布隆过滤器(BLOOM FILTER)、SPV和比特币
了解 布隆过滤器在比特币中的应用
布隆过滤器(Bloom Filter)是什么?
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的,它实际上是由一个很长的二进制向量和一系列随意映射函数组成。
它是一种基于概率的数据结构,主要用来判断某个元素是否在集合内,它具有运行速度快(时间效率),占用内存小的优点(空间效率),但是有一定的误识别率和删除困难的问题。它能够告诉你某个元素一定不在集合内或可能在集合内。
为什么说可能在集合内而无法确定一定在集合内呢?而一定不在集合内为什么又能则可以百分百确定呢?下面我们通过分析布隆过滤器的原理来解释。
为什么需要布隆过滤器(Bloom Filter)?
在软件设计时,我们经常要判断一个元素是否在一个集合中。如:网络爬虫时,一个网址是否已经被访问过、一个邮件地址是否在黑名单中、在文字处理软件中某个英文单词是否拼写正确等。一个直接的方法是,将集合中的所有元素都存储在计算机中(如保存在链表、树、哈希表等数据结构)。当要判断一个新元素的时候,直接跟集合中的已存储元素对比即可判断元素是否在集合中。但是,当随着加入的数据量增加,我们需要存储元素的空间就越来越大,而且检索速度也会开始变慢。链表、树、哈希表的数据结构检索时间复杂度分别为:O(n)、O(logn)、O(n/k)。
举个例子,像 Gmail 这种邮件服务提供商,要过滤垃圾邮件。如果采用上面说的方法,将垃圾邮件加入到哈希表中,那至少要加入数十亿的垃圾邮件地址。没存储一个亿的 email 地址,就需要 1.6GB(将一个 email 地址转换成一个 8 字节的信息指纹并存入到哈希表中。由于哈希表的存储效率一般只有 50%(为什么是 50%,可以看这篇文章),所以实际存储一个 email 地址需要 16 字节,一个亿的 email 地址就大概需要 1.6GB 的内存空间,如果存储几十亿的 email 地址,就可能需要几十上百的内存空间)。
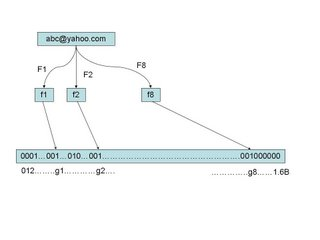
所以传统的存储方法要求要大量的存储空间。而采用布隆过滤器,它只需要哈希表的 1/8 或 1/4 的大小(也就是只需要 200MB 或 400MB 的空间)就可以解决问题。下面我们来看看布隆过滤器是怎么做到的(原理)。
布隆过滤器(Bloom Filter)的原理
布隆过滤器是一个基于 m 位的比特向量(b1,b2…,bm),这些比特向量的初始值为 0。同时还有一系列的哈希函数(h1,h2…,hk),这些哈希函数运算后的哈希值范围在[1, m]内。
如下图,就是 x、y、z 三个元素插入到布隆过滤器中,并判断 w 值是否在集合中的示意图。
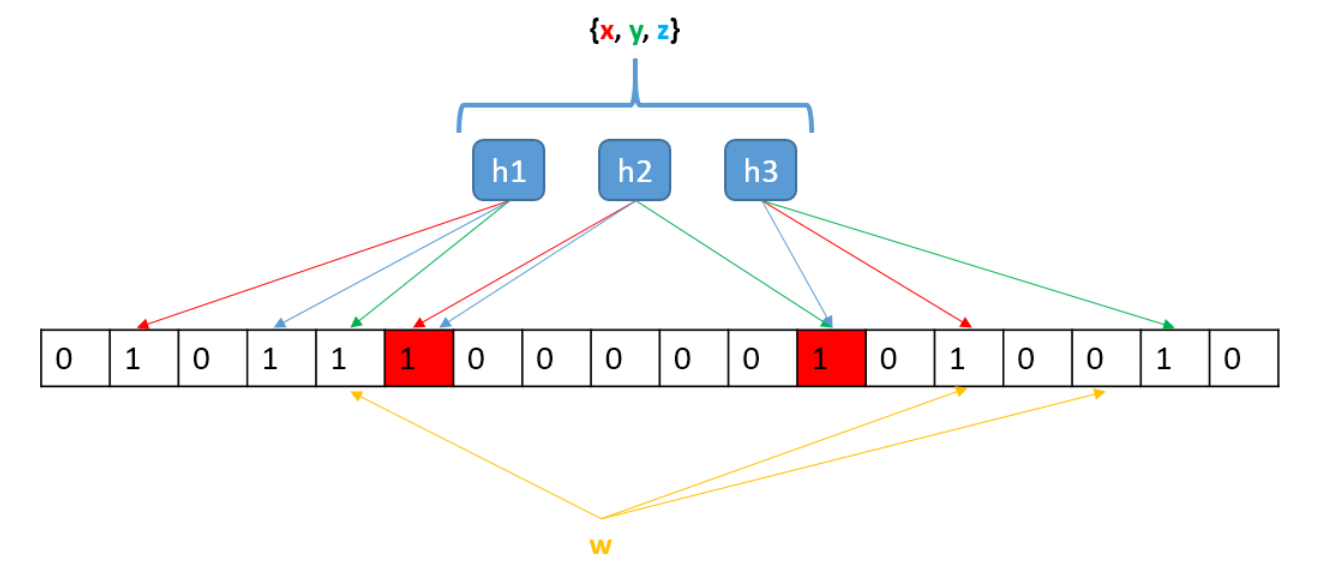
上图中,m=18,k=3,h1、h2 和 h3 是三个哈希函数将输入值分别映射成比特向量上的某个位置上。
插入 x 值(对应红线),则将经过 h1、h2 和 h3 三个哈希函数映射到的比特向量上的值改为 1。
y(对应绿线)和 z(对应蓝线)值也一样操作。
如果要查找 x、y、z,通过布隆过滤器可以找到对应的比特向量都为 1,我们只能确定想 x、y、z 可能在集合中。这里我们我上图中,可以发现,x 和 z 在 h2 哈希函数映射后映射到的是同一个比特向量位置(第 6 个),同时 y 和 z 在经过 h3 映射后也是同一个比特向量位置(第 12 个)。也就是说,当我们通过布隆过滤器判断一个元素是否在集合中时,即使对应的比特向量位置全为 1,也可能是其他元素映射后导致的。如果要查找 w 值,经过哈希映射后,可以发现有一个比特向量上的值不为 1,那就可以判断,w 值一定不在集合中。
** 所以布隆过滤器只能判断一个元素可能在集合中。而且插入的数据越多,误报的概率也越大。**具体关于误报概率的分析可以参考 wiki 文章:Probability of false positive。
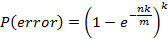
也就是说,误报率跟数据集的容量大小 n、哈希行数个数 k 和总比特数 m 相关。而当布隆过滤器的空间使用率为 50% 的时候,其误报率是最小,具体数学证明我就不展开,可以看看这篇文章的数学分析过程:《布隆过滤器详解》。
布隆过滤器(Bloom Filter)的优点
相比于哈希表、链表等数据结构,其空间和时间的优势明显。而且布隆过滤器的插入、查询时间都是常数 O(k),也就是说每次想要插入或查询一个元素是否在集合中时,只需要使用 k 个哈希函数对元素求值,并将对应的比特位标记或检查对应的比特位即可。
布隆过滤器(Bloom Filter)的缺点
一般情况下,无法从布隆过滤器中删除元素。因为在删除元素之前,我们需要确认一个元素是否在集合中,而我们知道布隆过滤器只能给出可能在集合中或者一定不在集合中的回复,而无法给出是否一定在集合中的回复。
布隆过滤器(Bloom Filter)python 实现
在实际应用中,我们要设计一个布隆过滤器,只需要确定数据集的容量大小 n 和误报率 P 这两个参数。
# -*- coding: utf-8 -*-
from pybloom_live import BloomFilter
# capacity是数据集容量大小(n), error_rate是能容忍的误报率(P)
f = BloomFilter(capacity=1000, error_rate=0.001)
print f.add(‘dog’)
# 当不存在该元素,返回False
print f.add(‘cat’) # 当不存在该元素,返回False
print f.add(‘fish’) # 当不存在该元素,返回False
print f.add(‘pig’) # 当不存在该元素,返回False
print f.add(‘cat’) # 若存在,返回 True
print len(f) # 当前存在的元素个数
输出:
False
False
False
False
True
4
布隆过滤器在比特币中的应用
比特币中布隆过滤器是在 BIP-0037 中提到。下面我们通过“比特币钱包如何知道有多少钱”的问题来介绍布隆过滤器在比特币中的应用。这个问题其实就是“比特币钱包如何知道有多少 UTXO”
备注:UTXO 的概念可以阅读《比特币交易原理分析》。
在 Merkle 树和 SPV 机制文章中,我们提到过比特币网络中主要有两种节点类型:
- 全节点:存放所有区块数据和交易
- SPV 节点:只存放区块头(Block Header)
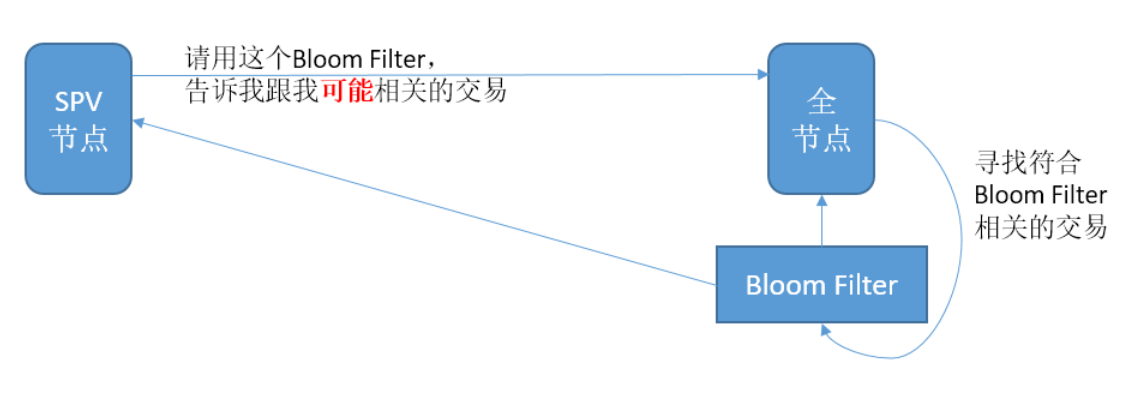
我们假设,比特币钱包最开始值存储了私钥,没有任何其他数据。那么它要获取跟自己地址相关的 UTXO,只能向比特币网络中相邻的全节点询问,询问的方式有 3 中:
方法一:下载完整的区块链账本,自己查找
这种方法很简单,也能隐藏用户的隐私(全节点无法知道 SPV 节点关联的钱包的地址)。但是在手机端是不现实的,每次用户需要下载上百 G 的区块链数据,才能知道自己钱包有多少钱,虽然保护了用户隐私,但是浪费了存储空间和带宽。所以这种方法不行,而这也是为什么有 SPV 的概念存在,中本聪也是考虑到移动支付的场景的。
方法二:直接告诉全节点自己钱包的所有地址,全节点返回所有跟钱包地址相关的 UTXO
这种方法直接等于是泄露了用户隐私,其他全节点就知道 SPV 节点所关联的钱包地址。但是好处是所要下载的数据少了很多,也更精确了。
方法三:告诉全节点部分自己钱包的地址信息,全节点返回可能相关的 UTXO
这种方法实际上就是采用布隆过滤器的方法隐藏用户隐私,从而做到即保护用户隐私,又节省存储空间和带宽。在前面的章节,我们知道布隆过滤器的两个特点:只能告诉你某个元素可能存在集合中以及某个元素一定不存在集合中。这里可以简单理解 Bloom Filter 就是一个过滤器,用来过滤不属于钱包的 UTXO。
钱包节点(SPV 节点)会以布隆过滤器的形式告诉相邻全节点自己地址信息,那么根据布隆过滤器的特性,会有两种结果:
- 没有通过布隆过滤器过滤出来的 UTXO,就【一定】不属于钱包地址
- 通过布隆过滤器过滤出来的 UTXO,【可能】属于钱包地址
这种方法虽然在一定程度上保护用户隐私,节省了存储空间和带宽,但是根据布隆过滤器的特点,我们知道,随着钱包交易的 UTXO 越多,布隆过滤器误报率会越高,也就是相邻全节点返回正确的 UTXO 概率越低。