递归神经网络
在传统神经网络中,模型不会关注上一时刻的处理会有什么信息可以用于下一时刻,每一次都只会关注当前时刻的处理.举个例子,我们想对一部影片中每一刻出现的事件进行分类.如果我们知道视频前面的时间序列信息,那么对于当前时刻观看量的预测就会非常简单.实际上,传统神经网络没有记忆功能,所以它对每一刻出现的时间进行预测不会用到之前已经出现的信息.那么有什么办法可以让神经网络能够记住这些信息呢?
递归神经网络就是把以前的信息传播下去的.(有记忆功能的神经网络)
递归神经网络的结果与传统神经网络有一些不同,它带有一个指向自身的环,用来表示传递当前时刻处理的信息给下一时刻使用.
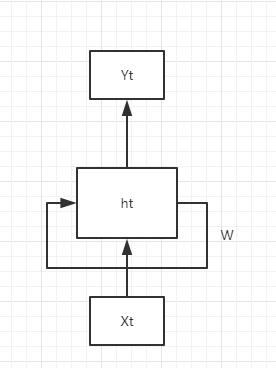
其中ht为隐藏变量,W是权重,Yt为输出.

其中X表示输入,W为各类权重,y表示输出,h表示隐藏层状态.上图可以认为它是对相同神经网络的多重复制,每一时刻的神经网络会传递信息给下一时刻.
长时依赖问题
长时依赖是这样的一个问题.当预测点与依赖的相关信息距离比较远的时候,就难以学到该相关信息.例如对于视频预测第几十分钟的预测和几千分钟后的预测关系.理论上,递归神经网络是可以处理这样的问题,但是实际上,常规的递归神经网络不能很好地解决长时依赖。而LSTM就是为了解决这样的问题.
LSTM神经网络
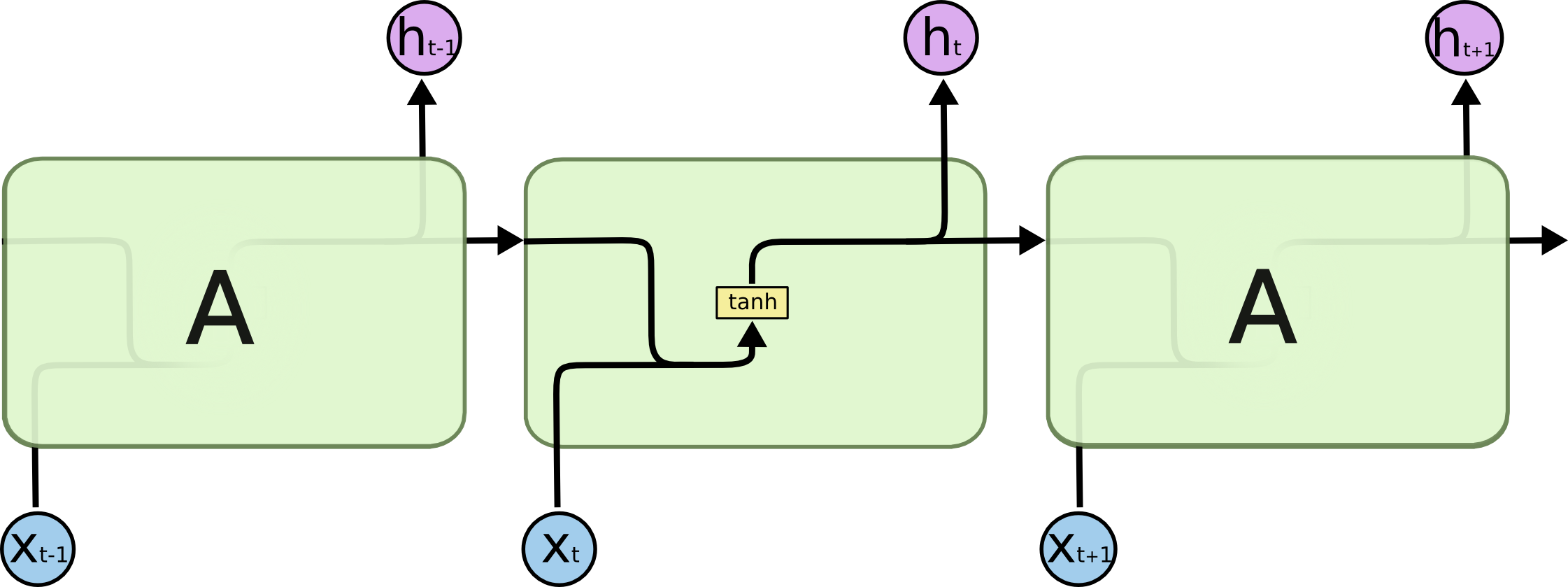
RNNs具体的结构,所有的递归神经网络是由重复神经网络模块构成一条链,它的处理层非常简单,通常是一个单tanh层。通过当前输入及上一时刻的输出状态得到当前输出.与神经网络相比,它可以利用上一时刻学习到的信息进行当前时刻的学习.
LSTM的结构与上面相似,不同的是它的重复模块比较复杂,它有四层结构:

LSTM的核心思想
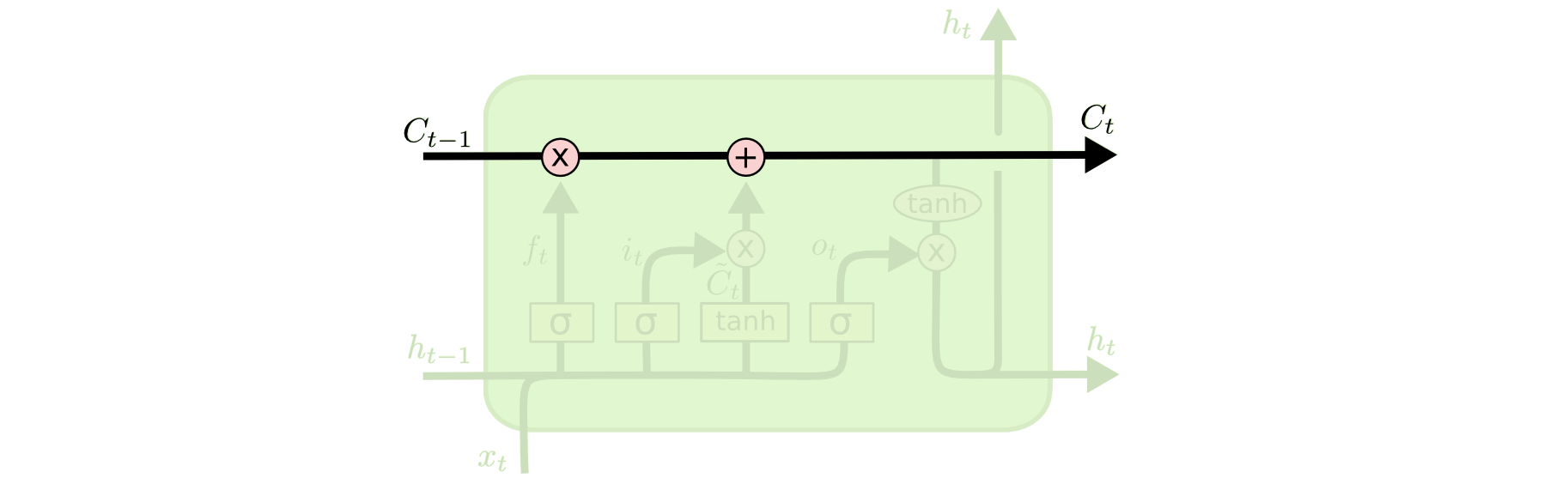
LSTM的整个层是记忆块,主要包含了三个门与一个记忆单元.上图的线称为单元状态C0,它就像一个传送带,可以控制信息传递给下一时刻.
逐步解析LSTM
遗忘门
LSTM第一步决定什么信息可以通过细胞状态.这个决定由遗忘门通过sigmoid函数来控制,它会让上一时刻的隐藏变量通过.
该层的输出是一个介于(0,1).

遗忘门输出公式:
ft=sigmoid(Wf*[h(t-1),xt]+bf),ft∈[0,1]
物理含义:这个决定由遗忘门通过sigmoid控制,它会根据上一时刻的输出h(t-1)和当前输入Xt来决定产生一个0到1的ft值.目的是决定是否让上一时刻学到的信息C(t-1)通过多少.
输入门
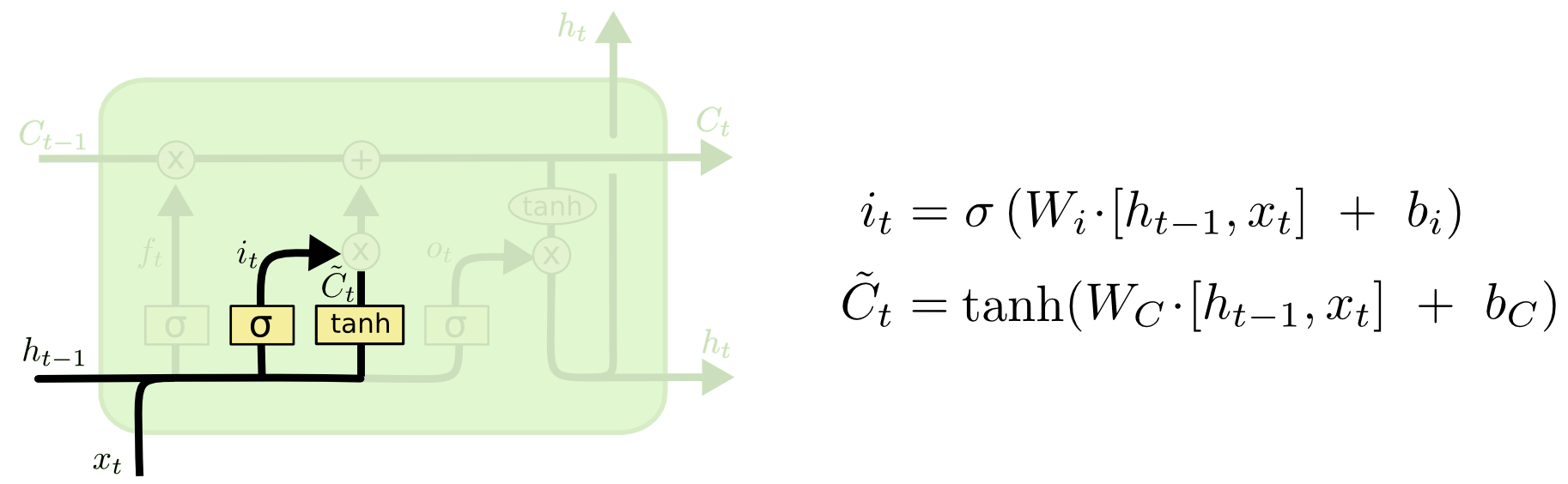
第二步是产生我们想要更新的信息.这一步包含两部分.
第一个是输入门通过sigmoid决定哪些值用来更新(注意对象是h(t-1),xt).it∈[0,1].
第二个是用tanh函数生成新的候选值C`t,作为当前输入门产生的候选值会添加到细胞状态Ct(时间序列).
把这两部分产生的值结合起来更新.
更新好的Ct有两部分,我们将老的细胞状态乘以ft忘掉不需要的信息,使用候选细胞乘以it更新需要更新的新,再把两者加起来,得到新的细胞状态.如下图所示.
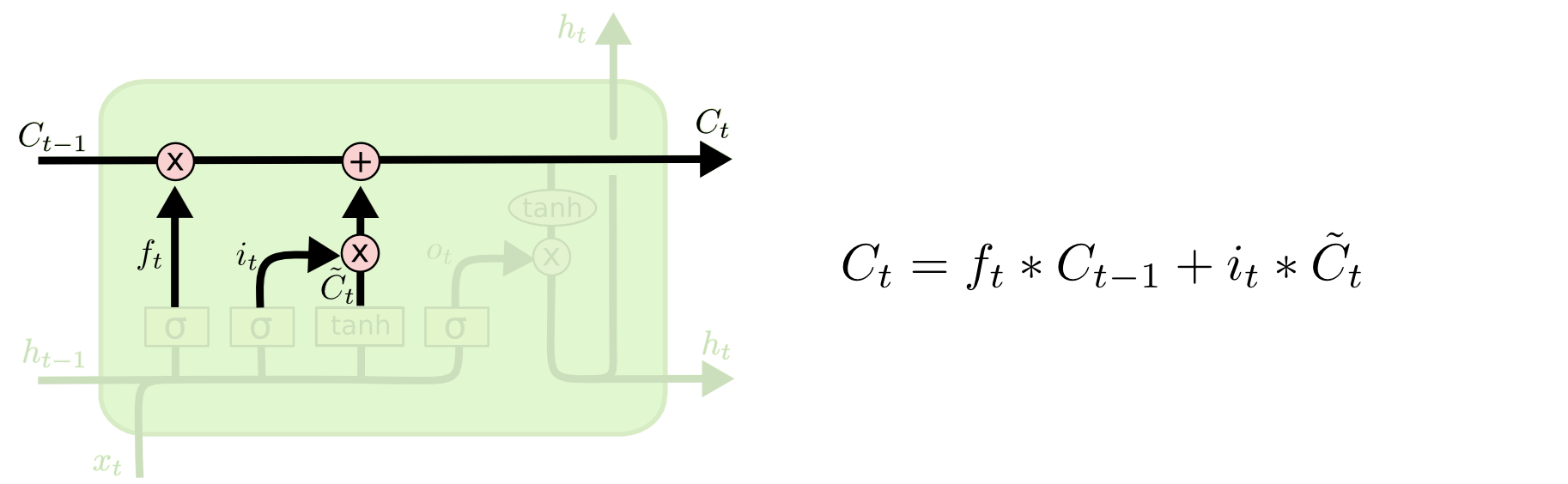
输出门
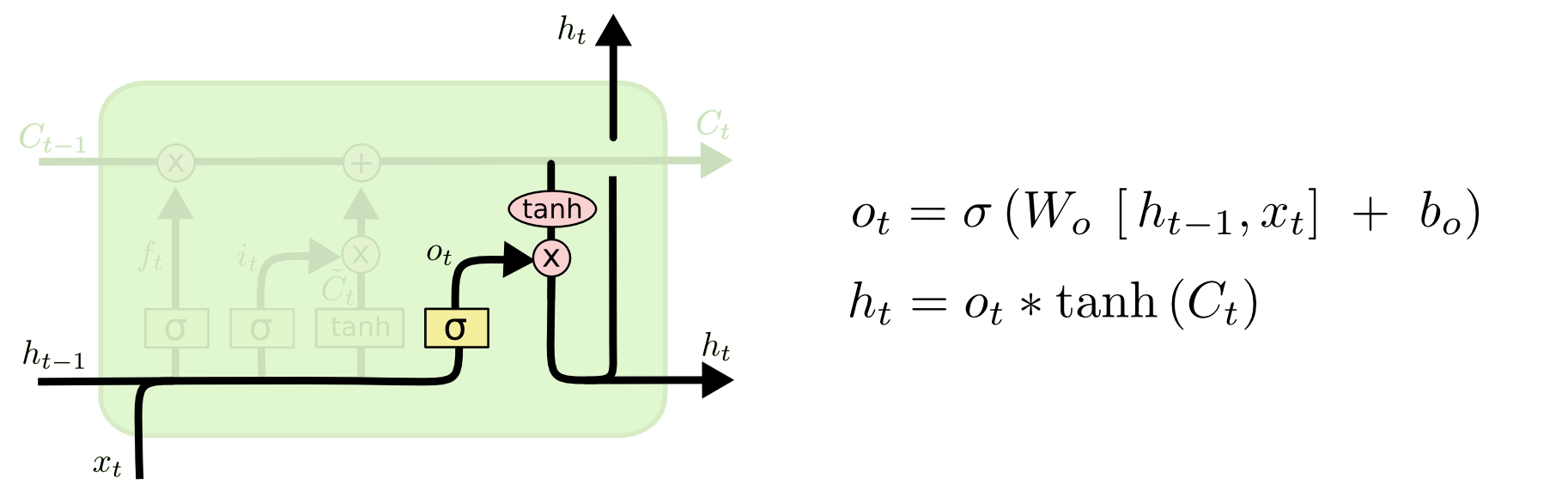
第三步是决定模型的输出.
首先h(t-1),Xt通过sigmoid函数得到一个初始输出Ot.(h(t-1)是上一时刻的输出,Xt是本次的输入.h(t-1)与Xt理想化是一样的.实际上存在误差.).
输出:使用tanh将Ct值缩放到(-1,1)状态.再与s初始输出Ot相乘得到模型输出ht.
这可以理解,首先sigmoid函数的输出是不考虑先前时刻学习到的信息,tanh函数是对先前学到的信息Ct压缩处理,起到稳定数值的作用.
两者的结合学习就是RNN的学习思考.至于模型是如何学习的,这就是后向传播误差学习权重的过程.
上面是对LSTM的典型结构的理解,一般下,它会有一些结构上的变形,但是基本思想不变.