
摘要
我们提出了一种基于学习的通用解决方案,用于恢复遭受空间变化的退化图像。先前的方法通常是特定于退化的,并且在不同的图像和图像中的不同像素上采用相同的处理。然而,我们假设这样的空间刚性处理对于同时恢复退化像素以及重建图像的干净区域而言是次优的。为了克服这一局限性,我们提出了SPAIR,这是一种网络设计,它包含退化定位信息,并根据图像中的困难区域动态调整计算。
SPAIR由两个部分组成,(1)一个用于识别退化像素的定位网络,以及(2)一个恢复网络,该网络利用来自filter和特征域中的定位网络的知识来选择性和自适应地恢复退化像素。我们的关键思想是利用空间域中严重退化的不均匀性,并将这些知识适当地嵌入到执行稀疏归一化、特征提取和注意的失真引导模块中。我们的方法是和物理模型无关的,我们概括了几种空间变化的退化类型。我们分别展示了SPAIR在四项恢复任务中的有效性——去除雨条纹、雨滴、阴影和运动模糊。在11个基准数据集上与现有技术进行了广泛的定性和定量比较,结果表明,与最先进的特定于退化的体系结构相比,我们的退化不可知网络设计提供了显著的性能增益。
方法
 如图1所示,分别是雨滴、雨纹、阴影、模糊,虽然形成原因不同,但是都有一个本质特征,就是空间变化。例如,雨滴和阴影根据其大小和位置降低图像的整体部分,运动模糊随场景深度和运动程度而变化,雨条纹仅影响方向取决于相对雨方向的稀疏区域。图1示出了退化图像和相应失真图的代表性示例。可以看出,大量像素很少或没有变形。另一个观察结果是,每个图像中的失真量及其空间分布是不同的。
如图1所示,分别是雨滴、雨纹、阴影、模糊,虽然形成原因不同,但是都有一个本质特征,就是空间变化。例如,雨滴和阴影根据其大小和位置降低图像的整体部分,运动模糊随场景深度和运动程度而变化,雨条纹仅影响方向取决于相对雨方向的稀疏区域。图1示出了退化图像和相应失真图的代表性示例。可以看出,大量像素很少或没有变形。另一个观察结果是,每个图像中的失真量及其空间分布是不同的。
现有方法有几个关键限制。
- 网络中的所有层都是通用的CNN层,对每幅退化图像应用相同的空间不变的filter。这类方法逆转高度依赖图像且空间变化的退化的能力有限。
- 大多数网络体系结构都是专门针对个别退化类型定制的,因为它们基于图像形成模型。
- 嵌入在标记数据集中的失真标记信息在所有现有解决方案中都未被使用或次优使用。
现有方法在遇到输入是没受退化与严重退化交织的区域的时候,表现的很差。基于恢复网络可以从适应每个测试图像中存在的退化中获益的理解,我们提出了一个失真感知模型,以同时实现恢复和重建的双重目标。我们的空间自适应图像恢复体系结构(称为SPAIR)适用于选择性影响图像部分的任何类型的退化。
网络框架

一个图像恢复模型需要同时解决两个问题:(1)确定图像中要恢复的区域的位置,(2)将正确的filter应用于相应的区域。而 N e t L Net_L NetL则为前者,我们通过空间引导修复来实现后者 N e t R Net_R NetR
SPAIR的示意图如图2所示。来自预训练的 N e t L Net_L NetL的中间特征的知识提高了网络 N e t R Net_R NetR的训练,而mask为恢复过程提供了自适应能力。为了实现恢复和重建的双重目标, N e t R Net_R NetR中提取的特征通过SFM(Spatial Feature Modulator)、SC(Sparse Convolution)和SNL(Sparse Non Local)模块进行失真引导滤波。
Distortion Localization Network ( N e t L ) (Net_L) (NetL)
为了最大限度地推广我们的方法,我们采用U-Net拓扑[48]作为我们的CNN主干(用于定位和恢复网络)。已知这种方法的不同版本对几种恢复任务有效,如图像去模糊、去噪和图像到图像的转换。我们构建了一个密集连接的编解码结构。这种设计在所有考虑的任务中都提供了较好的性能,因此可以作为我们的 N e t R Net_R NetR的主干, N e t L Net_L NetL是 N e t R Net_R NetR的轻量级版本(具有类似的结构),因为二元分类(定位)任务比回归(恢复)任务简单。
给定一个退化图像, N e t L Net_L NetL生成一个通道mask,并使用二元交叉熵损失对其进行训练。对于没有 mask的数据集,我们用退化图像和GT图像的差的绝对值,并对其进行阈值设置以获得mask,将像素分类为退化(值1)或干净(值0)。根据实验,我们观察到 N e t L Net_L NetL被训练为仅预测严重失真的像素时(而不是检测微小的强度变化), N e t R Net_R NetR的性能得到提升。
失真map直接影响了恢复的难度,它可能不同于物理上发生的退化分布。例如,当物理雨点均匀分布在整个图像中时,失真map在城市纹理区域中包含的非零值将多于天空区域(因为白色雨条纹不会显著改变天空中的亮度)。
Spatially-Guided Restoration Network ( N e t R ) (Net_R) (NetR)
N e t R Net_R NetR使用密集连接层从输入的退化图像中提取特征金字塔。这些特征被提供给生成恢复图像的解码器。虽然可以通过简单的卷积层来学习小强度变化的校正,但它们在空间分布的严重退化中起着作用。对于这些区域,基于定位指导可以提高恢复质量。我们提出了3个模块来使用经过培训的 N e t L Net_L NetL将定位知识传递给 N e t R Net_R NetR。
由于图像生成过程需要解码器学习重建和恢复,所以每一级的解码器都包含一个SC和一个SNL模块。请注意,我们避免在 N e t R Net_R NetR的编码器层中使用SC或SNL,因为这将完全丢弃退化的图像强度(其中包含部分有用的信息)。我们在多个层次上使用SFM来执行失真引导的特征规范化,以补充SC和SNL模块。
Spatial Feature Modulator (SFM)
SFM以相加的方式将 N e t R Net_R NetR的特征与预训练 N e t L Net_L NetL层的中间特征融合在一起。我们观察到,在这种特征指导下,早期的 N e t R Net_R NetR层提取出更多的失真感知特征,这些特征与输入图像中的退化变化密切相关。研究表明,特征均值与全局语义信息相关,方差与局部纹理相关。受此启发,我们的SFM调整退化位置的特征,以匹配清洁区域的特征统计(均值和方差)。
 公式1可以这样理解,和图像风格转换里面的adain类似。首先要被转换的特征经过自身的归一化,然后再经过一个风格的均值和方差的仿射变换,分布发生改变。对应在本文中,归一化就是公式1中最大的括号里的内容。当然了,其先对F的M部分进行归一化,因为M代表的是退化,(1-M)代表的是干净。归一化之后再用(1-M)的部分进行分布的变更。简单一句话,依据预测的退化mask,将图像分成退化和非退化两个分布,然后做仿射变换是为了将退化的分布拉到非退化的分布上来。
公式1可以这样理解,和图像风格转换里面的adain类似。首先要被转换的特征经过自身的归一化,然后再经过一个风格的均值和方差的仿射变换,分布发生改变。对应在本文中,归一化就是公式1中最大的括号里的内容。当然了,其先对F的M部分进行归一化,因为M代表的是退化,(1-M)代表的是干净。归一化之后再用(1-M)的部分进行分布的变更。简单一句话,依据预测的退化mask,将图像分成退化和非退化两个分布,然后做仿射变换是为了将退化的分布拉到非退化的分布上来。
Mask-guided Sparse Convolution (SC)
SC是dense结构,包括6 guided sparse convolution layers followed by a 1×1 convolution。

mask卷积如式子2,当前位置的mask如果是1,则进行正常的卷积,如果为0,直接结果就是0.
虽然SC对于手头的空间变化任务非常有效,其感受野仅限于退化像素。接下来,我们将描述我们的SNL模块,该模块使用全局上下文聚合(带有失真指导)提取特征,并补充SC的作用。
Region-Guided Sparse Non-Local Module (SNL)

我们假设,在恢复模型中,非局部上下文聚合过程可以从退化像素位置的知识中获益匪浅。我们直觉地认为,在整个空间域传播严重退化的信息可能适得其反。理想情况下,自适应模块应学会完全忽略不相关的特征,但最近的视觉模型表明,这种行为实际上并未实现。他们执行额外的过滤来重新去除不必要的信息。
相比之下,所提出的SNL模块利用失真mask来控制non local上下文聚合的范围。在恢复退化像素的同时,它将动态估计的非零权重分配给仅来自未退化/退化程度较低像素位置的特征,从而在抑制严重降级/损坏信息的影响时提供优异的性能。此外,SNL保持干净区域的特征不变,因为此操作仅在退化像素位置上形成。
SNL包含两个阶段的集成。在每一步中,在四个固定方向上压缩特征矩阵的水平-垂直扫描:从左到右,从上到下,反之亦然。


以水平方向为例,首先确保M=0的位置i,j的像素会和其右边所有的像素点计算一个相似性,也就是式子3. 然后这些相似性和其右边的像素相加权得到一个方向的结果。
最后用一个稀疏conv_1*1卷积进行融合特征。
实验
实验在4个任务上做的,但是其实是分别训练的。
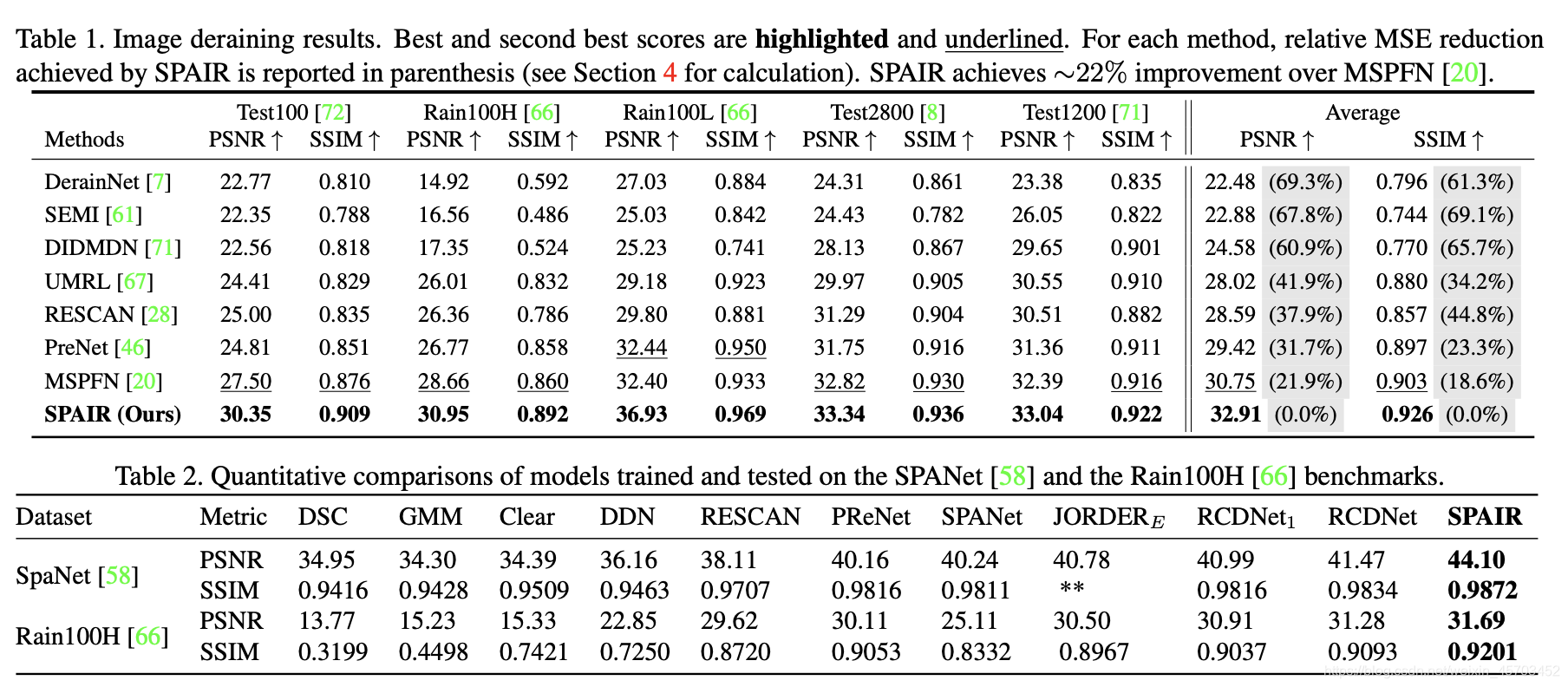
 以上是去雨纹的结果。
以上是去雨纹的结果。


以上是去雨滴的结果。

 以上是去阴影的结果。
以上是去阴影的结果。

 以上是去模糊的结果。
以上是去模糊的结果。
消融实验

Net1: Dense encoder-decoder network (CNN backbone of our N e t R Net_R NetR) with few additional parameters to match N e t L Net_L NetL.
Net2: Net1 guided by N e t L Net_L NetL using SFM.
Net3: Net2 with all densely connected convolutional blocks in decoder replaced with SC modules
Net4: Net3 with non-local (NL) layer introduced in the decoder.
Net5: Net4 containing the proposed SNL module instead of NL.
Good baseline scores of Net1 for both tasks support our backbone design choice.
亮点在于他们的SNL有效果。