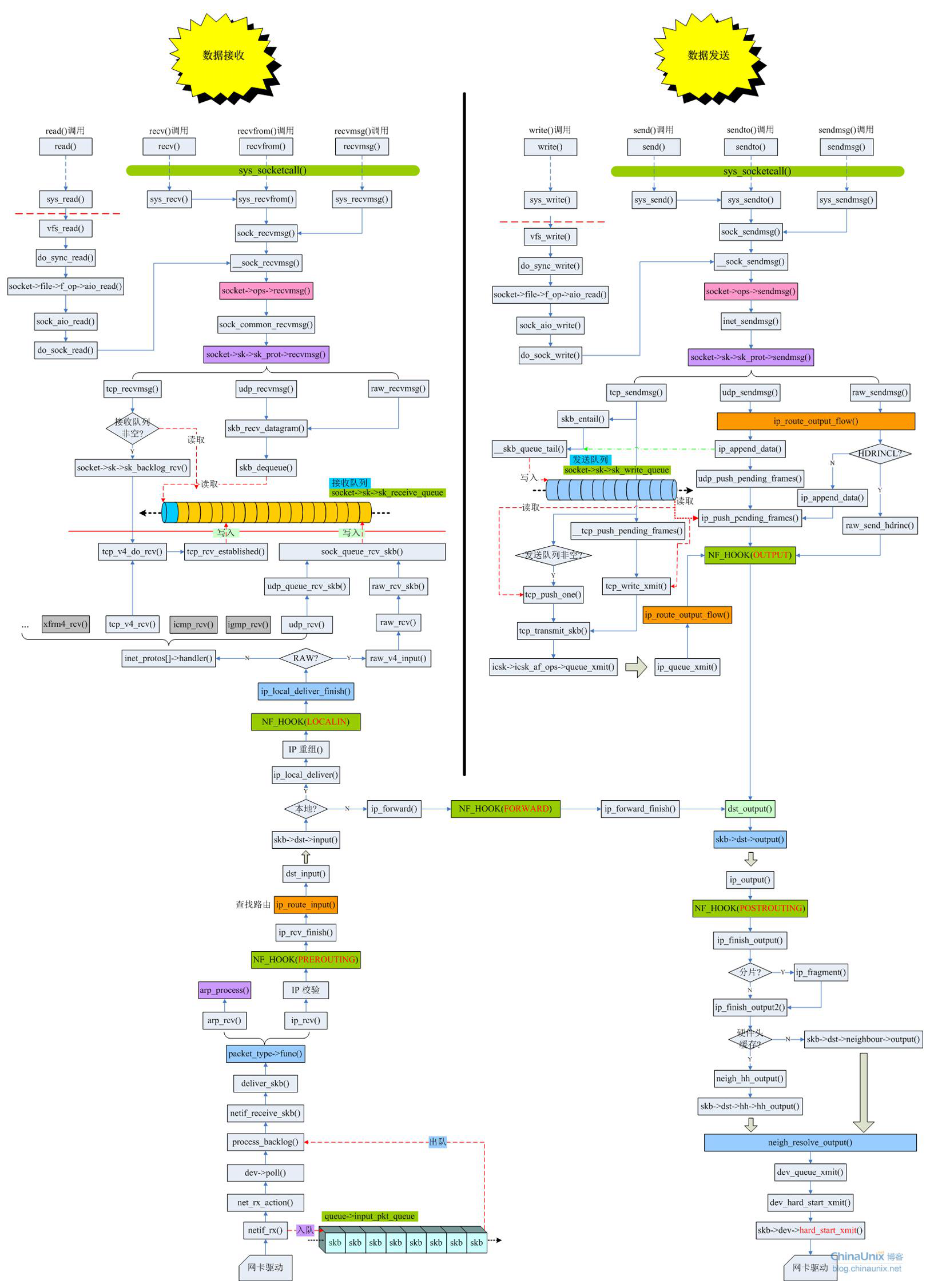
我们从sys_sendto开始分析。
从参数可以看出其实就是正常的那些用户态传入的玩意:
- fd用于查找
struct socket。 buff和len代表了用户要发送的数据。addr和addr_len代表了对端地址,用于udp的传输。
sendto
// 这个函数做的事情其实就是封装一个msg数据块
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len, unsigned, flags,
struct sockaddr __user *, addr, int, addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
int err;
struct msghdr msg;
struct iovec iov;
int fput_needed;
if (len > INT_MAX)
len = INT_MAX;
/* 通过文件描述符fd,找到对应的socket实例。
* 以fd为索引从当前进程的文件描述符表files_struct实例中找到对应的file实例,
* 然后从file实例的private_data成员中获取socket实例。
*/
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (! sock)
goto out;
/* 初始化消息头 */
iov.iov_base = buff;
iov.iov_len = len;
msg.msg_name = NULL;
msg.msg_iov = &iov;
msg.msg_iovlen = 1; /* 只有一个数据块 */
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
/* 把套接字地址从用户空间拷贝到内核空间 */
err = move_addr_to_kernel(addr, addr_len, &address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
/* 如果设置了非阻塞标志 */
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
/* 调用统一的发送入口函数sock_sendmsg(),我们下面看看这个函数*/
err = sock_sendmsg(sock , &msg, len);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
// 通过fd拿到socket
static struct socket *sockfd_lookup_light(int fd, int *err, int *fput_needed)
{
struct fd f = fdget(fd);
struct socket *sock;
*err = -EBADF;
if (f.file) {
sock = sock_from_file(f.file);
if (likely(sock)) {
*fput_needed = f.flags & FDPUT_FPUT;
return sock;
}
*err = -ENOTSOCK;
fdput(f);
}
return NULL;
}
struct socket *sock_from_file(struct file *file)
{
if (file->f_op == &socket_file_ops)
return file->private_data; /* set in sock_map_fd */
return NULL;
}
// 初始化一个异步IO控制块
int sock_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct kiocb iocb;
struct sock_iocb siocb;
int ret;
init_sync_kiocb(&iocb, NULL);
iocb.private = &siocb;
// 这里的size其实还是用户态传入的数据块长度,但是msg里面其实也是有的,不清楚为什么要加这么一个参数
ret = __sock_sendmsg(&iocb, sock, msg, size);
/* iocb queued, will get completion event */
if (-EIOCBQUEUED == ret)
ret = wait_on_sync_kiocb(&iocb);
return ret;
}
/* AIO控制块 */
struct kiocb {
struct file *ki_filp;
struct kioctx *ki_ctx; /* NULL for sync ops,如果是同步的则为NULL */
kiocb_cancel_fn *ki_cancel;
void *private; /* 指向sock_iocb */
union {
void __user *user;
struct task_struct *tsk; /* 执行io的进程 */
} ki_obj;
__u64 ki_user_data; /* user's data for completion */
loff_t ki_pos;
size_t ki_nbytes; /* copy of iocb->aio_nbytes */
struct list_head ki_list; /* the aio core uses this for cancellation */
/* If the aio_resfd field of the userspace iocb is not zero,
* this is the underlying eventfd context to deliver events to.
*/
struct eventfd_ctx *ki_eventfd;
};
接下来看看__sock_sendmsg,其实最主要的功能就是根据不同的协议调用不同的钩子函数。
static inline int __sock_sendmsg(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size)
{
int err = security_socket_sendmsg(sock, msg, size);
return err ?: __sock_sendmsg_nosec(iocb, sock, msg, size);
}
// 调用了个寂寞
static inline int security_socket_sendmsg(struct socket *sock,
struct msghdr *msg, int size){
return 0;
}
static inline int __sock_sendmsg_nosec(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size)
{
struct sock_iocb *si = kiocb_to_siocb(iocb);
si->sock = sock;
si->scm = NULL;
si->msg = msg;
si->size = size;
/* 调用Socket层的操作函数,如果是SOCK_STREAM,则proto_ops为inet_stream_ops, 函数指针指向inet_sendmsg(),最后调用tcp_sendmsg。 当然如果是SOCK_DGRAM调用的就是udp_sendmsg了。
*/
return sock->ops->sendmsg(iocb, sock, msg, size);
}
我们再来看看proto_ops的初始化过程,其实就是struct socket的ops字段:
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.flags = PROTO_CMSG_DATA_ONLY,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept,
.getname = inet_getname,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
#ifdef CONFIG_MMU
.mmap = tcp_mmap,
#endif
.sendpage = inet_sendpage,
.splice_read = tcp_splice_read,
.read_sock = tcp_read_sock,
.sendmsg_locked = tcp_sendmsg_locked,
.sendpage_locked = tcp_sendpage_locked,
.peek_len = tcp_peek_len,
#ifdef CONFIG_COMPAT
.compat_ioctl = inet_compat_ioctl,
#endif
.set_rcvlowat = tcp_set_rcvlowat,
};
const struct proto_ops inet_dgram_ops = {
.family = PF_INET,
.release = inet_release,
.bind = inet_bind,
.connect = inet_dgram_connect,
.socketpair = sock_no_socketpair,
.accept = sock_no_accept,
.getname = inet_getname,
.poll = udp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = sock_no_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
.mmap = sock_no_mmap,
.sendpage = inet_sendpage,
.set_peek_off = sk_set_peek_off,
#ifdef CONFIG_COMPAT
.compat_ioctl = inet_compat_ioctl,
#endif
};
可以看到sendmsg字段中的钩子函数都一样,都是inet_sendmsg函数。
int inet_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
sock_rps_record_flow(sk);
/* We may need to bnd the socket.
* 如果连接还没有分配本地端口,且允许自动绑定,那么给连接绑定一个本地端口。
* tcp_prot的no_autobaind为true,所以TCP是不允许自动绑定端口的。
*/
if (! inet_sk(sk)->inet_num && ! sk->sk_prot->no_autobind && inet_autobind(s))
return -EAGAIN;
/* 如果传输层使用的是TCP,则sk_prot为tcp_prot,sendmsg指向tcp_sendmsg() */
return sk->sk_prot->sendmsg(iocb, sk, msg, size);
}
/* Automatically bind an unbound socket. */
static int inet_autobind(struct sock *sk)
{
// 这个结构中其实存着对端ip:port 和本端的ip:port
struct inet_sock *inet;
/* We may need to bind the socket. */
lock_sock(sk);
/* 如果还没有分配本地端口 */
if (! inet->inet_num) {
/* SOCK_STREAM套接口的TCP操作函数集为tcp_prot,其中端口绑定函数为
* inet_csk_get_port()。
*/
if (sk->sk_prot->get_port(sk, 0)) {
release_sock(sk);
return -EAGAIN;
}
inet->inet_sport = htons(inet->inet_num);
}
release_sock(sk);
return 0;
}
struct inet_sock {
........
inet_daddr - Foreign IPv4 addr
inet_rcv_saddr - Bound local IPv4 addr
inet_dport - Destination port
inet_num - Local port
inet_saddr - Sending source
........
}
sk->sk_prot->sendmsg调用的就是不同的协议的钩子函数了,TCP调用tcp_sendmsg,UDP调用udp_sendmsg。
tcp_sendmsg
我们来看看tcp_sendmsg,此时我们持有四个资源:
- 异步IO控制块
struct sock- 经过封装的消息,其中数据块长度为1
- 这一个数据块的长度
可以看到整体的发送流程其实到这才刚刚开始。
借[9]中的话来说就是tcp_sendmsg的主要工作是把用户层的数据,填充到skb中,然后加入到sock的发送队列。之后调用tcp_write_xmit来把sock发送队列中的skb尽量地发送出去。下面的代码是我从[9]中中直接拷来的,[9]中有更详细的总结:
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size)
{
struct iovec *iov;
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb; // 一个插入发送缓冲区的数据块
int iovlen, flags, err, copied = 0;
int mss_now = 0, size_goal, copied_syn = 0, offset = 0;
bool sg;
long timeo;
lock_sock(sk);
flags = msg->msg_flags; // 数据块的状态,如果套接字为非阻塞,flag设置为MSG_DONTWAIT,sendto中有设置过
/* Send data in TCP SYN.
* 使用了TCP Fast Open时,会在发送SYN时携带上数据。
* 回想一下,fastopen会在第一次连接的时候设置cookie,后面连接只需要一个RTT,且可以携带数据。
*/
if (flags & MSG_FASTOPEN) {
err = tcp_sendmsg_fastopen(sk, msg, &copied_syn, size);
if (err == -EINPROGRESS && copied_syn > 0)
goto out;
else if (err)
goto out_err;
offset = copied_syn;
}
/* 发送的超时时间,如果是非阻塞的则为0 */
/*
static inline long sock_sndtimeo(const struct sock *sk, bool noblock){
return noblock ? 0 : sk->sk_sndtimeo;
}
*/
timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
/* Wait for a connection to finish.
* One exception is TCP Fast Open (passive side) where data is allowed to
* be sent before a connection is fully established.
* 等待连接完成。 TCP快速打开(被动端)是一个例外,其中允许在完全建立连接之前发送数据。
*/
/* 如果连接尚未完成三次握手,是不允许发送数据的,除非是Fast Open的被动打开方 */
if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) &&
! (tcp_passive_fastopen(sk)) {
/* 等待连接的建立,成功时返回值为0 */
if ((err = sk_stream_wait_connect(sk, &timeo)) != 0)
goto do_error;
}
/* 使用TCP_REPAIR选项时 */
if (unlikely(tp->repair)) {
/* 发送到接收队列中 */
if (tp->repair_queue == TCP_RECV_QUEUE) {
copied = tcp_send_rcvq(sk, msg, size);
goto out;
}
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out_err;
/* common sending to sendq */
}
/* This should be in poll.
* 清除使用异步情况下,发送队列满了的标志。
*/
clear_bit(SOCK_ASYNC_NOSPACE, &sk->sk_socket->flags);
/* 获取当前的发送MSS.
* 获取可发送到网卡的最大数据长度,如果使用GSO,会是MSS的整数倍。
* 获取一个skb可以容纳的数据量。
int tcp_send_mss(struct sock *sk, int *size_goal, int flags)
{
int mss_now;
mss_now = tcp_current_mss(sk);
// 计算size_goal的过程还是挺复杂的,有兴趣的朋友可以看看,这个函数返回值是 max(size_goal, mss_now);
*size_goal = tcp_xmit_size_goal(sk, mss_now, !(flags & MSG_OOB));
return mss_now;
}
*/
mss_now = tcp_send_mss(sk, &size_goal, flags);
/* Ok commence sending. */
iovlen = msg->msg_iovlen; /* 应用层数据块的个数*/
iov = msg->msg_iov; /* 应用层数据块数组的地址 */
copied = 0; /* 已拷贝到发送队列的字节数 */
err = -EPIPE; /* Broken pipe */
/* 检查之前TCP连接是否发生过异常,如果连接有错误,或者不允许发送数据了,那么返回-EPIPE */
if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN))
goto out_err;
sg = !! (sk->sk_route_caps & NETIF_F_SG); /* 网卡是否支持分散聚合 */
/* 遍历用户层的数据块数组 */
while (--iovlen >= 0) {
size_t seglen = iov->iov_len; /* 数据块的长度 */
unsigned char __user *from = iov->iov_base; /* 数据块的地址 */
iov++; /* 指向下一个数据块 */
/* Skip bytes copied in SYN.
* 如果使用了TCP Fast Open,需要跳过SYN包发送过的数据。
*/
if (unlikely(offset > 0)) {
if (offset >= seglen) {
offset -= seglen;
continue;
}
seglen -= offset;
from += offset;
offset = 0;
}
// 用户态数据块中还没发送的数据
while (seglen > 0) {
//copy保存本轮循环要拷贝的数据量
int copy = 0;
int max = size_goal; /* 单个skb的最大数据长度,如果使用了GSO,长度为MSS的整数倍 */
/*拿到发送队列的最后一个skb,因为该数据块当前已保存数据可能还没有超过size_goal,所以可以继续往该数据块中填充数据*/
/* sk_write_queue其实就是缓冲区了
static inline struct sk_buff *tcp_write_queue_tail(const struct sock *sk){
return skb_peek_tail(&sk->sk_write_queue);
}
static inline struct sk_buff *skb_peek_tail(const struct sk_buff_head *list_){
struct sk_buff *skb = READ_ONCE(list_->prev);
if (skb == (struct sk_buff *)list_)
skb = NULL;
return skb;
}
*/
skb = tcp_write_queue_tail(sk);
if (tcp_send_head(sk)) {
/* 还有未发送的数据,说明该skb还未发送 */
/* 如果网卡不支持检验和计算,那么skb的最大长度为MSS,即不能使用GSO */
if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
copy = max - skb->len; /* 此skb可追加的最大数据长度 */
}
if (copy <= 0) {
/* 需要使用新的skb来装数据 */
new_segment:
/* Allocate new segment. If the interface is SG,
* allocate skb fitting to single page.
*/
/* 如果发送队列的总大小sk_wmem_queued大于等于发送缓存的上限sk_sndbuf,
* 或者发送缓存中尚未发送的数据量超过了用户的设置值,就进入等待。
*/
if (! sk_stream_memory_free(sk))
goto wait_for_sndbuf;
/* 申请一个skb,其线性数据区的大小为:
* 通过select_size()得到的线性数据区中TCP负荷的大小 + 最大的协议头长度。
* 如果申请skb失败了,或者虽然申请skb成功,但是从系统层面判断此次申请不合法,
* 那么就进入睡眠,等待内存。
*/
skb = sk_stream_alloc_skb(sk, select_size(sk, sg), sk->sk_allocation);
if (! skb)
goto wait_for_memory;
/* All packets are restored as if they have already been sent.
* 如果使用了TCP REPAIR选项,那么为skb设置“发送时间”。
*/
if (tp->repair)
TCP_SKB_CB(skb)->when = tcp_time_stamp;
/* Check whether we can use HW checksum.
* 如果网卡支持校验和的计算,那么由硬件计算报头和首部的校验和。
*/
if (sk->sk_route_caps & NETIF_F_ALL_CSUM)
skb->ip_summed = CHECKSUM_PARTIAL;
/* 更新skb的TCP控制块字段,把skb加入到sock发送队列的尾部,
* 增加发送队列的大小,减小预分配缓存的大小。
*/
skb_entail(sk, skb);
copy = size_goal;
max = size_goal;
}
/* Try to append data to the end of skb.
* 本次可拷贝的数据量不能超过数据块的长度。
*/
if (copy > seglen) // 小于的话当然还是copy本身了
copy = seglen;
/* Where to copy to ?
* 如果skb的线性数据区还有剩余空间,就先复制到线性数据区。
*/
if (skb_availroom(skb) > 0) {
copy = min_t(int, copy, skb_availroom(skb));
/* 拷贝用户空间的数据到内核空间,同时计算校验和 */
err = skb_add_data_nocache(sk, skb, from, copy);
if (err)
goto do_fault;
} else {
/* 如果skb的线性数据区已经用完了,那么就使用分页区 */
bool merge = true;
int i = skb_shinfo(skb)->nr_frags; /* 分页数 */
struct page_frag *pfrag = sk_page_frag(sk); /* 上次缓存的分页 */
/* 检查分页是否有可用空间,如果没有就申请新的page。
* 如果申请失败,说明系统内存不足。
* 之后会设置TCP内存压力标志,减小发送缓冲区的上限,睡眠等待内存。
*/
if (! sk_page_frag_refill(sk, pfrag))
goto wait_for_memory;
/* 判断能否往最后一个分页追加数据 */
if (! skb_can_coalesce(skb, i, pfrag->page, pfrag->offset)) {
/* 不能追加时,检查分页数是否达到了上限,或者网卡不支持分散聚合。
* 如果是的话,就为此skb设置PSH标志,尽快地发送出去。
* 然后跳转到new_segment处申请新的skb,来继续填装数据。
*/
if (i == MAX_SKB_FRAGS || ! sg) {
tcp_mark_push(tp, skb);
goto new_segment;
}
merge = false;
}
copy = min_t(int ,copy, pfrag->size - pfrag->offset);
/* 从系统层面判断发送缓存的申请是否合法 */
if (! sk_wmem_schedule(sk, copy))
goto wait_for_memory;
/* 拷贝用户空间的数据到内核空间,同时计算校验和。
* 更新skb的长度字段,更新sock的发送队列大小和预分配缓存。
*/
err = skb_copy_to_page_nocache(sk, from, skb, pfrag->page, pfrag->offset, copy);
if (err)
goto do_error;
/* Update the skb. */
if (merge) {
/* 如果把数据追加到最后一个分页了,更新最后一个分页的数据大小 */
skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy);
} else {
/* 初始化新增加的页 */
skb_fill_page_desc(skb, i, pfrag->page, pfrag->offset, copy);
get_page(pfrag->page);
}
pfrag->offset += copy;
}
/* 如果这是第一次拷贝,取消PSH标志,*/
if (! copied)
TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH;
tp->write_seq += copy; /* 更新发送队列的最后一个序号 */
TCP_SKB_CB(skb)->send_seq += copy; /* 更新skb的结束序号 */
skb_shinfo(skb)->gso_segs = 0;
from += copy; /* 下次拷贝的地址 */
copied += copy; /* 已经拷贝到发送队列的数据量 */
/* 如果所有数据都拷贝好了,准备发送数据 */
if ((seglen -= copy) == 0 && iovlen == 0)
goto out;
/* 如果skb还可以继续填充数据,或者发送的是带外数据,或者使用TCP REPAIR选项,
* 那么继续拷贝数据,先不发送。
*/
if (skb->len < max || (flags & MSG_OOB) || unlikely(tp->repair))
continue;
/* 如果需要设置PSH标志 */
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
/* 尽可能的将发送队列中的skb发送出去,禁用nalge */
__tcp_push_pending_frames(sk, mss_now,TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now); /* 只发送一个skb */
continue;
wait_for_sndbuf:
/* 设置同步发送时,发送缓存不够的标志 */
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
wait_for_memory:
/* 如果已经有数据复制到发送队列了,就尝试立即发送 */
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH, size_goal);
/* 分两种情况:
* 1. sock的发送缓存不足。等待sock有发送缓存可写事件,或者超时。
* 2. TCP层内存不足,等待2~202ms之间的一个随机时间。
*/
if ((err = sk_stream_wait_memory(sk, &timeo)) != 0)
goto do_err;
/* 睡眠后MSS和TSO段长可能会发生变化,重新计算 */
mss_now = tcp_send_mss(sk, &size_goal, flags);
} // end while seglen > 0
} // end while --iovlen >= 0
out:
/* 如果已经有数据复制到发送队列了,就尝试立即发送 */
if (copied)
tcp_push(sk, flags, mss_now, tp->nonagle, size_goal);
release_sock(sk);
return copied + copied_syn;
do_fault:
if (! skb->len) {
/* 如果skb没有负荷 */
tcp_unlink_write_queue(skb, sk); /* 把skb从发送队列中删除 */
/* It is the one place in all of TCP, except connection reset,
* where we can be unlinking the send_head.
*/
tcp_check_send_head(sk, skb); /* 是否要撤销sk->sk_send_head */
sk_wmem_free_skb(sk, skb); /* 更新发送队列的大小和预分配缓存,释放skb */
}
do_error:
if (copied + copied_syn)
goto out;
out_err:
err = sk_stream_error(sk, flags, err);
release_sock(sk);
return err;
}
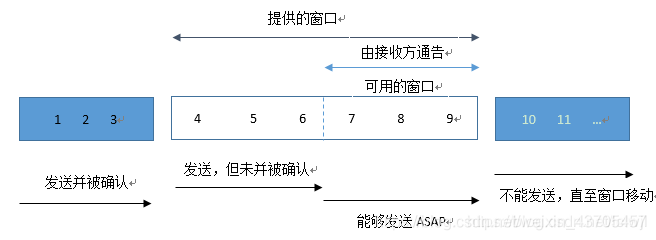
一个关于窗口与缓冲区的误区
我们可以看到tcp_sendmsg其实就是把用户态的数据拷贝到发送缓冲区中,注意这个拷贝的过程可以看出和窗口没啥关系,只和发送缓冲区大小以及内核的内存资源有关,所以我们不能简单的把窗口和发送缓冲区简单的理解为一个东西。课本上的滑动窗口的图很容易让人理解为当数据超过窗口大小时就会写入失败,其实这个想法是完全错误的。
tcp_push
在sock发送缓存不足、系统内存不足或应用层的数据都拷贝完毕等情况下,都会调用tcp_push来把已经拷贝到发送队列中的数据给发送出去。整个数据的发送过程在tcp_push中被描述,我们一起来看一看:
static void tcp_push(struct sock *sk, int flags, int mss_now, int nonagle, int size_goal)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
/* 如果没有未发送过的数据 */
if (! tcp_send_head(sk))
return;
/* 发送队列的最后一个skb */
skb = tcp_write_queue_tail(sk);
/* 如果接下来没有更多的数据需要发送,或者距离上次PUSH后又有比较多的数据,
* 那么就需要设置PSH标志,让接收端马上把接收缓存中的数据提交给应用程序。
*/
if (! (flags & MSG_MORE) || forced_push(tp))
tcp_mark_push(tp, skb);
/* 如果设置了MSG_OOB标志,就记录紧急指针 */
tcp_mark_urg(tp, flags);
/* 如果需要自动阻塞小包 */
if (tcp_should_autocork(sk, skb, size_goal)) {
/* avoid atomic op if TSQ_THROTTED bit is already set, 设置阻塞标志位 */
if (! test_bit(TSQ_THROTTLED, &tp->tsq_flags)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING);
set_bit(TSQ_THROTTLED, &tp->tsq_flags);
}
/* It is possible TX completion already happened before we set TSQ_THROTTED.
* 我的理解是,当提交给IP层的数据包都发送出去后,sk_wmem_alloc的值就会变小,
* 此时这个条件就为假,之后可以发送被阻塞的数据包了。
*/
if (atomic_read(&sk->sk_wmem_alloc) > skb->truesize)
return;
}
/* 如果之后还有更多的数据,那么使用TCP CORK,显式地阻塞发送 */
if (flags & MSG_MORE)
nonagle = TCP_NAGLE_CORK;// nagle和cork都可以阻止小包的发送,后者更极端一点
/* 尽可能地把发送队列中的skb发送出去。
* 如果发送失败,检查是否需要启动零窗口探测定时器。
*/
__tcp_push_pending_frames(sk, mss_now, nonagle);
}
/* Push out any pending frames which were held back due to TCP_CORK
* or attempt at coalescing tiny packets.
* The socket must be locked by the caller.
* push由于TCP_CORK而被阻止的所有挂起的帧,或尝试合并微小的数据包。
*/
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss, int nonagle)
{
/* If we are closed, the bytes will have to remain here.
* In time closedown will finish, we empty the write queue and
* all will be happy.
*/
if (unlikely(sk->sk_state == TCP_CLOSE))
return;
/* 如果发送失败 */
if (tcp_write_xmit(sk, cur_mss, nonagle, 0, sk_gfp_atomic(sk, GFP_ATOMIC)))
tcp_check_probe_timer(sk); /* 检查是否需要启用0窗口探测定时器*/
}
可以看到tcp_write_xmit才是最后的大boss,我们来看一看:
tcp_write_xmit
/* This routine writes packets to the network. It advances the
* send_head. This happens as incoming acks open up the remote
* window for us.
* 此例程将数据包写入网络。 它使send_head移动。 这发生在收到的ack中窗口大小变大的时候,注意,这里指流量窗口
*
* LARGESEND note: !tcp_urg_mode is overkill, only frames between
* snd_up-64k-mss .. snd_up cannot be large. However, taking into
* account rare use of URG, this is not a big flaw.
*
* Returns 1, if no segments are in flight and we have queued segments, but
* cannot send anything now because of SWS or another problem.
* 如果没有分段正在运行并且我们已将分段排队,则返回1,但是由于SWS或其他问题现在无法发送任何内容。
*/
static int tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
unsigned int tso_segs, sent_pkts;
int cwnd_quota;
int result;
/* sent_pkts用来统计函数中已发送报文总数。*/
sent_pkts = 0;
/* 检查是不是只发送一个skb buffer,即push one */
if (!push_one) {
/* 如果要发送多个skb,则需要检测MTU。
* 这时会检测MTU,希望MTU可以比之前的大,提高发送效率。
*/
/* Do MTU probing. */
result = tcp_mtu_probe(sk);
if (!result) {
return 0;
} else if (result > 0) {
sent_pkts = 1;
}
}
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
/* 设置有关TSO的信息,包括GSO类型,GSO分段的大小等等。
* 这些信息是准备给软件TSO分段使用的。
* 如果网络设备不支持TSO,但又使用了TSO功能,
* 则报文在提交给网络设备之前,需进行软分段,即由代码实现TSO分段。
*/
tso_segs = tcp_init_tso_segs(sk, skb, mss_now);
BUG_ON(!tso_segs);
/* 检查拥塞窗口, 可以发送几个segment */
/* 检测拥塞窗口的大小,如果为0,则说明拥塞窗口已满,目前不能发送。
* 拿拥塞窗口和正在网络上传输的包数目相比,如果拥塞窗口更大,则返回拥塞窗口减掉正在网络上传输的包数目剩下的大小。
* 该函数目的是判断正在网络上传输的包数目是否超过拥塞窗口,如果超过了,则不发送。
*/
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota)
break;
/* 检测当前报文是否完全处于发送窗口内,如果是则可以发送,否则不能发送 */
/*
Does at least the first segment of SKB fit into the send window?
static bool tcp_snd_wnd_test(const struct tcp_sock *tp,
const struct sk_buff *skb,
unsigned int cur_mss)
{
u32 end_seq = TCP_SKB_CB(skb)->end_seq;
if (skb->len > cur_mss) // 发送的包以cur_mss为单位,把skb的偏移量后移cur_mss
end_seq = TCP_SKB_CB(skb)->seq + cur_mss;
// 可以看出发送的单位是一个skb,如果小于滑动窗口的话可以发送;
// 至少在这看起来当数据大小大于窗口大小的时候不发送,这和我学的网络说的不太一样,这样就天然避免小包了,疑惑
// 当然换个角度,既然数据不到一个mss都小于窗口了,那么对端状态肯定不太好,不发也是对的
return !after(end_seq, tcp_wnd_end(tp));
}
static inline bool after(u32 seq1, u32 seq2)
{
return (s32)(seq1 - seq2) > 0;
}
// Returns end sequence number of the receiver's advertised window
static inline u32 tcp_wnd_end(const struct tcp_sock *tp)
{
return tp->snd_una + tp->snd_wnd;
}
*/
//
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now)))
break;
/* tso_segs=1表示无需tso分段 */
if (tso_segs == 1) {
// 更据上面的代码,nagle只有在发送数据小于窗口的时候才有用
/* 根据nagle算法,计算是否需要发送数据 */
if (unlikely(!tcp_nagle_test(tp, skb, mss_now,
(tcp_skb_is_last(sk, skb) ?
nonagle : TCP_NAGLE_PUSH))))
break;
} else {
/* 当不止一个skb时,通过TSO计算是否需要延时发送 */
/* 如果需要TSO分段,则检测该报文是否应该延时发送。
* tcp_tso_should_defer()用来检测GSO段是否需要延时发送。
* 在段中有FIN标志,或者不处于open拥塞状态,或者TSO段延时超过2个时钟滴答,
* 或者拥塞窗口和发送窗口的最小值大于64K或三倍的当前有效MSS,在这些情况下会立即发送,
* 而其他情况下会延时发送,这样主要是为了减少软GSO分段的次数,以提高性能。
*/
if (!push_one && tcp_tso_should_defer(sk, skb))
break;
}
limit = mss_now;
/* 在TSO分片大于1的情况下,且TCP不是URG模式。通过MSS计算发送数据的limit
* 以发送窗口和拥塞窗口的最小值作为分段段长*/
*/
if (tso_segs > 1 && !tcp_urg_mode(tp))
// limit就是我们可以立即发送的数据
limit = tcp_mss_split_point(sk, skb, mss_now, cwnd_quota);
/* 当skb的长度大于限制时,需要调用tso_fragment分片,如果分段失败则暂不发送 */
if (skb->len > limit &&
unlikely(tso_fragment(sk, skb, limit, mss_now)))
break;
/* 以上6行:根据条件,可能需要对SKB中的报文进行分段处理,分段的报文包括两种:
* 一种是普通的用MSS分段的报文,另一种则是TSO分段的报文。
* 能否发送报文主要取决于两个条件:一是报文需完全在发送窗口中,而是拥塞窗口未满。
* 第一种报文,应该不会再分段了,因为在tcp_sendmsg()中创建报文的SKB时已经根据MSS处理了,
* 而第二种报文,则一般情况下都会大于MSS,因为通过TSO分段的段有可能大于拥塞窗口的剩余空间,
* 如果是这样,就需要以发送窗口和拥塞窗口的最小值作为段长对报文再次分段。
*/
/* 更新tcp的时间戳,记录此报文发送的时间 */
TCP_SKB_CB(skb)->when = tcp_time_stamp;
// 发送数据
/* tcp_transmit_skb的注释
* 该例程实际上传输由tcp_do_sendmsg()排队的TCP数据包。
* 初始传输和可能的后续重传都使用此功能。 在这里看到的所有SKB都 是完全无头的。
* 我们的工作是构建TCP标头,并将数据包向下传递到IP,这样它就可以执行相同的操作,并将数据包传递给设备。
* 我们在这里使用的是原始SKB的克隆,或者是由重新传输引擎制作的新的唯一副本。
* 这里让我想到sendfile,可以参考这篇文章 https://www.cnblogs.com/lpfuture/p/7678143.html
* 发送数据的时候从socket到协议层还需要一次拷贝,看来就在这里了。
*/
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
/* Advance the send_head. This one is sent out.
* This call will increment packets_out.
*/
/* 更新统计,并启动重传计时器 */
/* 调用tcp_event_new_data_sent()-->tcp_advance_send_head()更新sk_send_head,
* 即取发送队列中的下一个SKB。同时更新snd_nxt,即等待发送的下一个TCP段的序号,
* 然后统计发出但未得到确认的数据报个数。最后如果发送该报文前没有需要确认的报文,
* 则复位重传定时器,对本次发送的报文做重传超时计时。
*/
tcp_event_new_data_sent(sk, skb);
/* 更新struct tcp_sock中的snd_sml字段。snd_sml表示最近发送的小包(小于MSS的段)的最后一个字节序号,
* 在发送成功后,如果报文小于MSS,即更新该字段,主要用来判断是否启动nagle算法
*/
tcp_minshall_update(tp, mss_now, skb);
sent_pkts++;
if (push_one)
break;
}
/* 如果本次有数据发送,则对TCP拥塞窗口进行检查确认。*/
if (likely(sent_pkts)) {
tcp_cwnd_validate(sk);
return 0;
}
/*
* 如果本次没有数据发送,则根据已发送但未确认的报文数packets_out和sk_send_head返回,
* packets_out不为零或sk_send_head为空都视为有数据发出,因此返回成功。
*/
return !tp->packets_out && tcp_send_head(sk);
}
我们从tcp_transmit_skb看到数据的一次拷贝,所以我们要从用户态发一个网络数据包的话至少两次拷贝,一次用户态到内核态,一次从socket缓冲区(skb)copy到相关协议层。
总结
我们再来回顾一下一个数据包的发送过程以及一些需要注意的点:
sendto对用户态的数据进行封装,伴随这一次从用户态到内核态的拷贝。sendmsg通过套接字协议的不同调用不同的发送处理函数,TCP调用tcp_sendmsg,UDP调用udp_sendmsg。- 以
tcp_sendmsg为例,主要把数据封装后插入数据缓冲区,可能插入失败,但是只于发送缓冲区大小以及内核的内存资源有关,这里暂时与窗口无关。 tcp_push负责把已经拷贝到发送队列中的数据给发送出去,最终调用tcp_write_xmit。tcp_write_xmit先检查拥塞窗口,再检查流量窗口,当小于两者的时候才进行发送,这里有一点很迷惑,就这个版本的源码来看,当发送的数据小于mss且大于窗口时一个字节也不发送。这样看来nagle,cork只有在数据包小于流量窗口时才有效。- 最后调用
tcp_transmit_skb发送数据包,这里藏着又一次拷贝,即从内核态到协议引擎的拷贝。 - 数据拷贝到了协议层以后就返回了,至于发送成功不成功与send就没有关系了。
回到这篇文章的主旨,一个是面试官的问题,一个是题目,我想答案已经很清楚了。
首先是面试官的问题,显然不可以,因为数据拷贝到协议引擎中的时候send已经返回了,发没发到对端机器根本不知道,就算发送到了也可能存在接收缓冲区没被应用接收,所以唯一一个确定对端收到数据的方法就是用户态的ACK。
接下来是网络发送缓冲区与窗口的关系,其实如果真的看完了上面的代码这个问题已经很明显了,或者只看tcp_write_xmit也可以,其实就是数据在没超过缓冲区上限(/proc/sys/net/ipv4/tcp_wmemd 描述了最小默认和最大的发送缓冲区大小)和内存上限的时候数据都存在发送缓冲区中,每次send都会尝试发送,当超过拥塞窗口和流量窗口的时候不会发送,
这里有一个不确定的小细节,就是当发送的数据小于mss且大于窗口时一个字节也不发送,这篇文章我已经第三次提起这个问题了。
最后纠正一个一直以来我观念上的一个错误,也是一个写过服务端代码的人可能都有的谬误,即write返回值小于数据块的时候与什么有关?我一直坚定不移的认为只与拥塞窗口和流量窗口有关,其实这是一个大错特错的想法,这也再次高速我们想当然的都不是真理。问题的答案是与发送缓冲区上限,内核内存上限,拥塞窗口和流量窗口都有关,且与前两者的关系更紧密些。这也告诉我们write成功这个数据可能根本就在缓冲区,连协议引擎都没进过去,更别说网卡,甚至对方机器或者对端应用层了。
这只是TCP发送部分,东西就已经很多了,其中很多细节都不是很理解,只能说大概明白了发送的过程。
接收部分就留到后面有时间或者需求的时候吧。
祝春招一切顺利。
我困了,该睡觉了。
参考: