1 量纲与无量纲
1.1 量纲
量纲我觉得最重要的一句话是:物理量的大小与单位有关。
从这句话我们来思考下最核心的两个单词:大小、单位。就是说量纲是有两部分组成:数、单位。就比如1块钱和1分钱,就是两个不同的量纲,因为度量的单位不同了。
1.2 无量纲
结合上面的内容来说,那么无量纲就是:物理量大小与单位无关。
那么我们来考虑下,哪些内容是无量纲的。首先标量肯定是无量纲的,因为只有大小,没有单位。其次就是比值,因为一般来说比值都是由一个量纲除以了某个量纲后得到的,比如速度可以有“k m / s km/skm/s”,“m / s m/sm/s”等等。还有一个很显眼的无量纲,就是协方差的相关系数,因为协方差的相关系数是协方差归一化后得到的结果,可以用来衡量相关性,既然能够直接拿来衡量相关性,那么就是无量纲的。
2 标准化
标准化(standardization)是一种特征缩放(feature scale)的方法,在书《python machine learning》中,关于标准化的定义如下:

用我粗糙的英语翻译一下就是:
梯度下降是受益于特征缩放的算法之一。有一种特征缩放的方法叫标准化,标准化使得数据呈现正态分布,能够帮助梯度下降中学习进度收敛的更快。标准化移动特征的均值(期望),使得特征均值(期望)为0,每个特征的标准差为1。
标准化公式如下:
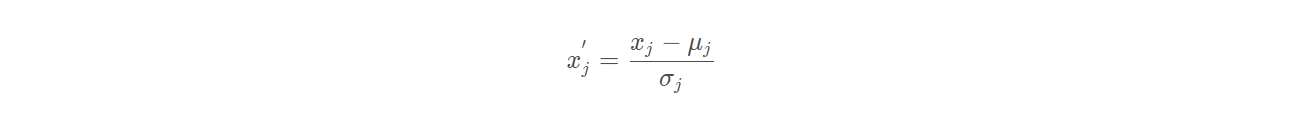



我们先翻译解释,再解释图片:

3 归一化
归一化(normalization)和标准化(standardization)区别不是很大,都是特征缩放(feature scale)的方式。
有的资料中说的,归一化是把数据压缩到[ 0 , 1 ] [0,1][0,1],把量纲转为无量纲的过程,方便计算、比较等。
在书本《python machine learning》中对归一化的定义为:

翻译如下:



4 正则化
正则化(regularization)是与标准化还有归一化完全不同的东西。正则化相当于是个惩罚项,用于惩罚那些训练的太好的特征。
在书《python machine learning》中,对于正则化的描述如下:

我们来翻译一下:
正则化就是用来处理collinearity的,这个collinearity指的是与特征高度相关,清理掉数据的噪声,最终阻止过拟合。而正则化实际上就是引入一个额外的信息(偏置)来惩罚极端的参数(权重)值。
我们借用吴恩达老师的PPT来说:

我们看到图三这个曲线非线性拟合的太完美了,那么就造成了过拟合,造成的原因是因为特征过多,训练的太好了,而这个特征过多,我个人认为就对应了上面英文中的collinearity (high correlation among features)。

减少特征个数(特征约减):
- 手工保留部分特征(你觉得你能做到么?反正我觉得我做不到)
- 模型选择算法(PCA,SVD,卡方分布) 正则化:保留所有特征,惩罚系数θ ,使之接近于0,系数小,贡献就小。
所以也就对应了书本上的惩罚极端参数值。

5 总结
- 量纲与无量纲的区别就是:物理量是否与单位有关。
- 标准化与归一化没有显著的区别,具体是谁要依据上下文确定。
- 归一化是把特征缩放到[ 0 , 1 ] [0,1][0,1],标准化是把特征缩放到均值为0,标准差为1。
- 正则化是与标准化和归一化完全不同的东西,是用于惩罚训练的太好的参数,防止模型过拟合,提高模型的泛化能力。
补充:
对于标准化和归一化,消除的是某列(特征)的量纲差异,方便模型训练。并不是对于不同列(特征)间的差异 —— 特征的权重分配问题。
参考:https://blog.csdn.net/qq_35357274/article/details/109371492