
摘要

快速、任意的风格转换引起了学术界、工业界和艺术界的广泛关注,因为它支持各种应用的灵活性。现有的解决方案要么专注于不考虑特征分布地将风格特征融入到深层内容特征,或根据风格特征自适应地规范化深层内容特征使得他们的全局统计量是匹配的。虽然有效,但留下的浅层特征没经过探索,且不考虑局部特征统计量,这样容易产生不自然的的局部扭曲。为了缓解这个问题,在本文中,我们提出了一个新的注意和规范化模块,名为自适应注意规范化(AdaAttN),以自适应的方式在每个点的上进行标准化。具体来说,spatial attention score是从内容和风格图像的浅层和深层特征学习的。然后计算逐点加权统计量,通过将一个风格特征点作为所有样式特征点的注意力加权输出的分布。最后的内容特征进行了规范化,它们显示与计算的逐点加权风格特征统计相同的局部特征统计信息。此外,为了提高局部视觉质量,基于AdaAttN提出了一种新的局部特征loss。我们还对AdaAttN进行了扩展,以便在稍作修改的情况下进行视频样式转换。实验证明我们的方法实现了SOTA的任意图像/视频风格转换。
方法
AdaIN将一个风格图像的全局均值和方差迁移到内容图像,但是局部细节和逐点模式在很大程度上被忽略,因此局部风格化性能在很大程度上被降低。为了增强任意风格转换模型的局部意识,最近一些方法采用了注意机制来完成这项任务。他们的共同直觉是,模型应该更多地关注风格图像中的相似区域,以便对内容图像区域进行风格化。这种注意机制已被证明能有效地在任意样式转换中生成更多的局部样式细节。不幸的是,在改进性能的同时,它未能完全解决这一问题,局部失真仍然存在。
原因在于当前针对任意风格转换的基于注意的解决方案的细节上,可以很容易地发现:
1)设计的注意机制通常基于更抽象级别上的深层CNN特征,而忽略了浅层的细节;
2) 注意力score通常用于重新加权风格图像的特征映射,重新加权的风格特征简单地融合到内容特征中进行解码。基于深度CNN特征的注意力使得浅层网络层的低层图像模式未被探索。因此,注意力得分可能集中在受高层次语义的支配低层次的纹理上。同时,如SANet(图3b),风格特征的空间重新加权,然后再融合重新加权的风格特征和内容特征,其工作原理不考虑特征分布。
我们试图解决这些问题,并在风格转换和内容结构保持之间取得更好的平衡。提出了Adaptive Attention Normalization (AdaAttN)。
Overall Framework

在我们提出的模型中,我们使用预训练的VGG-19网络作为编码器来提取多尺度feature map。解码器是参考另一篇论文设计了一个VGG-19的对称形式。为了充分利用浅层和深层的特征,我们采用了一种多级策略,分别在VGG的 R e L U _ 3 _ 1 ReLU\_3\_1 ReLU_3_1、 R e L U _ 4 _ 1 ReLU\_4\_1 ReLU_4_1和 R e L U _ 5 _ 1 ReLU\_5\_1 ReLU_5_1层上集成三个AdaAttN模块,如图2所示.

为了充分利用浅层特征,我们进一步将当前层的特征与其先前层的下采样后的特征连接起来:
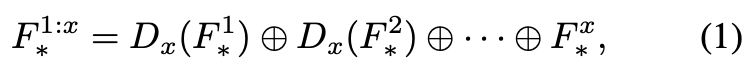

这里的D代表的是bilinear插值。 ⊕ \oplus ⊕代表的是cat。然后这些特征被送入到AdaAttN中。
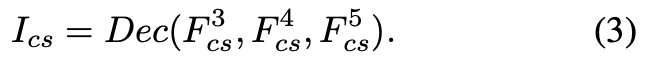
最后经过解码。
Adaptive Attention Normalization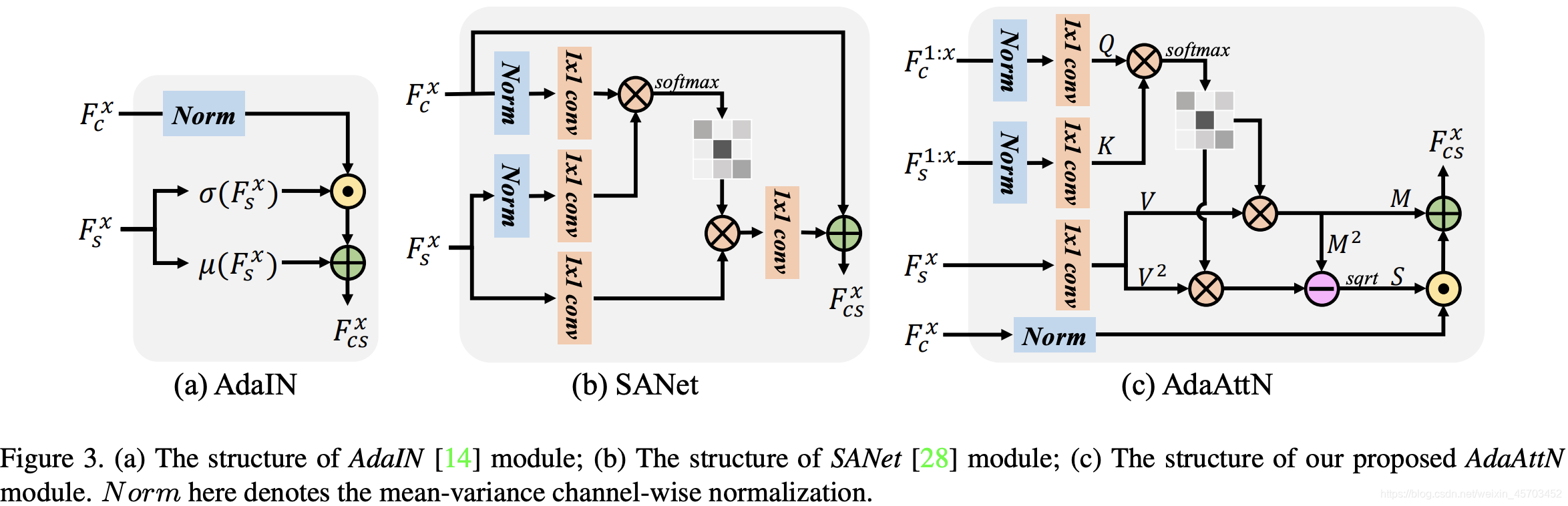
先和其他方法进行了对比,AdaIN考虑整体风格分布,并对内容特征进行操作,使其特征分布与样式风格的特征分布全局对齐,没考虑局部风格特征,SANet 展现了局部风格化,但是缺乏low-level匹配和局部分布的对齐。这二者给的启发,引入本文的方法。
- computing attention map with content and style features from shallow to deep layers;
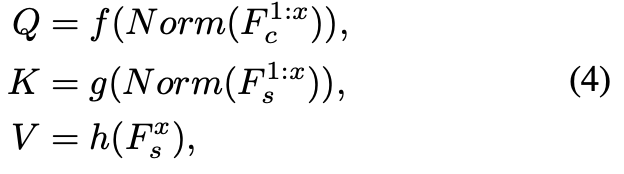

Q和K经过Instance Norm和conv_1*1之后,计算一个点和点的关系注意力A。 - calculating weighted mean and standard variance maps of style feature;
正如SANet所做的那样,将注意力得分矩阵A与风格特征 F s x F_s^x Fsx关联,可以被视为通过将所有风格特征点的加权和来计算每个目标风格的特征点。(这里做个解释,A无非就是内容和风格图像点与点的关系( H W ∗ H W HW*HW HW∗HW),得到的A每一行代表的是内容图像每个点和风格图像所有点的关系,这一行再去和V(V也是风格的特征 H W ∗ C HW*C HW∗C)的一列相乘,相当于是内容图像的一个像素点去聚合全局的风格信息)
在论文里,将此过程解释为将目标风格特征点的注意输出视为所有风格特征点加权的分布。因此进行了attention-weighted mean and attention-weighted standard variance:

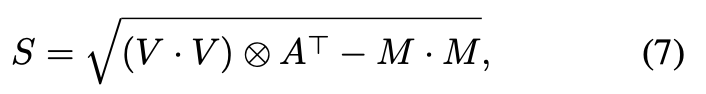
⋅ \cdot ⋅代表的是元素级的相乘。 - adaptively normalizing content feature for per-point feature distribution alignment.

loss
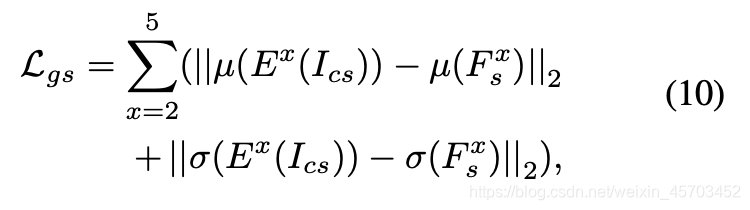
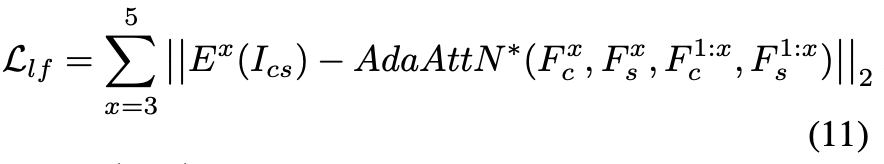
损失函数上用了两个,一个global一个local。global上拉近结果和风格的VGG特征图的均值和方差距离。local计算损失的时候,由于AdaAttN前含有1*1的conv要学习,我们将其删除,这样的话,没有可学习的参数了,就是确定的target。
Extension for Video Style Transfer
两个修改:
- 由于指数计算,等式5中的Softmax函数在注意分数上表现出强烈的排他性,它主要集中在局部模式上,对稳定性有负面影响。对于视频风格化,采用余弦相似度:
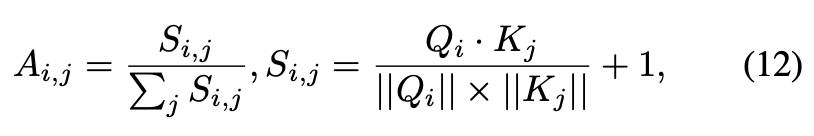

- 提出一个cross-image similarity loss去规范化图像内容。直观地说,这种跨图像相似性损失要求两幅内容图像的风格化结果与两幅原始图像具有相似的局部相似模式。因此,它确保了视频风格传输中帧间关系的感知,并有助于获得稳定的结果。
实验
Comparison with State-of-the-Art Methods
Qualitative Comparison. AdaIN[14]直接对内容特征的二阶统计量进行全局调整,我们可以看到风格被转换,内容细节严重丢失(第1、5、6行)。Avatar Net利用AdaIN进行多尺度传输,并引入了带有patch匹配策略的风格装饰器,这导致了带有明显斑块(第1、6、8行)的模糊风格化结果。SANet和MAST采用注意机制,在深层次上注意将风格特征转换为内容特征。这将导致内容结构损坏(第3、4、6行)和纹理变脏(第1、2、8行)。某些风格修补方法甚至不正确地直接传输到内容图像中(第4、8行)。LInear和MCCNet修改特征通过线性投影和逐通道相关,两者都产生相对干净的风格化输出。然而,风格图像的纹理模式没有被及时捕获,内容细节丢失(第3、5、6行),内容图像颜色保留(第7行)。如第3列所示,AdaAttN可以自适应地将风格转换到内容图像的每个位置,这归因于每一点上新颖的专注标准化。这表明AdaAttN在风格转换和内容结构保持之间取得了更好的平衡。
User Study.
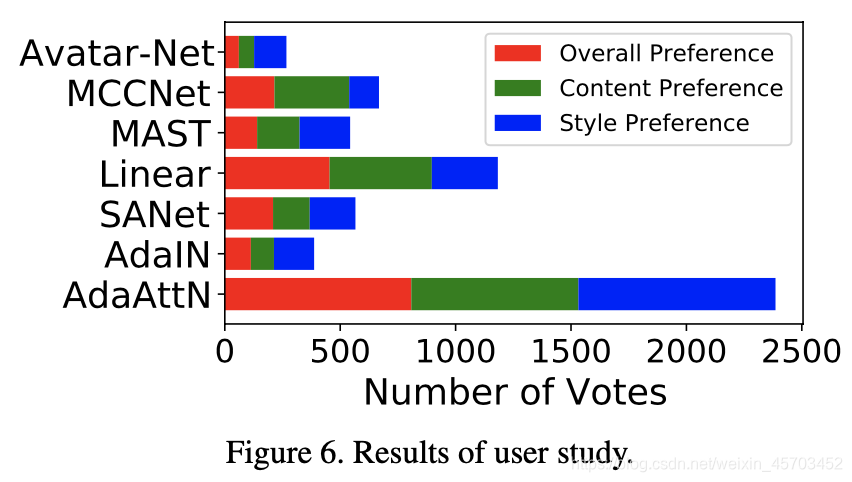
证明我们的风格化结果比竞争对手更具吸引力。
Efficiency Analysis.
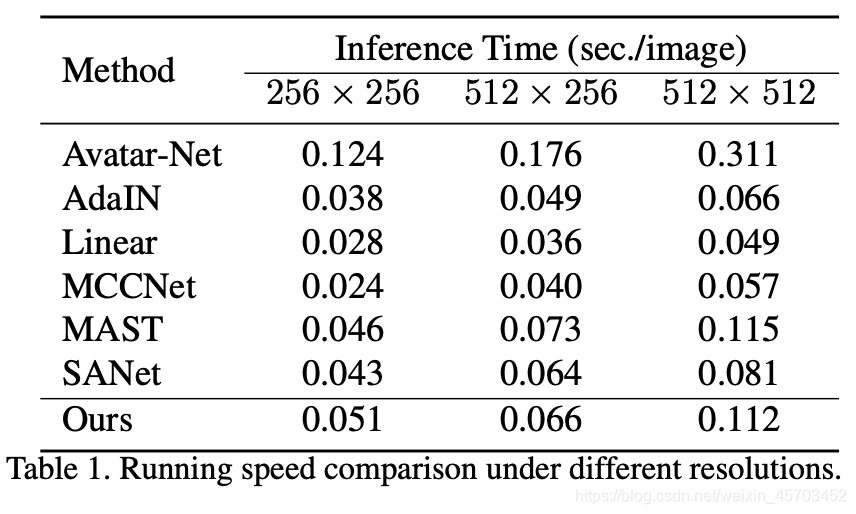
尽管本文方法使用了浅层的特征但是速度还是可以的。
Ablation Study

第4列:验证局部特征损失,将其换为常用的L2损失,质量差了很多。
第5列:去掉全局特征损失,可以在一定程度上迫使网络学习风格迁移。
第6列:不使用浅层的特征,即将 F 1 : x F^{1:x} F1:x换成 F x F^x Fx,细节会丢失。
Video Style Transfer

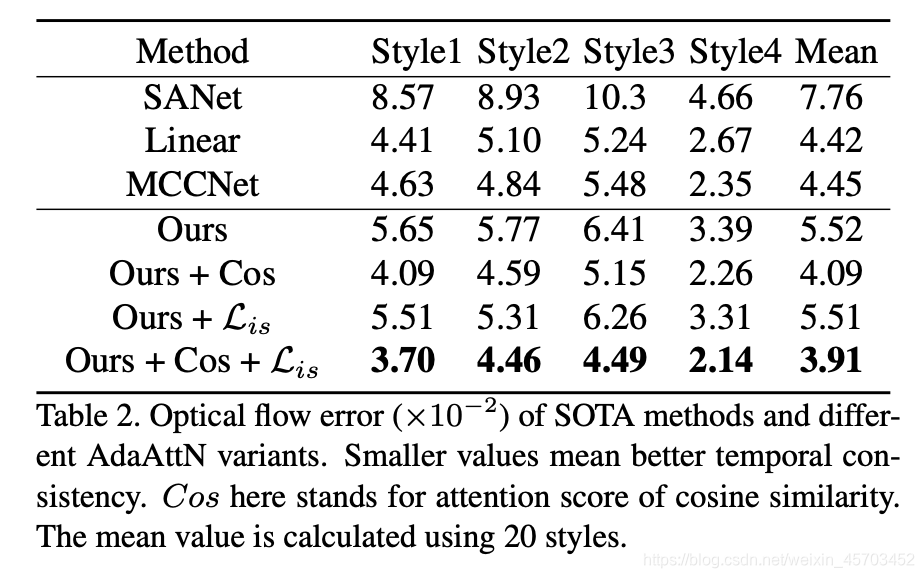
- 我们的方法比基于注意的方法SANet更稳定
- 用基于余弦距离的注意取代Softmax激活可以显著提高时序一致性
- 通过我们提出的修改,AdaAttN比Linear和MCCNet更稳定,后者也被用于视频风格化。
Multi-Style Transfer



AdaAttN pytorch
class AdaAttN(nn.Module):
def __init__(self, v_dim, qk_dim):
super().__init__()
self.f = nn.Conv2d(qk_dim, qk_dim, 1)
self.g = nn.Conv2d(qk_dim, qk_dim, 1)
self.h = nn.Conv2d(v_dim, v_dim, 1)
def forward(self, c_x, s_x, c_1x, s_1x):
Q = self.f(mean_variance_norm(c_1x))
Q = Q.flatten(-2, -1).transpose(1, 2)
K = self.g(mean_variance_norm(s_1x))
K = K.flatten(-2, -1)
V = self.h(s_x)
V = V.flatten(-2, -1).transpose(1, 2)
A = torch.softmax(torch.bmm(Q, K), -1)
M = torch.bmm(A, V)
Var = torch.bmm(A, V ** 2) - M ** 2
S = torch.sqrt(Var.clamp(min=0))
M = M.transpose(1, 2).view(c_x.size())
S = S.transpose(1, 2).view(c_x.size())
return S * mean_variance_norm(c_x) + M
Image Style Transfer补充


User Control. 支持用户控制,比如Figure 10。Figure 11又是一些额外的消融实验,在SANet上也做了浅层特征的融入。但是最终还是AdaAttN的效果好一点。

Pair-wise Combination between Content and Style. 验证方法的鲁棒性,同一张content和不同的style,或者同一张style和不同的content。Figure 12的效果很明显不错。
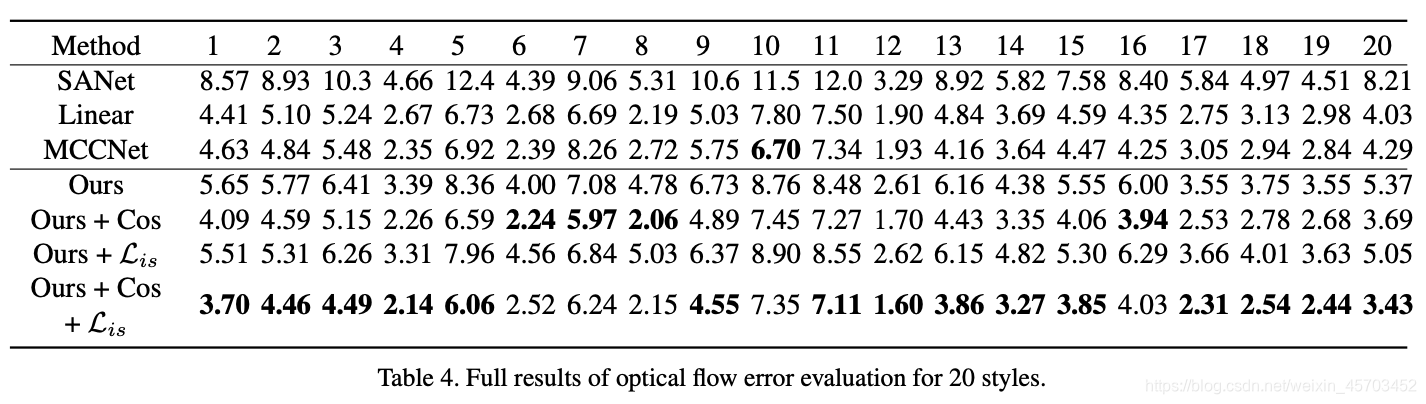

Video Style Transfer Table 4是对Table 2的补充,显示了光流error。Figure 13是更多的视频风格转换的结果展示。
这篇的主体操作不多,但是效果很好,实验做的很充分。另外就是论文的选图真的都很漂亮,很精致。下次见!