1.词嵌入(word2vec)
自然语言是一套用来表达含义的复杂系统。在这套系统中,词是表义的基本单元。顾名思义,词向量是用来表示词的向量,也可被认为是词的特征向量或表征。把词映射为实数域向量的技术也叫词嵌入(word embedding)。近年来,词嵌入已逐渐成为自然语言处理的基础知识。
2.为何不采用one-hot向量
- 【如何使用one-hot】
1、 假设词典中不同词的数量(词典大小)为N,每个词可以和从0到N−1的连续整数一一对应。这些与词对应的整数 叫作词的索引。
2、假设一个词的索引为i,为了得到该词的one-hot向量表示,我们创建一个全0的长为N的向量,并将其第i位设成1。这样 一来,每个词就表示成了一个长度为N的向量,可以直接被神经网络使用。
3、简单来说:就是有多少个不同的词,我就会创建多少维的向量,如上:一个词典中有N个不同词,那么就会开创N维的 向量,其中单词出现的位置为以1,该位置设为i,那么对应的向量就生成了。举个例子:[我,喜,欢,学,习],其中 的 “我”就可以编码为:[1,0,0,0,0],后面的“喜”就可以编码为:[0,1,0,0,0],依次类推。
- 【存在的问题】
1、无法使用该方法进行单词之间的相似度计算。
2、原因就是每个单词在空间中都是正交的向量,彼此之间没有任何联系。
3、比如我们通过余弦相似度进行度量。

4、对于向量,它们的余弦相似度是它们之间夹角的余弦值。
- 【解决策略】
1、既然one-hot的方式没有办法解决,那么我们就需要通过词嵌入的方式来解决。也就是我们后面重点要讲解的word2vec 的方 法。该方法目前有两种实现模型。
1.1、跳字模型(skip-gram):通过中心词来推断上下文一定窗口内的单词。
1.2、连续词袋模型(continuous bag of words,CBOW):通过上下文来推断中心词。
3.跳字模型(skip-gram)
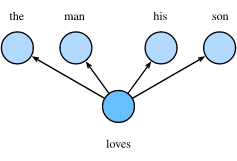
- 下面围绕着这样一幅图片进行展开。
- 首先我们举个栗子来说明这个算法在干嘛。
1、假设在我们的文本序列中有5个词,[“the”,“man”,“loves”,“his”,“son”]。
2、 假设我们的窗口大小skip-window=2,中心词为“loves”,那么上下文的词即为:“the”、“man”、“his”、“son”。这里的上 下文词又被称作“背景词”,对应的窗口称作“背景窗口”。
3、跳字模型能帮我们做的就是,通过中心词“loves”,生成与它距离不超过2的背景词“the”、“man”、“his”、“son”的条件概 率,用公式表示即:
P(“the",“man",“his",“son"∣“loves").
4、进一步,假设给定中心词的情况下,背景词之间是相互独立的,公式可以进一步得到:
P(“the"∣“loves")⋅P(“man"∣“loves")⋅P(“his"∣“loves")⋅P(“son"∣“loves").
5、上面的变换就类似于贝叶斯到朴素贝叶斯的变换过程。
6、简单图示可以表示为:
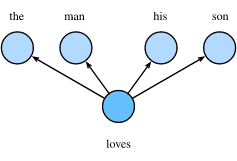
7、可以看得出来,这里是一个一对多的情景,根据一个词来推测2m个词,(m表示背景窗口的大小)。
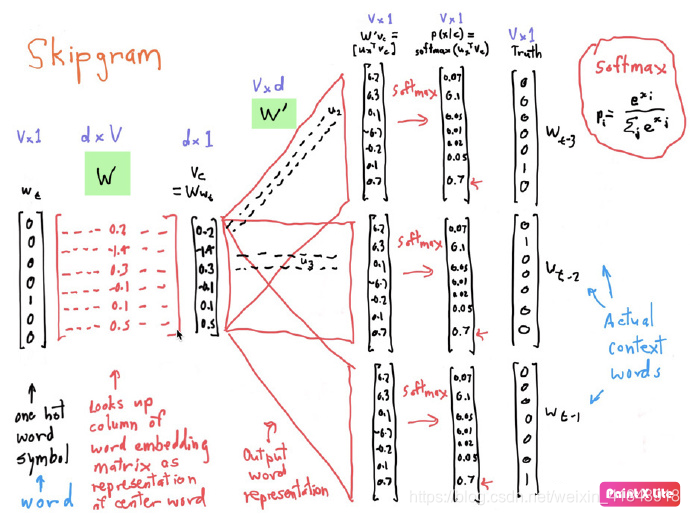
8、通过上面的例子大概清楚,skip-gram在做什么,那么就一步一步来解析上面的图。
3.1 one-hot word symbol(编码)
- 第一步,进行one-hot编码,有同学可以能疑惑,开篇就说了one-hot不行,存在着致命的问题,没有办法计算单词之间的相似度,但是我们不要忽略一个事实,计算机没办法识别“字符”,所有的数据必须转化成二进制的编码形式。
- 那么既然选择了使用one-hot进行编码,该怎么进行处理呢?
1、这个其实也非常的简单,就是常规操作,相信学过机器学习的都清楚,为了扫盲下面在啰嗦一下。
2、比如我这里的文本序列为:[“the”,“man”,“loves”,“his”,“son”],那么可以进行如下编码了。
the :[1,0,0,0,0]
man:[0,1,0,0,0]
loves:[0,0,1,0,0]
his:[0,0,0,1,0]
son:[0,0,0,0,1]
- 这样的方式非常的简单,编码后的结果就是一个非常稀疏的矩阵了。(稀疏到什么程度呢?每一行只有一个元素,其余的都为0)
- 比如:我的词典里有N个不重复的单词,那么整体编码后就是N∗N维的一个大矩阵了,对于一个单词来说就是1∗N的向量。
3.2 Lookup Table(查表)
- 上面我们说到了,one-hot是没发计算相似度,我们为了解决计算机无法识别“字符类型”的数据这一问题,又不得不使用这种方式,但是我们要清楚我们这么做是为了解决编码问题,最终的目的我们是想用一个稠密的向量去表示一个单词,并且这个单词是可以在空间中表征准确含义的。
- 比如,“man”和“woman”在空间中就应该是距离比较近的。
- 既然这样,那么我们必须先初始化一个这样的向量,然后通过学习的方式来更新向量的值(权重),然后得到我们最终想要的向量。
- 既然有这样的想法,就必须先将我们上面进行one-hot方式表示的单词,用一个稠密的向量进行表示,也就是进行一个映射。
- 这个映射过程,就被称作是嵌入(embedding),因为是单词的映射,所以被叫做词嵌入(word embedding),好,既然知道了要做这样的embedding,那具体该怎么去做呢?
- 假设我们要把一个单词映射到一个300维(这个300维是经过大量的实验得出的,一般的映射范围是200-500维)的向量中,那么我们直观的做法就是:矩阵运算。因为我们每个单词现在的情况是NNN维的一个向量,如果映射到300维,需要的权重矩阵就是N∗300,这样得到的矩阵就是一个1∗300的矩阵,可以理解为向量。以下图所示(假设N=5)。

- 矩阵的运算大家应该很清楚,后面的结果,在程序中就是通过,对应元素相乘再相加得到的,比如:10=0∗17+0∗23+0∗4+1∗10+0∗11,其他的可以依次得到。但是对于这么小的矩阵,在运算时就进行了5∗3=155*3=155∗3=15次操作,如果我的词汇表中有N=100000个不同的单词,每个词向量的大小为300,那么一个单词的映射就会计算N∗300次,3千万次的计算,可能觉得不算什么,但是我们要清楚,词汇表的大小可不止10万,这样的计算量应该是极其庞大的。
- 细心的同学可能已经观察到了,在上图存在着一个规律:
1、没错了,计算出来的这组向量,和我们单词在one-hot编码表的位置是有关系的!
2、如果单词出现的位置column = 3,那么对应的就会选中权重矩阵的Index = 3,(索引从0开始),知道了这个对于我们 来说意味着什么呢?
3、到现在为止,这个问题应该已经非常清楚了,我们不必计算了,直接通过这种索引位置对应的关系就可以将单词映射到 任意的维度了。
4、上面的通过索引对应的映射方式,就是查表(LookUp Table)了,不需要计算,仅仅是通过查询就可以进行映射了。
- 理解了上面,我们就在用专业的术语描述一下:理解了上面,我们就在用专业的术语描述一下:
1、这种映射关系为单映射, 那么何为单映射呢?简单理解就是:如果集合A→集合B存在映射关系,并且集合A中任意 不同的元素,在集合B中有不同的映射,这样做的目的是,保证每个单词都是独立的,都是不同的。
2、在进行映射之后,信息量不会发生变化。
3、过程就是,将one-hot编码后的词向量,通过一个神经网络的隐藏层,映射到一个低纬度的空间,并且没有任何激活函 数。
- 好,目前为止我们已经走完了两步:one-hot → lookup table。也就完成了我们词向量的初始化,后面要做的事情就是训练。后面有点难度了!!!
3.3 数学原理(参数更新)
- 先看一个图,标明一下我们进行到哪一步了
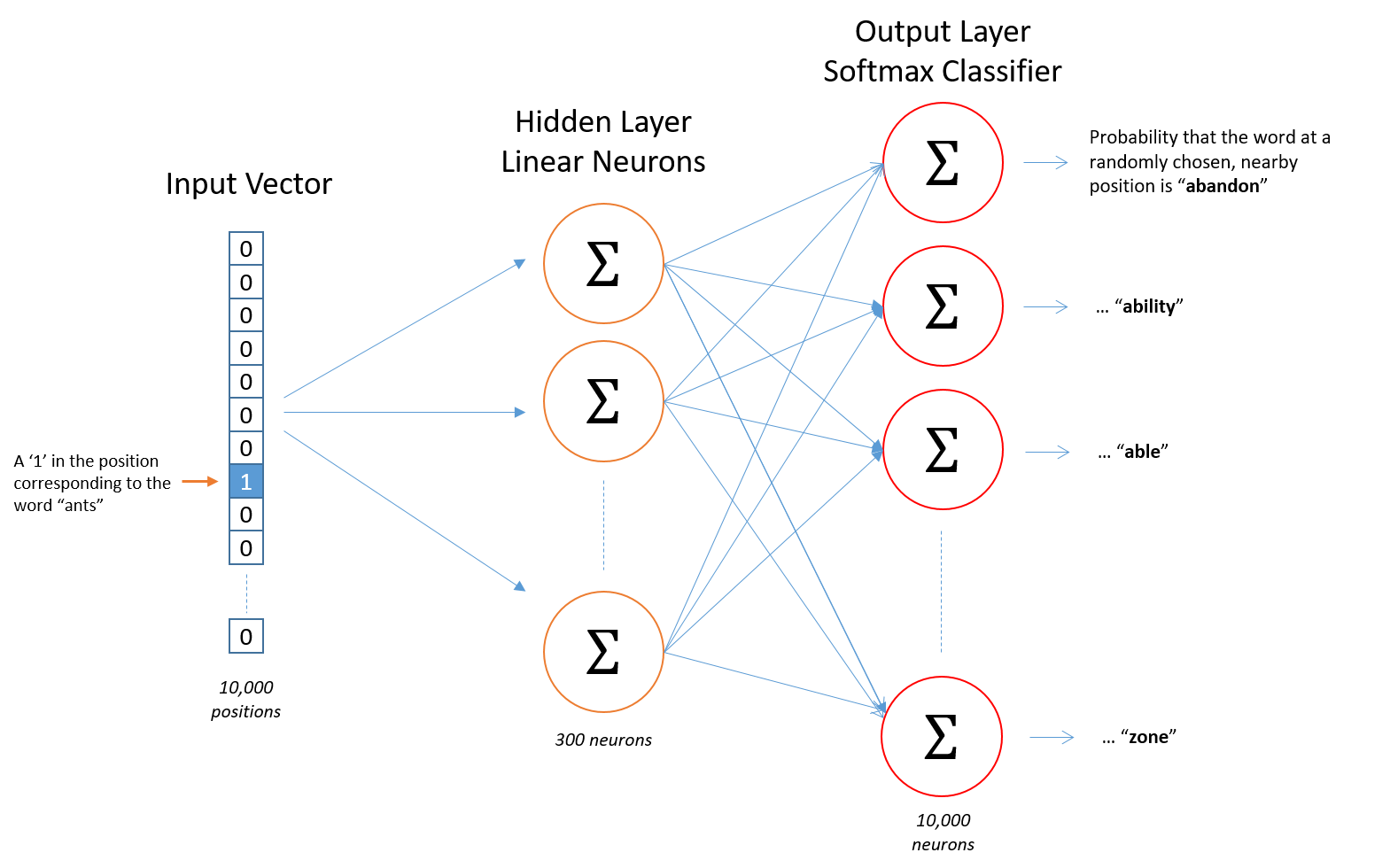
- 大家已经注意到,我们已经到了Hidden Layer到Output Layer这一层了,简单来看就是隐藏层和输出层进行全连接,然后是一个softmax,输出概率。
- 过程比较简单,一个Forward Propagation,一个Backward Propagation。完成参数的更新,为了方便理解,我们还是以一开始的例子说明一下。
- 举个例子
1、假设文本序列是“the”“man”“loves”“his”“son”。
2、以“loves”作为中心词,设背景窗口大小为2。如图所示,跳字模型所关心的是,给定中心词“loves”,生成与它距离不超 过 2个词的背景词“the”“man”“his”“son”的条件概率,即
P(“the",“man",“his",“son"∣“loves").
- 假设给定中心词的情况下,背景词的生成是相互独立的,那么上式可以改写成
P(“the"∣“loves")⋅P(“man"∣“loves")⋅P(“his"∣“loves")⋅P(“son"∣“loves").