一、前言
前几天参考CV Zone - Computer Vision Zone的课程做了一个基于opencv的手势识别项目,使用的是已经训练好的模型,缺少一些乐趣。故决定自己搭建一个深度学习环境,用yolov5训练自己的数据集,实现一些简单的目标检测。 
二、开发环境搭建
1.本机配置


可以看到CPU是AMD Ryzen9 4900H ,显卡是RTX2060,最高支持的CUDA版本是11.4
2.安装Anaconda
Anaconda是一个开源的python发行版,带有很多python包,而且方便管理,用它来配置开发环境很方便。用Anaconda配置pytorch环境时它会自动帮我们安装好cuda和cudnn,免去NVIDIA官网下载cuda安装程序和cudnn压缩包的麻烦
我们可以在anaconda的官网下载最新的Anaconda版本并安装。Anaconda | The World's Most Popular Data Science Platform
3.安装pytorch环境
打开Anaconda Prompt,创建环境。
conda create -n pytorch python=3.8激活环境
conda activate pytorch安装pytorch
由于anaconda默认的源在国外,安装过程中可能会遇到麻烦,我们将源换为国内源。具体参考anaconda | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
进入pytorch官网,PyTorch

复制上图这段命令,在anaconda prompt执行,等待安装完成。
4.安装IDE
pycharm是一款非常好用的IDE,专为python打造。jetbrains提供了免费的社区版。
选择刚才安装好的环境。

新建一个python文件并执行,可以验证cuda和cudnn已经安装完成,显示出了安装版本信息。
import torch
print(torch.cuda_version)
print(torch.backends.cudnn.version())三、建立数据集
labelimg是一款数据集标注工具,可以将标注的数据保存成不同格式。通过cmd执行命令来安装
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple然后在项目的目录里创建这样的文件结构
imgs里保存要标注的图片,labels里存放标注好的文件,class.txt里写入系列名称。这里我只建立了一个系列fire。可以根据需要创建多个。

cmd进入dataset目录,执行命令开始标注
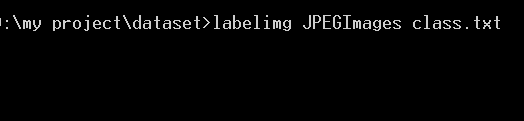

ctrl+u打开图片所在的imgs目录,ctrl+r选择数据保存的目录,w开启框选工具,a和d选择上一张和下一张,可以在view里面打开自动保存等功能。 由于下一步要使用yolov5进行训练和预测,这里将保存的格式设置成了yolo。
标注完成后将imgs和labels按自己喜欢的比例分配到train和val里就可以了,分别是训练模型时要用到的训练集和验证集,目录结构如下。

四、训练模型
1.源码克隆
在github克隆yolov5的源码https://github.com/ultralytics/yolov5/tree/v5.0,放到自己项目的文件夹里。
完成后的目录:

2.安装所需的环境
所需的环境全部写在requirements.txt里面,可以通过pycharm里的terminal执行命令来安装。
pip install -r requirements.txt本人在安装pycocotools时遇到了一些问题,参考这篇博客得到了解决。
3.获得预训练权重
在这个网址下载预训练权重,放到weights文件夹下。
https://github.com/ultralytics/yolov5/releases
4.修改yaml文件

修改data下的voc.yaml这里将文件的第10行注释掉,在第13,14行填入train和val的目录地址,17行后面填入要识别的系列数,20行为系列名。这里只有一个系列fire,故系列数为1。

修改models下的yolov5s.yaml文件,同样,更改第2行为自己要实现的系列数,本人改成了1。
5.开始训练
更改train.py里面的一些参数。

在此处分别填入预训练权重和刚刚更改的yaml文件路径。

训练的轮数,默认为300,根据需要进行修改


喂入批次文件的多少和最大工作核心数,根据自己设备的配置自行修改即可。
然后运行train.py,训练开始。

如果在训练时IDE报错,请参考目标检测---教你利用yolov5训练自己的目标检测模型_didiaopao的博客-CSDN博客
训练过程中,我们可以用tensorboard来查看训练情况。在terminal中输入。
tensorboard --logdir=runs/train或者在训练完后输入
tensorboard --logdir=runs 
本人标注了近2000组数据,从凌晨1点训练到早上9点,训练了650轮,可以看到拟合精度总体呈上升趋势。期间GPU负荷控制在50%左右,风扇声音比较吵。
训练完成后,项目目录下会生成一个runs\train\exp文件夹,其中weights下保存有最好的一个权重和最后一次的权重。还有其自动生成的数据信息。




五、用训练的模型进行推理
打开detect.py传入训练好的权重。
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp/weights/best.pt', help='model.pt path(s)')这里使用了训练好的那个最好的权重。
设置要处理的图片或视频的路径。
parser.add_argument('--source', type=str, default='C:/Users/Porridge/Desktop/66.mp4', help='source') 图片或视频均可,这里我选择了桌面上的一个视频。
运行detect.py

运行完毕后,生成的图片或视频会保存在runs/detect/exp下

可以看到,在进行几百轮的训练之后,模型已经可以做出比较正确的推理。