一、实验主要内容
1、内容1:接收启动信息
为了保证在以后改变画面模式后,系统仍能正常运行,我们需要将显存首地址,画面长宽等数据0xa0000,320,200存入asmhead.nas文件中定义的地址。

这里的0x0ff4之类的地址是为了与asmhead.nas中定义的地址保持一致的。
2、内容2:试用结构体
使用结构体将变量集中,以此简化程序,减少代码的行数
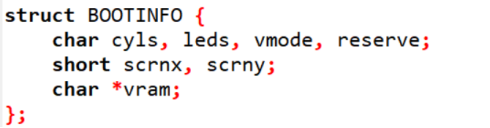
结构体命令将一串变量的声明集中起来,统一叫做“struct BOOTINFO”。最初是一字节的变量cyls,接着是1字节的变量leds,最后是vram。所有变量一共是12字节。

info指针指向地址0x0ff0是结构体的起始地址,结构体内的地址则依次按其类型增加。所以可以不用直接使用内存地址,而是使用*binfo来表示这个内存地址上12个字节的结构体。有了上述声明,“struct BOOTINFO”便可以作为一个新的变量类型,可以像int、char一样使用。*binfo便是这种类型的变量,其是一个4字节的变量。为了表示其中的scrnx,可以使用(*binfo).scrnx写法。
在这里定义了一个新结构体变量,然后再给这个结构体变量的各个元素赋值。结构体的好处是可以将各个元素一起传递。如果没有结构体,就只能将各个参数一个一个传递。
3、内容3:试用箭头记号
在这里可以使用一种不是使用括号的省略表现形式,即binfo->scrnx来表示类似于(*binfo).scrnx的表现手法,也就是所谓的箭头标记形式。

4、内容4:显示字符
实现在画面上写字,之前显示字符主要靠调用bios函数,但这次是32位模式,不能再使用bios。字符可以用8x16的长方形像素点阵来表示。将点阵中的数据置换成0或者1,8位是一个字节,而1个字符是16字节。如图:
将这些数据称之为字体数据,并将0、1排列重写成十六进制的数并存储下来。用for语句将画8个像素的程序循环16遍,便可以显示一个字符了。


以第1行为例,二进制是00000000,然后在后面的putfont8函数中进行判断画图,即判断8位上是否有1,如果有1,便将对应色号存储到该点的内存中。这样便可以显示出相应的字符了。结果如下:

5、内容5:增加字体
想要要显示更多的字符,如果使用上述方法一个一个的设计数据太麻烦,于是本书便引入OSASK的字体数据。
首先将hankaku.txt添加到源程序中,其的内容如下:


由于这既不是C语言也不是汇编语言,因此需要一个专用的编辑器。这里其是一个256的ASCII码表。其将上面的文本文件(256个字符的字体文件)读进来,然后输出成16x256=4096字节的文件。
编译生成hankaku.bin文件,并为其加上连接所必需的接口信息,将其变成目标文件。像这种在源程序以外准备的数据,需要加上extern属性,这样,c编译器便能够知道它是外部数据,并在编译时做出相应调整。
OSASK的字体数据,依照一般的ASCII字符编码,含有256个字符。A的字符编码是0x41,因此A的字体数据,放在自“hankaku+0x41*16”开始的16字节里。C语言中的A字符编码可以用‘A’来表示,所以也可以写成“hankaku+‘A’*16”。
结果如下:


6、内容6:显示字符串
通过设计显示函数来显示字符串:

因为每一个字符大小为8*16所以将x加8就相当于右移一个字符的位置
因为C语言中的字符串存储方式是连续的字符,在字符串结尾处是’\0’字符,所以以此字符作为结束标志,通过首字符地址s读取字符,即可完成字符串的打印
实验结果:


7、内容7:显示变量值
当程序运行与想象中不一致时,可以选择将可疑变量的值显示出来以做对比。
而想要输出可疑变量的值,我们就需要将变量的值导入到字符串中然后将其输出。
在这里可以选择使用sprintf函数,其是printf函数的同类,与printf函数的功能很相近。但与printf不同的是,其并不是按指定格式输出,只是将输出内容作为字符串写在内存中。
这个sprintf函数,是本次使用的名为GO的C编译器附带的函数,其只对内存进行操作,但能不适用操作系统的任何功能,因此其可以应用与所有的操作系统。要在C语言中使用sprintf函数,需要在源程序的开头写上# include <stdio.h>。
Sprintf函数的使用方法与printf相近是:sprintf(地址,格式,值,值,值…)。这里的地址是指定所生成字符串的存放地址。格式基本上是单纯单纯额的字符串,如果有%d这类的符号,就置换成后面的值的内容。%d将数值作为十进制数转化为字符串。

这里相当于是把scrnx = binfo->scrnx这个字符串放到了s内存地址的位置,格式基本上是单纯的字符串,然后通过调用putfonts8_asc函数,依次将从s地址开始的内存部分的数据以char的形式进行输出,直到地址位置的内容为空。
实验结果:

8、内容8:显示鼠标指针
这里显示鼠标指针的意思还是先将其画出来,这里相当于一个特殊的字符而已。
首先将鼠标指针的大小定为16x16,准备16x16=256字节的内存,然后往里面写入鼠标指针的数据。
当读取遇到*号时,向指定内存中填入黑色,当遇到O号时,向指定内存填土白色,当遇到. 号时,向指定内存中填入背景色。要将背景色显示出来,需要制作一个将buf中的数据复制到vram中的程序,程序如下:


这里的vram和vxsize是关于VRAM的信息,他们的值分别是0xa0000和320.pxsize和pysize是想要显示的图形的大小,鼠标指针的大小是16x16,因此这两个值都是16.px0和py0指定图形在画面上的显示位置。Buf和bxsize分别指定图形的存放地址和每一行含有的像素数。

首先进行初始化,然后通过mx和my确定鼠标的位置,再调用init_mouse_cursor8函数将鼠标的显示图形初始化,再通过调用putblock8_8函数将鼠标进行打印,再通过sprintf函数将mx和my这两个坐标写入内存中,通过调用putfonts8_asc函数将坐标在左上角进行打印。
9、内容9:GDT和IDT的初始化
想要使鼠标可以进行移动就需要中断机制,而中断机制首先需要将GDT和IDT初始化。
GDT与IDT都是与CPU有关的设定,为了让操作系统能够使用32模式,需要对CPU做各种设定。为了能使操作系统同时运行多个程序,但又要避免内存的使用范围重叠。解决这种问题的方法便是分段。
所谓分段就是将合计4GB的内存分成很多块,每一块的起始地址都看作0来处理。按这种分段方法,为了表示一个段,需要有以下信息。
段的大小
段的起始地址
段的管理属性(禁止写入,禁止执行,系统专用等)
CPU用8个字节(=64)的数据来表示这些信息。但用于指定段的寄存器只有16位,因此模仿图像调色板的做法,先有一个段号,存放在段寄存器里,然后预先设定好段号与段的对应关系。段号可以用0-8191的数。
但为什么段号只可以用0-8191的数呢?
因为段寄存器是16位,本来应该能处理0-65535范围的数,但由于CPU设计上的原因,段寄存器的低3位不能使用,因此能够使用的段号只有13位,能够处理的就只有位于0-8191的区域了。8192*8=64kb,所以占据64kb的空间。
GDT是全局段号记录表,将这些数据整齐地排列排列按在内存的某个地方,然后将内存的起始地址和有效设定个数放在CPU内被称作GDTR的特殊寄存器中。
IDT是中断记录表,当CPU遇到外部状况变化,或者是内部偶然发生某些错误时,会临时切换过去处理这种突发事件,这就是中断。
什么是中断机制?
各个设备有变化时产生中断,中断发生后,CPU暂时停止正在处理的任务,并做好接下来能够继续处理的准备,转而执行中断程序。中断程序执行完以后,再调用事先设定好的函数,返回处理中的任务。IDT记录了0-255的中断号码与调用函数的对应关系。
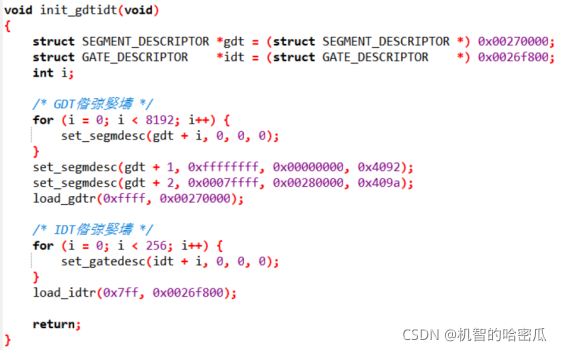
变量gdt被赋值为0x00270000,也就是将0x270000-0x27ffff设为GDT。
变量idt也是一样,IDT被设为0x26f800-0x26ffff。
接下来对段号为1和2的两个段进行设定,段号为1的段,上限值为0xffffffff即大小正好是4GB,地址是0,它表示CPU所能管理的全部内存,段属性设为0x4092,为可读可写不可执行。段号为2的段,其大小是512KB,地址是0x280000,其表示的范围为0x280000-0x280000+0x070000。实际上第二段就是我们的type.c,即os,对应的是应该0x409a为可读不可写可执行属性,Load_gdtr是通过汇编语言来给GDTR赋值。
二、遇到的问题及解决方法
1、问题1:
注册IDT时,函数中声明的变量意义
在第5天的教材中使用了set_gatedesc函数但没有给出这个函数的参数含义
void set_gatedesc(struct GATE_DESCRIPTOR gd, int offset, int selector, int ar)
解决方法:struct GATE_DESCRIPTOR gd–表示要注册的IDT位置
int offset–偏移(这个偏移是在代码段中的偏移)相当于在对应中断发生时调用相应的函数
int selector–表示第二个参数的函数属于哪个端(这里低3位必须为0,所以要左移3位)
比如set_getdesc(idt+0x21,(int)asm_inthandler21,2<<3,AR_INTGATE32);
就是将asm_inthandler21注册在idt的第x021号,属性为AR_INTGATE32即0x008e表示中断处理的有效设定
三、程序设计创新点
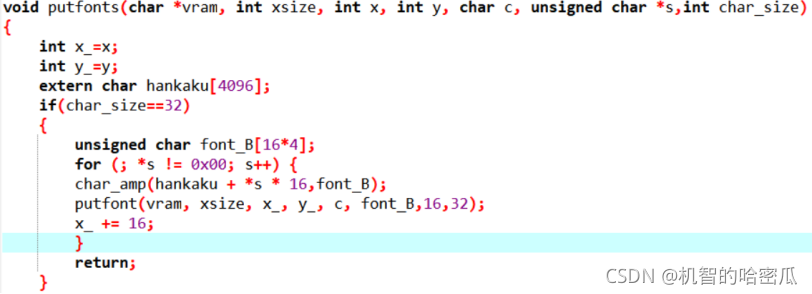
1、创新点1:创建自己的字体和实现任意大小字符的显示:
现在我们的系统中可以使用的字符为256个。每一个字符大小为816的像素,但目前的字符集中只有英文,但我们可以通过自己设计来使屏幕可以显示出汉字来
首先我们需要先确定我们汉字的大小,这里我在excell表格中测试了一下,发现16*16的大小是比较合适的
第二步,显示汉字,因为我们系统原来的代码是显示816大小的英文字符的,而汉字的大小为1616,作者的putfont8只能显示816像素大小的字符,这里我将该函数进行了改良,新添加了两个参数代表要显示字符的大小,比如显示816的英文字符,那我们的参数应该为8和16(表示行和列的像素大小),函数实现代码如下(新的函数更名为putfont):

有了这个函数,就方便我们后续对于任何大小字符显示的实现了
第三步:设计汉字显示的字节数据,汉字显示和英文一样由一个字节的8位表示颜色,这里我设计了自己的名字,具体数据如图:
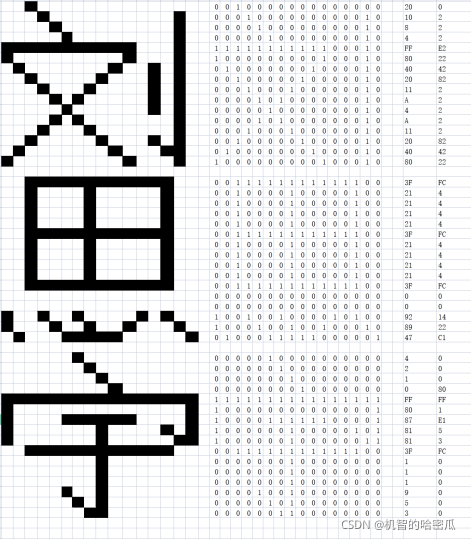
最后我们将数据写入一个数组中然后用我们写的函数putfont进行输出,输出结果如下:

(虽然不好看,不过还好成功了(说明我们前面写的显示任意大小字符的函数基本上也是对的))
2、创新点2:改变字符集的字体大小(放大)
作者给的字符集数据都是8*16大小的字符,但我们操作系统只有一种字体大小是明显不合适的,那我们如何去获得更大的字体呢,一种办法是想作者提供的字符集一样我们自己像上一步设计汉字一样,把256个字符全部设计一个大号的,但这个明显太耗人工了,而我们的目的是放大字体,而不是改变字体,那么放大后的字体应该与原有字体的数据是有关系的,而据此我们可以写一个放大字体的函数,以原字符数据为基础,将其按照一定的规则生成大号的字体数据,这样就能极大的解决我们的人力资源消耗了。
首先我们需要解决的就是如何将字符集中的字符放大了
这里我使用的是一种较为简单的放大方式:将字符的每一个像素点扩大4倍,其周围的像素点颜色与扩大的像素点颜色一致

将每一个像素点拿出来,然后将其扩大为一个22的4个像素点,其颜色与被拿出来的像素点颜色相同。
然后方法我们确定后,接下来就是写代码了
这个程序我的想法是将原字符数据一个行一行的扩大,现在字符数据一行是8位一个字节那么放大后应该是216的大小其中按照我们的方法扩大的话这两行的数据应该是一样的,所以我们只需要得出一行的数据就可以得到放大后的4个字节数据
考虑到这里的4位就可以生成我们的一个字节所以我们先对这个字节的前4位进行处理,
这里我们通过移位来获得前4位每一位的数据,然后将其赋给我们扩大后字节的两位,这样对于第i个字节的前4位的处理就完成了,然后同理完成后4位的处理就可以了
,最后将这一行的数据复制给下两个字节就完成了


全部函数代码如下:

最后我们再将作者的putfonts8_asc改写一下,使之能够适应我们放大后的字符显示
,这里因为我们只有放大4倍字符的能力,所以这里字符串输出这里,就不能像字符那样随意输出任意大小的字符了(主要由于输出字符串函数固定使用的是字符集中的数据),这里新设定一个参数用于表示是否放大字符,
最终代码如下:

最终结果如下:

3、创新点3:丰富字符串显示函数的功能(换行)
我们一般在Windows环境下的C语言编程的时候,输出字符串时,通常会习惯于在字符串末尾加上’\n’用于换行,但我们现有的字符串显示函数并不能识别出换行的效果,所以这里我们把这个功能加上:
原理很简单,在识别到’\n’字符时将后续要输出的字符的位置向下平移一个字符的高的大小(这里是放大版的所以是32)

输出效果:


四、实验心得体会
这次实验,书本上的内容有原本C语言的基础,还是比较容易理解,在本次实验中我用时最长的还是对于字符显示函数的改写,最开始我为了能够显示1616大小的汉字,我对照原来作者的函数重新写了一个putfont16函数用于输出,到后面的1632放大版字符的显示我也重新写的一个函数,不过后面我认为要开发一个操作系统,我们不能每次都只按照特定的大小来编写函数,所以我设想重新编写一个可以适应输出任意大小字符的函数,这个函数中我使用了一个m变量来表示下一个将要读取的位,然后配合对指针的操作才,做到了能够顺序处理每一个字节中每一位的数据,这样才完成了putfont函数的最终编写(所以别看这个函数代码量不大,实际上写起来还很麻烦)。